深入学习 Redis Cluster - 集群是啥,数如何理解据分片算法
目录
一、集群模式
1.1、集群是什么,解决了什么问题
1.2、数据分片算法(重点/考点)
1.2.1、哈希求余
a)算法思路
b)面临的问题
1.2.2、一致性哈希算法
a)算法思路
b)面临的问题
1.2.3、哈希槽分区算法(redis使用)
a)算法思想
b)问题一:redis 集群是最多有 16384 个分片么?
c)问题二:为什么是 16384 个槽位
一、集群模式
1.1、集群是什么,解决了什么问题
集群这个词,有两种说法:
- 广义的集群:只要你是多个机器,构成的分布式系统,都可以成为是一个 “集群”,也就是说,之前所讲的 主从结构、哨兵模式,也可以称为是一个 “广义的集群”.
- 狭义的集群:这个说的就是 redis 提供的集群模式. 这个集群模式之下,主要就是解决,存储空间不足的问题.
Ps:之前讲到,哨兵模式提高了系统的可用性,本质上还是 redis 主从节点存储数据,也就要求一个主节点/从节点,就得存储整个数据的 “全集”.
Redis cluster 的核心思路就是多搞几台机器,每台机器只存储全集数据的一部分.
例如 有 1TB 的数据需要存储.
拿两台机器来存,每个机器只需要 512GB 即可.
拿三台机器来存,每个机器只需要 300多 GB 即可.
拿四台机器来存,每个机器只需要 256GB 即可.
随着机器数量的增加,每个机器存储的数据量就减少了.
机器足够多了,那么接下来要面临的一个问题就是,如果给你一个 key,你该去哪台机子上存 value 值,或者读取 value 值?这时候就需要使用数据分片算法了~
1.2、数据分片算法(重点/考点)
关于数据分片算法,有三种主流的分片方式.
1.2.1、哈希求余
a)算法思路
哈希求余算法,借鉴了哈希表的基本思想,借助 hash 函数,把一个 key 映射到整数,在针对数组的长度求余,就可以得到一个数组的下标.
比如有三个分片,编号 0 1 2
此时就可以针对要插入的数据 key(这里是一个键值对数据),计算 hash 值(比如使用 md5),再把这个 hash 值余上一个分片的个数,就得到了一个下标,此时就可以把这个数据放到下标对应的分片中了.
假设 hash(key) % N = 0,那么此时这个 key 就要存储到 0 号分片中,后续如果查询的 key 是一样的,hash 函数不变,那么得到的分片就是一样的.
对 md5 的解释
md5 本身就是一个计算 hash 值的算法,针对一个字符串,里面的内容进行一系列的数字变换,最终得到一个整数.
md5 计算有以下三个特点:
- md5 计算结果是定长的:无论输入的原字符串是多长,最终算出的结构都是固定长度.
- md5 计算结构式分散的:两个原字符串,哪怕大部分相同,只有一个小的地方不同,算出来的 md5 也会差别很大.
- md5 计算的结果不可逆:给你一个原字符串,可以很容易的算出 md5 的值,但是给你 md5 值,很难还原出原始字符串(网上有些 md5 破解,其实就是把常见的字符串用 md5 提前算好,保存下来,然后按照打表的方式,来映射对应的字符串,具体能不能查到,就随缘了). 基于这一特点,经常用来做加密处理.
b)面临的问题
一旦服务器集群需要扩容,那么此时分片越多,数据量越大,扩容的成本越高.
这是为什么?
使用 hash(key) % N 的方式来计算,一旦引入新的分片,N 就改变了. 这也就导致,分片中很多原来的数据,都需要进行重新分配,也就是搬运元素,搬运到其他的分片中.
如下图:
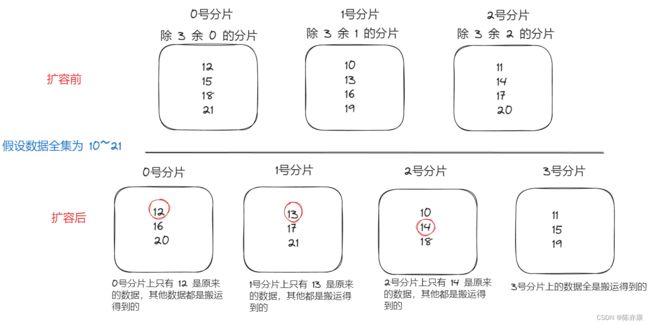
一共 12 个元素,只有 3 个数据不需要搬运,如果数据量十分庞大,搬运的成本就非常高了.
Ps:上述级别的扩容,开销极大,是不能直接再生产环境上操作的,只能通过 “替换” 的方式来实现扩容. 但是替换的成本更大,操作很复杂(重新搞原来这么多分片,并把数据都拷贝过来,再在新机器上扩容,扩容好了,再用新机器代替旧机器).
1.2.2、一致性哈希算法
a)算法思路
在 hash 求余算法中,当前 key 属于哪个分片,是交替的,也就是不连续.
在 一致性哈希算法 中,就把 交替出现,改进成了 连续出现.
具体的,第一步,把 0 ~ 2^32-1这个数据空间, 映射到⼀个圆环上. 数据按照顺时针⽅向增⻓.
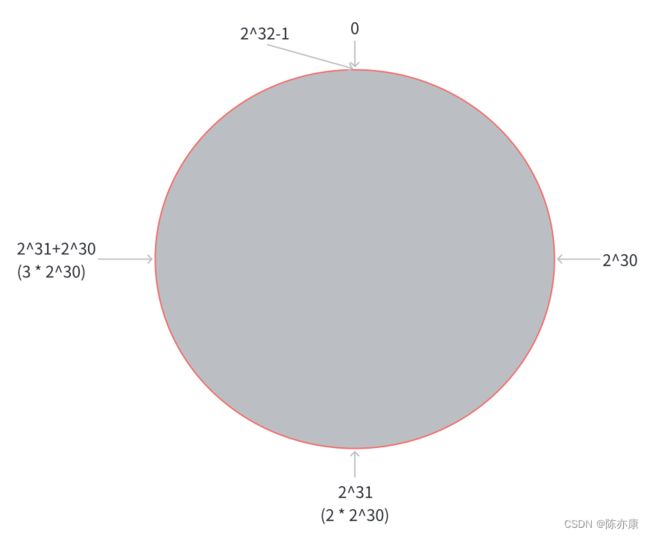
第二步,假设当前存在三个分⽚, 就把分⽚放到圆环的某个位置上.

第三步,假设有一个 key,通过 hash 计算出来的值为 value,就把个 value,映射到圆环上,接着顺时针去找,找到第一个分片就是该 key 所在的分片. 这样的分配就类似于下图
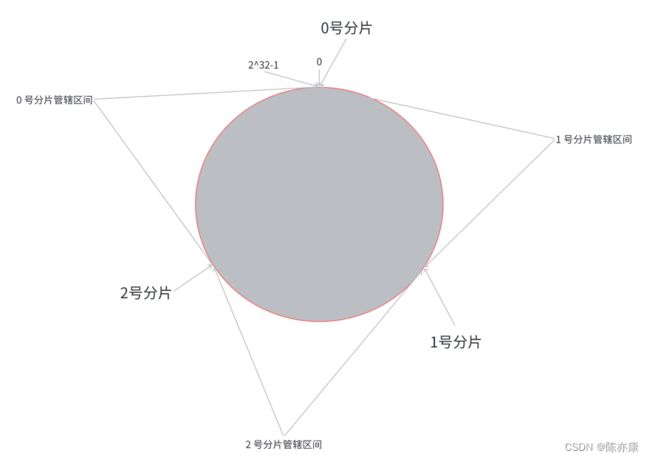
最后如果,如果需要扩容,那么原有分⽚在环上的位置不动, 只要在环上新安排⼀个分⽚位置即可,如下

这时候只需要把 0 号分片上部分数据搬运给 3 号分片即可,其他分片不用动.
b)面临的问题
这种算法,虽然搬运的成本低了,但是会导致数据倾斜(这几个分片上的数据量,可能会不均匀).
1.2.3、哈希槽分区算法(redis使用)
a)算法思想
这也是 redis 真正采用的分片算法. 这种算法的本质,就是把 一致性哈希 和 哈希求余 这两种方式结合了一下.
hash_slot = crc16(key) % 16384- hash_slot:表示哈希槽,有了哈希槽,就可以进一步把这些哈希槽分配到不同分片上.
- crc16:也是一种计算 hash 值的算法.
- 16384:16 * 1024,也就是 2^14.
相当于是把整个哈希值, 映射到 16384 个槽位上, 也就是 [0, 16383]. 然后再把这些槽位⽐较均匀的分配给每个分⽚. 每个分⽚的节点都需要记录⾃⼰持有哪些分⽚.
假设当前有三个分片,一种可能的分配方式如下:
- 0 号分片:[0, 5461],共 5462 个槽位.
- 1 号分片:[5462, 10923],共 5642 个槽位.
- 2号分片:[10924, 16383],共 5460 个槽位.
虽然不是严格意义的 “均匀” 差异非常小,但已经是比较均匀的了. 这只是一种分片方式,实际上分片是非常灵活的,槽位号可以是连续的,也可以是不连续的.
例如,进⾏扩容, ⽐如新增⼀个 3 号分⽚, 就可以针对原有的槽位进⾏重新分配. ⽐如可以把之前每个分⽚持有的槽位, 各拿出⼀点, 分给新分⽚. ⼀种可能的分配⽅式:
• 0号分⽚: [0, 4095], 共 4096 个槽位
• 1号分⽚: [5462, 9557], 共 4096 个槽位
• 2号分⽚: [10924, 15019], 共 4096 个槽位
• 3号分⽚: [4096, 5461] + [9558, 10923] + [15019, 16383], 共 4096 个槽位
Ps:每一个分片都会使用 “位图” 这样的数据结构,表示除当前有多少槽位. 16384 个 bit 位,每一位用 0/1 区分是否是自己这个分片当前持有的槽位号.
并且,redis 中,当前某个分片包含哪些槽位都是可以手动配置的.
b)问题一:redis 集群是最多有 16384 个分片么?
如果是这样,那么极端情况下,每个分片上就只分配一个槽位,而 key 是要先映射到槽位,在映射到分片的,这就导致很难保证数据在各个分片上的均衡性,因为有的槽位可能是多个 key,有的槽位可能没有 key,抛开这个不说,1.6W 个分片,整个服务器的集群规模就相当可怕,几万台主机构成的集群,整个集群的可用性是很低的(机器越多,越容易出故障).
Ps:实际上,Redis 作者建议分片的数目不因该超过 1000.
c)问题二:为什么是 16384 个槽位
- 分片之间是通过心跳包通信的,心跳包中就包含了该分片持有了哪些槽位,如果这个分片中持有的槽位越多,虽然使用位图这种数据结构表示,占用的内存不多,但是心跳包是周期性通信,吃非常吃网络带宽的(网络带宽相比于内存更稀有,更贵重).
- 另一方面,这个值基本够用了,占用的网络带宽也不是很大.
