Self-paced Multi-grained Cross-modal Interaction Modeling for Referring Expression Comprehension论文阅读
Self-paced Multi-grained Cross-modal Interaction Modeling for Referring Expression Comprehension论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- A、指代表达式理解
- B、Transformer
- C、自定进度学习
- 四、方法
-
- A、动机和框架总览
- B、多粒度跨模态注意力
-
- 1)跨模态交替注意力模块 Cross-modal Alternate Attention Module (CA^2^M)
- 2)跨模态交互分组和融合
- C、自定进度样本信息学习
- D、优化
- 五、实验
-
- A、数据集和评估指标
-
- 数据集
- 评估指标
- B、实施细节
-
- 训练
- 推理
- C、与 SOTA 方法的比较
- D、消融实验
-
- 1)视觉和语言特征数量的影响
- 2)CA^2^M 数量的影响
- 3) λ \lambda λ 和 σ \sigma σ 的影响
- 4)CA^2^M 和 Transformer 编码器层的比较
- E、定性结果
- 六、结论
写在前面
又是一周快过去了,哎,时间过得很快呀。这是一篇 REC 的文章,由于没放出代码,不好评价这个效果,尤其一些实验数据,感觉有点不可思议了。
- 论文地址:Self-paced Multi-grained Cross-modal Interaction Modeling for Referring Expression Comprehension
- 代码地址:原文暂未提供
- 预计提交于:某个会议
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
指代表达式理解 referring expression comprehension (REC) 通常需要大量的多粒度视觉-语言模态的信息来实现精确推理,此外一些难样本有着更多的信息。于是本文提出自定进度的多粒度跨模态交互建模 Self-paced Multi-grained Cross-modal Interaction Modeling。具体来说,设计一种基于 Transformer 的多粒度跨模态机制,提出一种自定进度的样本信息学习方法来增强网络对信息丰富的样本的学习能力。实验效果很好。
二、引言
首先指出 REC 的目的,意义,应用。接下来指出 REC 网络需要的定位能力,大白话修饰语句就不解读了。视觉编码器,例如 ResNet,在更深层时捕捉语义信息,而在浅层时捕捉详细信息。如下图中的注意力图所示:

与此同时,基于 Transformer 的语言编码器,例如 BERT 等,能够在浅层时捕捉短语级别的信息,而在高层时捕捉句子级别的信息。因此需要从这些模态中聚合多粒度信息,并执行跨模态交互。于是设计基于 Transformer 的多粒度跨模态注意力,逐渐且自适应地实现多粒度视觉和语言模态的交互。
对多粒度信息样本的充分学习也能促进多粒度跨模态交互。然而很难去直观衡量多粒度信息以及自适应样本学习的策略。于是本文利用定位的难易程度来反应多粒度信息的数量以及每个样本学习的必要性。具体来说,设计了一种自定的样本信息学习,能够让网络衡量训练样本的难易得分,从而自适应地驱动网络获得包含多粒度信息的样本知识。
具体来说,设计了一种基于 Transformer 的多粒度跨模态注意力,通过提出的多模态的交互交换注意力模块 cross-modal alternate attention module (CA2M) 实现分组和融合。进一步在每次训练迭代过程中,基于当前的网络为每个样本输出难易程度得分,于是网络能够自适应的从这些样本中学习到多粒度信息。大量实验表明方法很有效,且推理速度很快。如下图所示:

贡献总结如下:
- 提出一种自定速度的多粒度跨模态交互建模框架 Self-paced Multi-grained Cross-modal Interaction Modeling framework,在网络结果和学习机制上的创新提升了定位性能;
- 构建了一种多粒度跨模态注意力机制,设计了一种自定进度的样本信息学习策略,能够自适应地驱动网络学习多粒度样本信息;
- 实验表明方法效果很好。
三、相关工作
A、指代表达式理解
之前传统的 REC 方法包含两个阶段:产生候选 Box,选择最匹配的 Box。在第一阶段,通过预训练的目标检测器,例如 Faster-RCNN 生成大量的候选 boxes,第二阶段挑选出最佳候选的 box 作为目标 box。然而受限于 Box、匹配的正确度、表达式,此类方法精度和速度达不到要求。最近一些方法通过设计视觉-语言融合模块来直接预测目标 box,但是忽略了多粒度视觉语言编码器中信息的利用。于是本文提出一组多粒度跨模态注意力来提炼视觉语言编码器中的多粒度信息。
B、Transformer
基于 Transformer 的方法在自然语言处理任务中性能非常好,之后用于视觉任务中,例如图像分类,目标检测,全景分割等,还有一些基于 Transformer 的预训练模型用于视觉-语言任务。Transformer 中的注意力机制能够捕捉上下文的长范围依赖以及跨模态 tokens 间的关联。相比于这些 Transformer,本文提出的 CA2M 能够充分地进行多粒度跨模态交互且实现更准确定位的同时,推理速度更快。
C、自定进度学习
自定进度学习采用当前的训练网络来衡量样本的难易度进行目标学习。自定进度学习可以在训练过程中动态实现样本的学习。正因为 REC 数据集中样本的分布不均,本文旨在设计自定进度样本信息学习来自适应地实现网络的渐进学习。
四、方法
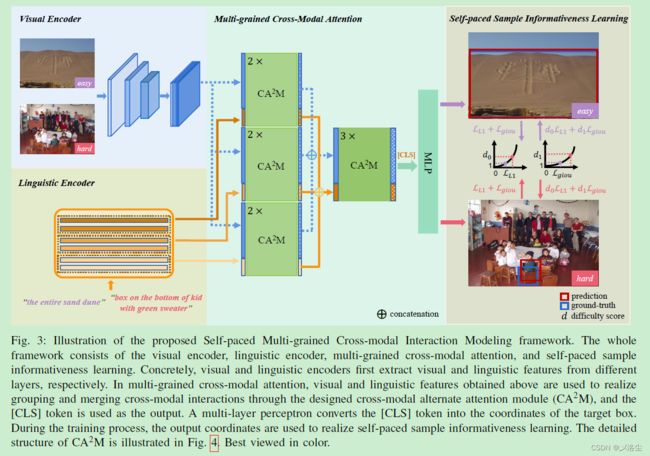
A、动机和框架总览
REC 通常需要大量的多粒度信息来实现定位。由于视觉和语言编码器在不同的层次上处理多粒度信息,且复杂样本通常包含充分的细粒度信息,于是本文提出自定进度的跨模态交互建模框架,通过多粒度跨模态注意力和自定进度的样本信息学习来提升推理能力。(这个故事讲的有点牵强,估计还是先有结果再有故事吧。)
给定一幅图像和一个指代表达式,本文旨在直接回归出目标 box 的坐标。基于 ResNet 的视觉编码器和基于 BERT 的语言编码器首先从不同的层中提取多粒度信息,然后在多粒度跨模态注意力中,通过设计的跨模态交替注意力模块 CA2M,获得的视觉语言特征用于实现跨模态交互的分组和融合,而 [CLS] token 用于输出。预测头由三层感知机组成,将 [CLS] token 转化为 box 的坐标。在每次的训练迭代过程中,自定进度的样本信息学习计算每个样本的难度得分,指导网络增进对具有充分多粒度信息的样本的学习。
B、多粒度跨模态注意力

1)跨模态交替注意力模块 Cross-modal Alternate Attention Module (CA2M)
实际上就是两个 Cross-attention 模块。
CA2M 核心组成是注意力模块,其输入源于视觉和语言模态的 token 序列。开始时采用的全连接模块:
Q = X q W q , K = X s W k , V = X s W ν Q=X^{q}W^{q},\quad K=X^{s}W^{k},\quad V=X^{s}W^{\nu} Q=XqWq,K=XsWk,V=XsWν其中 W q W^{q} Wq、 W k W^{k} Wk、 W v W^{v} Wv 分别是 query、key、value 的可学习权重, X q X^{q} Xq、 X s X^{s} Xs 来源于不同的模态。接下来:
C r o s s A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K ⊤ d d i m ) V \mathrm{CrossAttention}(Q,K,V)=\mathrm{Softmax}(\frac{QK^{\top}}{\sqrt{d_{\mathrm{dim}}}})V CrossAttention(Q,K,V)=Softmax(ddimQK⊤)V其中 d dim d_{\text{dim}} ddim 为 embeddings 的通道维度。
视觉语言特征融合过程如图 4 所示。具体来说,给定视觉特征 F v F_v Fv 和语言特征 F l F_l Fl。CA2M 首先拿 F v F_v Fv 和 F l F_l Fl 作为 X q X^q Xq 和 X s X^s Xs,然后有:
F ν ∗ = L N ( F ν + M H C A ( F ν , F l ) ) F ν ′ = L N ( F ν ∗ + F F N ( F ν ∗ ) ) \begin{aligned}F_{\nu}^{*}&=\mathrm{LN}(F_{\nu}+\mathrm{MHCA}(F_{\nu},F_{l}))\\\\F_{\nu}^{'}&=\mathrm{LN}(F_{\nu}^{*}+\mathrm{FFN}(F_{\nu}^{*}))\end{aligned} Fν∗Fν′=LN(Fν+MHCA(Fν,Fl))=LN(Fν∗+FFN(Fν∗))其中 L N \mathrm{LN} LN, M H C A \mathrm{MHCA} MHCA, F F N \mathrm{FFN} FFN 分别表示层归一化,多头注意力,前项传播网络。在获得 F v ′ F_v^{\prime} Fv′ 后,CA2M 分别将 F l F_l Fl 和 F v ′ F_v^{\prime} Fv′ 视为 X q X^q Xq 和 X s X^s Xs,从而获得特征 F l ′ F_l^{\prime} Fl′:
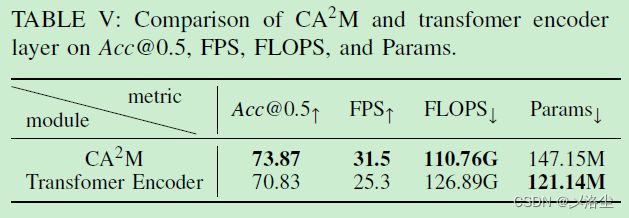
F l ∗ = L N ( F l + M H C A ( F l , F ν ′ ) ) F l ′ = L N ( F l ∗ + F F N ( F l ∗ ) ) \begin{aligned}F_l^*&=\mathrm{LN}(F_l+\mathrm{MHCA}(F_l,F_\nu^{'}))\\F_l^{'}&=\mathrm{LN}(F_l^*+\mathrm{FFN}(F_l^*))\end{aligned} Fl∗Fl′=LN(Fl+MHCA(Fl,Fν′))=LN(Fl∗+FFN(Fl∗))相比于 Transformer 编码器层,CA2M 效率更高:
最后,将 CA2M 作为多粒度跨模态注意力的核心组成部分,来实现下面跨模态交互的分组和融合。
2)跨模态交互分组和融合
基于 ResNet 的视觉编码器从最后三个阶段中提取出视觉特征,之后通过下采样或上采样操作拼接得到视觉特征 F v 0 ∈ R ( H W ) × C 1 F_v^0\in \mathbb{R}^{(HW)\times C_1} Fv0∈R(HW)×C1。基于 6 层的 BERT 将每两层视为一个 Block,提取出具有相同维度 L × C 1 L\times C_1 L×C1 的三个语言特征 { F l , i 0 } i = 1 3 \{F_{l,i}^0\}^3_{i=1} {Fl,i0}i=13,其中 L L L 和 C 1 C_1 C1 分别表示长度和通道。在分组跨模态交互中, F v 0 F_v^0 Fv0 和 F l , i 0 F_{l,i}^0 Fl,i0 分别通过两层的 CA2M 进行交互。
在完成第一阶段的多粒度跨模态注意力后,得到 { F v , i 1 , F l , i 1 } i = 1 3 \{F_{v,i}^{1},F_{l,i}^{1}\}_{i=1}^{3} {Fv,i1,Fl,i1}i=13,其维度分别为 ( H W ) × C 0 (HW)\times C_0 (HW)×C0 和 L × C 0 L\times C_0 L×C0。在分组跨模态交互中,首先拼接 { F v , i 1 , F l , i 1 } i = 1 3 \{F_{v,i}^{1},F_{l,i}^{1}\}_{i=1}^{3} {Fv,i1,Fl,i1}i=13 得到 F v 2 ∈ R ( H W ) × C 1 F_{v}^{2}\in\mathbb{R}^{(HW)\times C_{1}} Fv2∈R(HW)×C1 和 F l 2 ∈ R L × C 1 F_{l}^{2}\in\mathbb{R}^{L\times C_{1}} Fl2∈RL×C1。之后三层的 CA2M 用于执行第二阶段的多粒度跨模态注意力,得到 F v 3 ∈ R ( H W ) × C 1 F_{v}^{3}\in\mathbb{R}^{(HW)\times C_{1}} Fv3∈R(HW)×C1 和 F l 3 ∈ R L × C 1 F_{l}^{3}\in\mathbb{R}^{L\times C_{1}} Fl3∈RL×C1。最后从 F l 3 F_l^3 Fl3 中得到的 [CLS] 经过三层感知机后预测目标 Box b ^ = ( x ^ , y ^ , w ^ , y ^ ) \hat b=(\hat x,\hat y,\hat w,\hat y) b^=(x^,y^,w^,y^)。
C、自定进度样本信息学习
在训练的每次迭代过程中,采用 L1 损失和通用的 IoU 损失两个角度来衡量每个样本的难度。给定 GT b = ( x , y , w , h ) b=(x,y,w,h) b=(x,y,w,h) 和预测的目标 box b ^ = ( x ^ , y ^ , w ^ , h ^ ) \hat b=(\hat x,\hat y,\hat w,\hat h) b^=(x^,y^,w^,h^),L1 损失为:
L L 1 = ∣ x − x ^ ∣ + ∣ y − y ^ ∣ + ∣ w − w ^ ∣ + ∣ h − h ^ ∣ {\mathcal L}_{L1}=|x-\hat x|+|y-\hat y|+|w-\hat w|+|h-\hat h| LL1=∣x−x^∣+∣y−y^∣+∣w−w^∣+∣h−h^∣进一步将矩形框 b b b 和 b ^ \hat b b^ 表示为 A A A 和 B B B,通用 IoU 损失为:
L g i o u = 1 − ∣ A ∩ B ∣ ∣ A ∪ B ∣ + ∣ C − A ∪ B ∣ ∣ C ∣ \mathcal{L}_{\mathrm{g}iou}=1-\frac{|A\cap B|}{|A\cup B|}+\frac{|C-A\cup B|}{|C|} Lgiou=1−∣A∪B∣∣A∩B∣+∣C∣∣C−A∪B∣其中 C C C 表示 A A A 和 B B B 的最小内接矩形, ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示区域的面积。不难发现 L L 1 {\mathcal L}_{L1} LL1 和 L g i o u \mathcal{L}_{\mathrm{g}iou} Lgiou 的最小值都是 0。而 L L 1 {\mathcal L}_{L1} LL1 和 L g i o u \mathcal{L}_{\mathrm{g}iou} Lgiou 越小,表明当前样本越容易。
在得到 L L 1 {\mathcal L}_{L1} LL1 和 L g i o u \mathcal{L}_{\mathrm{g}iou} Lgiou 后,使用 D ( ⋅ ) \mathcal{D}(\cdot) D(⋅) 生成难度得分 d 0 d_0 d0 和 d 1 d_1 d1 引导网络学习样本,于是有:
d 0 = D μ 0 , σ 0 ( L L 1 ) , d 1 = D μ 1 , σ 1 ( L g i o u ) d_{0}=\mathcal{D}_{\mu_{0},\sigma_{0}}(\mathcal{L}_{L1}),\quad d_{1}=\mathcal{D}_{\mu_{1},\sigma_{1}}(\mathcal{L}_{giou}) d0=Dμ0,σ0(LL1),d1=Dμ1,σ1(Lgiou)具体而言,对于每个 L \mathcal L L,其对应的难度得分 d d d 定义为一个指数函数:
d = D μ , σ ( L ) = e ( L − μ ) 2 σ 2 d=\mathcal{D}_{\mu,\sigma}(\mathcal{L})=e^{\frac{(\mathcal{L}-\mu)^{2}}{\sigma^{2}}} d=Dμ,σ(L)=eσ2(L−μ)2其中 μ \mu μ 表示位置, σ \sigma σ 控制着函数的宽度。当 L L 1 {\mathcal L}_{L1} LL1 和 L g i o u \mathcal{L}_{\mathrm{g}iou} Lgiou 越接近 0 0 0 时,样本的定位精度越高,于是设置 μ 0 \mu_0 μ0 和 μ 1 \mu_1 μ1 为 0。此外, σ 0 \sigma_0 σ0 和 σ 1 \sigma_1 σ1 是可学习的参数,其值越大时,函数越光滑。在每次训练迭代过程中,从上述的难度得分 d 0 d_0 d0 和 d 1 d_1 d1 中使用 d 0 L L 1 d_0{\mathcal L}_{L1} d0LL1 和 d 1 L g i o u d_1\mathcal{L}_{\mathrm{g}iou} d1Lgiou 用于自定进度的样本信息学习。
D、优化
总体损失如下:
L t o t a l = d 0 L L 1 + d 1 L g i o u − λ ( d 0 + d 1 ) \mathcal{L}_{total}=d_{0}\mathcal{L}_{L1}+d_{1}\mathcal{L}_{giou}-\lambda(d_{0}+d_{1}) Ltotal=d0LL1+d1Lgiou−λ(d0+d1)其中 λ \lambda λ 为归一化系数, λ ( d 0 + d 1 ) \lambda(d_{0}+d_{1}) λ(d0+d1) 为控制 σ 1 \sigma_1 σ1 和 σ 1 \sigma_1 σ1 的常数。
五、实验
A、数据集和评估指标
数据集
RefCOCO、RefCOCO+、RefCOCOg、ReferItGame。
评估指标
A c c @ 0.5 [email protected] Acc@0.5:当 GT 和预测 Box 的 IoU 超过 0.5 时,即为正确,最后统计平均得分。此外还包含推理速度。
B、实施细节
训练
AdamW 优化器,权重衰减 1 e − 4 1e-4 1e−4,ResNet-50 或 ResNet-101 预训练在 MC-COCO 上用于视觉编码器,未级联的 6 层 BERT 用于语言编码器。 σ 0 \sigma_0 σ0、 σ 1 \sigma_1 σ1 初始化为 2.5, λ \lambda λ 0.75, H H H、 W W W 分别缩小为原图的 16 倍。 C 0 C_0 C0 和 C 1 C_1 C1 分别为 256,768。视觉和语言编码器的初始学习率设为 1 e − 5 1e-5 1e−5, σ 0 \sigma_0 σ0、 σ 1 \sigma_1 σ1 的学习率设为 5 e − 5 5e-5 5e−5,剩下的模块设为 1 e − 4 1e-4 1e−4。模型训练 120 个 epoch,Batch_size 192,其中学习率在第 10 和第 80 个 epoch 时衰减 10%。在大尺度训练和微调中,训练 40 epoch 和 60 epoch,而在第 30 和 40 epoch 时,学习率衰减 10%。输入的图像尺寸为 512 × 512 512\times512 512×512。数据增强包含:随机水平翻转、随机仿射变换、随机颜色空间抖动、高斯模糊。表达式的最大长度设为 40,相应的 [CLS] 和 [SEP] 插入其中。训练采用 8 块 NVIDIA A100 GPUs(有钱)。
推理
输入图像尺寸为 512 × 512 512\times512 512×512,表达式的最大长度设为 40,无数据增强。模型直接输出坐标,无需后续操作。
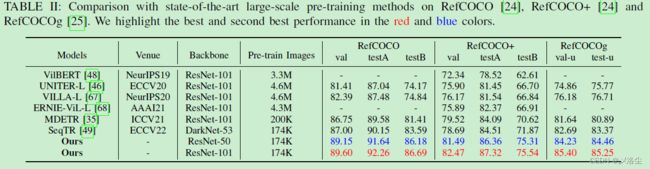
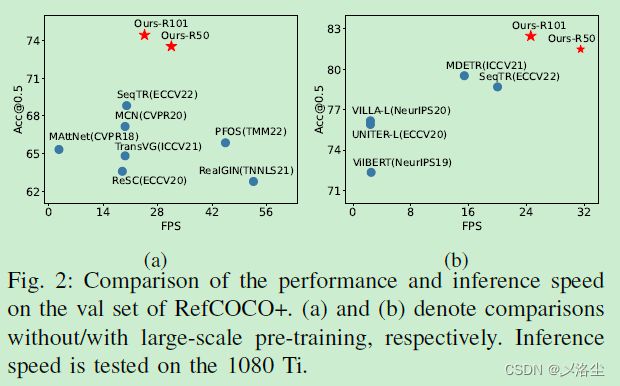
C、与 SOTA 方法的比较


D、消融实验
采用 ResNet-50 和 6 层的 BERT 分别作为视觉和语言编码器,在 RefCOCOg-google 验证集上进行。
1)视觉和语言特征数量的影响

2)CA2M 数量的影响

3) λ \lambda λ 和 σ \sigma σ 的影响

4)CA2M 和 Transformer 编码器层的比较
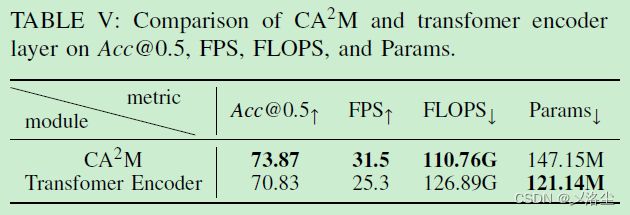
E、定性结果

六、结论
本文提出自定进度的多粒度跨模态交互建模框架,通过聚合难样本的不同模态的多粒度信息来提升定位能力。具体来说,构建了一个基于 Transformer 的多粒度跨模态注意力,设计了一个自定进度的样本信息学习来自适应地实现模型对具有充分信息的样本的学习。实验表明有效。
写在后面
这篇文章创新点水平较中等(与顶会相比),其中的注意力模块不能算是自主创新,因为就是个 Cross-Attention 的叠加,想必在很多模型中都会用到。第二个创新点可以的,就是这个难样本的学习策略,这一点倒是还没有文章注意到。还要吐槽的就是这篇文章没有代码,那个推理速度的实验有点难信服。