大规模数据处理之架构图
1.画出文件系统HDFS架构的图,并写出各部件的功能。
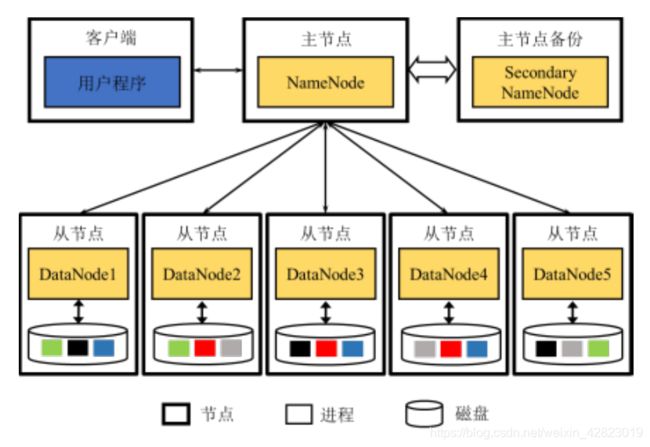
①NameNode:维护文件元数据FsImage和操作日志EditLog。
②SecondaryNameNode:NameNode的备份的进程。
③DataNode:存储数据块,为客户端提供文件数据的进程。
2.画出批处理系统MapReduce架构图,并写出各部件的功能。

①JobTracker:管理Job和Resource的进程。
- 管理Job,将Job拆分成Task,调度Task,监控Job和Task执行进度。
- 管理Resource,监控从节点资源使用情况,分配资源。
②TaskTracker:管理Task和Resource的进程。
- 管理Task,根据JobTracker命令,启动task,监控Task执行进度。
- 管理Resource,使用slot等量划分本节点上的资源量,一个Task至少获取一个slot。
- 汇报信息,通过心跳将从节点资源使用情况和Task进度汇报给JoTracker。
③Task(Child):执行Task的进程。
3.1画出批处理系统Spark的抽象架构图,并写出各部件的功能。
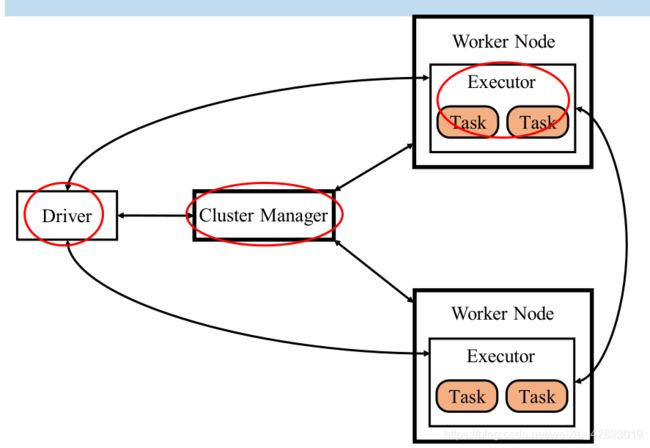
①Cluster Manager:管理Resource的进程,监控WorkerNode资源使用情况,分配资源。
- Standalone方式包括Master和Worker。
- Yarn方式包括Resource Manager和NodeManager。
③Driver:管理App和Job和Task的进程,启动Application,调度Task,监控Job执行进度,其中SparkContext维护了DAG、RDD Lineage信息。
②Executor:管理Task的进程,例如启动Task或TaskSet。
④Task:执行Task的线程。
3.2画出批处理系统Spark的Standalone架构图,并写出各部件的功能。
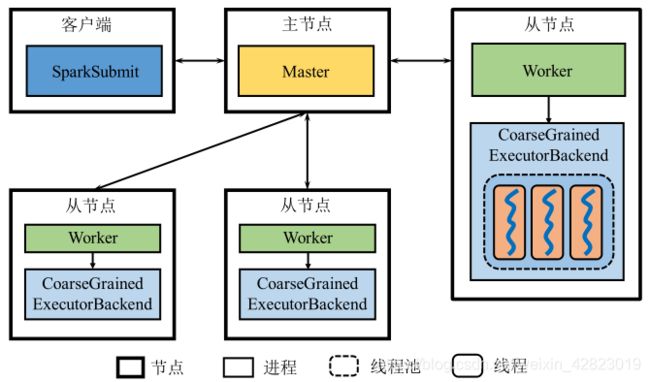
①Master+Worker=Cluster manager:管理Resource的进程,监控Worker资源使用情况,分配资源。
②Driver:管理App和Job和Task进程,启动Application,调度Task,监控Job执行进度,其中SparkContext维护了DAG、RDD Lineage信息。
- Client部署方式是Driver和客户端以同一个进程存在。
- Cluster部署方式是Master决定某一Worker启动一个进程作为Driver。
③CoarseGrainedExecutorBackend:管理Task的进程,例如启动Task或TaskSet。
④Task:执行Task的线程。
4.画出资源管理系统Yarn的架构图,并写出各部件的功能。
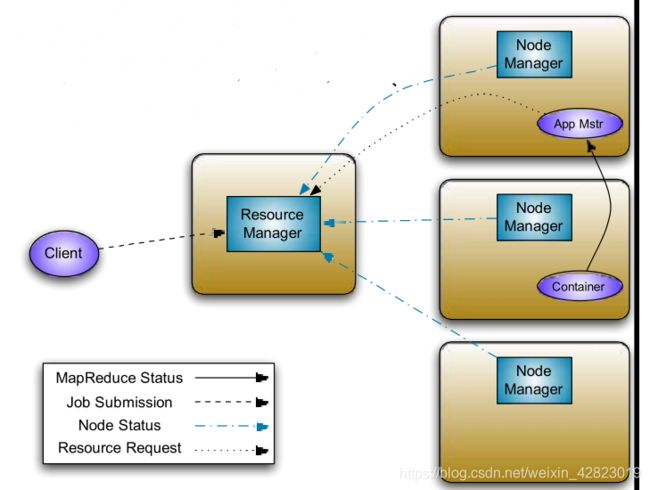
①ResourceManager:管理Resource和AppMaster的进程。
- 管理Resource,监控NodeManager资源使用情况,给AppMaster分配资源。
- 管理AppMaster,例如启动AppMaster。
③AppMaster:管理application的进程,例如启动/监控application。
③NodeManager:管理Resource和Container的进程。
- 管理Resource,监控Container资源使用情况。
- 管理Container,例如启动Container。
④Container:管理Resource的进程,分配运行任务的资源(CPU、内存、磁盘)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ySZpGLMR-1611227411246)(pic/Yarn2.png)]
5.画出协调服务系统ZooKeeper的架构图,并写出各部件的功能。

①Leader:读/写节点,维护Znode树。
②Folower:只读节点,同步Znode树。
③Oberver:只读节点,同步Znode树,不参与选举。
②Client:在Znode树上设置Watcher跟踪变化,实现通过Sever通信。
6.画出流计算系统Storm的架构图,并写出各部件的功能。
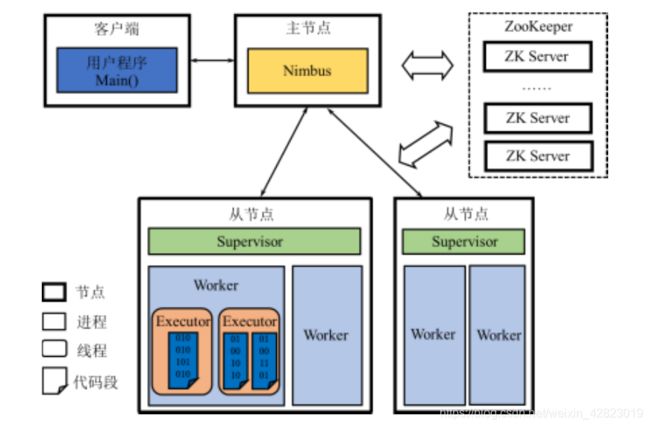
①Nimbus:管理Resource和Task的进程。
- 管理Resource,监控从节点资源使用情况。
- 管理Topology,根据Topology划分Task,调度Task。
②Supervisor:管理Resource和Worker的进程。
-
管理Resource,监控从节点资源使用情况。
-
管理Worker,根据Nimbus分配的Task启动或停止Worker进程。
③Worker:管理Executor的进程,例如启动Executor线程或线程池。
④Executor:执行Task的线程。
⑤ZooKeeper:负责Nimbus和Supervisor间的协调工作以及故障恢复工作。
7.画出流计算系统SparkStreaming的架构图,并写出各部件的功能。
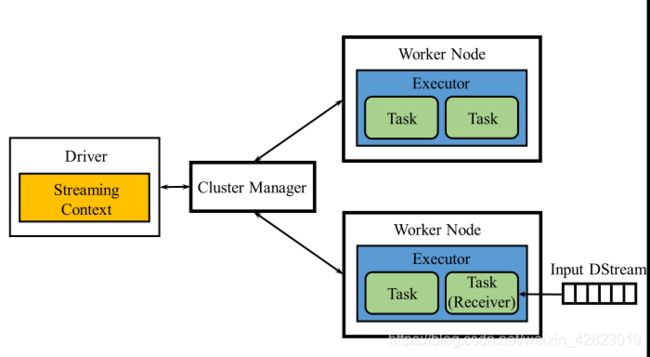
①StreamingContext:维护管理流计算的元信息。
②ReceiverTask:执行输入流数据的线程。
8.画出批流融合系统Lambda的架构图,并写出各部件的功能和该架构的局限性。
<
①Batch Layer:批处理层,全量计算,存储MasterDataset。
②Speed Layer:流计算层,增量计算,根据最近的数据,更新realtime view。
③Serving Layer:数据库层,根据batch layer的计算结果更新batch view。
缺点:开发复杂,需要将所有的算法实现两次,批处理系统和实时系统分开编程,还要求查询得到的是两个系统结果的合并。运维复杂,需要同时维护两套执行引擎。
9.画出批流融合系统Flink的架构图,并写出各部件的功能。

①JobManager:管理Resource和Job的进程。
- 管理Resource,监控从节点的资源使用情况,分配资源。
- 管理Job,将Job划分为多个Task,调度Task。
- 状态快照和故障恢复。
- Standalone部署方式下,JobManager的进程名为StandaloneSessionClusterEntrypoint。
②TaskManager:管理Resource和Task的进程。
- 管理Resource,监控从节点的资源使用情况,定时上报;将内存划分为多个TaskSlot,用来执行Task。
- 管理Task,例如启动Task。
- Standalone部署方式下,TaskManager的进程名为TaskManagerRunner。
③Task:执行Task的线程。
③CliFronted:将用户编写的DataStream程序翻译为逻辑执行图,并进行chaining优化,将用户编写的DataSet程序翻译为逻辑执行图,并进行chaining和基于代价的优化。将优化后的逻辑执行图提交到JobManager。
10.1画出图处理系统Pregel的架构图,并写出各部件的功能。

①Master:管理Worker的进程,Master维护的数据信息大小,只与分区的数量有关,而与顶点和边的数量无关。
②Worker:管理Task的进程,Master将图进行了划分为分区,每个Worker负责一个或多个分区并负责针对该分区的计算任务。
③Coordination Service:协调Master与worker以及worker之间。
10.2画出图处理系统Giraph的架构图,并写出各部件的功能

①所有的图处理逻辑都在启动Map任务的run函数中实现。从MapReduce框架的角度来看,执行Giraph作业仅启动了Map任务。
②启动的Map任务中,有一个作为Giraph的Master,其余作为Worker。