《MixConv--混合的深度卷积核》论文阅读笔记
MixNet
这篇文章来自谷歌大脑,是最近(19年7月)刚挂出来的,然后应该是发表在了BMVC 2019上。原文可见MixConv: Mixed Depthwise Convolutional Kernels。
摘要
深度卷积在现代高效卷积神经网络中越来越受欢迎,但其核大小却常常被忽略。在本文中,我们系统地研究了不同核大小的影响,并观察到将不同尺寸核的优点结合起来可以获得更好的精度和效率。在此基础上,我们提出了一种新的混合深度卷积(MixConv),它很自然地将多个核大小混合在一个卷积中。我们的MixConv作为对普通的深度卷积的一种简单的代替,提高了现有MobileNets在ImageNet分类和COCO目标检测方面的准确性和效率。为了证明MixConv的有效性,我们将其整合到AutoML搜索空间中,开发了一个新的模型家族,命名为MixNets,其性能优于之前的移动模型,包括MobileNetV2(ImageNet top-1准确率+4.2%)、ShuffleNetV2(+3.5%)、MnasNet(+1.3%)、ProxylessNAS(+2.2%)和FBNet(+2.0%)。特别值得一提的是,我们的MixNet-L在典型的移动设置(<600M FLOPS)下实现了最新的78.9%的ImageNet top-1精度。代码位于https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet/mixnet。
1. 引言
卷积神经网络(ConvNets)在图像分类、检测、分割等方面有着广泛的应用。卷积神经网络设计的一个最新趋势是提高精度和效率。随着这一趋势,深度卷积在现代卷积中越来越受欢迎,如MobileNets、ShuffleNets、NASNet、AmoebaNet、MnasNet和EfficientNet。与普通卷积不同,深度卷积核分别应用于每个单独的通道,从而将计算成本降低了一个因子C,其中C是通道数。在设计具有深度卷积核的卷积神经网络时,一个重要但常常被忽略的因素是核大小。虽然常用的做法是简单地使用3x3卷积核,但是最近的研究结果表明,更大的核尺寸,如 5 × 5 5\times 5 5×5卷积核和 7 × 7 7\times 7 7×7卷积核,可能会提高模型的精度和效率。
在本文中,我们重新讨论了一个基本问题:更大的核是否总是能够获得更高的精度?从在AlexNet中首次观察到之后,我们就知道每个卷积核都负责捕获一个局部图像模式,这可能是早期阶段的边缘,也可能是后期阶段的对象。大的核往往以牺牲更多的参数和计算为代价来获取具有更多细节的高分辨率模式,但是它们总是提高精度吗?为了回答这个问题,我们基于MobileNets系统地研究了核大小的影响。图1显示了结果。正如预期的那样,较大的内核大小会显著地使用更多参数从而增加模型大小;然而,从 3 × 3 3\times 3 3×3到 7 × 7 7\times 7 7×7模型精度首先提高,但当核大小大于 9 × 9 9\times 9 9×9时,模型精度迅速下降,这表明非常大的核大小可能会损害精度和效率。事实上,这个观察符合卷积神经网络的最初直觉:在核大小等于输入分辨率的极端情况下,ConvNet简单地成为一个完全连接的网络,这是众所周知的次品。本研究指出单一核大小的局限性:我们既需要大卷积核来捕获高分辨率模式,也需要小卷积核来捕获低分辨率模式,以获得更好的模型精度和效率。

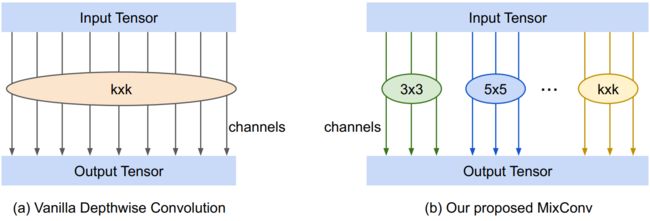
在此基础上,我们提出了一种混合深度卷积(MixConv),它将不同的核大小混合在一个卷积运算中,这样就可以很容易地捕获不同分辨率的模式。图2显示了MixConv的结构,它将通道划分为多个组,并对每组通道应用不同的核大小。我们的MixConv是一个简单的替换普通深度卷积的方法,但是它在ImageNet分类和COCO目标检测上都能显著提高MobileNets的准确性和效率。
为了进一步证明MixConv的有效性,我们利用神经结构搜索开发了一个名为MixNets的新模型家族。实验结果表明,我们的MixNet模型明显优于之前所有的移动卷积神经网络,如ShuffleNets、MnasNet、FBNet和ProxylessNAS。特别是,我们的中等尺寸的MixNet-M实现了与ResNet-152相同的77.0% ImageNet top-1精度,同时使用了比ResNet-152少12倍的参数和31倍的FLOPs。
注:原文用的是FLOPS,虽然只有大小写上的区别,但实际上FLOPS和FLOPs是不同的概念,FLOPS是“每秒所执行的浮点运算次数”(floating-point operations per second)的缩写,它常被用来估算电脑的执行效能,而FLOPs全称是floating point operations,即表示浮点运算次数,所以这里应该是FLOPs才对。
2. 相关工作
高效卷积神经网络: 近年来,人们在提高卷积神经网络效率方面做出了巨大的努力,从更高效的卷积操作、瓶颈层,到更高效的架构。特别是,深度卷积在所有移动尺寸的卷积神经网络中越来越流行,如MobileNets、ShuffleNets、MnasNet以及其他。最近,EfficientNet通过广泛使用深度和逐点卷积,甚至实现了最先进的ImageNet精度和十倍更高的效率。与常规卷积不同,深度卷积对每个通道分别执行卷积核,从而减小了参数大小和计算成本。我们提出的MixConv推广了深度卷积的概念,可以认为是普通深度卷积的直接替代。
多尺度网络和特性: 我们的想法与之前的多分支卷积神经网络有很多相似之处,比如Inceptions、Inception-ResNet、ResNeXt和NASNet。通过在每一层中使用多个分支,这些卷积神经网络能够在一层中使用不同的操作(例如卷积和池化)。同样,之前也有很多工作是将不同层次的多尺度特征图结合起来,如DenseNet和特征金字塔网络。然而,与以前的工作不同,这些工作主要集中在改变神经网络的宏观架构以便利用不同的卷积运算,我们的工作旨在设计单个深度卷积的直接替换,目的是轻松利用不同的卷积核大小而不改变网络结构。
神经架构搜索: 最近,神经架构搜索通过自动化设计过程和学习更好的设计选择,实现了比手工模型更好的性能。因为我们的MixConv是一个灵活的操作,有许多可能的设计选择,所以我们使用了与[ProxylessNAS, MnasNet, FBNet]类似的现有架构搜索方法,通过将MixConv添加到搜索空间来开发一个新的MixNets家族。
3. MixConv
MixConv的主要思想是在一个深度卷积操作中混合多个不同大小的卷积核,这样就可以很容易地从输入图像中捕获不同类型的模式。在本节中,我们将讨论MixConv的特征图和设计选择。
3.1 MixConv Feature Map
我们从普通的深度卷积开始。设 X ( h , w , c ) X^{(h,w,c)} X(h,w,c)为形状为 ( h , w , c ) (h,w,c) (h,w,c)的输入张量,其中 h h h为空间高度, w w w为空间宽度, c c c为通道大小。设 W W W为深度卷积核,其中 k × k k\times k k×k为核大小, c c c为输入通道大小, m m m为通道乘数。为了简单起见,这里我们假设核宽度和高度是相同的 k k k,但是很容易将其推广到核宽度和高度不同的情况。输出张量 Y ( h , w , c ⋅ m ) Y^{(h,w,c\cdot m)} Y(h,w,c⋅m)将具有相同的空间形状 ( h , w ) (h,w) (h,w)和成倍的输出通道大小 m ⋅ c m\cdot c m⋅c,每个输出特征图的值计算如下:
Y x , y , z = ∑ − k 2 ≤ i ≤ k 2 , − k 2 ≤ j ≤ k 2 X x + i , y + j , z / m ⋅ W i , j , z , ∀ z = 1 , … , m ⋅ c Y_{x,y,z}=\sum_{-\frac{k}{2}\le i\le\frac{k}{2},-\frac{k}{2}\le j\le\frac{k}{2}}X_{x+i,y+j,z/m}\cdot W_{i,j,z},\qquad\forall z=1,\ldots,m\cdot c Yx,y,z=−2k≤i≤2k,−2k≤j≤2k∑Xx+i,y+j,z/m⋅Wi,j,z,∀z=1,…,m⋅c
与普通的深度卷积不同,MixConv将通道划分为组,并为每个组提供不同的核大小,如图2所示。更具体地说,输入张量划分为g组的虚拟张量 < X ^ ( h , w , c 1 ) , … , X ^ ( h , w , c g ) > <\hat{X}^{(h,w,c_{1})},\ldots,\hat{X}^{(h,w,c_{g})}> <X^(h,w,c1),…,X^(h,w,cg)>,所有虚拟张量 X ^ \hat{X} X^具有相同的空间高度 h h h和宽度 w w w,并且他们的总通道大小与原始输入张量的相等: c 1 + c 2 + … + c g = c c_{1}+c_{2}+\ldots+c_{g}=c c1+c2+…+cg=c。同样的,我们也将卷积核分成g组虚拟核: < W ^ ( k 1 , k 1 , c 1 , m ) , … , W ^ ( k g , k g , c g , m ) > <\hat{W}^{(k_{1},k_{1},c_{1},m)},\ldots,\hat{W}^{(k_{g},k_{g},c_{g},m)}> <W^(k1,k1,c1,m),…,W^(kg,kg,cg,m)>。对于第t组虚拟输入张量和核,相应的虚拟输出计算如下:
Y ^ x , y , z t = ∑ − k t 2 ≤ i ≤ k t 2 , − k t 2 ≤ j ≤ k t 2 X ^ x + i , y + j , z / m t ⋅ W ^ i , j , z t , ∀ z = 1 , … , m ⋅ c t \hat{Y}^{t}_{x,y,z}=\sum_{-\frac{k_{t}}{2}\le i\le\frac{k_{t}}{2},-\frac{k_{t}}{2}\le j\le\frac{k_{t}}{2}}\hat{X}^{t}_{x+i,y+j,z/m}\cdot \hat{W}^{t}_{i,j,z},\qquad\forall z=1,\ldots,m\cdot c_{t} Y^x,y,zt=−2kt≤i≤2kt,−2kt≤j≤2kt∑X^x+i,y+j,z/mt⋅W^i,j,zt,∀z=1,…,m⋅ct
最终输出张量是所有虚拟输出张量 < Y ^ x , y , z 1 1 , … , Y ^ x , y , z g g > <\hat{Y}^{1}_{x,y,z_{1}},\ldots,\hat{Y}^{g}_{x,y,z_{g}}> <Y^x,y,z11,…,Y^x,y,zgg>的串联(concatenation):
Y x , y , z o = C o n c a t ( Y ^ x , y , z 1 1 , … , Y ^ x , y , z g g ) Y_{x,y,z_{o}}=Concat(\hat{Y}^{1}_{x,y,z_{1}},\ldots,\hat{Y}^{g}_{x,y,z_{g}}) Yx,y,zo=Concat(Y^x,y,z11,…,Y^x,y,zgg)
其中 z o = z 1 + … + z g = m ⋅ c z_{o}=z_{1}+\ldots+z_{g}=m\cdot c zo=z1+…+zg=m⋅c是最终的输出通道大小。
图3是一个python实现的基于Tensorflow的MDConv简单样例。在某些平台上,MixConv可以作为一个单独的操作实现,并使用分组卷积进行优化。尽管如此,如图所示,MixConv可以被认为是一种简单的取代普通深度卷积的方法。

3.2 MixConv的设计选择
MixConv是一个灵活的卷积运算,有几个设计选项:
组大小g: 它决定一个输入张量使用多少种不同类型的卷积核。在 g = 1 g=1 g=1的极端情况下,MixConv等价于普通的深度卷积。在我们的实验中,我们发现 g = 4 g=4 g=4通常是MobileNets的一个安全选择,但在神经架构搜索的帮助下,我们发现从1到5的各种组大小可以进一步提高模型的效率和准确性。
每个组的核大小: 理论上,每个组可以有任意的核大小。但是,如果两个组具有相同的内核大小,那么就相当于将这两个组合并成一个组,因此我们限制每个组具有不同的核大小。此外,由于小的卷积核大小通常具有更少的参数和FLOPs,我们限制核大小总是从 3 × 3 3\times 3 3×3开始,并且每组单调地增加2。换句话说,组 i i i的核大小总是 2 i + 1 2i+1 2i+1。例如,4组MixConv总是使用内核大小 { 3 × 3 , 5 × 5 , 7 × 7 , 9 × 9 } \{3\times 3,5\times 5,7\times 7,9\times 9\} {3×3,5×5,7×7,9×9}。有了这个限制,每个组的核大小都是为任何组大小g所预定义的,从而简化了我们的设计过程。
每组的通道大小: 本文主要考虑两个通道划分方法:(1)均等划分:每组将有相同数量的滤波器;(2)指数划分:第i组约占总通道的 2 − i 2^{-i} 2−i部分。例如,给定一个总滤波器数量为32的4组MixConv,均等划分将通道划分为 ( 8 , 8 , 8 , 8 ) (8,8,8,8) (8,8,8,8),而指数划分将通道划分为 ( 16 , 8 , 4 , 4 ) (16,8,4,4) (16,8,4,4)。
空洞卷积: 由于大的卷积核需要更多的参数和计算,另一种选择是使用空洞卷积,它可以增加感受野,而不需要额外的参数和计算。然而,正如我们在3.4节的消融研究中所示,空洞卷积通常比使用大尺寸卷积核时的精度低。
3.3 MixConv在MobileNets上的性能
由于MixConv是普通深度卷积的简单替代,我们使用现有的MobileNets评估其在分类和检测任务上的性能。
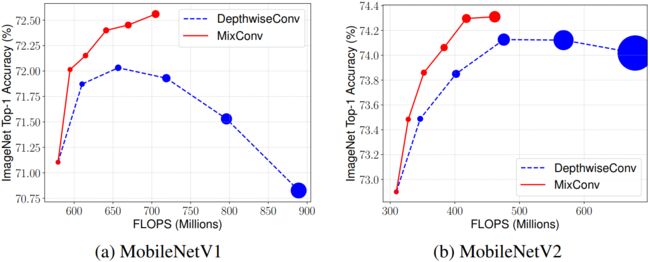
ImageNet分类性能: 图4显示了MixConv在ImageNet分类上的性能。基于MobileNet V1和V2,我们用更大的或MixConv核替换了所有原来的 3 × 3 3\times 3 3×3深度卷积核。值得注意的是,MixConv总是从 3 × 3 3\times 3 3×3核大小开始,然后每组单调地增加2,因此图中MixConv最右边的点有6组核大小为 { 3 × 3 , 5 × 5 , 7 × 7 , 9 × 9 , 11 × 11 , 13 × 13 } \{3\times 3,5\times 5,7\times 7,9\times 9,11\times 11,13\times13\} {3×3,5×5,7×7,9×9,11×11,13×13}的滤波器。在图中,我们观察到:(1)MixConv通常使用较少的参数和FLOPs,但其精度与普通的深度卷积相近或更好,说明混合不同的卷积核可以提高效率和精度;(2)与普通的深度卷积相比,深度卷积的精度会因为更大的核而降低,如图1所示,MixConv对非常大的核的敏感度要低得多,这表明不同的核混合在一起,对于较大的核尺寸,可以获得更稳定的精度。
COCO检测性能: 我们还评估了MixConv基于MobileNets的COCO目标检测。表1显示了性能比较,其中我们的MixConv始终比普通的深度卷积获得更好的效率和准确性。特别是,与普通的 d e p t h w i s e 7 × 7 depthwise7\times 7 depthwise7×7相比,我们的MixConv357(具有3组内核 { 3 × 3 , 5 × 5 , 7 × 7 } \{3\times 3,5\times 5,7\times 7\} {3×3,5×5,7×7})使用更少的参数和FLOPs在MobileNetV1上实现了0.6%更高的mAP,在MobileNetV2上实现了1.1%更高的mAP。

3.4 消融实验
为了更好地理解MixConv,我们提供了一些消融研究:
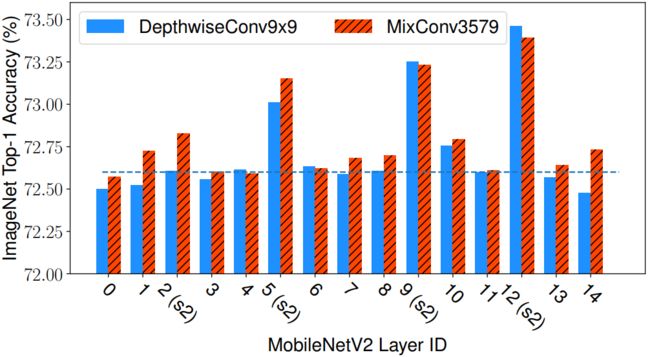
用于单层的MixConv: 除了将MixConv应用于整个网络之外,图5还显示了MobileNetV2上的单层性能。我们用(1)普通的核大小为 9 × 9 9\times 9 9×9的 D e p t h w i s e C o n v 9 × 9 DepthwiseConv9\times 9 DepthwiseConv9×9,或(2)含有4组核: { 3 × 3 , 5 × 5 , 7 × 7 , 9 × 9 } \{3\times 3,5\times 5,7\times 7,9\times 9\} {3×3,5×5,7×7,9×9}的MixConv3579替换这15层中的一层。如图所示,较大的核大小对不同的层有不同的影响:对于大多数层,精度变化不大,但是对于某些具有stride为2的层,较大的核可以显著提高精度。值得注意的是,尽管MixConv3579只使用了普通的 D e p t h w i s e C o n v 9 × 9 DepthwiseConv9\times 9 DepthwiseConv9×9一半的参数和FLOPs,但是我们的MixConv在大多数层上都实现了类似的或者稍微好一点的性能。
通道划分方法: 图6比较了两种通道划分方法:均等划分(MixConv)和指数划分(MixConv+exp)。正如预期的那样,对于相同的核大小,指数划分需要更少的参数和FLOPs,方法是将更多的通道分配给更小的核。我们的实证研究表明,指数通道划分在MobileNetV1上的性能仅略好于均等划分,但如果同时考虑MobileNetV1和V2,则没有明显的赢家。指数划分的一个可能限制是,大卷积核没有足够的通道来捕获高分辨率模式。
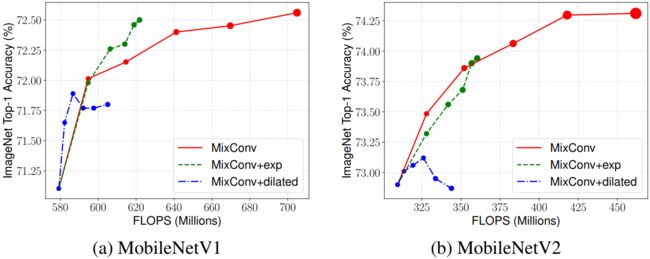
空洞卷积: 图6还比较了膨胀卷积的性能(表示为MixConv+dilated)。对于 K × K K\times K K×K的核大小,它使用一个具有 ( K − 1 ) / 2 (K-1)/2 (K−1)/2空洞率的 3 × 3 3\times 3 3×3核:例如,一个 9 × 9 9\times 9 9×9内核将被一个具有空洞率为4的 3 × 3 3\times 3 3×3核所取代。值得注意的是,由于Tensorflow空洞卷积与stride为2不兼容,所以我们只在stride为1的层上使用空洞卷积。如图所示,空洞卷积对于小核具有合理的性能,但是对于大核精度下降很快。我们的假设是,当大核的空洞率很大时,空洞卷积会跳过很多局部信息,这会影响精度。
4. MixNet
为了进一步证明MixConv的有效性,我们利用神经结构搜索的最新进展,开发了一个新的基于MixConv的模型家族,称为MixNets。
4.1 架构搜索
我们的神经架构搜索设置类似于最近的MnasNet、FBNet和ProxylessNAS,使用MobileNetV2作为基线网络结构,搜索最佳核大小、扩展比、通道大小等设计选择。然而,与之前使用普通深度卷积作为基本卷积运算的工作不同,我们采用我们提出的MixConv作为搜索选项。具体来说,我们有5个MixConv候选组 g = 1 , … , 5 g=1,\ldots,5 g=1,…,5:
- 3 × 3 3\times 3 3×3:带有一组过滤器的MixConv( g = 1 g=1 g=1),核大小为 3 × 3 3\times 3 3×3。
- … \ldots …
- 3 × 3 , 5 × 5 , 7 × 7 , 9 × 9 , 11 × 11 3\times 3,5\times 5,7\times 7,9\times 9,11\times 11 3×3,5×5,7×7,9×9,11×11: MixConv有5组过滤器( g = 5 g=5 g=5),核大小为 { 3 × 3 , 5 × 5 , 7 × 7 , 9 × 9 , 11 × 11 } \{3\times 3,5\times 5,7\times 7,9\times 9,11\times 11\} {3×3,5×5,7×7,9×9,11×11}。 每个组的通道数量大致相同。
为了简化搜索过程,我们没有在搜索空间中包含指数通道划分或空洞卷积,但是在将来的工作中集成它们是很简单的。
与最近的神经结构搜索方法类似,我们直接在ImageNet训练集上搜索,然后从搜索中选择一些表现最佳的模型,以验证它们在ImageNet验证集和迁移学习数据集上的准确性。
4.2 MixNet在ImageNet上的表现
表2显示了MixNets的ImageNet性能。这里我们通过神经结构搜索得到了MixNet-S和M,并利用深度乘数1.3对MixNet-M进行了扩展,得到了MixNet-L。所有模型都使用与MnasNet相同的设置进行训练。
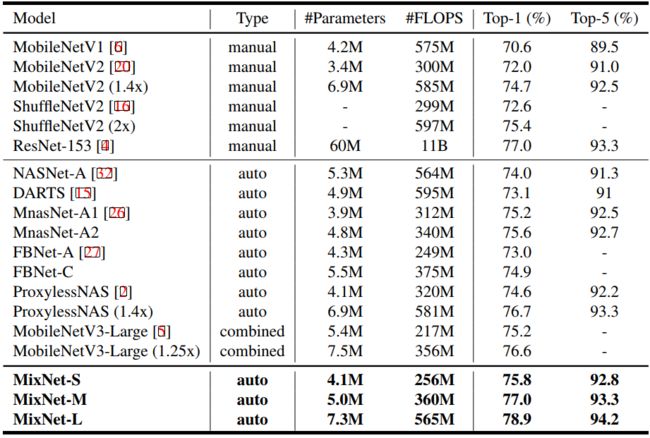
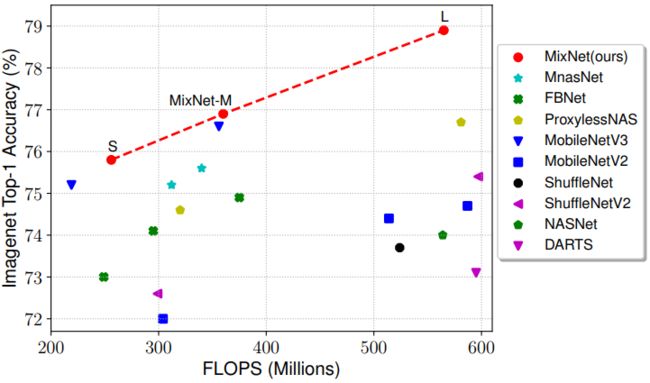
总体而言,我们的MixNets优于所有最新的移动卷积神经网络:与手工设计的模型相比,在相同的FLOPs约束下,我们的MixNets的top-1精度比MobileNetV2提高了4.2%,比ShuffleNetV2提高了3.5%;与最新的自动化模型相比,在相似的FLOPs约束下,我们的MixNet比MnasNet(+1.3%)、FBNets(+2.0%)和ProxylessNAS(+2.2%)的准确率更高。MixNets还实现了与最新的MobileNetV3类似的性能(使用更少的参数),后者是与我们的工作同时开发的,除了架构搜索之外,还进行了几个手工优化。特别值得一提的是,我们的MixNet-L在典型的移动FLOPs(<600M)约束下,实现了78.9%的最先进的top-1精度。与广泛使用的ResNets相比,我们的MixNet-M实现了与ResNet-152相同的77%的top-1精度,但参数减少了12倍,FLOPs减少了31倍。
图7可视化了ImageNet性能比较。我们观察到,与以前手工设计的移动卷积神经网络相比,神经架构搜索的最新进展显著提高了模型性能。然而,通过引入一种新型的高效MixConv,我们可以基于相同的神经结构搜索技术进一步提高模型的准确性和效率。
4.3 MixNet架构
为了理解为什么我们的MixNet能够达到更好的精度和效率,图8说明了表2中MixNet-S和MixNet-M的网络架构。通常,它们都在整个网络中使用各种不同核大小的MixConv:为了节省计算成本,小的卷积核在早期更为常见,而大的卷积核在后期更为常见,以获得更好的准确性。我们还观察到,较大的MixNet-M倾向于使用更大的核和更多的层来追求更高的精度,而代价是更多的参数和FLOPs。与对于较大的核大小会导致严重的精度下降(图1)普通的深度卷积不同,我们的MixNets能够使用非常大的核,比如 9 × 9 9\times 9 9×9和 11 × 11 11\times 11 11×11,从输入图像中捕捉高分辨率的模式,而不会影响模型的精度和效率。

4.4 迁移学习性能
我们还对四种广泛使用的迁移学习数据集进行了评估,包括CIFAR-10/100、Oxford-IIIT Pets和Food-101。表3显示了它们的训练集大小、测试集大小和类数的统计信息。
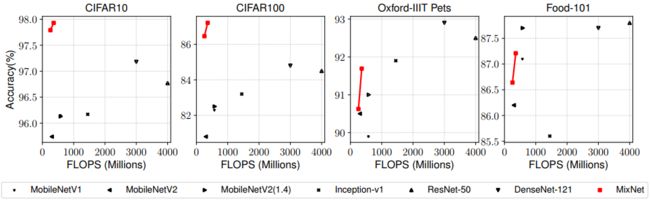
图9将MixNet-S/M与一列以前的模型对迁移学习精度和FLOPs进行了比较。对于每个模型,我们首先在ImageNet上从零开始训练它,然后使用类似于[Do better imagenet models transfer better?]的设置在目标数据集上对所有权重进行微调。MobileNets、Inception、ResNet、DenseNet的精度和FLOPs数据均来自[Do better imagenet models transfer better?]。总的来说,我们的MixNet在所有这些数据集上都明显优于以前的模型,特别是在使用最广泛的CIFAR-10和CIFAR-100上,这表明我们的MixNet也可以很好地推广到迁移学习。特别地,我们的MixNet-M以3.49M的参数和352M的FLOPS实现了97.92%的精度,比ResNet-50提高了1%的精度,效率提高了11.4倍。
5. 结论
在本文中,我们重新讨论了卷积核大小对深度卷积的影响,并指出传统的深度卷积存在单一卷积核大小的限制。为了解决这个问题,我们提出了MixConv,它将多个卷积核混合在一个操作中,以利用不同的核大小。我们证明了我们的MixConv是普通的深度卷积的一个简单的直接替代,并提高了MobileNets在图像分类和目标检测任务上的准确性和效率。基于我们提出的MixConv,我们进一步利用神经结构搜索技术开发了一个新的MixNet家族。实验结果表明,我们的MixNet在ImageNet分类和四种广泛使用的迁移学习数据集上都比所有最新的移动卷积神经网络具有更好的精度和效率。
个人看法
这篇文章最重要的创新点在于多种尺寸的卷积核的混用,也就是提出的MixConv操作,不过这种混合多种卷积核的操作我在SqueezeNet里面也有见过,不同的是SqueezeNet里面是为了降低参数量而用 1 × 1 1\times 1 1×1卷积核替代了部分 3 × 3 3\times 3 3×3卷积核,而且用的还是普通卷积。然后在Inception系列里这种不同大小卷积核混用的也早就有了,只是用的还是普通卷积而且没有对通道做分组(也就是以分支形式,在不同分支用不同大小的卷积核,每个分支都会处理输入的所有通道)。MixConv的结构可以看做是结合运用了分组深度卷积与Inception结构的不同尺寸卷积核混用两个特点而成的吧。最近NAS搜出来的结构越来越多用到了 5 × 5 5\times 5 5×5以上的大卷积核,或许也是一种提高精度的趋势吧,对于手工设计来说决定各个层用什么尺寸的卷积核可能还是略显复杂了点。。。