C++之沧海拾遗
这篇博客是本人总结的一些细节问题,大佬们想必都了解,但想到还有千千万万和本人一样执着于细节的同志,我决定把这些知识点逐个记录下来。
本篇博客既然为拾遗,内容还是比较杂的,主要包括以下几方面:1)友元类和友元函数,2)静态成员变量及静态成员函数,3)常成员变量、常成员函数及常对象,4)引用成员变量初始化,5)浅度拷贝和深度拷贝,6)is-a、has-a和use-a关系,7)public和private继承的区别和作用,8)volatile关键字,9)嵌套类和局部类,10)基类析构函数为何是虚函数,11)嵌套宏展开。诸君切勿着急,且听我娓娓道来:
1.友元类和友元函数
类的定义除了对自己本身做介绍外(声明自己的成员变量和成员函数),还需要介绍一下自己的朋友们(既然我把你当朋友,那对别人而言不可见的保护成员和私有成员,自然也就可以拿出来一起分享了),这些朋友们就称为友元类和友元函数。需要注意的是类A是类B的友元,并不代表类B就是累A的友元了(类B把类A当朋友,而类A却不把类B当朋友)。
由于友元类和友元函数并不属于本类,而是在类外定义和实现的,因此有:1)友元关系不可以被继承;2)友元函数不属于public、protected和private中的任何一个,因此可以放在任意一个权限修饰符下。
下面让我来举个关于友元类和友元函数的小程序吧。
#include
using namespace std;
class B;
class A;
void Show( A& , B& );
class B
{
private:
int tt;
friend class A;
friend void Show( A& , B& );
public:
B( int temp = 100):tt ( temp ){}
};
class A
{
private:
int value;
friend void Show( A& , B& );
public:
A(int temp = 200 ):value ( temp ){}
void Show( B &b )
{
cout << value << endl;
cout << b.tt << endl;
}
};
void Show( A& a, B& b )
{
cout << a.value << endl;
cout << b .tt << endl;
}
int main()
{
A a;
B b;
a.Show( b );
Show( a, b );
return 0;
} main函数最终输出的结果应该是:200,100,200,100。
让我们来分析一下这段代码,在此处,类B声明了类A是其友元类,全局函数show是其友元函数,因此A中的show函数A::show()和全局函数show()都能访问B类对象的私有数据成员tt;类A也将全局函数show声明为其友元函数,故全局函数show()也能访问A类对象的私有数据成员value。
友情提醒:类的定义后需要加";"。以前经常忘记,然后莫名其妙报错。
2.静态成员变量及静态成员函数
2.1 静态成员变量
静态成员变量的声明和定义:
- 静态成员变量在类的内部声明,声明时直接通过static关键字修饰;
- 静态成员变量在类的外部定义与初始化,定义时不再需要static关键字,语法规则为Type ClassName::VarName = value;。
静态成员变量具有如下特点:
- 静态成员变量不占用类的大小,而是在类外的全局数据区单独分配空间;
- 静态成员变量属于整个类所有,所有对象共享类的静态成员变量;
- 可以通过类名和对象名访问public的静态成员变量;
- 静态成员变量的生命周期不依赖于任何对象,是全生命周期的。
2.2 静态成员函数
静态成员函数具有如下特点:
- 可以通过类名和对象名调用public静态成员函数;
- 静态成员函数只能访问静态成员变量和静态成员函数。(思考一下为什么?因为静态成员函数可以被类名调用,而通过类名是访问不了非静态成员变量/函数的)
3.常成员变量、常成员函数及常对象
3.1 常成员变量
使用关键字const来修饰常成员变量,const位于类型前和变量前都一样,如下所示:
class rect
{
public:
rect(int i, int j):length(i),width(j){} //常成员变量必须在构造函数的初始化列表里初始化
const int length; //常成员变量,const位于类型前
int const width; //常成员变量,const位于变量前
};常成员变量特点:
- 常成员变量必须在构造函数的初始化列表里初始化,这一点在上方的代码块中得到了体现;
- 常成员变量可以像普通成员变量一样被访问,但是其值不能被修改。
3.2 常成员函数
用const来修饰常成员函数,需要将const关键字放在函数括号后面,并且声明和定义的地方都要加const,如下所示:
class rect
{
public:
rect(int i, int j):length(i),width(j){} //常成员变量必须在构造函数的初始化列表里初始化
const int length; //常成员变量,const位于类型前
int const width; //常成员变量,const位于变量前
int ClacArea()const; //常成员函数,const位于括号后
};
//常成员函数在定义时,也要将const放在括号后
int rect::CalcArea()const
{
return length*width;
}常成员函数特点:
- 常成员函数可以通过this指针访问所有成员变量(包括常成员变量和非常成员变量),但不能修改this指针访问的成员变量;
- 常成员函数可以通过this指针调用常成员函数,但不能调用非常成员函数。
3.3 常对象
定义常对象的形式为:
const 类名 对象名(实参列表) 或 类名 const 对象名(实参列表)。如下所示:
class Demo
{
public:
...
Demo();
Demo(int i);
...
};
/* 常对象的定义 */
const Demo D1;
Demo const D2;
const Demo D3(100);
Demo const D4(200);常对象具有如下特点:
- 常对象中所有成员变量的值都不能修改;
- 常对象只能调用常成员函数。(思考一下为什么?因为常成员函数中不能修改成员变量的值,这与常对象特点1刚好吻合。常对象若能调用非常成员函数,那么就有可能改动成员变量的值,这与常对象特点1矛盾)
备注:这里插播一下,访问修饰符、static、virtual关键字在类的定义中标明即可,在类外实现时不必再标明。但const关键字无论是在类内还是类外都要标明。
4.引用成员变量的初始化
引用成员变量需要注意一下几点:
- 引用成员变量必须在构造函数的初始化列表内完成初始化;
- 构造函数中初始化引用成员变量的形参也必须为引用类型。
引用成员变量示例如下:
class Ref
{
public:
// 构造函数形参为传值,不能保证正确性
// Ref (int target) :myref(target) {}
// 函数体对引用赋值,编译错误:引用未初始化
// Ref (int &target)
// {
//myref = target;
// }
// 如果成员为变量为引用类型,那么构造函数的参数为引用类型
// 引用必须在构造函数初始化列表里初始化,不能在函数体内初始化
// 在函数体里面修改myref,相当于赋值,显然引用不能赋值
Ref (int &target) :myref(target) {}
private:
int &myref;
};5.浅度拷贝和深度拷贝
首先,我引入一些题外话。在C++的类中,包含这么几个缺省的成员:默认的构造函数、默认的析构函数、默认的拷贝构造函数、默认的赋值运算符。它们的形式如下所示:
class programmer
{
public:
programmer(); //默认构造函数
~programmer(); //默认析构函数
programmer(const programmer& p1); //默认拷贝构造函数
void operator=(const programmer& p1); //默认赋值运算符
}
int main()
{
programmer p1,p2;
p1 = p2; //调用默认赋值运算符
programmer p3;
programmer p4 = p3; //调用拷贝构造函数
}其中,默认的拷贝构造函数和赋值运算符都涉及到拷贝,且它们默认是浅度拷贝。
5.1 浅度拷贝
浅度拷贝就是无脑地、原封不动地将源对象所在内存中的全部数据拷贝至目标对象所在内存。这在一般情况下是没有问题的,但如果类中的数据成员包含指针,浅度拷贝就会产生问题。具体会产生什么问题呢?我通过下面的例子进行分析。
class A
{
public:
A() //构造函数
{
cout << "A() called !" << endl;
x = 1;
p = new int; //堆上申请内存
cout << "Constructed called!" << endl;
}
~A() //析构函数
{
cout << "~A() called !" << endl;
delete p; //销毁p
p = NULL;
cout << "Destructed !" << endl;
}
private:
int x;
int* p;
};
int main()
{
A a; //构造对象a
A b = a; //拷贝构造对象b
return 0;
}
问题1:由于使用的是默认的拷贝构造函数,所以A类对象a被浅度拷贝给了A类对象b,对象a和对象b中的指针成员变量p都指向了同一片内存。此时,若通过对象a改变了p所指向内存中的数据,那么对象b中p指向的数据也同步发生了改变,这显然是不合理的。比如A类代表人类,指针成员变量p指向的内存代表年龄,我修改了a的年龄后,b的年龄也跟着改变了,这是不符合常理的。
问题2:运行这段程序后,会引发一个如下图所示的严重问题。可以看到,如果正常的话,这里在“~A() called!”后应当还有一个“Destructed”,因此引发问题的时期是对象b调用delete p;这一句进行析构时,为什么会有问题呢?还是默认浅拷贝导致的。
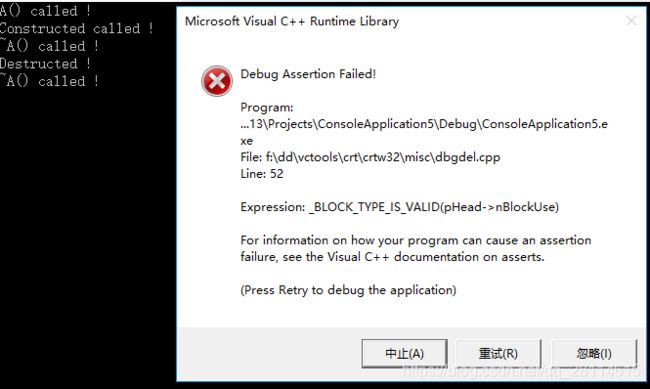
构造对象a时,动态为a.p申请了内存,a.p也就存放了一个有效的地址,而当b浅拷贝a时,b.p又被赋值为了a.p,也就是说a.p和b.p是指向的同一个地方,当main函数结束时,先析构对象a,此时就把p销毁掉了,a.p所指的地址也被释放了,然后再析构对象b,也要去释放b.p所指的内存,而此时这片内存早已在a.p销毁时被释放了,这就引发了二次析构,自然就报错了。
因此,当类中存在指针成员变量时,需要自己实现一个深度拷贝的拷贝构造函数和赋值运算符。
5.2 深度拷贝
为了避免浅度拷贝引发的问题,需要自己定义一个深度拷贝的拷贝构造函数。在实现该拷贝构造函数时,对于相应的指针成员变量,需要重新开辟空间,以上面引发二次析构的程序为基础,自定义一个深度拷贝的拷贝构造函数,如下所示:
class A
{
public :
A()
{
cout << "A() called !" << endl;
x = 1;
p = new int;
(*p) = 2;
cout << "Constructed !" << endl;
}
~A()
{
cout << "~A() called !" << endl;
delete p;
p = NULL;
cout << "Destructed !" << endl;
}
A(const A& a) //自定义拷贝构造函数(深拷贝)
{
cout << "A() copy called !" << endl;
x = a.x; //拷贝a.x
p = new int; //重新开辟空间
*(p) = *(a.p); //拷贝*(a.p)
cout << "Copy constructed !" << endl;
}
int x;
int* p;
};
int main()
{
A a; //构造对象a
A b = a; //拷贝构造对象b
cout << a.x << " " << a.p << " " << *(a.p) << endl; //输出a的数据成员以及a.p指向的值
cout << b.x << " " << b.p << " " << *(b.p) << endl; //输出b的数据成员以及b.p指向的值
system("pause");
return 0;
}运行结果如下:
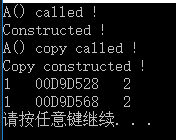
可见,这样一来a.p和b.p的值就不一样了,也就是说二者之一改变也不会影响另一个,析构时也不会引发二次析构问题,这种在自定义拷贝构造函数中重新分配内存再拷贝的方式就是深度拷贝。
6.is-a、has-a和use-a关系
is-a、has-a和use-a都是用来表述类与类之间关系的,下面我分别来介绍。
6.1 is-a关系
is-a关系是继承关系。继承包含接口继承(public继承)和实现继承(private继承),这里指的是接口继承关系(在接口继承中,子类是更特殊的父类,父类是一般化的子类,所以可以说“子类 is a 父类”)。
举个例子:男人(Man)是人(Human)的一种,女人(Woman)也是人的一种,那么类Man 可以从类Human 派生,类Woman也可以从类Human 派生。示例程序如下:
class Human
{
…
};
class Man : public Human
{
…
};
class Woman : public Human
{
…
};
6.2 has-a关系
has-a关系表示聚合关系,是整体与部分间的关系,整体与部分拥有相同的生命周期。例如眼(Eye)、鼻(Nose)、口(Mouth)、耳(Ear)是头(Head)的一部分,所以类Head 与类Eye、Nose、Mouth、Ear 之间是has-a关系。has-a关系可以通过包含(也称为组合)和私有继承来实现。
所谓的包含就是将Eye、Nose、Mouth、Ear 对象作为Head 类的数据成员,即新的类A包含另一个类B的对象。此时,新的类A就可以通过包含的B类对象调用B类的public方法。示例程序如下:
class Eye
{
public:
void Look(void);
};
class Nose
{
public:
void Smell(void);
};
class Mouth
{
public:
void Eat(void);
};
class Ear
{
public:
void Listen(void);
};
// 通过包含实现has-a关系
class Head
{
public:
void Look(void) { m_eye.Look(); }
void Smell(void) { m_nose.Smell(); }
void Eat(void) { m_mouth.Eat(); }
void Listen(void) { m_ear.Listen(); }
private:
Eye m_eye;
Nose m_nose;
Mouth m_mouth;
Ear m_ear;
};使用私有继承,基类(Eye、Nose、Mouth、Ear 类)的公有成员和保护成员都将成为派生类(Head类)的私有成员。这意味着基类方法将不会成为派生对象公有接口的一部分,但可以在派生类的成员函数中使用它们。示例程序如下:
class Eye
{
public:
void Look(void);
};
class Nose
{
public:
void Smell(void);
};
class Mouth
{
public:
void Eat(void);
};
class Ear
{
public:
void Listen(void);
};
// 私有继承实现is-a关系
class Head:private Eye, private Nose, private Mouth, private Ear
{
public:
void Look(void) { Eye::Look(); }
void Smell(void) { Nose::Smell(); }
void Eat(void) { Mouth::Eat(); }
void Listen(void) { Ear::Listen(); }
};
那么,何时使用包含,何时使用private继承来实现has-a关系呢?大部分时候我们倾向于前者。不过,private继承所提供的特性确实比包含多。假设被包含类包含保护成员,使用private继承,派生类(包含类)仍然可以访问这个保护成员;若使用包含,则无法通过包含的类对象去访问这个保护成员。另一种需要使用私有继承的情况是重新定义虚函数,通过private继承,派生类可以重新定义虚函数,而使用包含类不能。
6.3 use-a关系
它是一种依赖关系。类A的方法操作了B类对象的成员,则称之为类A“use-a”(用到了)类B。类A虽然用到了B类对象,但并不负责销毁B类对象,也就是说生命周期并不一样。接下来看一个综合示例,把以上三者再梳理一遍:
#include
using namespace std;
class A
{
public:
void funcA()
{
cout<< "funcA" <x;
}
private:
int x;
};
class B
{
public:
void funcB()
{
cout<< "funcB" < 7.public和private继承的区别和作用
初学C++时,只知道private继承会将继承来的成员的可访问性都变成private,目的是不让这些成员被以后的子类继续继承。但经过仔细的思考、查找资料和论证,发现private继承的本质远不止如此。
public继承塑造出的是一种is-a关系,是一种接口继承。如果你令class Derived以public形式继承class Base,那么每一个类型为Derived的对象同时也是一个类型为Base的对象,反之不成立。意思是Base比Derived表现出更一般化的概念,而Derived比Base表现出更特殊化的概念。你主张:Base对象可派上用场的地方,Derived对象一样可以派上用场。因为每一个Derived对象都是一个Base对象,可以调用从Base类继承的接口(这里指Base类中可访问性为public的成员方法)。反之如果你需要一个Derived对象,Base对象无法效劳。
private继承塑造出的是一种has-a关系(has-a关系还可以通过包含实现,至于何时用private继承,何时用包含,参见上一章内容),是一种实现继承,它无法支持多态。
- 何谓实现继承?即你的用意是为了在Derived类中采用Base类中已备好的某些特性,而不是说Derived类与Base类存在任何观念上的关系。private继承是一种纯粹的实现技术,意味着只有实现部分被继承(Derived可以使用Base中实现的方法),而忽略了接口(Base中的public方法(接口)被private继承到Derived类后,全部转变为private方法,用户无法通过Derived对象访问这些接口)。
- private继承为何无法支持多态?比如,让class Derived以private形式继承class Base,编译器不会自动将Derived对象转化为Base对象,即Base *pB = new Derived();这句话是编译不通过的(因为Derived与Base不存在任何观念上的关系,即Derived对象不能被当作Base对象,Derived只是为了使用Base中写好的方法而去private继承它的),因此无法实现多态。
下面通过一个具体例子,形象地理解private继承:
class PersonInfo{
public:
explicit PersonInfo(DatabaseID pid);
virtual ~PersonInfo();
virtual const char* theName() const;
virtual const char* theBirthDate() const;
...
private:
virtual const char* valueDelimOpen() const{return "["}; //“开始”符号,用于姓名的输出
virtual const char* valueDelimClose() const{return "]"}; //“结束”符号
...
};
const char* PersonInfo::theName() const{
static char value[Max_Formatted_Field_Value_Length]; //保留缓冲区给返回值使用。注意由于缓冲区是static的,会被自动初始化为“全部是0”
std::strcpy(value, valueDelimOpen()); //写入起始符号
... //添加姓名
std::strcat(value, valueDelimClose()); //写入结束符号
return value;
}
class CPerson : private PersonInfo{
public:
std::string name()const
{return PersonInfo::theName();}
std::string birthDate()const
{return PersonInfo::theBirthDate();}
private:
virtual const char* valueDelimOpen() const{return ""};
virtual const char* valueDelimClose() const{return ""};
...
};我希望实现一个类CPerson,它能提取人的姓名name和生日birthdate。我想偷个懒,发现有这么一个类PersonInfo,能实现差不多的功能,只是返回结果的格式有点不符合我的要求。此时让CPerson私有继承PersonInfo,可以发现:
- 类CPerson的name方法可以通过调用类PersonInfo的成员方法实现。Cperson中使用了PersonInfo的实现,却没有给用户提供调用类PersonInfo成员的接口(因为是private继承)。
- 由于PersonInfo返回结果的格式不符合我的要求(它使用方括号[ ]包裹返回结果,我却不想要方括号),而控制格式的两个函数valueDelimOpen和valueDelimClose是虚函数, 所以我就可以通过在Cperson中重写这两个虚函数,修改返回结果的格式。