PyTorch深度学习(四)【加载数据集、多分类问题】
加载数据集:使用mini-batch训练数据。
使用mini-batch之前先了解三个概念:(Batch之前聊过)Epoch、Batch-Size、Iterations。
第一个:Epoch.
当所有的训练样本进行了一次前向传播和反向传播,整个过程就叫做一个Epoch,也就是说把所有样本都参与了训练就叫做一个Epoch。
第二个:Batch-Size.
每次训练的时候,所用的样本数量叫做Batch-Size,批次大小。
第三个:Iterations.
假如你现在有1w个样本,batch-size是一千个,那么Iteration就是10。
ok,再看一下DataLoder:
当你拿到一个数据集,这个数据集呢需要支持索引,将来DataLoder能够访问到所有的元素,DataLoder还需要知道长度,这样DataLoder就能够对 dataset进行自动的小批量的数据集生成。
(数据集在上一篇文末获取)
代码:
import torchimport numpy as npfrom torch.utils.data import Dataset # utils:工具;Dataset:抽象类,不能实例化,只能被其他子类继承from torch.utils.data import DataLoader # DataLoader:加载数据,可以实例化# prepare datasetclass DiabetesDataset(Dataset): #自己定义的类。DiabetesDataset继承Datasetdef __init__(self, filepath): #初始化、读写。“filepath”:文件来自于什么地方,数据集地址xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) #读取32位浮点数self.len = xy.shape[0] # shape(多少行,多少列) n行9列self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])def __getitem__(self, index): #魔法方法。实例化后,这个对象能够支持下标操作。(取数)。根据索引返回数据样本return self.x_data[index], self.y_data[index]def __len__(self): #能把数据集的数据条数进行返回(数量)return self.lendataset = DiabetesDataset('diabetes.csv') #用自定义的类来实例化。构造数据对象train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) # num_workers 多线程#DataLoader是pytorch提供的一个加载器,在初始化的时候,一般有这四个参数。第一个加载数据集,第二个容量是多少;#第三个:是否打乱,第四个:在读数据的时候是否并行化,如果设为2,就是2个进程。并行化可以提高读取效率# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model()# construct loss and optimizercriterion = torch.nn.BCELoss(reduction='mean')optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# training cycle forward, backward, updateif __name__ == '__main__':for epoch in range(100): #一整批数据跑100遍for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch;i是当前迭代次数inputs, labels = data #x,y(都是张量)y_pred = model(inputs) #求y^loss = criterion(y_pred, labels) #求lossprint(epoch, i, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()
多分类问题
网络结构:
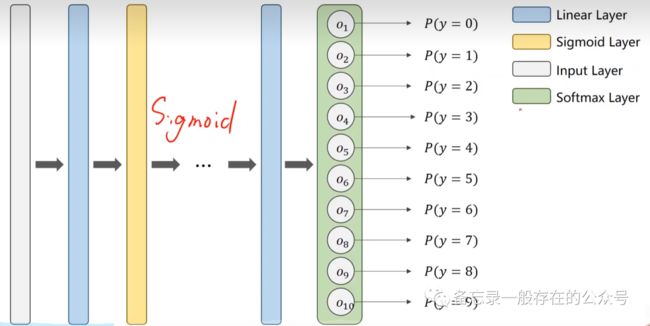
softmax层用的公式:

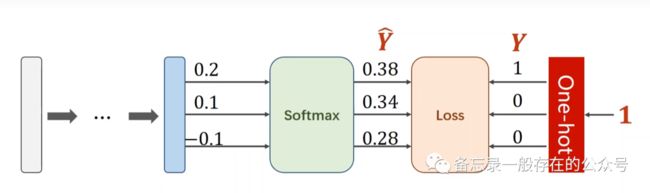
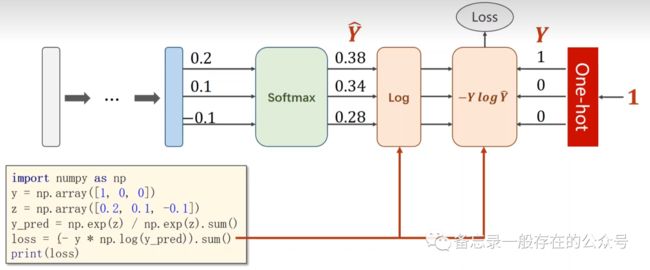
损失:
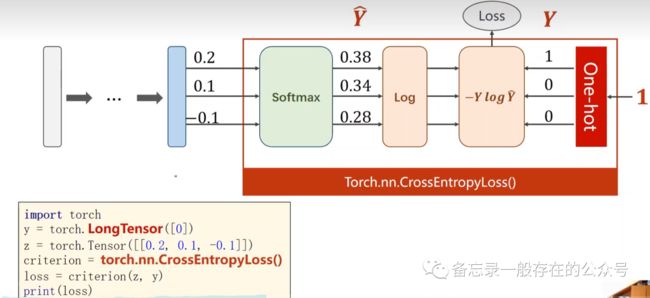
图像张量:


模型:

view():改变张量的形状,共784列;view之后得到n×784的矩阵。
代码:(对于代码中的数据集教大家一个方法如何获取,在文章靠后的位置)
import torchfrom torchvision import transforms #2~4行都是与数据集有关的包from torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as F #使用激活函数reluimport torch.optim as optim #优化器的包# prepare datasetbatch_size = 64 #设置batch_size大小transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差;PIL#“ToTensor”实现从“输入”到“pytorch”的格式(上面简介中的图有介绍);“Normalize”标准化;“(0.1307”:均值;“0.3081”:标准差;这个数字是在计算后得到的值train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform) #训练数据集train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.l1 = torch.nn.Linear(784, 512) #网络层self.l2 = torch.nn.Linear(512, 256)self.l3 = torch.nn.Linear(256, 128)self.l4 = torch.nn.Linear(128, 64)self.l5 = torch.nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 784) # -1其实就是自动获取mini_batch;改变形状x = F.relu(self.l1(x)) #每一层激活一下x = F.relu(self.l2(x))x = F.relu(self.l3(x))x = F.relu(self.l4(x))return self.l5(x) # 最后一层不做激活,不进行非线性变换model = Net() #把网络定义为model# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss() #交叉熵损失optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) #梯度下降,把冲量设置为0.5优化过程# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0): #又要训练又要测试# 获得一个批次的数据和标签inputs, target = data #x存到inputs,y存到targetoptimizer.zero_grad()# 获得模型预测结果(64, 10)outputs = model(inputs)# 交叉熵代价函数outputs(64,10),target(64)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item() #累计lossif batch_idx % 300 == 299: #输出print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) #每300轮输出一次lossrunning_loss = 0.0def test(): #test不需要计算梯度correct = 0total = 0with torch.no_grad(): #执行这句代码就不会计算梯度for data in test_loader: #从test_loader取数据images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度。把最大值下标取出来total += labels.size(0)correct += (predicted == labels).sum().item() # 张量之间的比较运算,比较完之后求和print('accuracy on test set: %d %% ' % (100 * correct / total)) #正确的数除以总数if __name__ == '__main__':for epoch in range(10): #训练10轮train(epoch) #一轮训练test() #一轮测试

数据集获取:
首先,它是用的手写数字识别的数据集,名字叫做mnist,将这个单词复制一下去你的电脑里面搜索,如下操作:(一般有过一点子小基础的安装过python相关的软件或者做过一些小项目都存在此文件,不存在就去网上下载,很多!)
稍等片刻,就会出现如下的内容:



完了之后,就可以运行了,数据集会自动下载,如下: