Docker安装+Kafka的简易使用+代码实现
docker简介
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker 是一种容器系统,容器(container)有点类似虚拟机,但是更加轻量级,容器并没有像虚拟机一样虚拟出一套完整的硬件环境,而是隔离出独立的运行环境(起源于chroot),但仍然运行在宿主系统的操作系统内核之上。
Docker使得开发人员可以将程序隔离于环境,从而快速的交付软件,而无需操心生产环境。
Docker 要求 CentOS 系统的内核版本高于 3.10
用途
1、docker是个大容器,先下载安装。
2、docker中可以使用docker命令安装images(镜像),可以是java,nginx,rabbitMQ等等待运行程序。
3、把image用docker命令运行起来后,意味着image(镜像)进到一个container(容器)中运行了,即container1里运行着nginx,container2中运行着nacos等等。docker中运行着多个container
安装:
1、查看linux内核版本。(使用 root 权限登录 Centos )
[root@iZgia1btkivmb2Z ~]# uname -r #查看linux内核版本
3.10.0-957.21.3.el7.x86_64 #结果
[root@iZgia1btkivmb2Z ~]#
2、确保yum包更新到最新:
[root@iZgia1btkivmb2Z ~]# yum -y update
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
正在解决依赖关系
--> 正在检查事务
---> 软件包 GeoIP.x86_64.0.1.5.0-13.el7 将被 升级
---> 软件包 GeoIP.x86_64.0.1.5.0-14.el7 将被 更新
......
完毕!
[root@iZgia1btkivmb2Z ~]#
3、卸载旧版本(如果安装过旧版本的话):
sudo yum remove -y docker*
[root@iZgia1btkivmb2Z ~]# sudo yum remove -y docker*
已加载插件:fastestmirror
参数 docker* 没有匹配
不删除任何软件包
[root@iZgia1btkivmb2Z ~]#
4、安装需要的软件, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的:
yum install -y yum-utils
[root@iZgia1btkivmb2Z ~]# yum install -y yum-utils
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
正在解决依赖关系
--> 正在检查事务
完毕!
[root@iZgia1btkivmb2Z ~]#
5、设置yum源,并更新 yum 的包索引
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@iZgia1btkivmb2Z ~]# sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
已加载插件:fastestmirror
adding repo from: http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
grabbing file http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo to /etc/yum.repos.d/docker-ce.repo
repo saved to /etc/yum.repos.d/docker-ce.repo
[root@iZgia1btkivmb2Z ~]#
yum makecache fast
[root@iZgia1btkivmb2Z ~]# yum makecache fast
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
......
元数据缓存已建立
[root@iZgia1btkivmb2Z ~]#
6、查看所有仓库中所有docker版本,并选择特定版本安装
yum list docker‐ce ‐‐showduplicates | sort ‐r
[root@iZgia1btkivmb2Z ~]# yum list docker-ce --showduplicates | sort -r
已加载插件:fastestmirror
可安装的软件包
Loading mirror speeds from cached hostfile
docker-ce.x86_64 3:20.10.9-3.el7 docker-ce-stable
docker-ce.x86_64 3:20.10.8-3.el7 docker-ce-stable
docker-ce.x86_64 3:20.10.7-3.el7 docker-ce-stable
docker-ce.x86_64 3:20.10.6-3.el7 docker-ce-stable
[root@iZgia1btkivmb2Z ~]#
7、安装docker
yum install -y docker-ce-3:19.03.9-3.el7.x86_64
[root@iZgia1btkivmb2Z ~]# yum install -y docker-ce-3:19.03.9-3.el7.x86_64
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
正在解决依赖关系
--> 正在检查事务
---> 软件包 docker-ce.x86_64.3.19.03.9-3.el7 将被 安装
完毕!
[root@iZgia1btkivmb2Z ~]#
8、启动docker
systemctl start docker
[root@iZgia1btkivmb2Z ~]# systemctl start docker
9、设置开机自动启动
systemctl enable docker
10、查看版本信息:
(有client和service两部分表示docker安装启动都成功了 )
docker version
一. Kafka简介
参考:看完这篇Kafka,你也许就会了Kafka
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了。
安装的kafka版本:2.8+的kafka,已经不需要依赖zookeeper来创建topic,新版本使用 --bootstrap-server 参数(近来kafka已经要开始抛弃zookeeper)
三大特点:
- 高吞吐量:可以满足每秒百万级别消息的生产和消费。
- 持久性:有一套完善的消息存储机制,确保数据高效安全且持久化。
- 分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
1.消息队列的好处
解耦合
耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
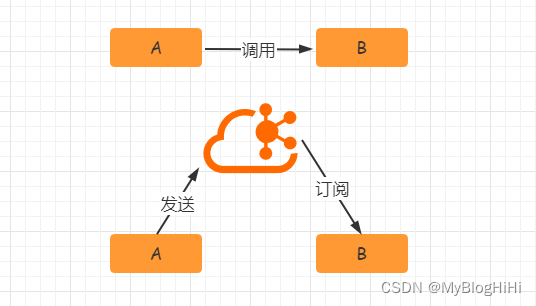
异步处理
异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
流量削峰
高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
2.消息系统
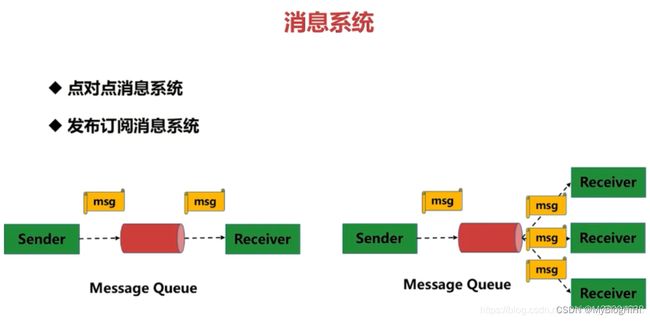
点对点消息系统
生产者发送一条消息到queue,一个queue可以有很多消费者,但是一个消息只能被一个消费者接受,当没有消费者可用时,这个消息会被保存直到有 一个可用的消费者,所以Queue实现了一个可靠的负载均衡。
发布订阅消息系统
发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息。topic实现了发布和订阅,当你发布一个消息,所有订阅这个topic的服务都能得到这个消息,所以从1到N个订阅者都能得到这个消息的拷贝。
3.kafka术语
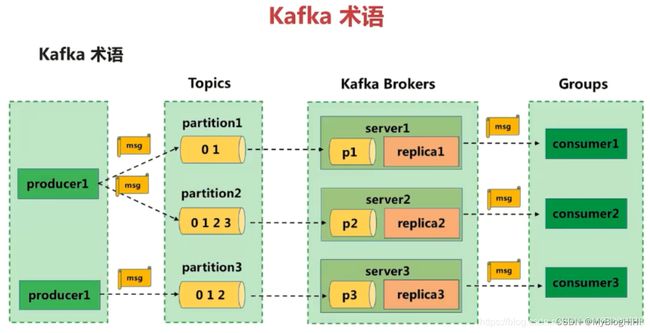
消息由producer产生,消息按照topic归类,并发送到broker中,broker中保存了一个或多个topic的消息,consumer通过订阅一组topic的消息,通过持续的poll操作从broker获取消息,并进行后续的消息处理。
Producer :消息生产者,就是向broker发指定topic消息的客户端。
Consumer :消息消费者,通过订阅一组topic的消息,从broker读取消息的客户端。
Broker :一个kafka集群包含一个或多个服务器,一台kafka服务器就是一个broker,用于保存producer发送的消息。一个broker可以容纳多个topic。
Topic :每条发送到broker的消息都有一个类别,可以理解为一个队列或者数据库的一张表。
Partition:一个topic的消息由多个partition队列存储的,一个partition队列在kafka上称为一个分区。每个partition是一个有序的队列,多个partition间则是无序的。partition中的每条消息都会被分配一个有序的id(offset)。
Offset:偏移量。kafka为每条在分区的消息保存一个偏移量offset,这也是消费者在分区的位置。kafka的存储文件都是按照offset.kafka来命名,位于2049位置的即为2048.kafka的文件。比如一个偏移量是5的消费者,表示已经消费了从0-4偏移量的消息,下一个要消费的消息的偏移量是5。
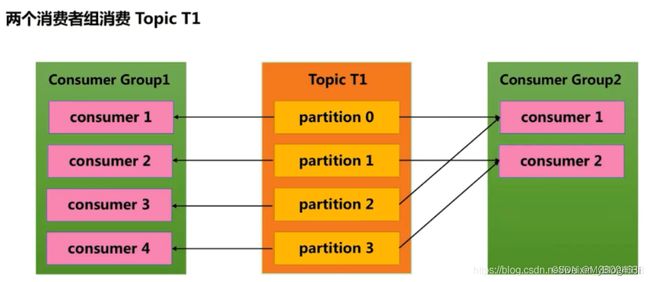
Consumer Group (CG):若干个Consumer组成的集合。这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
假如一个消费者组有两个消费者,订阅了一个具有4个分区的topic的消息,那么这个消费者组的每一个消费者都会消费两个分区的消息。消费者组的成员是动态维护的,如果新增或者减少了消费者组中的消费者,那么每个消费者消费的分区的消息也会动态变化。比如原来一个消费者组有两个消费者,其中一个消费者因为故障而不能继续消费消息了,那么剩下一个消费者将会消费全部4个分区的消息。
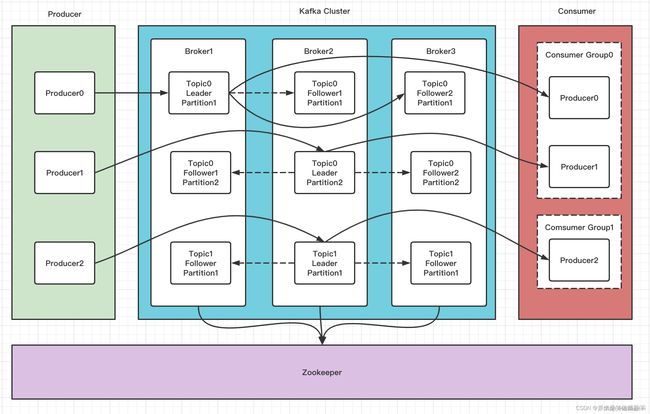
二.在Windows安装运行Kafka
kafka整体架构图
一、安装JAVA JDK
1、下载安装包
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
注意:根据32/64位操作系统下载对应的安装包
2、添加系统变量:JAVA_HOME=C:\Program Files (x86)\Java\jdk1.8.0_144
二、安装ZooKeeper
1、 下载安装包
http://zookeeper.apache.org/releases.html#download
2、 解压并进入ZooKeeper目录,如:D:\Kafka\zookeeper-3.4.9\conf
3、 将“zoo_sample.cfg”重命名为“zoo.cfg”
4、 打开“zoo.cfg”找到并编辑dataDir=D:\Kafka\zookeeper-3.4.9\tmp(必须以\分割)
5、 添加系统变量:ZOOKEEPER_HOME=D:\Kafka\zookeeper-3.4.9
6、 编辑path系统变量,添加路径:%ZOOKEEPER_HOME%\bin
7、 在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181)
8、 打开新的cmd,输入“zkServer“,运行Zookeeper
9、 命令行提示如下:说明本地Zookeeper启动成功
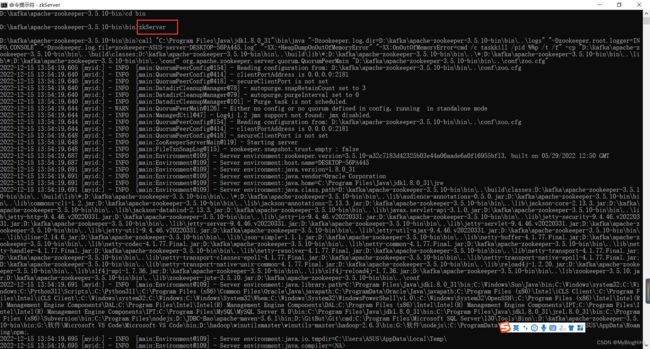
注意:不要关了这个窗口
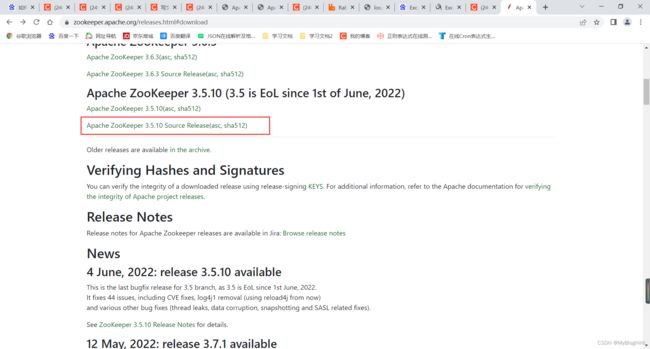
三、安装Kafka
注意:kafka版本高,2.8+的kafka,已经不需要依赖zookeeper来创建topic,新版本使用 --bootstrap-server 参数,以下例子是不依赖与zookeeper实现的
创建主题
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --partitions 1
查看主题
./kafka-topics.sh --list --bootstrap-server localhost:9092
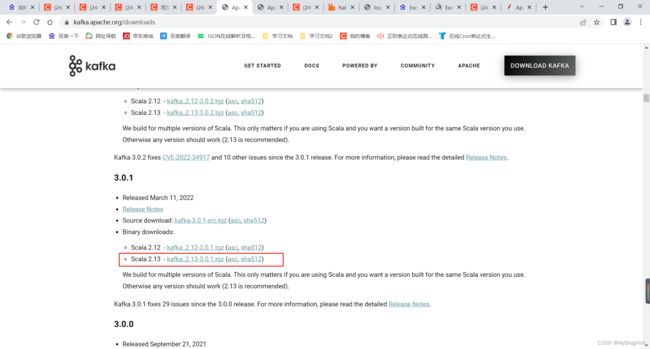
1、 下载安装包
http://kafka.apache.org/downloads
注意要下载二进制版本
2、 解压并进入Kafka目录,笔者:D:\kafka\kafka_2.13-3.0.1
3、 进入config目录找到文件server.properties并打开
4、 找到并编辑log.dirs=log.dirs=D:\kafka\kafka_2.13-3.0.1\kafka-logs
5、 找到并编辑zookeeper.connect=localhost:2181
6、 Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181
7、 进入Kafka安装目录D:\kafka\kafka_2.13-3.0.1,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
1. .\bin\windows\kafka-server-start.bat .\config\server.properties
或
2. bin\kafka-server-start.sh config\server.properties
注意:不要关了这个窗口,启用Kafka前请确保ZooKeeper实例已经准备好并开始运行
四、测试
(linux直接在bin目录下.sh,windows需要进入bin\winndows下的.bat)

1、 创建主题
进入Kafka安装目录D:\kafka\kafka_2.13-3.0.1,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
不依赖zookeeper创建(下图中的报错是因为,我本地使用版本比较高,不支持zookeeper方式了)
(新的的方式)
.\bin\windows\kafka-topics.bat --create --topic zhangphil_demo --bootstrap-server localhost:9092
zhangphil_demo:为创建的主题名
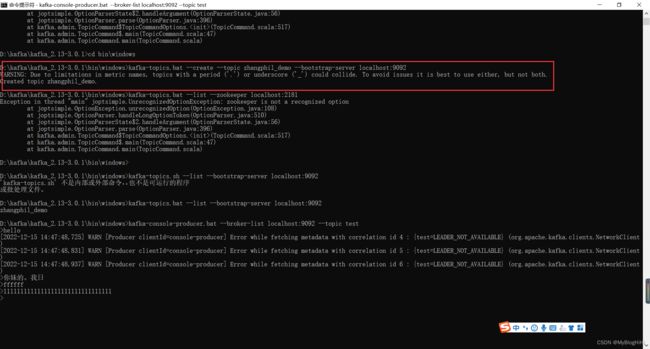
依赖zookeeper创建(老的方式)
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
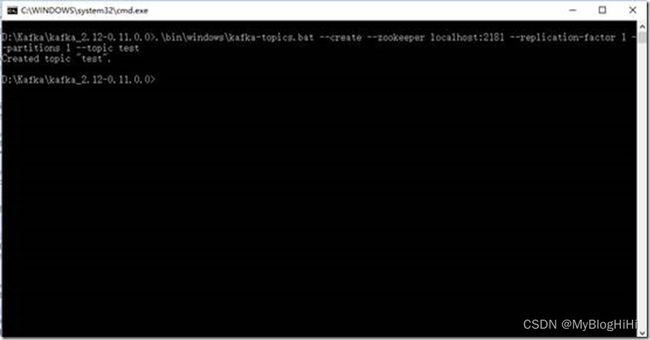
注意:不要关了这个窗口
2、查看主题输入:
新的方式
kafka-topics.bat --list --bootstrap-server localhost:9092
![]()
老的方式
.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
3、 创建生产者-发送消息
进入Kafka安装目录D:\kafka\kafka_2.13-3.0.1,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
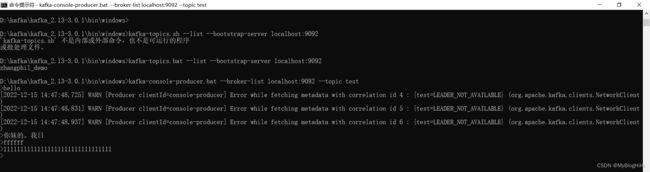
4、 创建消费者-接收消息
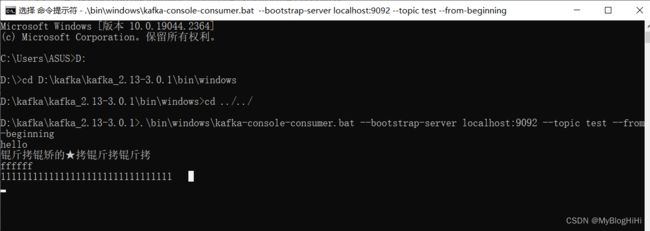
进入Kafka安装目录D:\kafka\kafka_2.13-3.0.1,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
此时,往生产者窗口写入消息,消费者窗口也能同步的接收到消息
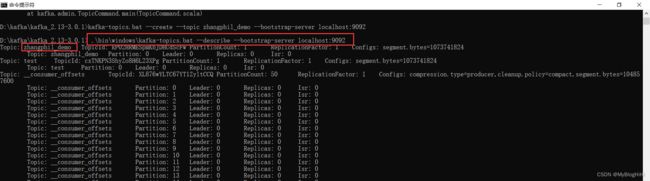
5、查看topic
进入Kafka安装目录D:\kafka\kafka_2.13-3.0.1,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
kafka-topics.bat --create --topic zhangphil_demo --bootstrap-server localhost:9092
6、 重要(操作日志的处理):
kafka启动后,如果你去查看kafka所在的根目录,或者是kafka本身的目录,会发现已经默认生成一堆操作日志(这样看起来真心很乱):
而且会不断生成不同时间戳的操作日志。刚开始不知所措,一番研究后,看了启动的脚本内容,发现启动的时候是会默认使用到这个log4j.properties文件中的配置,而在zoo.cfg是不会看到本身的启动会调用到这个,还以为只有那一个日志路径:
在这里配置一下就可以了,找到config下的log4j.properties:
将路径更改下即可,这样就可以归档在一个文件夹下边了,路径根据自己喜好定义:
另外如何消除不断生成日志的问题,就是同一天的不同时间会不停生成。
修改这里,还是在log4j.properties中:
本身都为trace,字面理解为会生成一堆跟踪日志,将其改为INFO即可。
kafka运行-结构
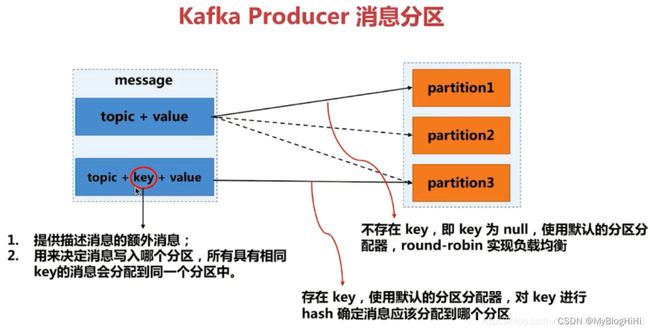
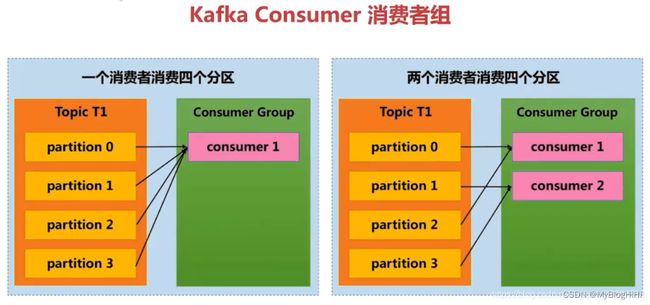
一次写入,支持多个应用读取,读取信息是相同的
三.kafka代码实现
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.24</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
Producer生产者
发送消息的方式,只管发送,不管结果:只调用接口发送消息到 Kafka 服务器,但不管成功写入与否。由于 Kafka 是高可用的,因此大部分情况下消息都会写入,但在异常情况下会丢消息
同步发送:调用 send() 方法返回一个 Future 对象,我们可以使用它的 get() 方法来判断消息发送成功与否
异步发送:调用 send() 时提供一个回调方法,当接收到 broker 结果后回调此方法
public class MyProducer {
private static KafkaProducer<String, String> producer;
//初始化
static {
Properties properties = new Properties();
//kafka启动,生产者建立连接broker的地址
properties.put("bootstrap.servers", "127.0.0.1:9092");
//kafka序列化方式
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//自定义分区分配器
properties.put("partitioner.class", "com.imooc.kafka.CustomPartitioner");
producer = new KafkaProducer<>(properties);
}
/**
* 创建topic:.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181
* --replication-factor 1 --partitions 1 --topic kafka-study
* 创建消费者:.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092
* --topic imooc-kafka-study --from-beginning
*/
//发送消息,发送完后不做处理
private static void sendMessageForgetResult() {
ProducerRecord<String, String> record = new ProducerRecord<>("kafka-study", "name", "ForgetResult");
producer.send(record);
producer.close();
}
//发送同步消息,获取发送的消息
private static void sendMessageSync() throws Exception {
ProducerRecord<String, String> record = new ProducerRecord<>("kafka-study", "name", "sync");
RecordMetadata result = producer.send(record).get();
System.out.println(result.topic());//imooc-kafka-study
System.out.println(result.partition());//分区为0
System.out.println(result.offset());//已发送一条消息,此时偏移量+1
producer.close();
}
/**
* 创建topic:.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181
* --replication-factor 1 --partitions 3 --topic kafka-study-x
* 创建消费者:.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092
* --topic kafka-study-x --from-beginning
*/
private static void sendMessageCallback() {
ProducerRecord<String, String> record = new ProducerRecord<>("kafka-study-x", "name", "callback");
producer.send(record, new MyProducerCallback());
//发送多条消息
record = new ProducerRecord<>("kafka-study-x", "name-x", "callback");
producer.send(record, new MyProducerCallback());
producer.close();
}
//发送异步消息
//场景:每条消息发送有延迟,多条消息发送,无需同步等待,可以执行其他操作,程序会自动异步调用
private static class MyProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
return;
}
System.out.println("*** MyProducerCallback ***");
System.out.println(recordMetadata.topic());
System.out.println(recordMetadata.partition());
System.out.println(recordMetadata.offset());
}
}
public static void main(String[] args) throws Exception {
//sendMessageForgetResult();
//sendMessageSync();
sendMessageCallback();
}
}
自定义分区分配器:决定消息存放在哪个分区.。默认分配器使用轮询存放,轮到已满分区将会写入失败
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
//获取topic所有分区
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int numPartitions = partitionInfos.size();
//消息必须有key
if (null == keyBytes || !(key instanceof String)) {
throw new InvalidRecordException("kafka message must have key");
}
//如果只有一个分区,即0号分区
if (numPartitions == 1) {return 0;}
//如果key为name,发送至最后一个分区
if (key.equals("name")) {return numPartitions - 1;}
return Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1);
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> map) {}
}
启动生产者发送消息,通过自定义分区分配器分配,查询到topic信息的value、partitioner

Kafka消费者(组)
自动提交位移 * 手动同步提交当前位移 * 手动异步提交当前位移 * 手动异步提交当前位移带回调 * 混合同步与异步提交位移
public class MyConsumer {
private static KafkaConsumer<String, String> consumer;
private static Properties properties;
//初始化
static {
properties = new Properties();
//建立连接broker的地址
properties.put("bootstrap.servers", "127.0.0.1:9092");
//kafka反序列化
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//指定消费者组
properties.put("group.id", "KafkaStudy");
}
//自动提交位移:由consume自动管理提交
private static void generalConsumeMessageAutoCommit() {
//配置
properties.put("enable.auto.commit", true);
consumer = new KafkaConsumer<>(properties);
//指定topic
consumer.subscribe(Collections.singleton("kafka-study-x"));
try {
while (true) {
boolean flag = true;
//拉取信息,超时时间100ms
ConsumerRecords<String, String> records = consumer.poll(100);
//遍历打印消息
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format(
"topic = %s, partition = %s, key = %s, value = %s",
record.topic(), record.partition(), record.key(), record.value()
));
//消息发送完成
if (record.value().equals("done")) { flag = false; }
}
if (!flag) { break; }
}
} finally {
consumer.close();
}
}
//手动同步提交当前位移,根据需求提交,但容易发送阻塞,提交失败会进行重试直到抛出异常
private static void generalConsumeMessageSyncCommit() {
properties.put("auto.commit.offset", false);
consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("kafka-study-x"));
while (true) {
boolean flag = true;
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format(
"topic = %s, partition = %s, key = %s, value = %s",
record.topic(), record.partition(), record.key(), record.value()
));
if (record.value().equals("done")) { flag = false; }
}
try {
//手动同步提交
consumer.commitSync();
} catch (CommitFailedException ex) {
System.out.println("commit failed error: " + ex.getMessage());
}
if (!flag) { break; }
}
}
//手动异步提交当前位移,提交速度快,但失败不会记录
private static void generalConsumeMessageAsyncCommit() {
properties.put("auto.commit.offset", false);
consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("kafka-study-x"));
while (true) {
boolean flag = true;
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format(
"topic = %s, partition = %s, key = %s, value = %s",
record.topic(), record.partition(), record.key(), record.value()
));
if (record.value().equals("done")) { flag = false; }
}
//手动异步提交
consumer.commitAsync();
if (!flag) { break; }
}
}
//手动异步提交当前位移带回调
private static void generalConsumeMessageAsyncCommitWithCallback() {
properties.put("auto.commit.offset", false);
consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("kafka-study-x"));
while (true) {
boolean flag = true;
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format(
"topic = %s, partition = %s, key = %s, value = %s",
record.topic(), record.partition(), record.key(), record.value()
));
if (record.value().equals("done")) { flag = false; }
}
//使用java8函数式编程
consumer.commitAsync((map, e) -> {
if (e != null) {
System.out.println("commit failed for offsets: " + e.getMessage());
}
});
if (!flag) { break; }
}
}
//混合同步与异步提交位移
@SuppressWarnings("all")
private static void mixSyncAndAsyncCommit() {
properties.put("auto.commit.offset", false);
consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("kafka-study-x"));
try {
while (true) {
//boolean flag = true;
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format(
"topic = %s, partition = %s, key = %s, " + "value = %s",
record.topic(), record.partition(),
record.key(), record.value()
));
//if (record.value().equals("done")) { flag = false; }
}
//手动异步提交,保证性能
consumer.commitAsync();
//if (!flag) { break; }
}
} catch (Exception ex) {
System.out.println("commit async error: " + ex.getMessage());
} finally {
try {
//异步提交失败,再尝试手动同步提交
consumer.commitSync();
} finally {
consumer.close();
}
}
}
public static void main(String[] args) {
//自动提交位移
generalConsumeMessageAutoCommit();
//手动同步提交当前位移
//generalConsumeMessageSyncCommit();
//手动异步提交当前位移
//generalConsumeMessageAsyncCommit();
//手动异步提交当前位移带回调
//generalConsumeMessageAsyncCommitWithCallback()
//混合同步与异步提交位移
//mixSyncAndAsyncCommit();
}
}
先启动消费者等待接收消息,再启动生产者发送消息,进行消费消息
