【C++基于多设计模式下的同步&异步日志系统】
文章目录
-
- @[toc]
- 1 :peach:项目介绍:peach:
- 2 :peach:开发环境:peach:
- 3 :peach:核心技术:peach:
- 4 :peach:环境搭建:peach:
- 5 :peach:日志系统介绍:peach:
-
- 5.1 :apple:为什么需要日志系统?:apple:
- 5.2 :apple:日志系统技术实现:apple:
-
- 5.2.1 :lemon:同步写日志:lemon:
- 5.2.2 :lemon:异步写日志:lemon:
- 6 :peach:相关技术知识补充:peach:
-
- 6.1 :apple:不定参函数:apple:
-
- 6.1.1 :lemon:不定参宏函数:lemon:
- 6.1.2 :lemon:C风格不定参函数:lemon:
- 6.1.3 :lemon:C++风格不定参函数:lemon:
- 6.2 :apple:设计模式:apple:
-
- 6.2.1 :lemon:六大原则:lemon:
- 6.2.2 :lemon:单例模式:lemon:
- 6.2.3 :lemon:工厂模式:lemon:
- 6.2.4 :lemon:建造者模式:lemon:
- 6.2.5 :lemon:代理模式:lemon:
- 7 :peach:日志系统框架设计:peach:
-
- 7.1 :apple:模块划分:apple:
- 8 :peach:代码设计(重要):peach:
-
- 8.1 :apple:实用类设计:apple:
- 8.2 :apple:日志等级类设计:apple:
- 8.3 :apple:日志消息类设计:apple:
- 8.4 :apple:日志输出格式化类设计:apple:
- 8.5 :apple:日志落地类设计:apple:
- 8.6 :apple:日志器类设计:apple:
- 8.7 :apple:双缓冲区异步任务处理器设计:apple:
- 8.8 :apple:异步日志器设计:apple:
- 8.9 :apple:单例日志器管理类设计:apple:
- 8.10 :apple:日志宏&全局接口设计:apple:
- 9 :peach:性能测试:peach:
-
- 9.1 :apple:测试环境:apple:
- 9.2 :apple:测试方法:apple:
- 9.3 :apple:测试结果与结论:apple:
-
- 9.3.1 :lemon:单线程同步日志:lemon:
- 9.3.2 :lemon:多线程同步日志:lemon:
- 9.3.3 :lemon:单线程异步日志:lemon:
- 9.3.4 :lemon:多线程异步日志:lemon:
- 9.3.5 :lemon:结论:lemon:
- 10 :peach:扩展:peach:
文章目录
-
- @[toc]
- 1 :peach:项目介绍:peach:
- 2 :peach:开发环境:peach:
- 3 :peach:核心技术:peach:
- 4 :peach:环境搭建:peach:
- 5 :peach:日志系统介绍:peach:
-
- 5.1 :apple:为什么需要日志系统?:apple:
- 5.2 :apple:日志系统技术实现:apple:
-
- 5.2.1 :lemon:同步写日志:lemon:
- 5.2.2 :lemon:异步写日志:lemon:
- 6 :peach:相关技术知识补充:peach:
-
- 6.1 :apple:不定参函数:apple:
-
- 6.1.1 :lemon:不定参宏函数:lemon:
- 6.1.2 :lemon:C风格不定参函数:lemon:
- 6.1.3 :lemon:C++风格不定参函数:lemon:
- 6.2 :apple:设计模式:apple:
-
- 6.2.1 :lemon:六大原则:lemon:
- 6.2.2 :lemon:单例模式:lemon:
- 6.2.3 :lemon:工厂模式:lemon:
- 6.2.4 :lemon:建造者模式:lemon:
- 6.2.5 :lemon:代理模式:lemon:
- 7 :peach:日志系统框架设计:peach:
-
- 7.1 :apple:模块划分:apple:
- 8 :peach:代码设计(重要):peach:
-
- 8.1 :apple:实用类设计:apple:
- 8.2 :apple:日志等级类设计:apple:
- 8.3 :apple:日志消息类设计:apple:
- 8.4 :apple:日志输出格式化类设计:apple:
- 8.5 :apple:日志落地类设计:apple:
- 8.6 :apple:日志器类设计:apple:
- 8.7 :apple:双缓冲区异步任务处理器设计:apple:
- 8.8 :apple:异步日志器设计:apple:
- 8.9 :apple:单例日志器管理类设计:apple:
- 8.10 :apple:日志宏&全局接口设计:apple:
- 9 :peach:性能测试:peach:
-
- 9.1 :apple:测试环境:apple:
- 9.2 :apple:测试方法:apple:
- 9.3 :apple:测试结果与结论:apple:
-
- 9.3.1 :lemon:单线程同步日志:lemon:
- 9.3.2 :lemon:多线程同步日志:lemon:
- 9.3.3 :lemon:单线程异步日志:lemon:
- 9.3.4 :lemon:多线程异步日志:lemon:
- 9.3.5 :lemon:结论:lemon:
- 10 :peach:扩展:peach:
1 项目介绍
本项⽬主要实现⼀个⽇志系统, 其主要⽀持以下功能:
- 1️⃣⽀持多级别⽇志消息;
- 2️⃣⽀持同步⽇志和异步⽇志;
- 3️⃣⽀持可靠写⼊⽇志到控制台、⽂件以及滚动⽂件中;
- 4️⃣⽀持多线程程序并发写⽇志;
- 5️⃣⽀持扩展不同的⽇志落地⽬标.
2 开发环境
- 1️⃣CentOS 7.6(2核,内存2GB,SSD云硬盘40GB)
- 2️⃣vscode/vim
- 3️⃣g++/gdb
- 4️⃣Makefile
3 核心技术
- 1️⃣类层次设计(继承和多态的应⽤)
- 2️⃣C++11(多线程、bind、智能指针、右值引用、互斥锁等)
- 3️⃣双缓冲区
- 4️⃣生产消费模型
- 6️⃣设计模式(单例、工厂、代理、模板等)
4 环境搭建
本项⽬不依赖其他任何第三⽅库, 只需要安装好CentOS/Ubuntu + vscode/vim环境即可开发。
5 日志系统介绍
5.1 为什么需要日志系统?
- ⽣产环境的产品为了保证其稳定性及安全性是不允许开发⼈员附加调试器去排查问题, 可以借助日志系统来打印⼀些⽇志帮助开发⼈员解决问题;
- 上线客户端的产品出现bug⽆法复现并解决, 可以借助日志系统打印⽇志并上传到服务端帮助开发⼈员进⾏分析;
- 对于⼀些⾼频操作(如定时器、心跳包)在少量调试次数下可能⽆法触发我们想要的⾏为,通过断点的暂停⽅式,我们不得不重复操作⼏⼗次、上百次甚⾄更多,导致排查问题效率是⾮常低下, 可以借助打印⽇志的⽅式查问题;
- 在分布式、多线程/多进程代码中, 出现bug比较难以定位, 可以借助⽇志系统打印log帮助定位bug;
- 帮助⾸次接触项⽬代码的新开发⼈员理解代码的运⾏流程。
5.2 日志系统技术实现
⽇志系统的技术实现主要包括三种类型:
- 利⽤
printf、std::cout等输出函数将⽇志信息打印到控制台; - 对于⼤型商业化项⽬, 为了⽅便排查问题,我们⼀般会将⽇志输出到⽂件或者是数据库系统⽅便查询和分析⽇志, 主要分为
同步⽇志和异步⽇志⽅式。
5.2.1 同步写日志
同步日志是指当输出日志时,必须等待⽇志输出语句执⾏完毕后,才能执⾏后⾯的业务逻辑语句,日志输出语句与程序的业务逻辑语句将在同⼀个线程运⾏。每次调⽤⼀次打印⽇志API就对应⼀次系统调⽤write写⽇志⽂件。

但是在⾼并发场景下,随着⽇志数量不断增加,同步⽇志系统容易产⽣系统瓶颈:
- ⼀⽅⾯,⼤量的⽇志打印陷入等量的
write系统调⽤,有⼀定系统开销; - 另⼀⽅⾯,使得打印⽇志的进程附带了⼤量同步的磁盘IO,程序性能下降。(一旦输出日志的进程阻塞,整个流程都将不被推进)
5.2.2 异步写日志
异步日志是指在进行日志输出时,日志输出语句与业务逻辑语句并不是在同⼀个线程中运行,⽽是有专⻔的线程⽤于进⾏⽇志输出操作。业务线程只需要将⽇志放到⼀个内存缓冲区中不⽤等待即可继续执后续业务逻辑(作为⽇志的⽣产者),⽽⽇志的落地操作交给单独的⽇志线程去完成(作为⽇志的消费者), 这是⼀个典型的生产者-消费者模型。
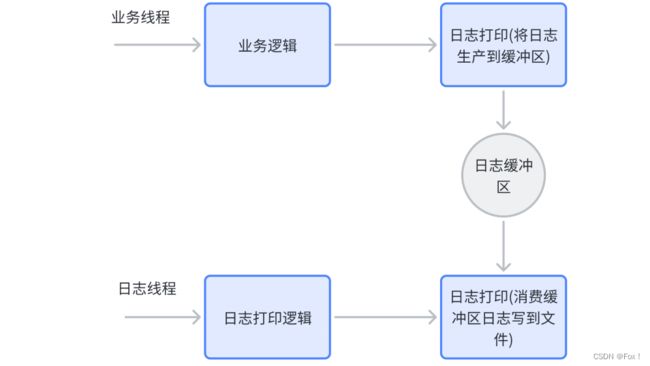
这样做的好处是即使日志没有真的完成输出也不会影响程序的主业务,可以提⾼程序的性能:
- 主线程调⽤⽇志打印接⼝成为非阻塞操作(因为主线程只需要将日志消息放在日志缓冲区即可);
- 同步的磁盘IO从主线程中剥离出来交给单独的线程完成。
6 相关技术知识补充
6.1 不定参函数
在初学C语⾔的时候,我们都⽤过printf函数进⾏打印。其中printf函数就是⼀个不定参函数,在函数内部可以根据格式化字符串中格式化字符分别获取不同的参数进⾏数据的格式化。而这种不定参函数在实际的使⽤中也⾮常多见。
6.1.1 不定参宏函数
#include 
6.1.2 C风格不定参函数
#include 
6.1.3 C++风格不定参函数
#include 
6.2 设计模式
设计模式是大佬们对代码开发经验的总结,是解决特定问题的⼀系列套路。它不是语法规定,⽽是⼀套⽤来提⾼代码可复⽤性、可维护性、可读性、稳健性以及安全性的解决方案。
6.2.1 六大原则
-
1️⃣单⼀职责原则(Single Responsibility Principle)
类的职责应该单⼀,⼀个方法只做⼀件事。职责划分清晰了,每次改动到最小单位的⽅法或类;使用建议:两个完全不⼀样的功能不应该放⼀个类中,⼀个类中应该是⼀组相关性很⾼的函数、数据的封装;比如:在网络聊天中,应该分割成为网络通信类 & 聊天类。 -
2️⃣开闭原则(Open Closed Principle)
对扩展开放,对修改封闭。使⽤建议:对软件实体的改动,最好⽤扩展而非修改的⽅式;比如在超时卖货中,商品价格并不是修改商品的原来价格,而是新增促销价格。 -
3️⃣里氏替换原则(Liskov Substitution Principle)
通俗点讲,就是只要父类能出现的地方,子类就可以出现,而且替换为子类也不会产⽣任何错误或异常;在继承类时,务必重写⽗类中所有的⽅法,尤其需要注意⽗类的protected⽅法,子类尽量不要暴露⾃⼰的public⽅法供外界调⽤。使⽤建议:子类必须完全实现⽗类的⽅法,且⼦类可以有⾃⼰的个性,覆盖或实现⽗类的⽅法时,输⼊参数可以被放⼤,输出可以缩⼩;比如跑步运动员类-会跑步,子类长跑运动员-会跑步且擅长长跑, 子类短跑运动员-会跑步且擅⻓短跑。 -
4️⃣依赖倒置原则(Dependence Inversion Principle)
高层模块不应该依赖低层模块,两者都应该依赖其抽象. 不可分割的原子逻辑就是低层模式,原⼦逻辑组装成的就是⾼层模块;模块间依赖通过抽象(接⼝)发⽣,具体类之间不直接依赖。使⽤建议:每个类都尽量有抽象类,任何类都不应该从具体类派生;尽量不要重写基类的方法;结合里氏替换原则使⽤。例如奔驰车司机类–只能开奔驰; 司机类–给什么⻋,就开什么⻋; 开车的人–依赖于抽象。 -
5️⃣迪米特法则(Law of Demeter)
⼜叫“最少知道法则”,尽量减少对象之间的交互,从⽽减⼩类之间的耦合。⼀个对象应该对其他对象最少的了解;对类的低耦合提出了明确的要求:只和直接的朋友交流, 朋友之间也是有距离的,⾃⼰的就是⾃⼰的(如果⼀个⽅法放在本类中,既不增加类间关系,也对本类不产⽣负⾯影响,那就放置在本类中)比如⽼师让班⻓点名,⽼师给班⻓⼀个名单,班⻓完成点名勾选,返回结果,⽽不是班⻓点名,⽼师勾选。 -
6️⃣接口隔离原则(Interface Segregation Principle)
客户端不应该依赖它不需要的接⼝,类间的依赖关系应该建⽴在最小的接⼝上。使⽤建议:接⼝设计尽量精简单⼀,但是不要对外暴露没有实际意义的接⼝。比如在修改密码时,不应该提供修改用户信息接⼝,⽽提供单⼀的最小修改密码接⼝,更不要暴露数据库操作。
从整体上来理解六⼤设计原则,可以简要的概括为⼀句话:⽤抽象构建框架,用实现扩展细节,具体到每⼀条设计原则,则对应⼀条注意事项:
- 单⼀职责原则告诉我们实现类要职责单⼀;
- ⾥⽒替换原则告诉我们不要破坏继承体系;
- 依赖倒置原则告诉我们要向接口编程;
- 接⼝隔离原则告诉我们在设计接⼝的时候要精简单⼀;
- 迪⽶特法则告诉我们要降低耦合;
- 开闭原则是总纲,告诉我们要对扩展开放,对修改关闭。
6.2.2 单例模式
⼀个类只能创建⼀个对象,即单例模式,该设计模式可以保证系统中该类只有⼀个实例,并提供⼀个访问它的全局访问点,该实例被所有程序模块共享。⽐如在某个服务器程序中,该服务器的配置信息存放在⼀个⽂件中,这些配置数据由⼀个单例对象统⼀读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种⽅式简化了在复杂环境下的配置管理。
单例模式有两种实现模式:饿汉模式和懒汉模式
- 饿汉模式: 程序启动时就会创建⼀个唯⼀的实例对象。 因为单例对象已经确定, 所以⽐较适⽤于多线程环境中, 多线程获取单例对象不需要加锁, 可以有效的避免资源竞争, 提⾼性能。但是如果单例对象过大可能够导致程序的加载速度会变慢。
class Singleton
{
private:
static Singleton _eton;
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
public:
static Singleton& getInstance()
{
return _eton;
}
};
Singleton Singleton::_eton;
- 懒汉模式:第⼀次使⽤要使⽤单例对象的时候创建实例对象。如果单例对象构造特别耗时或者耗费资源(加载插件、加载⽹络资源等), 可以选择懒汉模式, 在第⼀次使⽤的时候才创建对象。
在之前讲解线程池的时候博主是用了双重if条件判断来加锁,这里介绍一种更为简便的方式:
这⾥介绍的是《Effective C++》⼀书作者 Scott Meyers 提出的⼀种更加优雅简便的单例模式:C++11 Static local variables 特性以确保,C++11起,静态变量将能够在满足thread-safe的前提下唯⼀地被构造和析构。
所以我们可以使用下面的方式:
// 懒汉模式
class Singleton
{
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
public:
static Singleton& getInstance()
{
static Singleton _eton;
return _eton;
}
};
6.2.3 工厂模式
工厂模式是⼀种创建型设计模式, 它提供了⼀种创建对象的最佳⽅式。在工厂模式中,我们创建对象时不会对上层暴露创建逻辑,而是通过使⽤⼀个共同结构来指向新创建的对象,以此实现创建-使⽤的分离。
工厂模式可以分为:简单工厂模式,工厂方法模式,抽象工厂模式。
- 1️⃣简单工厂模式:简单⼯⼚模式实现由⼀个⼯⼚对象通过类型决定创建出来指定产品类的实例。假设有个⼯⼚能⽣产出⽔果,当客户需要产品的时候明确告知⼯⼚⽣产哪类⽔果,⼯⼚需要接收⽤⼾提供的类别信息,当新增产品的时候,⼯⼚内部去添加新产品的⽣产⽅式。
/*简单工厂模式*/
class Fruit
{
public:
virtual void show() = 0;
};
class Apple : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个苹果" << std::endl;
}
};
class Peach : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个桃子" << std::endl;
}
};
class FruitFactory
{
public:
static std::shared_ptr<Fruit> create(const std::string &name = "")
{
if (name == "苹果")
return std::make_shared<Apple>();
else if (name == "桃子")
return std::make_shared<Peach>();
else
return std::shared_ptr<Fruit>();
}
};
int main()
{
std::shared_ptr<Fruit> obj = FruitFactory::create("苹果");
if (obj.get() != nullptr)
obj->show();
obj = FruitFactory::create("桃子");
if (obj.get() != nullptr)
obj->show();
return 0;
}
简单⼯⼚模式:通过参数控制可以⽣产任何产品(将所有的产品都放在一个工厂中生产)。
优点:简单粗暴,直观易懂。使⽤⼀个⼯⼚⽣产同⼀等级结构下的任意产品。缺点:所有东西⽣产在⼀起,产品太多会导致代码量庞⼤;开闭原则遵循(开放拓展,关闭修改)的不是太好,要新增产品就必须修改工厂方法。
- 2️⃣工厂⽅法模式: 在简单⼯⼚模式下新增多个⼯⼚,多个产品,每个产品对应⼀个⼯⼚。假设现在有A、B 两种产品,则开两个⼯⼚,⼯⼚ A 负责⽣产产品 A,⼯⼚ B 负责⽣产产品 B,⽤⼾只知道产品的⼯⼚名,⽽不知道具体的产品信息,⼯⼚不需要再接收客户的产品类别,⽽只负责⽣产产品。
/*工厂方法模式*/
class Fruit
{
public:
virtual void show() = 0;
};
class Apple : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个苹果" << std::endl;
}
};
class Peach : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个桃子" << std::endl;
}
};
class FruitFactory
{
public:
virtual std::shared_ptr<Fruit> create()=0;
};
class AppleFactory:public FruitFactory
{
public:
virtual std::shared_ptr<Fruit> create()
{
return std::make_shared<Apple>();
}
};
class PeachFactory:public FruitFactory
{
public:
virtual std::shared_ptr<Fruit> create()
{
return std::make_shared<Peach>();
}
};
int main()
{
std::shared_ptr<FruitFactory> factory(new AppleFactory);
auto obj = factory->create();
obj->show();
factory.reset(new PeachFactory);
obj = factory->create();
obj->show();
return 0;
}
⼯⼚⽅法:定义⼀个创建对象的接⼝,由⼦类来决定创建哪种对象,使⽤多个⼯⼚分别⽣产指定的固定产品。(每种产品均对应着一种工厂)
优点:减轻了⼯⼚类的负担,将某类产品的⽣产交给指定的⼯⼚来进⾏;开闭原则(扩展而非修改)遵循较好,添加新产品只需要新增产品的⼯⼚即可,不需要修改原先的⼯⼚类。缺点:对于某种可以形成⼀组产品族的情况处理较为复杂,需要创建⼤量的⼯⼚类。
- 3️⃣ 抽象工厂模式: ⼯⼚⽅法模式通过引⼊⼯⼚等级结构,解决了简单⼯⼚模式中⼯⼚类职责太重的问题,但由于⼯⼚⽅法模式中的每个⼯⼚只⽣产⼀类产品,可能会导致系统中存在⼤量的⼯⼚类,势必会增加系统的开销。此时,我们可以考虑将⼀些相关的产品组成⼀个产品族(位于不同产品等级结构中功能相关联的产品组成的家族),由同⼀个⼯⼚来统⼀⽣产,这就是抽象⼯⼚模式的基本思想。
/*抽象工厂模式*/
class Fruit
{
public:
virtual void show() = 0;
};
class Apple : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个苹果" << std::endl;
}
};
class Peach : public Fruit
{
public:
virtual void show()
{
std::cout << "我是一个桃子" << std::endl;
}
};
class Vegetable
{
public:
virtual void show() = 0;
};
class Potato : public Vegetable
{
public:
virtual void show()
{
std::cout << "我是一个土豆" << std::endl;
}
};
class Lettuce : public Vegetable
{
public:
virtual void show()
{
std::cout << "我是一片生菜" << std::endl;
}
};
class Factory
{
public:
virtual std::shared_ptr<Fruit> create_fruit(const std::string &name = "") = 0;
virtual std::shared_ptr<Vegetable> create_Vegetable(const std::string &name = "") = 0;
};
class FruitFactory : public Factory
{
public:
virtual std::shared_ptr<Fruit> create_fruit(const std::string &name = "")
{
if (name == "苹果")
return std::make_shared<Apple>();
else if (name == "桃子")
return std::make_shared<Peach>();
else
return std::shared_ptr<Fruit>();
}
virtual std::shared_ptr<Vegetable> create_Vegetable(const std::string &name = "")
{
return std::shared_ptr<Vegetable>();
}
};
class VegetableFactory : public Factory
{
public:
virtual std::shared_ptr<Vegetable> create_Vegetable(const std::string &name = "")
{
if (name == "土豆")
return std::make_shared<Potato>();
else if (name == "生菜")
return std::make_shared<Lettuce>();
else
return std::shared_ptr<Vegetable>();
}
virtual std::shared_ptr<Fruit> create_fruit(const std::string &name = "")
{
return std::shared_ptr<Fruit>();
}
};
class CreateFactory
{
public:
static std::shared_ptr<Factory> get_factory(const std::string &name = "")
{
if (name == "水果")
return std::make_shared<FruitFactory>();
else if (name == "蔬菜")
return std::make_shared<VegetableFactory>();
else
return std::shared_ptr<Factory>();
}
};
int main()
{
std::shared_ptr<Factory> vegetable_factory = CreateFactory::get_factory("蔬菜");
if (vegetable_factory.get() != nullptr)
{
std::shared_ptr<Vegetable> vegetable = vegetable_factory->create_Vegetable("土豆");
if (vegetable.get() != nullptr)
vegetable->show();
vegetable = vegetable_factory->create_Vegetable("生菜");
if (vegetable.get() != nullptr)
vegetable->show();
}
std::shared_ptr<Factory> fruit_factory = CreateFactory::get_factory("水果");
if (fruit_factory.get() != nullptr)
{
std::shared_ptr<Fruit> fruit = fruit_factory->create_fruit("桃子");
if (fruit.get() != nullptr)
fruit->show();
fruit = fruit_factory->create_fruit("苹果");
if (fruit.get() != nullptr)
fruit->show();
}
return 0;
}
抽象⼯⼚:围绕⼀个超级⼯⼚创建其他⼯⼚,每个⽣成的⼯⼚按照⼯⼚模式提供对象;将⼯⼚抽象成两层,抽象⼯厂&具体⼯⼚⼦类, 在⼯⼚⼦类种⽣产不同类型的⼦产品。
优点:解决了简单⼯⼚模式中⼯⼚类职责太重的问题;解决了工厂方法类中要创建大量子类工厂的问题。缺点:抽象⼯⼚模式适⽤于⽣产多个⼯⼚系列产品衍⽣的设计模式,增加新的产品等级结构复杂,需要对原有系统进⾏较⼤的修改,甚⾄需要修改抽象层代码,违背了“开闭原则”。
6.2.4 建造者模式
建造者模式是⼀种创建型设计模式, 使用多个简单的对象⼀步⼀步构建成⼀个复杂的对象,能够将⼀个复杂的对象的构建与它的表⽰分离,提供⼀种创建对象的最佳⽅式。主要⽤于解决对象的构建过于复杂的问题。
建造者模式主要基于五个核⼼类实现:
- 抽象产品类;
- 具体产品类:⼀个具体的产品对象类;
- 抽象Builder类:创建⼀个产品对象所需的各个部件的抽象接⼝;
- 具体产品的Builder类:实现抽象接⼝,构建各个部件;
- 指挥者Director类:统⼀组建过程,提供给调⽤者使⽤,通过指挥者来构造产品。(注意:当构建产品时有顺序要求时我们要加上指挥者来按顺序帮助我们构建产品,但是如果没有顺序要求的话指挥者是可以省略的)
/*建造者模式*/
class Computer
{
public:
void set_board(const std::string &board)
{
_board = board;
}
void set_display(const std::string &display)
{
_display = display;
}
std::string show_argument()
{
std::string computer = "Computer:{\n";
computer += "\tboard=" + _board + ",\n";
computer += "\tdisplay=" + _display + ",\n";
computer += "\tOs=" + _os + ",\n";
computer += "}\n";
std::cout<<computer<<std::endl;
return computer;
}
virtual void set_os()=0;
protected:
std::string _board;
std::string _display;
std::string _os;
};
class Macbook:public Computer
{
public:
virtual void set_os() override
{
_os="MAC OS X13";
}
};
class Builder
{
public:
virtual void build_board(const std::string &board)=0;
virtual void build_display(const std::string &display)=0;
virtual void build_os()=0;
virtual std::shared_ptr<Computer> build()=0;
};
class BuilderMacbook:public Builder
{
public:
BuilderMacbook()
: _computer(new Macbook())
{}
virtual void build_board(const std::string &board)override
{
_computer->set_board(board);
}
virtual void build_display(const std::string &display)override
{
_computer->set_display(display);
}
virtual void build_os()override
{
_computer->set_os();
}
virtual std::shared_ptr<Computer> build()
{
return _computer;
}
private:
std::shared_ptr<Computer> _computer;
};
class Director
{
public:
Director(Builder* bulider)
:_builder(bulider)
{}
void construct(const std::string &board,const std::string &display)
{
_builder->build_board(board);
_builder->build_display(display);
_builder->build_os();
}
std::shared_ptr<Computer> get_computer()
{
return _builder->build();
}
private:
std::shared_ptr<Builder> _builder;
};
int main()
{
std::shared_ptr<Builder> builder(new BuilderMacbook());
std::shared_ptr<Director> director(new Director(builder.get()));
director->construct("Inter主板","MAC显示器");
director->get_computer()->show_argument();
return 0;
}
6.2.5 代理模式
代理模式指代理控制对其他对象的访问, 也就是代理对象控制对原对象的引⽤。在某些情况下,⼀个对象不适合或者不能直接被引⽤访问,⽽代理对象可以在客户端和⽬标对象之间起到中介的作⽤。代理模式的结构包括⼀个是真正的你要访问的对象(⽬标类)、⼀个是代理对象。⽬标对象与代理对象实现同⼀个接⼝,先访问代理类再通过代理类访问⽬标对象。代理模式分为静态代理、动态代理。
- 静态代理指的是,在编译时就已经确定好了代理类和被代理类的关系。也就是说,在编译时就已经确定了代理类要代理的是哪个被代理类。
- 动态代理指的是,在运⾏时才动态⽣成代理类,并将其与被代理类绑定。这意味着,在运⾏时才能确定代理类要代理的是哪个被代理类。
class RentHouse
{
public:
virtual void rent_house() = 0;
};
/*房东类:将房⼦租出去*/
class Landlord : public RentHouse
{
public:
virtual void rent_house()
{
std::cout << "将房⼦租出去"<<std::endl;
}
};
/*中介代理类:对租房⼦进⾏功能加强,实现租房以外的其他功能*/
class Intermediary : public RentHouse
{
public:
virtual void rent_house()
{
std::cout << "发布招租启⽰\n";
std::cout << "带⼈看房\n";
_landlord.rent_house();
std::cout << "负责租后维修\n";
}
private:
Landlord _landlord;
};
int main()
{
Intermediary intermediary;
intermediary.rent_house();
return 0;
}
7 日志系统框架设计
本项⽬实现的是⼀个多⽇志器⽇志系统,主要实现的功能是让程序员能够轻松的将程序运⾏⽇志信息落地到指定的位置,且⽀持同步与异步两种⽅式的⽇志落地⽅式。
项⽬的框架设计将项⽬分为以下⼏个模块来实现。
7.1 模块划分
-
1️⃣日志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符功能。
Debug:调试,调试时的关键信息输出;
Infor:提⽰,普通的提⽰型⽇志信息;
Warnning:警告,不影响运⾏,但是需要注意⼀下的⽇志;
Error:错误,程序运⾏出现错误的⽇志;
Fatal:致命,⼀般是代码异常导致程序⽆法继续推进运⾏的⽇志;
Ukonwn:未知错误;
Off:关闭。 -
2️⃣日志消息模块:中间存储日志输出所需的各项要素信息;
时间:描述本条⽇志的输出时间;
线程ID:描述本条⽇志是哪个线程输出的;
日志等级:描述本条⽇志的等级;
日志数据:本条⽇志的有效载荷数据;
日志⽂件名:描述本条⽇志在哪个源码⽂件中输出的;
日志行号:描述本条⽇志在源码⽂件的哪⼀⾏输出的。 -
3️⃣ 日志消息格式化模块:设置日志输出格式,并提供对日志消息进⾏格式化功能。
系统的默认⽇志输出格式:
[%d{%H:%M:%S}][%t][%p][%c][%f:%l]%T%m%n
%d{%H:%M:%S}:表⽰⽇期时间,花括号中的内容表示日期时间的格式;
%T:表⽰制表符缩进;
%t:表⽰线程ID;
%p:表⽰⽇志级别;
%c:表⽰⽇志器名称,不同的开发组可以创建⾃⼰的⽇志器进⾏⽇志输出,⼩组之间互不影响;
%f:表⽰⽇志输出时的源代码⽂件名;
%l:表⽰⽇志输出时的源代码⾏号;
%m:表⽰给与的⽇志有效载荷数据;
%n:表⽰换行。
设计思想:设计不同的⼦类,不同的⼦类从⽇志消息中取出不同的数据进⾏处理。
- 4️⃣日志消息落地模块:决定了日志的落地⽅向,可以是标准输出,也可以是⽇志⽂件,也可以滚动⽂件输出。
标准输出:表⽰将⽇志进⾏标准输出的打印;
日志⽂件输出:表⽰将⽇志写⼊指定的⽂件末尾;
滚动⽂件输出:当前以⽂件⼤⼩进⾏控制,当⼀个⽇志⽂件⼤⼩达到指定⼤⼩,则切换下⼀个⽂件进⾏输出后期,也可以扩展远程⽇志输出,创建客户端,将⽇志消息发送给远程的⽇志分析服务器。
设计思想:设计不同的子类,不同的子类控制不同的⽇志落地⽅向。
-
5️⃣日志器模块:此模块是对以上几个模块的整合模块,⽤户通过日志器进行日志的输出,有效降低⽤户的使用难度。包含有:日志消息落地模块对象,日志消息格式化模块对象,日志输出等级。
-
6️⃣日志器管理模块:为了降低项⽬开发的⽇志耦合,不同的项⽬组可以有⾃⼰的⽇志器来控制输出格式以及落地⽅向,因此本项⽬是⼀个多⽇志器的⽇志系统;管理模块就是对创建的所有⽇志器进行统⼀管理。并提供⼀个默认⽇志器提供标准输出的日志输出。
-
7️⃣异步线程模块:实现对日志的异步输出功能,用户只需要将输出⽇志任务放⼊任务池,异步线程负责⽇志的落地输出功能,以此提供更加高效的非阻塞⽇志输出。
8 代码设计(重要)
8.1 实用类设计
提前完成⼀些零碎的功能接⼝,以便于项⽬中会⽤到。
- 获取系统时间
- 判断⽂件是否存在
- 获取⽂件的所在⽬录路径
- 创建⽬录
此类我们设计在Utill.hpp中:
#pragma once
/*通⽤功能类,与业务⽆关的功能实现
1. 获取系统时间
2. 获取⽂件⼤⼩
3. 创建⽬录
4. 获取⽂件所在⽬录*/
#include 8.2 日志等级类设计
日志等级总共分为7个等级,分别为:
- 1️⃣Off 关闭所有⽇志输出;
- 2️⃣Debug 进⾏debug时候打印日志的等级;
- 3️⃣Infor 打印⼀些⽤户提⽰信息;
- 4️⃣Warnning 打印警告信息;
- 5️⃣Error 打印错误信息;
- 6️⃣Fatal 打印致命信息,导致程序崩溃的信息。
- 7️⃣Uknown未知错误。
日志等级类我们设计在LogLevel.hpp中:
#pragma once
#include8.3 日志消息类设计
日志消息类主要是封装⼀条完整的⽇志消息所需的内容,其中包括日志等级、对应的logger name、打印日志源文件的位置信息(包括文件名和行号)、线程ID、时间戳信息、具体的日志信息等内容。
日志消息类我们封装到LogMessage.hpp中:
#pragma once
#include"LogLevel.hpp"
#include8.4 日志输出格式化类设计
日志格式化(Formatter)类主要负责格式化⽇志消息。
我们思考下它的成员应该有什么,首先我们肯定要有一个string类型的字符串来保存总的日志输出化表示(_pattern),如 [%d{%H:%M:%S}][%t][%p][%c][%f:%l]%T%m%n ;然后我们需要将_pattern中的特定项解析出来保存,所以我们不妨用一个vector来存放。
_pattern其主要包含以下内容:
- %d{%H:%M:%S}:表⽰⽇期时间,花括号中的内容表示日期时间的格式;
- %T:表⽰制表符缩进;
- %t:表⽰线程ID;
- %p:表⽰⽇志级别;
- %c:表⽰⽇志器名称,不同的开发组可以创建⾃⼰的⽇志器进⾏⽇志输出,⼩组之间互不影响;
- %f:表⽰⽇志输出时的源代码⽂件名;
- %l:表⽰⽇志输出时的源代码⾏号;
- %m:表⽰给与的⽇志有效载荷数据;
- %n:表⽰换行。
我们不妨使用继承的思想,使用一个基类FormatItem,然后派生出不同格式化子项的输出形式;之前vector存放的数据类型我们可以使用基类的智能指针,这样当我们返回各种类型的子项智能指针类型的数据时,使用基类来访问成员函数时都能够得到正确调用(多态的原理)。所以基本框架我们就搭建好了,然后我们在Format.hpp中先来实现基本接口:
#pragma once
#include"LogMessage.hpp"
#include前面类中的实现很好理解,我就不在多解释了,这里重点讲解Formatter类中的成员函数:
-
1️⃣prase_pattern函数:这个函数的功能是将
_pattern中的一个一个格式化子项解析到_items中,我们画张图来理解理解:
 图中红色表示
图中红色表示_items中的每一个数据,绿色表示k和v,其中""表示k或者v中有一个为空,这样对应着对照表我们就可以将不同的格式化子项解析出来,具体解析方法我们在后面再来给出。 -
2️⃣format函数:这个函数的目的是将我们解析出来的具体内容提取到流里面(可能是标准输出,也可能是文件流等)我们实现了两个版本,返回
string类型是方便测试的版本,将解析出来的具体内容放进stringstream流中,返回对应的字符串方便验证;另外一个则我们可以根据传入的具体流来测试,具体的流可以参考下面流继承体系:

-
3️⃣create_item函数:将解析出来的k对应着相应的子类智能指针返回即可。
接下来便来实现prase_pattern函数:
//abcdf%%[ %d { %H:%M:%S } ][ %t ][ %p ][ %c ][ %f : %l ]%T %m %n
//将_pattern中的内容解析到_items中
private:
bool prase_pattern()
{
int cur=0,n=_pattern.size();
std::vector<std::pair<std::string,std::string>> vs;
std::string key,val;
while(cur<n)
{
if(_pattern[cur]!='%')//这里最好用if来判断
{
val+=_pattern[cur++];
continue;
}
//判断%是否是转义字符
if(cur+1<n && _pattern[cur+1]=='%')
{
val+='%';
cur+=2;
continue;
}
//走到这里表示Other已经解析完毕
if (!val.empty())
{
vs.push_back({"", val});
val.clear(); // 记得清空
}
//再解析%后面位置的信息
cur++;
if(cur<n)
{
key=_pattern[cur];
}
else
{
std::cout<<"%解析失败(后面没有字符)"<<std::endl;
return false;
}
//走到这里表示%已经解析成功
//开始解析是否有子格式(val)如: %H:%M:%S 注意这里并不需要将{}添加进去
cur++;
bool err=false;
if(cur<n && _pattern[cur]=='{')
{
cur++;
err=true;
while(cur<n && _pattern[cur]!='}')
{
val+=_pattern[cur++];
}
if(cur<n)
err=false;
cur++;
}
if(err)
{
std::cout<<"没有对应的}"<<std::endl;
return false;
}
vs.push_back({key,val});
key.clear();
val.clear();
}
for(auto& e:vs)
{
_items.push_back(create_item(e.first,e.second));
}
return true;
}
具体每一步我都写了详细的注释,相信大家能够看懂。
我们接下来写一个简单的测试程序来测测是否有错误:
int main()
{
grmlog::LogMsg msg(grmlog::LogLevel::values::Debug,"root","main.c",18,"这是一个测试");
grmlog::Formatter fmt("abcd%%[%d{%H:%M:%S}][%t][%p][%c][%f:%l]%T%m%n");
std::string str=fmt.format(msg);
std::cout<<str<<std::endl;
return 0;
}
运行结果:
 很显然跟我们预期是相符合的。
很显然跟我们预期是相符合的。
8.5 日志落地类设计
⽇志落地类主要负责落地⽇志消息到⽬的地。
它主要包括以下内容:
标准输出:表⽰将⽇志进⾏标准输出的打印;
日志文件输出:表⽰将⽇志写⼊指定的⽂件末尾;
滚动文件输出:当前以⽂件⼤⼩进⾏控制,当⼀个⽇志⽂件⼤⼩达到指定⼤⼩,则切换下⼀个⽂件进⾏输出后期,也可以扩展远程⽇志输出,创建客户端,将⽇志消息发送给远程的⽇志分析服务器。
这个类⽀持可扩展,其成员函数log设置为纯虚函数,当我们需要增加⼀个log输出⽬标, 可以增加一个类继承⾃该类并重写log⽅法实现具体的落地⽇志逻辑。
滚动⽇志⽂件输出的必要性:
- 由于机器磁盘空间有限, 我们不可能⼀直⽆限地向⼀个⽂件中增加数据;
- 如果⼀个⽇志⽂件体积太⼤,⼀⽅⾯是不好打开,另⼀⽅⾯是即时打开了由于包含数据巨⼤,也不利于查找我们需要的信息,所以实际开发中会对单个⽇志⽂件的⼤⼩也会做⼀些控制,即当⼤⼩超过某个⼤⼩时(如1GB),我们就重新创建⼀个新的⽇志⽂件来滚动写⽇志。 对于那些过期的⽇志, ⼤部分企业内部都有专⻔的运维⼈员去定时清理过期的⽇志,或者设置系统定时任务,定时清理过期⽇志。
⽇志⽂件的滚动思想:⽇志⽂件滚动的条件有两个:文件大小和时间
本项⽬基于文件大小的判断滚动⽣成新的⽂件,扩展可以使用文件时间。
日志落地类我们放在LogSeek.hpp中:
#pragma once
#include"Format.hpp"
#include代码中注意点:
- 1️⃣为什么在滚动文件的类成员设计中要加上一个
_name_cnt?
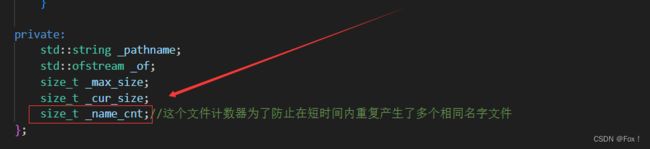 这是因为短时间内我们可能产生大量的文件,如果文件名字一样那么就会产生累加。
这是因为短时间内我们可能产生大量的文件,如果文件名字一样那么就会产生累加。 - 2️⃣ 我们使用简单工厂模式来方便不同落地方式的组织,同时为了便于用户增加新的落地方式不用再修改源码,我们使用了模板参数以及可变参数列表。

我们可以设计测试程序来进行测试
int main()
{
grmlog::LogMsg msg(grmlog::LogLevel::values::Debug, "root", "main.c", 18, "这是一个测试");
grmlog::Formatter fmt("abcd%%[%d{%H:%M:%S}][%t][%p][%c][%f:%l]%T%m%n");
std::string str = fmt.format(msg);
std::cout << str << std::endl;
// 日志落地
grmlog::Sink::ptr test_stdout = grmlog::SinkFactory::create<grmlog::StdoutSink>();
//grmlog::Sink::ptr normal_file=grmlog::SinkFactory::create("./log.txt/test.log");
//grmlog::Sink::ptr roll_file = grmlog::SinkFactory::create("./log.txt/test-");
// normal_file->log(str.c_str(),str.size());
int sz = 0;
int cnt = 0;
while (sz < 1024 * 1024 * 10)
{
std::string tmp = str + "-" + std::to_string(cnt++);
test_stdout->log(tmp.c_str(), tmp.size());
sz += tmp.size();
}
return 0;
}
- 先测试标准输出:

- 再测试普通文件:
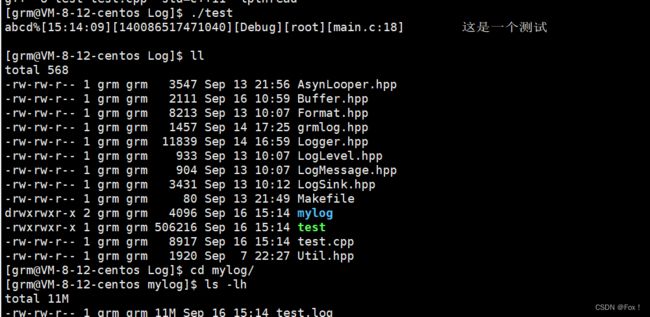 我们看看文件中内容:
我们看看文件中内容:

- 再测试滚动文件:
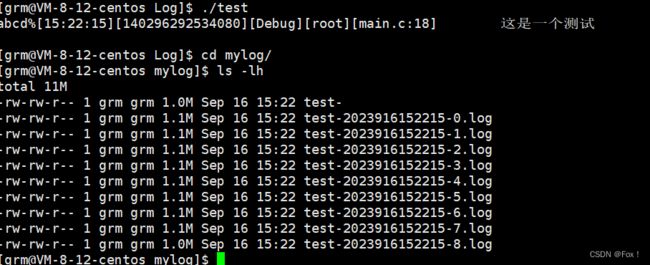 最后一个文件内容:
最后一个文件内容:

8.6 日志器类设计
日志器主要是⽤来和前端交互, 当我们需要使⽤⽇志系统打印log的时候, 只需要创建Logger对象,调⽤该对象debug、infor、warn、error、fatal等⽅法输出⾃⼰想打印的⽇志即可,⽀持解析可变参数列表和输出格式, 即可以做到像使⽤printf函数⼀样打印⽇志。当前⽇志系统⽀持同步日志 & 异步日志两种模式,两个不同的⽇志器唯⼀不同的地⽅在于他们在日志的落地⽅式上有所不同:
- 同步⽇志器:直接对⽇志消息进⾏输出;
- 异步⽇志器:将日志消息放⼊缓冲区,由异步线程进行输出。
因此⽇志器类在设计的时候先设计出⼀个Logger基类,在Logger基类的基础上,继承出SyncLogger同步⽇志器和AsyncLogger异步⽇志器。且因为⽇志器模块是对前边多个模块的整合,想要创建⼀个⽇志器,需要设置日志器名称,设置日志输出等级,设置日志器类型,设置日志输出格式,设置落地方向,且落地⽅向有可能存在多个,同时为了保证落地时不会发生输出冲突还得需要一把互斥锁来保证线程安全。
整个⽇志器的创建过程较为复杂,为了保持良好的代码⻛格,编写出优雅的代码,因此⽇志器的创建这⾥采⽤了建造者模式来进⾏创建。
日志器类我们放在Logger.hpp中:
#pragma once
#include "Format.hpp"
#include "LogLevel.hpp"
#include "LogMessage.hpp"
#include "LogSink.hpp"
#include"AsynLooper.hpp"
#include 测试程序:
int main()
{
//同步日志器的测试
const std::string name="sync_logger";
grmlog::LogLevel::values limit_level=grmlog::LogLevel::values::Warnning;
grmlog::Formatter::ptr fmatter(new grmlog::Formatter);
grmlog::Sink::ptr test_stdout=grmlog::SinkFactory::create<grmlog::StdoutSink>();
grmlog::Sink::ptr normal_file=grmlog::SinkFactory::create<grmlog::FileSink>("./mylog/test.log");
grmlog::Sink::ptr roll_file=grmlog::SinkFactory::create<grmlog::RollFileSink>("./mylog/roll-");
std::vector<grmlog::Sink::ptr> sinks={test_stdout,normal_file,roll_file};
grmlog::SyncLogger::ptr sync_logger(new grmlog::SyncLogger(name,limit_level,fmatter,sinks));
sync_logger->debug(__FILE__,__LINE__,"%s,","这是一条debug测试");
sync_logger->infor(__FILE__,__LINE__,"%s,","这是一条infor测试");
sync_logger->warnning(__FILE__,__LINE__,"%s,","这是一条warnning测试");
sync_logger->error(__FILE__,__LINE__,"%s,","这是一条error测试");
sync_logger->fatal(__FILE__,__LINE__,"%s,","这是一条fatal测试");
int sz = 0;
int cnt = 0;
std::string str="测试";
while (sz < 1024 * 1024 * 2)
{
std::string tmp = str + "-" + std::to_string(cnt++);
sync_logger->fatal(__FILE__,__LINE__,"测试日志%d,",cnt++);
sz += tmp.size();
}
return 0;
}
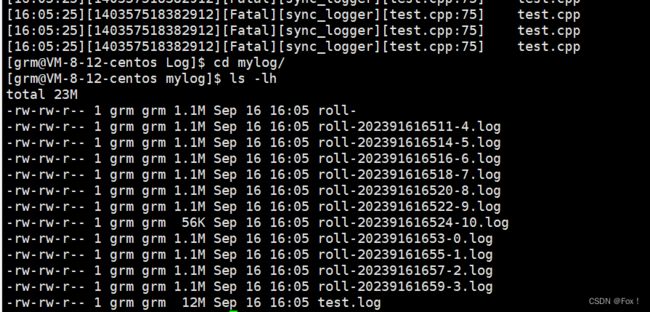 当我们打开
当我们打开test.log和roll-:


由于我们设置限制日志等级为warnning,所以debug和infor都没有输出。
大家应该也从测试用例中看出,这个设计其实对用户是不友好的,用户得去看源码才能够知道应该如何操作,所以此时我们可以使用建造者模式来进行创建;由于个部件的构建并没有强制的顺序要求,所以可以不使用指挥者。
enum LoggerType
{
SynLog=0,
AsynLog
};
//使用建造者模式来构建日志器对象,而不是直接构造日志器对象,简化用户的使用复杂度
//这里不使用指挥者的原因是因为对象构建的顺序并没有强制性的要求
class Bulid
{
public:
Bulid()
:_logger_type(LoggerType::SynLog)
,_limit_level(LogLevel::values::Debug)
{}
void bulid_logtype(LoggerType logtype)
{
_logger_type=logtype;
}
void bulid_logname(const std::string& logname)
{
_logger_name=logname;
}
void bulid_level(LogLevel::values level)
{
_limit_level=level;
}
void bulid_format(const std::string& pattern)
{
_format=std::make_shared<Formatter>(pattern);
}
template<typename SinkType,typename ...Args>
void bulid_sinks(Args && ...args)
{
Sink::ptr psink=SinkFactory::create<SinkType>(std::forward<Args>(args)...);
_sinks.push_back(psink);
}
virtual Logger::ptr bulid()=0;
protected:
LoggerType _logger_type;
std::string _logger_name;
LogLevel::values _limit_level;
Formatter::ptr _format;
std::vector<Sink::ptr> _sinks;
AsynBufState _asyn_state;
};
class LocalLoggerBuild : public Bulid
{
public:
virtual Logger::ptr bulid() override
{
assert(!_logger_name.empty());//日志器名称必须有
if(_format.get() == nullptr)
_format=std::make_shared<Formatter>();
if(_sinks.empty())
bulid_sinks<StdoutSink>();
if(_logger_type == LoggerType::AsynLog)
return std::make_shared<ASyncLogger>(_logger_name,_limit_level,_format,_sinks,_asyn_state);
else
return std::make_shared<SyncLogger>(_logger_name,_limit_level,_format,_sinks);
}
};
上面我们使用了LocalLoggerBuild创建的日志器是局部的,也就是当前创建的日志器只能在当前函数栈帧中使用,其他地方要使用就必须传参,这样其实是有点麻烦的,所以后面我们又会实现一种全局方式来创建日志器。
现在我们使用建造者模式来完成复杂对象的构建:
int main()
{
//使用建造者模式来一步一步将复杂过程具体化和简单化
std::shared_ptr<grmlog::Bulid> build(new grmlog::LocalLoggerBuild);
build->bulid_level(grmlog::LogLevel::values::Warnning);
build->bulid_format("%m%n");
build->bulid_logname("sync_logger");
build->bulid_sinks<grmlog::StdoutSink>();
build->bulid_sinks<grmlog::FileSink>("./mylog/test.log");
build->bulid_sinks<grmlog::RollFileSink>("./mylog/roll-");
grmlog::Logger::ptr sync_logger=build->bulid();
sync_logger->debug(__FILE__,__LINE__,"%s,","这是一条debug测试");
sync_logger->infor(__FILE__,__LINE__,"%s,","这是一条infor测试");
sync_logger->warnning(__FILE__,__LINE__,"%s,","这是一条warnning测试");
sync_logger->error(__FILE__,__LINE__,"%s,","这是一条error测试");
sync_logger->fatal(__FILE__,__LINE__,"%s,","这是一条fatal测试");
int sz = 0;
int cnt = 0;
std::string str="测试";
while (sz < 1024 * 1024 * 2)
{
std::string tmp = str + "-" + std::to_string(cnt++);
sync_logger->fatal(__FILE__,__LINE__,"测试日志%d,",cnt++);
sz += tmp.size();
}
return 0;
}

注意:为啥现在文件只有两个了呢?我们使用的格式化字符串只用了%m%n,输出的内容是很少的。

8.7 双缓冲区异步任务处理器设计
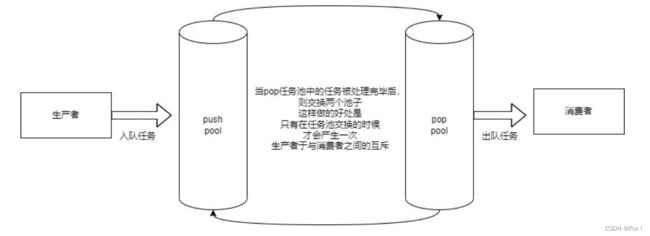
设计思想:异步处理线程 + 数据池
使⽤者将需要完成的任务添加到任务池中,由异步线程来完成任务的实际执⾏操作。
任务池的设计思想:双缓冲区阻塞数据池
优势:避免了空间的频繁申请释放,且尽可能的减少了⽣产者与消费者之间锁冲突的概率,提⾼了任务处理效率。
在任务池的设计中,有很多备选⽅案,比如循环队列等等,但是不管是哪⼀种都会涉及到锁冲突的情况,因为在⽣产者与消费者模型中,任何两个⻆⾊之间都具有互斥关系,因此每⼀次的任务添加与取出都有可能涉及锁的冲突,⽽双缓冲区不同,双缓冲区是处理器将⼀个缓冲区中的任务全部处理完毕后,然后交换两个缓冲区,重新对新的缓冲区中的任务进⾏处理,虽然同时多线程写⼊也会冲突,但是冲突并不会像单缓冲区那样频繁(减少了生产者与消费者之间的锁冲突),且不涉及到空间的频繁申请释放所带来的消耗。
 先来实现一份单缓冲区类在
先来实现一份单缓冲区类在Buffer.hpp中:
#pragma once
#include如何测试来验证单缓冲区的正确性呢?思路是这样的:我们先将test.log文件中的数据读到单缓冲区中,然后再将缓冲区的数据写到另外一个新文件tmp.log中,最后使用md5sum来计算test.log和tmp.log的哈希值是否相等。
具体代码如下:
int main()
{
//1 将文件中的数据读到s中
std::ifstream ifs("./mylog/test.log",std::ios::binary);
if(ifs.is_open() == false)
{
std::cout<<"open file fail"<<std::endl;
return -1;
}
ifs.seekg(0,std::ios::end);//将指针置于末尾
size_t sz=ifs.tellg();//获取当前位置与起始位置的偏移量
ifs.seekg(0,std::ios::beg);//将指针置于开始
std::string s;
s.resize(sz);
ifs.read(&s[0],sz);
if(ifs.good() == false)
{
std::cout<<"read fail"<<std::endl;
}
ifs.close();
//2 将s放到缓冲区
grmlog::Buffer buff;
for(int i=0; i<s.size(); ++i)
buff.push(&s[i],1);
//3 将缓冲区的内容写到新文件tmp.log中
std::ofstream ofs("./mylog/tmp.log",std::ios::binary);
if(ofs.is_open() == false)
{
std::cout<<"open file fail"<<std::endl;
return -1;
}
//千万不能用下面这种方式,buff.read_use_maxsize()是会发生改变的
// for(int i=0; i
// {
// ofs.write(buff.begin(),1);
// buff.read_move(1);
// }
size_t len=buff.read_use_maxsize();
for(int i=0; i<len; ++i)
{
ofs.write(buff.begin(), 1);
if (ofs.good() == false)
{
std::cout << "write fail" << std::endl;
}
buff.read_move(1);
}
//可以使用md5sum来计算映射
return 0;
}
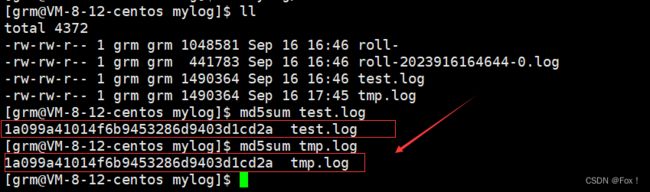
我们可以明显看出两个文件中内容应该是一致的。
接下来我们再来设计双缓冲区的异步缓冲池在AsynLopper.hpp中:
#pragma once
#include"Buffer.hpp"
#include其中的注意点有:
- 1️⃣
AsynBufState类中的Safe和Unsafe是什么意思?
这个是我们设计的两种模式:安全模式与非安全模式,其中安全模式便是不能够无限扩容,当达到规定的容量上限后就不扩容了,而是直接交换;非安全模式生产者缓冲区是不会等待的,直接push(可能会扩容),然后唤醒消费缓冲区进行交换,一般是用来进行极限压力测试的。 - 2️⃣ 异步双缓冲池中并没有直接实现将缓冲区的数据进行输出,而是使用了包装器来接受上层传入的回调;且工作线程设计一个就足够了,让工作线程周而复始的进行数据输出。
- 3️⃣大家看看下面的代码:
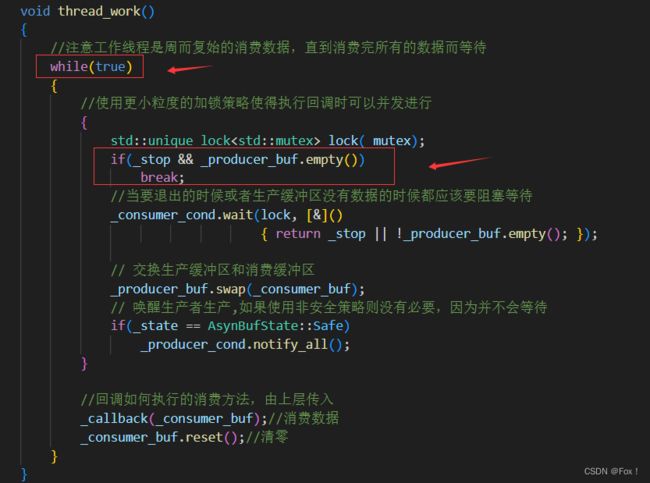 其中
其中while的条件可以改成!quit,不要下面的break语句吗?
这个是一个容易让人忽略的点,这样做是不可以的,为什么呢?
假如我们按照上面那种方式修改了后,当我们析构时会调用stop函数退出,这时_stop被置为true,此时while循环并没有进去,但是大家别忘了,生产缓冲区中可能还是有数据的,还没有被交换,那么这个数据不就丢失了吗,所以我们可以使用上面的方式来处理。
其他注意点代码中都有着详细的注释。
8.8 异步日志器设计
异步日志器类继承⾃⽇志器类, 并在同步⽇志器类上拓展了异步消息处理器。当我们需要异步输出⽇志的时候, 需要创建异步⽇志器和消息处理器, 调⽤异步⽇志器的log、error、infor、fatal等函数输出不同级别日志。
log_it函数为重写Logger类的函数, 主要实现将日志数据加入异步双缓冲区中;real_log函数主要由异步线程进⾏调⽤(是为异步消息处理器设置的回调函数),完成⽇志的实际落地⼯作。
代码实现:
class ASyncLogger: public Logger
{
public:
using ptr = std::shared_ptr<ASyncLogger>;
ASyncLogger(const std::string &logger_name,
LogLevel::values limit_level,
Formatter::ptr format,
std::vector<Sink::ptr> &sinks,
AsynBufState state)
: Logger(logger_name, limit_level, format, sinks)
,_looper(std::make_shared<AsynBuf>(state,std::bind(&ASyncLogger::real_log,this,std::placeholders::_1)))
{}
void real_log(Buffer & buff)
{
//由于异步日志器实际落地只有一个线程,所以在消费时只有一个线程在消费是串行化执行的
if(_sinks.empty())
return;
for(auto& sink:_sinks)
{
sink->log(buff.begin(),buff.read_use_maxsize());
}
}
virtual void log_it(const char* data,size_t len)override
{
_looper->push(data,len);
}
AsynBuf::ptr _looper;
};
enum LoggerType
{
SynLog=0,
AsynLog
};
8.9 单例日志器管理类设计
日志的输出,我们希望能够在任意位置都可以进⾏,但是当我们创建了⼀个⽇志器之后,就会受到⽇志器所在作⽤域的访问属性限制。因此,为了突破访问区域的限制,我们创建⼀个⽇志器管理类,且这个类是⼀个单例类,这样的话,我们就可以在任意位置来通过管理器单例获取到指定的⽇志器来进⾏⽇志输出了。
基于单例⽇志器管理器的设计思想,我们对于⽇志器建造者类进⾏继承,继承出⼀个全局⽇志器建造者类,实现⼀个⽇志器在创建完毕后,直接将其添加到单例的⽇志器管理器中,以便于能够在任何位置通过⽇志器名称能够获取到指定的⽇志器进⾏⽇志输出。
class LoggerManager
{
public:
static LoggerManager& GetInstance()
{
static LoggerManager local_log;
return local_log;
}
bool exist(const std::string& loggername)
{
std::unique_lock<std::mutex> lock(_mutex);
auto it=_loggers.find(loggername);
if(it == _loggers.end())
return false;
return true;
}
void add_logger(const std::string& loggername, Logger::ptr logger)
{
std::unique_lock<std::mutex> lock(_mutex);
auto it=_loggers.find(loggername);
if(it == _loggers.end())
_loggers.insert({loggername,logger});
}
Logger::ptr get_logger(const std::string& loggername)
{
std::unique_lock<std::mutex> lock(_mutex);
auto it=_loggers.find(loggername);
if(it == _loggers.end())
return Logger::ptr();
return it->second;
}
Logger::ptr get_rootlogger()
{
std::unique_lock<std::mutex> lock(_mutex);
return _root_logger;
}
private:
LoggerManager()
{
std::shared_ptr<grmlog::Bulid> build(new grmlog::LocalLoggerBuild);
build->bulid_logname("root");
build->bulid_logtype(LoggerType::SynLog);
_root_logger=build->bulid();
_loggers.insert({"root",_root_logger});
}
LoggerManager(const LoggerManager& logger)=delete;
LoggerManager& operator=(const LoggerManager& logger)=delete;
std:: mutex _mutex;
Logger::ptr _root_logger;//默认的日志器
std::unordered_map<std::string,Logger::ptr> _loggers;
};
class PublicLoggerBuild : public Bulid
{
public:
virtual Logger::ptr bulid() override
{
assert(!_logger_name.empty());//日志器名称必须有
if(_format.get() == nullptr)
_format=std::make_shared<Formatter>();
if(_sinks.empty())
bulid_sinks<StdoutSink>();
Logger::ptr logger;
if(_logger_type == LoggerType::AsynLog)
logger=std::make_shared<ASyncLogger>(_logger_name,_limit_level,_format,_sinks,_asyn_state);
else
logger=std::make_shared<SyncLogger>(_logger_name,_limit_level,_format,_sinks);
LoggerManager::GetInstance().add_logger(_logger_name,logger);
return logger;
}
};
在Bulid中我们还得添加一个是否安全的选项:
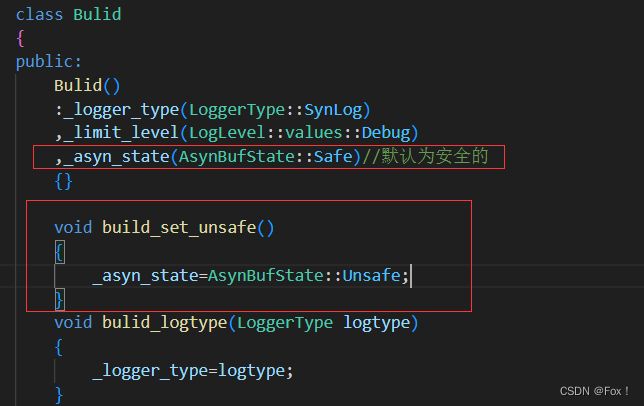
这样我们就可以使用全局日志器来访问了,写一个测试用例来测试正误:
void public_test()
{
grmlog::Logger::ptr async_logger=grmlog::LoggerManager::GetInstance().get_logger("async_logger");
assert(async_logger.get());
async_logger->debug(__FILE__,__LINE__,"%s,","这是一条debug测试");
async_logger->infor(__FILE__,__LINE__,"%s,","这是一条infor测试");
async_logger->warnning(__FILE__,__LINE__,"%s,","这是一条warnning测试");
async_logger->error(__FILE__,__LINE__,"%s,","这是一条error测试");
async_logger->fatal(__FILE__,__LINE__,"%s,","这是一条fatal测试");
int cnt = 0;
std::string str="测试";
while (cnt < 500000)
{
async_logger->fatal(__FILE__,__LINE__,"测试日志%d,",cnt++);
}
}
int main()
{
//异步日志器的测试
//使用建造者模式来一步一步将复杂过程具体化和简单化
std::cout<<__FILE__<<std::endl;
std::shared_ptr<grmlog::Bulid> pubuild(new grmlog::PublicLoggerBuild);
pubuild->bulid_logtype(grmlog::LoggerType::AsynLog);//设置为异步工作器
pubuild->bulid_level(grmlog::LogLevel::values::Warnning);
pubuild->bulid_format("[%f:%l]%m%n");
pubuild->bulid_logname("async_logger");
pubuild->bulid_sinks<grmlog::StdoutSink>();
pubuild->bulid_sinks<grmlog::FileSink>("./mylog/async.log");
pubuild->build_set_unsafe();
pubuild->bulid();
public_test();
return 0;
}
我们打开async.log最后几行内容:
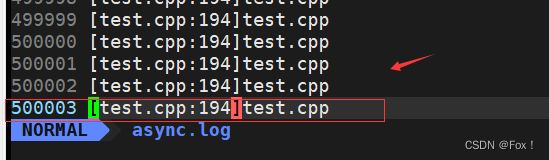
一共有500003行内容,是符合我们预期的。

8.10 日志宏&全局接口设计
提供全局的⽇志器获取接⼝。
使⽤代理模式通过全局函数或宏函数来代理Logger类的debug、infor、error、fatal等接⼝,以便于控制源码⽂件名称和⾏号的输出控制,简化用户操作。
当仅需标准输出⽇志的时候可以通过主⽇志器来打印⽇志。 且操作时只需要通过宏函数直接进⾏输出即可。
我们将这些内容都设计到grmlog.hpp中:
#pragma once
#include"Logger.hpp"
namespace grmlog
{
Logger::ptr get_logger(const std::string& name)
{
return LoggerManager::GetInstance().get_logger(name);
}
Logger::ptr get_root_logger(const std::string& name)
{
return LoggerManager::GetInstance().get_rootlogger();
}
#define debug(fmt, ...) debug(__FILE__, __LINE__, fmt, ##__VA_ARGS__)
#define infor(fmt, ...) infor(__FILE__, __LINE__, fmt, ##__VA_ARGS__)
#define warnning(fmt, ...) warnning(__FILE__, __LINE__, fmt, ##__VA_ARGS__)
#define error(fmt, ...) error(__FILE__, __LINE__, fmt, ##__VA_ARGS__)
#define fatal(fmt, ...) fatal(__FILE__, __LINE__, fmt, ##__VA_ARGS__)
#define LOG_DEBUG(logger, fmt, ...) (logger)->debug(fmt, ##__VA_ARGS__)
#define LOG_INFO(logger, fmt, ...) (logger)->infor(fmt, ##__VA_ARGS__)
#define LOG_WARN(logger, fmt, ...) (logger)->warnning(fmt, ##__VA_ARGS__)
#define LOG_ERROR(logger, fmt, ...) (logger)->error(fmt, ##__VA_ARGS__)
#define LOG_FATAL(logger, fmt, ...) (logger)->fatal(fmt, ##__VA_ARGS__)
#define Log_Debug(fmt, ...) LOG_DEBUG(grmlog::get_root_logger(), fmt, ##__VA_ARGS__)
#define Log_Infor(fmt, ...) LOG_INFO(grmlog::get_root_logger(), fmt, ##__VA_ARGS__)
#define Log_Warnning(fmt, ...) LOG_WARN(grmlog::get_root_logger(), fmt, ##__VA_ARGS__)
#define Log_Error(fmt, ...) LOG_ERROR(grmlog::get_root_logger(), fmt, ##__VA_ARGS__)
#define Log_Fatal(fmt, ...) LOG_FATAL(grmlog::get_root_logger(), fmt, ##__VA_ARGS__)
}
当我们使用该日志项目时其实只需要包含grmlog.hpp头文件即可。
我们写个测试程序来验证:
void public_test()
{
grmlog::Logger::ptr async_logger=grmlog::LoggerManager::GetInstance().get_logger("async_logger");
assert(async_logger.get());
async_logger->debug("%s,","这是一条debug测试");
async_logger->infor("%s,","这是一条infor测试");
async_logger->warnning("%s,","这是一条warnning测试");
async_logger->error("%s,","这是一条error测试");
async_logger->fatal("%s,","这是一条fatal测试");
int cnt = 0;
std::string str="测试";
while (cnt < 100000)
{
async_logger->fatal("测试日志%d,",cnt++);
}
}
int main()
{
//异步日志器的测试
//使用建造者模式来一步一步将复杂过程具体化和简单化
std::cout<<__FILE__<<std::endl;
std::shared_ptr<grmlog::Bulid> pubuild(new grmlog::PublicLoggerBuild);
pubuild->bulid_logtype(grmlog::LoggerType::AsynLog);//设置为异步工作器
pubuild->bulid_level(grmlog::LogLevel::values::Warnning);
pubuild->bulid_format("[%f:%l]%m%n");
pubuild->bulid_logname("async_logger");
pubuild->bulid_sinks<grmlog::StdoutSink>();
pubuild->bulid_sinks<grmlog::FileSink>("./mylog/async.log");
pubuild->build_set_unsafe();
pubuild->bulid();
public_test();
return 0;
}
打开async.log :


9 性能测试
一般来说性能测试我们要从3个方面来准备:
- 测试环境
- 测试方法
- 测试结果与结论
9.1 测试环境
- CPU: Intel® Xeon® Platinum 8255C CPU @ 2.50GHz
- 内存:最大容量2GB,Handle 0x1000, DMI type 16, 23 bytes
- OS:CentOS 7.6(2核,内存2GB,SSD云硬盘40GB)
我们可以使用lscpu来查看cpu的配置:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
Stepping: 5
CPU MHz: 2494.140
BogoMIPS: 4988.28
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 36608K
NUMA node0 CPU(s): 0,1
9.2 测试方法
我们可以通过手动创建输入线程的数量,日志器名称,总的消息条数,每条消息的长度。
使用多线程来进行输入时记录开始时间和结束时间,然后计算出每个线程的耗时以及每个线程平均每秒输出的消息个数,然后计算总共耗时以及总共平均每秒输出消息个数。
具体代码:
#include"../Log/grmlog.hpp"
#include9.3 测试结果与结论
9.3.1 单线程同步日志
[grm@VM-8-12-centos Property]$ ./test
输出的总日志大小: 95Mb
输出的总日志条数: 1000000条
输入的总线程数量: 1个
线程0耗时: 2.04552s 平均1s输出消息个数: 488874个
总共耗时:2.04552s
平均每秒输出消息个数488874
9.3.2 多线程同步日志
[grm@VM-8-12-centos Property]$ ./test
输出的总日志大小: 95Mb
输出的总日志条数: 1000000条
输入的总线程数量: 5个
线程4耗时: 2.1405s 平均1s输出消息个数: 95083个
线程2耗时: 2.1878s 平均1s输出消息个数: 91873个
线程3耗时: 2.19586s 平均1s输出消息个数: 90885个
线程1耗时: 2.11844s 平均1s输出消息个数: 97625个
线程0耗时: 2.14576s 平均1s输出消息个数: 92586个
总共耗时:2.11844s
平均每秒输出消息个数468870
9.3.3 单线程异步日志
[grm@VM-8-12-centos Property]$ ./test
输出的总日志大小: 95Mb
输出的总日志条数: 1000000条
输入的总线程数量: 1个
线程0耗时: 2.34552s 平均1s输出消息个数: 434782个
总共耗时:2.34552s
平均每秒输出消息个数434782
9.3.4 多线程异步日志
[grm@VM-8-12-centos Property]$ ./test
输出的总日志大小: 95Mb
输出的总日志条数: 1000000条
输入的总线程数量: 5个
线程1耗时: 1.82806s 平均1s输出消息个数: 109405个
线程4耗时: 1.85411s 平均1s输出消息个数: 107868个
线程0耗时: 1.86217s 平均1s输出消息个数: 107401个
线程3耗时: 1.89818s 平均1s输出消息个数: 105364个
线程2耗时: 1.89986s 平均1s输出消息个数: 105270个
总共耗时:1.89986s
平均每秒输出消息个数526354
9.3.5 结论
注意不同测试环境的CPU,内存,磁盘的性能是不一样的,要根据具体的环境具体分析。
在我的测试环境下:
-
在单线程情况下,异步效率看起来还没有同步高,这个是因为现在的IO操作在用户态都会有缓冲区进⾏缓冲,因此我们当前测试⽤例看起来的同步其实大多时候也是在操作内存,只有在缓冲区满了才会涉及到阻塞写磁盘操作,⽽异步单线程效率看起来低;也有⼀个很重要的原因就是单线程同步操作中不存在锁冲突,⽽单线程异步⽇志操作存在⼤量的锁冲突,因此性能也会有⼀定的降低。
-
但是,我们也要看到限制同步⽇志效率的最⼤原因是磁盘的性能,打⽇志的线程多少并⽆明显区别,线程多了反⽽会降低,因为增加了磁盘的读写争抢;⽽对于异步⽇志的限制,并⾮磁盘的性能,⽽是cpu的处理性能,打⽇志并不会因为落地⽽阻塞,因此在多线程打⽇志的情况下性能有了显著的提⾼。
当然如果你的测试环境中磁盘的性能较差,单线程同步日志的性能就不会很好;如果测试的CPU的处理性能很高,那么多线程异步日志的效率就会非常高。
10 扩展
- 丰富sink类型:
- ⽀持按⼩时按天滚动⽂件;
- ⽀持将log通过⽹络传输落地到⽇志服务器(tcp/udp);
- ⽀持在控制台通过⽇志等级渲染不同颜⾊输出⽅便定位;
- ⽀持落地⽇志到数据库;
- ⽀持配置服务器地址,将⽇志落地到远程服务器.
- 实现⽇志服务器负责存储⽇志并提供检索、分析、展⽰等功能
【源码仓库】