Java8实战-总结28
Java8实战-总结28
- 用流收集数据
-
- 收集器接口
-
- 理解Collector接口声明的方法
- 全部融合到一起
用流收集数据
收集器接口
Collector接口包含了一系列方法,为实现具体的归约操作(即收集器)提供了范本。Collector接口中实现了许多收集器,例如toList或groupingBy。这也意味着,可以为Collector接口提供自己的实现,从而自由地创建自定义归约操作。下面将展示如何实现Collector接口来创建一个收集器,来比先前更高效地将数值流划分为质数和非质数。
要开始使用Collector接口,先看看toList工厂方法,它会把流中的所有元素收集成一个List。在日常工作中经常会用到这个收集器,而且它也是写起来比较直观的一个,至少理论上如此。通过仔细研究这个收集器是怎么实现的,可以很好地了解Collector接口是怎么定义的,以及它的方法所返回的函数在内部是如何为collect方法所用的。
首先让在下面的列表中看看Collector接口的定义,它列出了接口的签名以及声明的五个方法。
Collector接口:
public interface Collector<T, A, R> {
Supplier<A> supplier();
Biconsumer<A, T> accumulator();
Function<A, R> finisher();
Binaryoperator<A> combiner();
Set<Characteristics> characteristics();
}
本列表适用以下定义。
T是流中要收集的项目的泛型。A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。R是收集操作得到的对象(通常但并不一定是集合)的类型。
例如,可以实现一个ToListCollector类,将Stream中的所有元素收集到一个List里,它的签名如下:
public class ToListCollector<T> implements Collector<T, List<T>, List<T>>
这里用于累积的对象也将是收集过程的最终结果。
理解Collector接口声明的方法
现在来分析Collector接口声明的五个方法。前四个方法都会返回一个会被collect方法调用的函数,而第五个方法characteristics则提供了一系列特征,也就是一个提示列表,告诉collect方法在执行归约操作的时候可以应用哪些优化(比如并行化)。
1.建立新的结果容器:supplier方法
supplier方法必须返回一个结果为空的Supplier,也就是一个无参数函数,在调用时它会创建一个空的累加器实例,供数据收集过程使用。很明显,对于将累加器本身作为结果返回的收集器,比如ToListCollector,在对空流执行操作的时候,这个空的累加器也代表了收集过程的结果。在ToListCollector中,supplier返回一个空的List,如下所示:
public Supplier<List<T>> supplier() {
return () -> new ArrayList<T>();
}
注意也可以只传递一个构造函数引用:
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
2.将元素添加到结果容器:accumulator方法
accumulator方法会返回执行归约操作的函数。当遍历到流中第n个元素时,这个函数执行时会有两个参数:保存归约结果的累加器(已收集了流中的前n-1个项目),还有第n个元素本身。该函数将返回void,因为累加器是原位更新,即函数的执行改变了它的内部状态以体现遍历的元素的效果。对于ToListCollector,这个函数仅仅会把当前项目添加至已经遍历过的项目的列表:
public Biconsumer<List<T>, T> accumulator() {
return(list, item) -> list.add(item);
}
也可以使用方法引用,这会更为简洁:
public Biconsumer<List<T>, T> accumulator() {
return List::add;
}
3.对结果容器应用最终转换:finisher方法
在遍历完流后,finisher方法必须返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。通常,就像ToListCollector的情况一样,累加器对象恰好符合预期的最终结果,因此无需进行转换。所以finisher方法只需返回identity函数:
public Function<List<T>, List<T>> finisher() {
return Function.identity();
}
这三个方法已经足以对流进行顺序归约,至少从逻辑上看可以按下图进行。实践中的实现细节可能还要复杂一点,一方面是因为流的延迟性质,可能在collect操作之前还需要完成其他中间操作的流水线,另一方面则是理论上可能要进行并行归约。
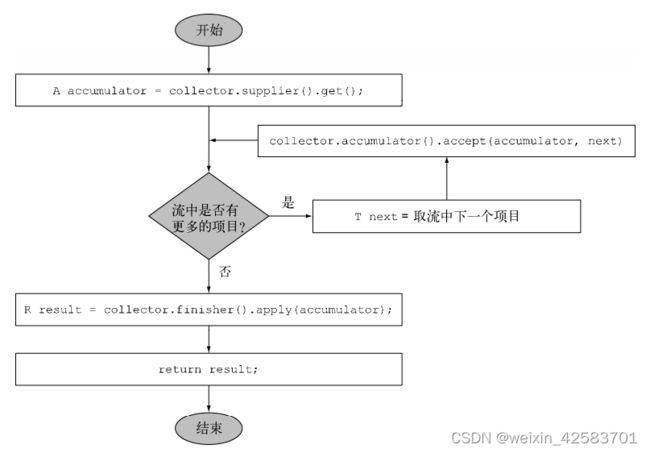
4.合并两个结果容器:combiner方法
四个方法中的最后一个——combiner方法会返回一个供归约操作使用的函数,它定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器要如何合并。对于toList而言,这个方法的实现非常简单,只要把从流的第二个部分收集到的项目列表加到遍历第一部分时得到的列表后面就行了:
public BinaryOperator<List<T>> combiner() {
return(list1, list2) -> {
list1.addAll(list2);
return list1; }
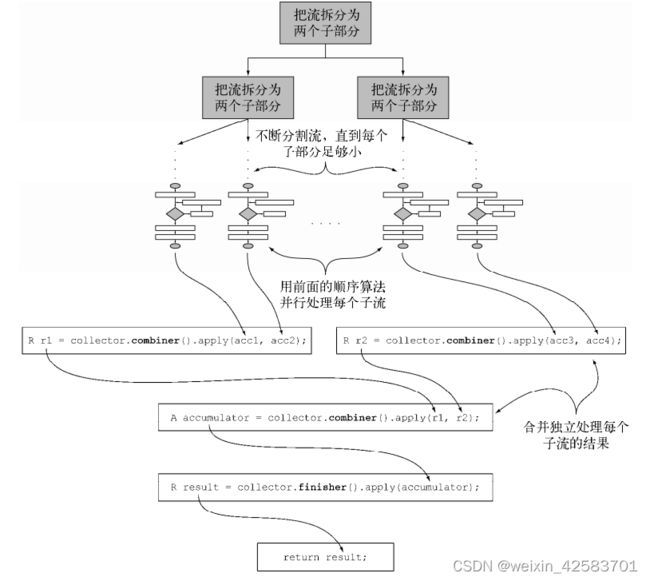
有了这第四个方法,就可以对流进行并行归约了。它会用到Java 7中引入的分支/合并框架和Spliterator抽象,这个过程类似于下图所示。
- 原始流会以递归方式拆分为子流,直到定义流是否需要进一步拆分的一个条件为非(如果分布式工作单位太小,并行计算往往比顺序计算要慢,而且要是生成的并行任务比处理器内核数多很多的话就毫无意义了)。
- 现在,所有的子流都可以并行处理,即对每个子流应用下图所示的顺序归约算法。
- 最后,使用收集器
combiner方法返回的函数,将所有的部分结果两两合并。这时会把原始流每次拆分时得到的子流对应的结果合并起来。
 5.characteristics方法
5.characteristics方法
最后一个方法——characteristics会返回一个不可变的Characteristics集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示。Characteristics是一个包含三个项目的枚举。
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。
- CONCURRENT——
accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约。 - IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查地转换为结果R是安全的。
迄今开发的ToListCollector是IDENTITY_FINISH的,因为用来累积流中元素的List已经是需要的最终结果,用不着进一步转换了,但它并不是UNORDERED,因为用在有序流上的时候,希望顺序能够保留在得到的List中。最后,它是CONCURRENT的,只仅在背后的数据源无序时才会并行处理。
全部融合到一起
可以把它们都融合起来,如下面的代码清单所示。
代码清单ToListCollector:
import java.util.*;
import java.util.function.*;
import java.util.stream.Collector;
import static java.util.stream.Collector.Characteristics.*;
public class ToListcollector<T> implements Collector<T, List<T>, List<T>> {
//创建集合操作的起始点
@Override
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
//累积遍历过的项目,原位修改累加器
@Override
public Biconsumer<List<T>, T> accumulator() {
return List::add;
}
//恒等函数
@Override
public Function<List<T>, List<T>> finisher() {
return Function.indentity();
}
@Override
public Binaryoperator<List<T>> combiner() {
return(list1, list2) -> {
list1.addAll(list2);//修改第一个累加器,将其与第二个累加器的内容合并
return list1; //返回修改后的第一个累加器
};
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(
IDENTITY_FINISH, CONCURRENT));//为收集器添加IDENTITY_PINISH和CONCURRENT标志
}
}
这个实现与Collectors.toList方法并不完全相同,但区别仅仅是一些小的优化。这些优化的一个主要方面是Java API所提供的收集器在需要返回空列表时使用了Collections.emptyList()这个单例(singleton)。这意味着它可安全地替代原生Java,来收集菜单流中的所有Dish的列表:
List<Dish> dishes = menustream.collect(new ToListCollector<Dish>());
这个实现和标准的
List<Dish> dishes = menuStream.collect(toList());
构造之间的其他差异在于toList是一个工厂,而ToListCollector必须用new来实例化。进行自定义收集而不去实现Collector对于IDENTITY_FINISH的收集操作,还有一种方法可以得到同样的结果而无需从头实现新的Collectors接口。Stream有一个重载的collect方法可以接受另外三个函数——supplier、accumulator和combiner,其语义和Collector接口的相应方法返回的函数完全相同。所以可以像下面这样把菜肴流中的项目收集到一个List中:
List<Dish> dishes = menuStream.collect(//供应源
ArrayList::new,
List::add, //累加器
List::addAll); //组合器
第二种形式虽然比前一个写法更为紧凑和简洁,却不那么易读。此外,以恰当的类来实现自己的自定义收集器有助于重用并可避免代码重复。另外值得注意的是,这第二个collect方法不能传递任何Characteristics,所以它永远都是一个IDENTITY_FINISH和CONCURRENT但并非UNORDERED的收集器。