python使用imagededup实现图片去重(加深理解版)
问题描述:
任务一:对一个文件夹内相同图片进行去重操作。
任务二:有两个文件夹存放着图片(这里称之为新数据集与旧数据集),将新数据集中与旧数据集中相同的图片去除掉,并进行保存。
前面会对使用到的imagededup进行一些说明和介绍,可以加深理解方便使用,以后遇到去重任务可以更加轻松的进行处理,如果赶时间可以直接pip imagededup,复制下面任务代码更改路径,创建相应文件进行使用。
关于imagededup:
介绍
imagededup提供了非常强大的功能对文件进行去重操作,可以使用CNN、PHash、DHash、WHash、以及AHash这几种方法之一对图像生成编码,然后根据编码进行比对图像是否重复。
个人感觉与其他方法进行对比的话imagededup还是比较快捷方便的,主要要清楚它进行比对后输出的结果,才好进行后处理,拓展到更多复杂的图片去重任务上去。
环境配置:
我使用的conda虚拟环境进行安装imagededup,使用pycharm进行运行程序。注意imagededup与Python 3.8以上版本兼容,这里使用的imagededup的版本是0.3.1,根据官方文档imagededup0.2.2的下个版本更新时很多方法都进行了一些调整。
![]()
python版本:3.10.6
imagededup版本:0.3.1
核心代码解释
imagededup核心的代码部分是
from imagededup.methods import <method-name>
method_object = <method-name>()
duplicates = method_object.find_duplicates(image_dir='path/to/image/directory', <threshold-parameter-value>)
是不是看着巨简单有木有,没错,就是这么简单,剩下多余的代码全是对文件进行操作了,但它的代码可能会使用GPU进行计算。
主要参数解释:
method-name:对应的是去重使用的处理方法,可以设置为CNN、PHash、DHash、WHash、以及AHash这几种方法之一
image_dir:所有图像文件所在的目录
scores: 把它设置为 "True "会返回代表键文件中每个重复文件名的hamming距离(用于散列)或余弦相似度(用于cnn)的分数(这里我直接复制的官方使用文档,我也不太清楚什么是hamming距离和余弦相似度,反正是来比较相似度的一些指标,会用就完事了,如果想弄明白的话建议去看官方文档在这种情况下,返回的 "重复 "字典有以下内容:
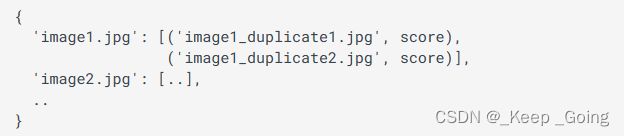
其中字典的键代表的是一个图片名(注意不是图片的完整路径,后续操作要加上图片的完整路径),键所对应的值为与之相似的图片的图片名。score对应是的相似的程度的一个分数。
这里有一些需要注意的地方,举个简单的例子:
from imagededup.methods import PHash
phasher = PHash()
duplicates = phasher.find_duplicates(image_dir=new_img_path)
print(new_dataset_duplicates)
这里的duplicates是一个字典,打印出来如下图所示![[Pasted image 20230427212227.png]]其中字典的键代表的是一个图片名(注意不是图片的完整路径,后续操作的话可以加上图片的完整路径),键所对应的值为与之相似的图片的图片名,拿前两个进行举例,第一的键代表图片是1.jpg,它的值为空,则说明这个文件中没有与其重复的图片;第二个是图片10.jpg,它所对应的值为[‘3.jpg’, ‘9.jpg’],则说明3.jpg和9.jpg与10.jpg是重复的。注意,字典中的键包含了文件中的每一个图片,值包含了文件中所有与键相同的图片,并不是3.jpg和9.jpg与10.jpg是重复的,后面就不会有他们了,可以看到上图中第四个键为 3.jpg,它的值为[‘10.jpg’, ‘9.jpg’]。
导入imagededup包:
pip install imagededup -i https://pypi.tuna.tsinghua.edu.cn/simple
结果如下,显示已经安装成功
![]()
任务一:
注意如果是windows系统的话要加上if name==‘main’: ,因为它会默认使用多线程进行处理,不加的话会报错。
完整代码:
import os
import shutil
from tqdm import tqdm
if __name__=='__main__':
from imagededup.methods import PHash
phasher = PHash()
new_img_path = r"path\" # 要处理的文件路径
merge = r"path\" # 合并后路径(是一个空文件夹路径,取用存放去重后不重复的图片)
new_dataset_duplicates = phasher.find_duplicates(image_dir=new_img_path)
print(new_dataset_duplicates)
new_k = []
new_v = []
for k, v in tqdm(new_dataset_duplicates.items(), desc="筛选新数据集"):
'''其实没必要搞这么麻烦,主要是防止出现类似 1:[], 2:[3, 1]或者
2:[3, 1], 1:[]的情况,但会大大增加计算量,要求不大的话一层for循环就能搞定'''
if len(v) == 0 and (k not in new_v):
new_k.append(k)
new_v.extend(v)
continue
if k not in new_v:
if len(new_k) == 0:
new_k.append(k)
new_v.extend(v)
continue
for jug in new_k:
if jug in v:
break
else:
new_k.append(k)
new_v.extend(v)
break
# 将新数据集中不重复的数据迁移到另一个文件夹中
for q in tqdm(new_k, desc='迁移不重复新数据集'):
local = os.path.join(new_img_path, q)
shutil.copy(local, merge)
任务二:
注意如果是windows系统的话要加上if name==‘main’: ,因为他会默认使用多线程进行处理,不加的话会报错。
import os
import shutil
from tqdm import tqdm
if __name__=='__main__':
# 使用PHash进行处理
from imagededup.methods import PHash
phasher = PHash()
# 将新数据集中重复的去除掉剩下不重复的图片
# 要建立两个空文件夹分别将路径赋值给下面merge和final——file
new_img_path = r"new\path" # 新数据集路径
old_img_path = r"old\path" # 旧数据集路径
merge = r"merge\path" # 合并后路径(空文件夹路径)
final_file = r"final\path" # 全部处理完之后保存新数据集图片的文件夹(空文件夹路径)
# 筛选新数据集
# 下面这行代码时实现编码和进行比对的关键代码
new_dataset_duplicates = phasher.find_duplicates(image_dir=new_img_path)
new_k = []
new_v = []
for k, v in tqdm(new_dataset_duplicates.items(), desc="筛选新数据集"):
'''其实没必要搞这么麻烦,主要是防止出现类似 1:[], 2:[3, 1]或者
2:[3, 1], 1:[]的情况,但会大大增加计算量,要求不大的话一层for循环就能搞定'''
if len(v) == 0 and (k not in new_v):
new_k.append(k)
new_v.extend(v)
continue
if k not in new_v:
if len(new_k) == 0:
new_k.append(k)
new_v.extend(v)
continue
for jug in new_k:
if jug in v:
break
else:
new_k.append(k)
new_v.extend(v)
break
# 将新数据集中不重复的数据迁移到另一个文件夹中
for q in tqdm(new_k, desc='迁移不重复新数据集'):
local = os.path.join(new_img_path, q)
shutil.copy(local, merge)
# 对新旧数据集合并
old_dataset_list = os.listdir(old_img_path)
for k in tqdm(old_dataset_list, desc="合并新旧数据集"):
move = os.path.join(old_img_path, k)
shutil.copy(move, merge)
# 处理合并后的新旧数据集,挑出合并后与旧数据集不重复的新数据集
duplicates_all = phasher.find_duplicates(image_dir=merge)
print(duplicates_all)
keys = []
# 如果新数据集中的图片既不在之前的数据集中,也没有和它相同的,那么就将它添加到k中。
for k, v in duplicates_all.items():
if len(v) == 0 and (k not in old_dataset_list):
keys.append(k)
# 将合并后不重复的新数据集数据移动到final_file中
for k in tqdm(keys, desc="final treatment"):
all_uniq = os.path.join(merge, k)
shutil.copy(all_uniq, final_file)
总结
这里我代码处理文件的部分写的不是很好,使用了两层for循环来避免出现问题,如果数据量太大的话也可以对文件处理部分进行修改,用空间换时间,如果想更熟练的运用imagededup,可以去阅读官方文档,或者看一下官方给出的几个例子。