Linux关于memory cgroup的几个要点
概述
本文讲述memory cgroup比较容易误解的一些逻辑,如果不太经常使用和解决问题的话,对于memory cgroup的认知会比较浅显:cgroup memory用来限制进程的内存使用,但是我们进一步想如下的问题:
- 进程的内存可以分很多类型,比如page cache,slab,anon memory等,到底是限制的哪些内存?
- 如果进程A已经运行起来占用了一些内存,之后,再将A加入memory cgroup限制,原来占用的内存会统计入新的memory cgroup?
- memory cgroup有memory.soft_limit_in_bytes和memory.limit_in_bytes,假设进程使用内存超过这两个限制,内存回收时机和路径是怎么样的?
- 我们知道内核回收页面采用lru算法,同时memcg也有per node lru,这两个lru是什么关系?
被误解的cgroup内存限制
结论:Cgroup 内存范围包括进程RSS 及该进程首次触发加载进Page Cache 所占用的内存,但不包括Slab 部分。
我们怎么从源码确认page cache是被cgroup限制的呢?charge逻辑:我们知道新页面产生的时候,内核会charge增加cgroup内存使用的统计,所以最直接的方式我们看下read或者write产生page cache是否存在charge逻辑,如果存在说明进程pagecache也是被cgroup限制的。
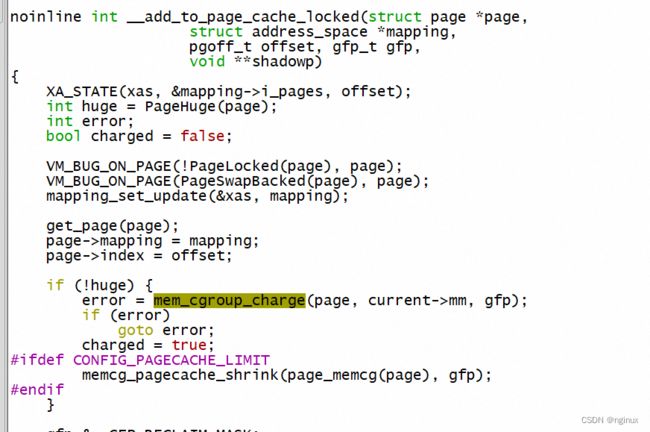
上述函数的调用栈:
#0 try_to_free_mem_cgroup_pages (memcg=0xffff8880009ba000, nr_pages=1, gfp_mask=1125578, may_swap=true) at mm/vmscan.c:3326
#1 0xffffffff81422729 in try_charge (memcg=0xffff8880009ba000, gfp_mask=, nr_pages=) at mm/memcontrol.c:2703
#2 0xffffffff81425f56 in mem_cgroup_charge (page=0xffffea0000019240, mm=, gfp_mask=) at mm/memcontrol.c:6718
#3 0xffffffff8132bed0 in __add_to_page_cache_locked (page=0xffffea0000019240, mapping=0xffff888002826330, offset=65, gfp_mask=1125578, shadowp=0xffff888000b27650) at ./arch/x86/include/asm/current.h:15
#4 0xffffffff8132c224 in add_to_page_cache_lru (page=0xffffea0000019240, mapping=0xffff888002826330, offset=65, gfp_mask=1125578) at mm/filemap.c:922
#5 0xffffffff81344d9b in page_cache_readahead_unbounded (mapping=, file=, index=65, nr_to_read=, lookahead_size=) at mm/readahead.c:228
#6 0xffffffff81344eeb in __do_page_cache_readahead (mapping=0xffff888002826330, file=0xffff8880054fca00, index=, nr_to_read=32, lookahead_size=32) at mm/readahead.c:273
#7 0xffffffff8134518f in ra_submit (filp=, mapping=, ra=) at mm/internal.h:64
#8 ondemand_readahead (mapping=0xffff888002826330, ra=0xffff8880054fca98, filp=, hit_readahead_marker=, index=64, req_size=) at mm/readahead.c:551
#9 0xffffffff813454cd in page_cache_async_readahead (page=, req_count=, index=, filp=, ra=, mapping=)
at mm/readahead.c:631
#10 page_cache_async_readahead (mapping=0xffff888002826330, ra=0xffff8880054fca98, filp=, page=0xffffffff8332f0b0 , index=, req_count=)
at mm/readahead.c:604
#11 0xffffffff8132eba7 in generic_file_buffered_read (iocb=0xffff888000b27ad8, iter=0xffff888000b27a78, written=0) at mm/filemap.c:2220
#12 0xffffffff8132f674 in generic_file_read_iter (iocb=0xffff888000b27ad8, iter=0xffff888000b27a78) at mm/filemap.c:2520 可以看到read文件产生pagecache,最终要在add_to_page_cache_lru加入到address_space radix_tree和相对应的lru链表中,进而调用到mem_cgroup_charge逻辑,所以确认了我们的结论。
进程已运行后,加入Cgroup A中,已经使用的内存是否迁移统计入A
当一个进程从一个cgroup移动到另一个cgroup时,默认情况下,该进程已经占用的内存还是统计在原来的cgroup里面,不会占用新cgroup的配额,但新分配的内存会统计到新的cgroup中(包括swap out到交换空间后再swap in到物理内存中的部分)。
我们可以通过设置memory.move_charge_at_immigrate让进程所占用的内存随着进程的迁移一起迁移到新的cgroup中。
enable: echo 1 > memory.move_charge_at_immigrate disable:echo 0 > memory.move_charge_at_immigrate
注意: 就算设置为1,但如果不是thread group的leader,这个task占用的内存也不能被迁移过去。换句话说,如果以线程为单位进行迁移,必须是进程的第一个线程,如果以进程为单位进行迁移,就没有这个问题。
当memory.move_charge_at_immigrate被设置成1之后,进程占用的内存将会被统计到目的cgroup中,如果目的cgroup没有足够的内存,系统将尝试回收目的cgroup的部分内存(和系统内存紧张时的机制一样,删除不常用的file backed的内存或者swap out到交换空间上,如果回收不成功,那么进程迁移将失败。
memory.soft_limit_in_bytes和memory.limit_in_bytes内存回收时机
有了hard limit(memory.limit_in_bytes),为什么还要soft limit呢?hard limit是一个硬性标准,绝对不能超过这个值,而soft limit可以被超越,既然能被超越,要这个配置还有啥用?先看看它的特点
-
当系统内存充裕时,soft limit不起任何作用
-
当系统内存吃紧时,系统会尽量的将cgroup的内存限制在soft limit值之下(内核会尽量,但不100%保证)
从它的特点可以看出,它的作用主要发生在系统内存吃紧时,如果没有soft limit,那么所有的cgroup一起竞争内存资源,占用内存多的cgroup不会让着内存占用少的cgroup,这样就会出现某些cgroup内存饥饿的情况。如果配置了soft limit,那么当系统内存吃紧时,系统会让超过soft limit的cgroup释放出超过soft limit的那部分内存(有可能更多),这样其它cgroup就有了更多的机会分配到内存。
从上面的分析看出,这其实是系统内存不足时的一种妥协机制,给次等重要的进程设置soft limit,当系统内存吃紧时,把机会让给其它重要的进程。
注意: 当系统内存吃紧且cgroup达到soft limit时,系统为了把当前cgroup的内存使用量控制在soft limit下,在收到当前cgroup新的内存分配请求时,就会触发回收内存操作,所以一旦到达这个状态,就会频繁的触发对当前cgroup的内存回收操作,会严重影响当前cgroup的性能。
结论:
soft_limit_in_bytes只有触发kswapd或者direct reclaim时候才会进行顺道的回收
limit_in_bytes:新页面产生时候,charge增加使用计数,如果超过limit_in_bytes就会回收。
全局LRU和memcg LRU的关系
结论:我们经常讨论的全局LRU其实对应root_mem_cgroup的per node LRU。
假设目前系统没有设置任何的cgroup,那么只有root_mem_cgroup这个memcg,只要配置CONFIG_CGROUP,内核初始化的时候就会初始化root cgroup。那么我们read/write产生pagecache情况下,新产生page加入lru的代码,看看到底加入的哪个LRU?
lru_cache_add
--->__pagevec_lru_add
--->pagevec_lru_move_fn
static void pagevec_lru_move_fn(struct pagevec *pvec,
void (*move_fn)(struct page *page, struct lruvec *lruvec, void *arg),
void *arg)
{
int i;
struct pglist_data *pgdat = NULL;
struct lruvec *lruvec;
unsigned long flags = 0;
for (i = 0; i < pagevec_count(pvec); i++) {
struct page *page = pvec->pages[i];
struct pglist_data *pagepgdat = page_pgdat(page);
if (pagepgdat != pgdat) {
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
pgdat = pagepgdat;
spin_lock_irqsave(&pgdat->lru_lock, flags);
}
//内核通过mem_cgroup_page_lruvec获取加入的LRU,由于我们没有配置任何cgroup,
//那么此时产生的page对应的lru就是root_mem_cgroup的pgdat这个node的 lru
lruvec = mem_cgroup_page_lruvec(page, pgdat);
(*move_fn)(page, lruvec, arg);
}
if (pgdat)
spin_unlock_irqrestore(&pgdat->lru_lock, flags);
release_pages(pvec->pages, pvec->nr);
pagevec_reinit(pvec);
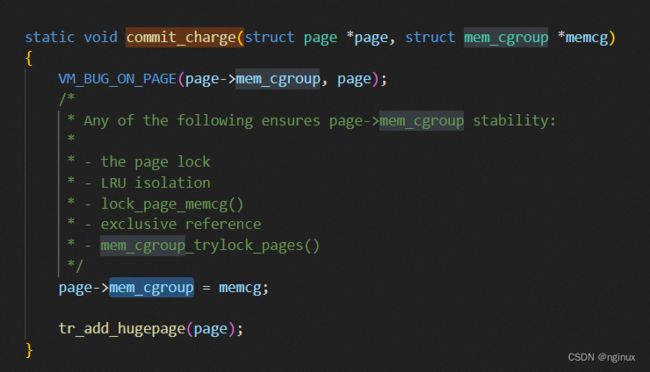
}如上面代码注释,最终mem_cgroup_page_lruvec获取到page->memcg的pgdat node对应的lruvec,而这里page->memcg又是指向哪里的,由于目前系统没有配置任何的cgroup,这个page->memcg就指向root_mem_cgroup,那么page->memcg赋值的地方在哪里的,针对我们目前read pagecache这种场景,最终是在mm/memcontrol.c :commit_charge里面,调用栈:
remote Thread 1 In: mem_cgroup_charge Line: 6723 PC: 0xffffffff8142f6cd
#0 commit_charge (page=, memcg=) at mm/memcontrol.c:6723
#1 mem_cgroup_charge (page=0xffffea00000c7600, mm=, gfp_mask=) at mm/memcontrol.c:6723
#2 0xffffffff81330f80 in __add_to_page_cache_locked (page=0xffffea00000c7600, mapping=0xffff888006245e80, offset=4, gfp_mask=1125578, shadowp=0xffff888006557650) at ./arch/x86/include/asm/current.h:15
#3 0xffffffff813312d4 in add_to_page_cache_lru (page=0xffffea00000c7600, mapping=0xffff888006245e80, offset=4, gfp_mask=1125578) at mm/filemap.c:922
#4 0xffffffff8134a0eb in page_cache_readahead_unbounded (mapping=, file=, index=4, nr_to_read=, lookahead_size=) at mm/readahead.c:228
#5 0xffffffff8134a25b in __do_page_cache_readahead (mapping=0xffff888006245e80, file=0xffff88800548b640, index=, nr_to_read=32, lookahead_size=16) at mm/readahead.c:273
#6 0xffffffff8134a4ff in ra_submit (filp=, mapping=, ra=) at mm/internal.h:64
#7 ondemand_readahead (mapping=0xffff888006245e80, ra=0xffff88800548b6d8, filp=, hit_readahead_marker=, index=0, req_size=) at mm/readahead.c:551
#8 0xffffffff8134aac8 in page_cache_sync_readahead (req_count=, index=, filp=, ra=, mapping=) at mm/readahead.c:585
#9 page_cache_sync_readahead (mapping=, ra=0xffff88800548b6d8, filp=0xffff88800548b640, index=, req_count=) at mm/readahead.c:567
#10 0xffffffff81333bf1 in generic_file_buffered_read (iocb=0xffff888006557ad8, iter=0xffff888006557a78, written=0) at mm/filemap.c:2208
#11 0xffffffff81334776 in generic_file_read_iter (iocb=0xffff888006557ad8, iter=0xffff888006557a78) at mm/filemap.c:2520
commit_charge如下:
参考:
Linux内核mem_cgroup浅析-wzzushx-ChinaUnix博客