Python绘图系统18:导入txt格式数据
文章目录
-
- 简单的数据导入
- genfromtxt的参数
- 源代码
Python绘图系统:
- 从0开始的3D绘图系统一套3D坐标,多个函数散点图、极坐标和子图
- 自定义控件:绘图风格风格控件定制绘图风格
- 坐标设置进阶:动态更新组件导入外部文件导入txt
简单的数据导入
由于我们设置了两种导入数据的方式,一种简单的,一种复杂的。如果用复杂的,那么就需要设计一个参数对话框,并获取相关参数;如果用简单的,那么只需沿用之前设置的参数就可以了。
这隐含着一个必选的方案,即设计几个类成员,用于存放这些参数。最好的地方当然是放在initVar函数中
def initVar(self, mode):
self.txtPara = {}
self.binPara = {}
self.FILES = [('文本文件', 'txt'), ('文本文件', 'csv'),
('二进制文件', 'bin')]
# ...
由于目前只对文本文件和二进制有兴趣,所以参数列表也只用了两个。
接下来先设计简单的数据导入函数
def btnImportSimple(self, evt):
f = askopenfilename(filetypes=self.FILES)
self.data = np.genfromtxt(f, **self.txtPara)
self.showImData()
def showImData(self):
tmp = self.data.reshape(-1)[:10].astype(str)
self.imText.set(", ".join(tmp.tolist()))
其中showImData可以展示前10个数值,效果如下
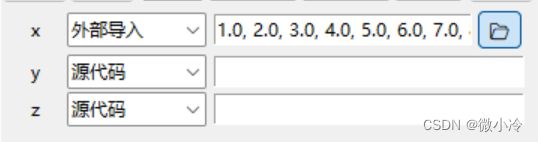
genfromtxt的参数
复杂文本数据的导入,需要一个参数对话框,我们使用的genfromtxt的常用参数大致有下面这些
genfromtxt(fname,dtype,comments,delimiter,skipd_header,skip_fonter,converters,missing_values,filling_values,usecols,names, autostrip,**kwarg)
其中,大部分参数与loadtxt中含义相同,其他参数的含义如下。
| 参数 | 类型 | 含义 |
|---|---|---|
| fname | 字符串 | 文件名 |
| dtype | 字符串 | 读取后的数据类型 |
| comments | 字符串 | 注释标识符,加载时会自动忽略注释标识符后的字符串 |
| delimiter | 字符串 | 分割符,为整数时表示元素最大宽度 |
| skip_header | 数值 | 跳过文件头部的字符行数 |
| skip_footer | 字数值 | 跳过文件尾部字符串行数 |
| missing_values | 字符串 | 指定数组中忽略的值 |
| filling_values | 字符串 | 指定某个值用于替代忽略值 |
| autostrip | 布尔 | 为True时可自动去除变量首尾的空格 |
| converters | 字典或函数 | 用以转化数据格式 |
| usecols | 数值 | 使用的列号 |
| encoding | 字符串 | 编码方式 |
据此先设计一个翻译字典,以便于文件对话框使用
self.TXTLABEL = {
"comments" : "注释标识",
"delimiter" : "分割符号",
"skip_header" : "文首跳过行数",
"skip_footer" : "文尾舍弃行数",
"missing_values" : "指定忽略值",
"filling_values" : "忽略值替代为",
"autostrip" : "去除首尾空格",
"usecols" : " 使用的列号",
"encoding" : "编码方式",
}
为了实现这些功能的顺利输入,可以设计一个字典参数对话框。然后就可以更改高级文本的导入代码了,有关参数对话框,可参考这篇:tkinter自定义参数对话框
考虑到这里面有一些参数是整型,所以要在得到数据之后对数据类型进行转换
def btnImportComplex(self, evt):
f = askopenfilename(filetypes=self.FILES)
if f.endswith('.txt'):
self.txtImport(f)
def txtImport(self, fileName):
dct = {v:"" for v in self.TXTLABEL.values()}
AskDct(dct)
for key in dct:
if dct[key] == "":
continue
if key in ["skip_header", "skip_footer", "usecols"]:
dct[key] = int(dct[key])
self.txtPara[key] = dct[key]
self.data = np.genfromtxt(fileName, **self.txtPara)
self.showImData()
源代码
import tkinter as tk
import tkinter.ttk as ttk
from tkinter.filedialog import askopenfilename
import numpy as np
# 字典参数对话框
class AskDct(tk.Tk):
def __init__(self, dct):
super().__init__()
self.title("请输入参数")
self.dct = dct
self.initWidgets()
self.mainloop()
def initWidgets(self):
self.varDct = {}
for i,key in enumerate(self.dct):
self.varDct[key] = tk.StringVar()
self.varDct[key].set(self.dct[key])
frm = tk.Frame(self)
frm.pack(side=tk.TOP)
ttk.Label(frm, text=key, width=10).pack(side=tk.LEFT, pady=2)
ttk.Entry(frm, width=20,
textvariable=self.varDct[key]).pack(side=tk.LEFT, pady=2)
frm = tk.Frame(self)
frm.pack(side=tk.TOP)
ttk.Button(self, text="取消", width=10,
command=self.btnCancel).pack(side=tk.RIGHT, pady=2)
ttk.Button(self, text="确定", width=10,
command=self.btnOK).pack(side=tk.RIGHT, pady=2)
def btnOK(self):
for key in self.dct:
self.dct[key] = self.varDct[key].get()
self.btnCancel()
def btnCancel(self):
self.destroy()
self.quit()
class AxisFrame(ttk.Frame):
# widths 是每个控件的宽度
def __init__(self, master, label, mode, widths, **options):
super().__init__(master, **options)
self.pack()
self.label = label
self.initVar(mode)
self.initWidgets(widths)
def initVar(self, mode):
self.txtPara = {}
self.binPara = {}
self.TXTLABEL = {
"comments" : "注释标识",
"delimiter" : "分割符号",
"skip_header" : "文首跳过行数",
"skip_footer" : "文尾舍弃行数",
"missing_values" : "指定忽略值",
"filling_values" : "忽略值替代为",
"autostrip" : "去除首尾空格",
"usecols" : " 使用的列号",
"encoding" : "编码方式",
}
self.FILES = [('文本文件', 'txt'), ('文本文件', 'csv'),
('二进制文件', 'bin')]
self.MODES = ("序列化", "源代码", "外部导入", "无数据")
self.mode = tk.StringVar()
self.srcText = tk.StringVar()
self.arrText = [tk.StringVar() for _ in range(3)]
self.imText = tk.StringVar()
self.setMode(mode)
def initWidgets(self, widths):
tk.Label(self, text=self.label, width=widths[0]).pack(side=tk.LEFT)
slct = ttk.Combobox(self, width=widths[1],
textvariable=self.mode)
slct['value'] = self.MODES
slct.bind('<>' , self.slctChanged)
slct.pack(side=tk.LEFT)
self.initRes(widths[2])
def initRes(self, width):
self.srcEntry = tk.Entry(self, width=width-1,
textvariable=self.srcText)
# 序列化参数设置
self.arrFrame = ttk.Frame(self, width=width-5)
for i, key in enumerate(["起点", "终点", "步长"]):
tk.Label(self.arrFrame, text=key).grid(row=0, column=i*3)
tk.Entry(self.arrFrame, width=int(width/6),
textvariable=self.arrText[i]).grid(row=0, column=i*3+1)
# 导入数据设置
self.imFrame = ttk.Frame(self, width=width-5)
tk.Entry(self.imFrame, width=width-6,
textvariable=self.imText).pack(side=tk.LEFT)
btn = ttk.Button(self.imFrame, text="", width=3)
btn.pack(side=tk.LEFT, padx=3)
btn.bind("" , self.btnImportSimple)
btn.bind("" , self.btnImportComplex)
self.showRes(self.mode.get())
def btnImport(self):
f = askopenfilename(filetypes=self.FILES)
self.imText.set(f)
return f
def btnImportSimple(self, evt):
f = askopenfilename(filetypes=self.FILES)
self.data = np.genfromtxt(f, **self.txtPara)
self.showImData()
def showImData(self):
tmp = self.data.reshape(-1)[:10].astype(str)
self.imText.set(", ".join(tmp.tolist()))
def btnImportComplex(self, evt):
f = askopenfilename(filetypes=self.FILES)
if f.endswith('.txt'):
self.txtImport(f)
def txtImport(self, fileName):
dct = {v:"" for v in self.TXTLABEL.values()}
AskDct(dct)
for key in dct:
if dct[key] == "":
continue
if key in ["skip_header", "skip_footer", "usecols"]:
dct[key] = int(dct[key])
self.txtPara[key] = dct[key]
self.data = np.genfromtxt(fileName, **self.txtPara)
self.showImData()
def showRes(self, mode):
resDct = {"源代码":self.srcEntry, "序列化":self.arrFrame,
"外部导入": self.imFrame}
resDct[mode].pack(padx=5, pady=2, side=tk.LEFT, fill=tk.X)
def slctChanged(self, evt):
self.srcEntry.pack_forget()
self.arrFrame.pack_forget()
self.imFrame.pack_forget()
mode = self.mode.get()
self.showRes(self.mode.get())
def setMode(self, mode):
if type(mode) != str:
mode = self.MODES[mode]
self.mode.set(mode)
def setData(self, data=None, **txyz):
if self.mode.get() == "序列化":
return self.getArray()
elif self.mode.get() == "外部导入":
return self.loadData(data)
else:
return self.readPython(**txyz)
def readPython(self, t=None, x=None, y=None, z=None):
self.data = eval(self.srcText.get())
return self.data
def loadData(self, data):
if type(data) != type(None):
self.data = data
return self.data
def getArray(self):
vs = [float(t.get()) for t in self.arrText]
self.data = np.arange(*vs)
return self.data