Elasticsearch索引生命周期管理
前言
在ELK架构中,使用Elasticsearch来存储系统日志时,有如下典型的特点:
- 数据量非常大
- 经常访问新增的数据,随着时间的推移,数据的价值也在逐渐降低
随着数据量的增大,Elasticsearch创建索引的数量也在不断增长,这个时候就需要对 索引 进行一定策略的维护管理甚至是删除清理,否则随着数据量越来越多除了浪费磁盘与内存空间之外,还会严重影响 Elasticsearch 的性能。
为了对Elasticsearch中的索引进行更好的管理,Elasticsearch在6.6版本中引入了Index Lifecycle Management(索引生命周期管理),简称ILM,并在 6.7 版正式推出该功能。
本篇示例使用的环境:
- Elasticsearch版本7.2.0
- Kibana版本7.2.0
- Elasticsearch节点个数:2
一、概述
索引生命周期管理ILM是指Elasticsearch对索引进行设置、创建、打开、关闭、删除的全生命周期管理的过程。
1.1 阶段介绍
将索引生命周期分为4个阶段:hot、warm、cold、delete。
其中hot阶段主要负责对索引进行滚动更新操作,warm、cold、delete阶段主要负责进一步处理滚动更新后的数据。

具体介绍
| 阶段 | 介绍 |
|---|---|
| hot | 热数据阶段,主要处理时序数据的实时写入。可根据索引的文档数、大小、时长决定是否调用rollover API来滚动更新索引。 |
| warm | 冷数据阶段,索引不再写入,主要用来提供查询。 |
| cold | 冷数据阶段,索引不再更新,查询很少,查询速度会变慢。 |
| delete | 删除数据阶段,索引将被删除。 |
添加生命周期管理方式
-
通过索引模板添加生命周期管理策略
将策略应用到整个别名覆盖的索引下
-
为单个索引添加生命周期管理策略
只能覆盖当前索引,新滚动的索引不再受策略影响。
阶段动作
| 阶段/action | 优先级设置 | 取消跟随 | 滚动索引 | 分片分配 | 只读 | 强制段合并 | 收缩索引 | 冻结索引 | 删除 |
|---|---|---|---|---|---|---|---|---|---|
| hot | √ | √ | √ | × | × | × | × | × | × |
| warm | √ | √ | × | √ | √ | √ | √ | × | × |
| cold | √ | √ | × | √ | × | × | × | √ | × |
| delete | × | × | × | × | × | × | × | × | √ |
1.2 常用Action
| 参数 | 说明 |
|---|---|
| rollover | 当写入索引达到了一定的大小,文档数量或创建时间时,rollover可创建一个新的写入索引,将旧的写入索引的别名去掉,并把别名赋给新的写入索引。所以便可以通过切换别名控制写入的索引是谁。它可用于Hot阶段。 |
| shrink | 减少一个索引的主分片数,可用于Warm阶段。需要注意的是当shink完成后索引名会由原来的shrink-. |
| force merge | 可触发一个索引分片的segment merge,同时释放掉被删除文档的占用空间。用于Warm阶段。 |
| allocate | 可指定一个索引的副本数,用于warm, cold阶段。 |
| delete | 删除索引,用户delete阶段 |
二、配置生命周期管理
2.1 需求
索引策略如下:
- 初始创建索引包含一个主分片和一个副本分片
- 刚创建的索引默认在hot阶段
- 当文档数量达到5个进行滚动更新,旧索引从hot阶段进入到warm阶段
- 在warm阶段,删除掉索引副本分片,只留下主分片
- 在10秒后索引从warm阶段进入到delete阶段,并在20秒后将索引删除。
2.2 步骤
- 第一步:配置lifecycle检测时间;
- 第二步:创建一个索引策略;
- 第三步:创建一个索引模版,指定使用的索引策略;
- 第四步:创建一个符合上述索引模版的索引;
- 第五步:向索引中写入数据,使索引触发滚动更新策略;
- 第六步:查看索引所处阶段
2.3 实现
(1)配置lifecycle检测时间
PUT /_cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "1s"
}
}默认为十分钟,为了测试看效果,改为1秒钟,如果在生产环境中则不需要进行修改。
(2)创建一个索引策略
# /_ilm/policy为固定格式,leefs_ilm_policy为创建索引策略名称
PUT /_ilm/policy/leefs_ilm_policy
{
# policy:配置策略
"policy": {
# phases:阶段配置
"phases": {
"hot": {
"actions": {
# rollover:滚动更新
"rollover": {
# max_docs:文档数量最大为5执行操作
"max_docs": "5"
}
}
},
"warm": {
# min_age:该阶段最小停留时长
"min_age": "10s",
"actions": {
# allocate:指定一个索引的副本数
"allocate": {
# number_of_replicas:进行索引副本数量设置
"number_of_replicas": 0
}
}
},
"delete": {
"min_age": "20s",
"actions": {
# delete:删除索引,如果没有该方法即使到删除阶段也不执行删除操作
"delete": {}
}
}
}
}
}
说明
在创建索引策略时,不是每个阶段都是必须的,除了hot阶段,其他阶段都可以根据需求进行省略。
包括滚动更新(rollover)在内的所有actions中的方法都可以根据需求进行省略。
(3)创建一个索引模版,指定使用的索引策略
# leefs_ilm_template:索引模版名称
PUT _template/leefs_ilm_template
{
# 模版匹配的索引名以"leefs_logs-"开头
"index_patterns": ["leefs_logs-*"],
"settings": {
# number_of_shard:设置主分片数量
"number_of_shards": 1,
# number_of_replicas:设置副本分片数量
"number_of_replicas": 1,
# 通过索引策略名称指定模版所匹配的索引策略
"index.lifecycle.name": "leefs_ilm_policy",
# 索引rollover后切换的索引别名为leefs_logs
"index.lifecycle.rollover_alias": "leefs_logs"
}
}(4)创建一个符合上述索引模版的索引
# 清空之前索引
DELETE leefs_logs*
# 创建第一个索引
PUT leefs_logs-000001
{
"aliases": {
//设置索引别名为leefs_logs的索引
"leefs_logs": {
//允许索引被写入数据
"is_write_index":true
}
}
}
(5)向索引中写入数据,使索引触发滚动更新策略
# refresh写入后更新
POST leefs_logs/_doc?refresh
{
"name":"llc"
}上方命名执行5次,使其触发滚动更新策略。
(6)查看索引所处阶段
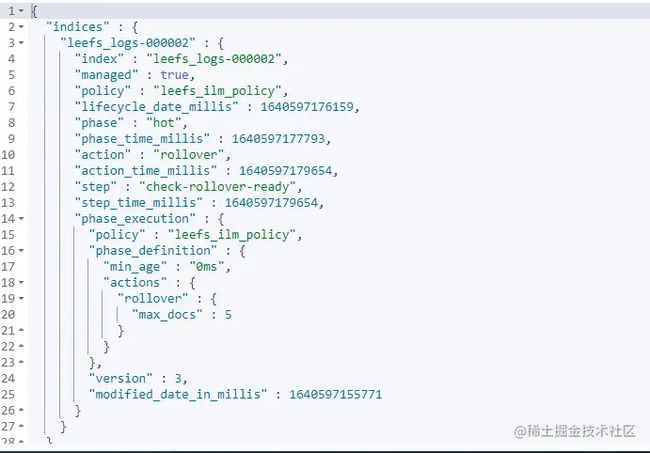
# 查询索引名称以leefs_logs-开头的索引信息
GET leefs_logs-*/_ilm/explain查询结果
json
复制代码
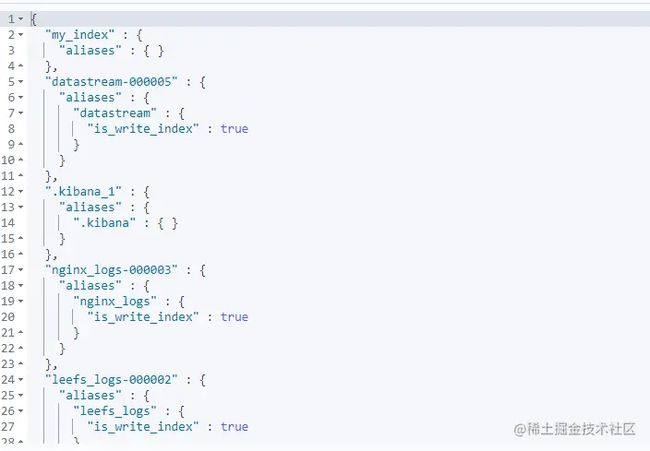
# 查询索引别名 GET _alias/
三、更新策略
- 如果没有index应用这份策略,那么我们可以直接更新该策略。
- 如果有index应用了这份策略,那么当前正在执行的阶段不会同步修改,当当前阶段结束后,会进入新版本策略的下个阶段。
- 如果更换了策略,当前正在执行的阶段不会变化,在结束当前阶段后,将会由新的策略管理下一个生命周期。
四、启动和停止索引生命周期管理
ILM默认是开启状态。
(1)查看ILM的当前运行状态
GET _ilm/status
执行结果
{
"operation_mode" : "RUNNING"
}ILM的操作模式
| 阶段/action | 优先级设置 |
|---|---|
| 正在运行 | 正常运行,所有策略均正常执行 |
| 停止 | ILM已收到停止请求,但仍在处理某些策略 |
| 已停止 | 这表示没有执行任何策略的状态 |
(2)停止ILM
POST _ilm/stop
停止后,所有其他政策措施都将停止。这将反映在状态API中
{
"operation_mode": "STOPPING"
}然后,ILM服务将异步地将所有策略运行到可以安全停止的位置。在ILM确认它是安全的之后,它将移至该STOPPED模式
{
"operation_mode": "STOPPED"
}(3)启动ILM
POST _ilm/start启动后查询状态
{
"operation_mode": "RUNNING"
}