java-String
java-String
1,存储
数据底层都是用0和1进行存储和传输,String底层是一个字符数组,“abc”——>[‘a’,‘b’,‘c’];每个字符根据编码表[字符集]进行存储。
- ASCII表——适合英文,字符较少
- unicode
- utf8——三个字节描述一个字符
- gbk——两个字节描述一个字符
2,常量池——了解
注意:这块知识不太可靠,要看汇编语言
1,字符串常量池由来
在日常开发过程中,字符串的创建是比较频繁的,而字符串的分配和其他对象的分配是类似的,需要耗费大量的时间和空间,从而影响程序的运行性能,所以作为最基础最常用的引用数据类型,Java设计者在JVM层面提供了字符串常量池。
2,实现前提
- 实现这种设计的一个很重要的因素是:String类型是不可变的,实例化后,不可变,就不会存在多个同样的字符串实例化后有数据冲突;
- 运行时,实例创建的全局字符串常量池中会有一张表,记录着长相持中每个唯一的字符串对象维护一个引用,当垃圾回收时,发现该字符串被引用时,就不会被回收。
3,实现原理
为了提高性能并减少内存的开销,JVM在实例化字符串常量时进行了一系列的优化操作:
在JVM层面为字符串提供字符串常量池,可以理解为是一个缓存区;
创建字符串常量时,JVM会检查字符串常量池中是否存在这个字符串;若字符串常量池中存在该字符串,则直接返回引用实例;若不存在,先实例化该字符串,并且,将该字符串放入字符串常量池中,以便于下次使用时,直接取用,达到缓存快速使用的效果。
String str1 = "abc";
String str2 = "abc";
System.out.println("str1 == str2: " + (str1 == str2)); //结果:str1 == str2: true
4,字符串常量池位置变化
方法区
提到字符串常量池,还得先从方法区说起。方法区和Java堆一样(但是方法区是非堆),是各个线程共享的内存区域,是用于存储已经被JVM加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
很多人会把方法区称为永久代,其实本质上是不等价的,只不过HotSpot虚拟机设计团队是选择把GC分代收集扩展到了方法区,使用永久代来代替实现方法区。其实,在方法区中的垃圾收集行为还是比较少的,这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载,但是这个区域的回收总是不尽如人意的,如果该区域回收不完全就会出现内存泄露。当然,对于JDK1.8时,HostSpot VM对JVM模型进行了改造,将元数据放到本地内存,将常量池和静态变量放到了Java堆里。
元空间
JDK 1.8, HotSpot JVM将永久代移除了,使用本地内存来存储类的元数据信息,即为元空间(Metaspace)
所以,字符串常量池的具体位置是在哪里?当然这个我们后面需要区分jdk的版本,jdk1.7之前,jdk1.7,以及jdk1.8,因为这些版本中,字符串常量池因为方法区的改变而做了一些变化。
JDK1.7之前
在jdk1.7之前,常量池是存放在方法区中的。

JDK1.7
在jdk1.7中,字符串常量池移到了堆中,运行时常量池还在方法区中。
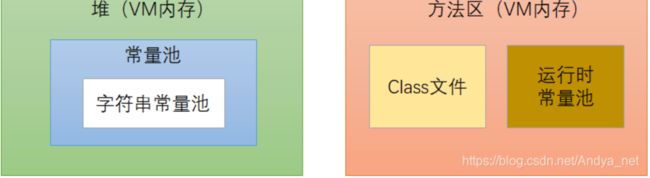
JDK1.8
jdk1.8删除了永久代,方法区这个概念还是保留的,但是方法区的实现变成了元空间,常量池沿用jdk1.7,还是放在了堆中。这样的效果就变成了:常量池和静态变量存储到了堆中,类的元数据及运行时常量池存储到元空间中。

为啥要把方法区从JVM内存(永久代)移到直接内存(元空间)?主要有两个原因:
- 直接内存属于本地系统的IO操作,具有更高的一个IO操作性能,而JVM的堆内存这种,如果有IO操作,也是先复制到直接内存,然后再去进行本地IO操作。经过了一系列的中间流程,性能就会差一些。非直接内存操作:本地IO操作——>直接内存操作——>非直接内存操作——>直接内存操作——>本地IO操作,而直接内存操作:本地IO操作——>直接内存操作——>本地IO操作。
- 永久代有一个无法调整更改的JVM固定大小上限,回收不完全时,会出现OutOfMemoryError问题;而直接内存(元空间)是受到本地机器内存的限制,不会有这种问题。
变化
在JDK1.7前,运行时常量池+字符串常量池是存放在方法区中,HotSpot VM对方法区的实现称为永久代。
在JDK1.7中,字符串常量池从方法区移到堆中,运行时常量池保留在方法区中。
在JDK1.8中,HotSpot移除永久代,使用元空间代替,此时字符串常量池保留在堆中,运行时常量池保留在方法区中,只是实现不一样了,JVM内存变成了直接内存。
5,字符串对象两种创建详解
String s1 = “abc”和 String s2 = new String(“abc”)
public class StringTest02 {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
System.out.println("s1==s2, " + (s1==s2));
System.out.println("s2==s3, " + (s2==s3));
System.out.println("s2 equlas s3," + (s2.equals(s3)));
}
}


如果是采用双引号引起来的字符串常量,首先会到常量池中去查找,如果存在就不再分配,如果不存在就分配,常量池中的数据是在编译期赋值的,也就是生成 class 文件时就把它放到常量池里了,所以 s1 和 s2 都指向常量池中的同一个字符串“abc”
关于 s3,s3 采用的是 new 的方式,在 new 的时候存在双引号,所以他会到常量区中查找“abc”,而常量区中存在“abc”,所以常量区中将不再放置字符串,而 new 关键子会在堆中分配内存,所以在堆中会创建一个对象 abc,s3 会指向 abc
如果比较 s2 和 s3 的值必须采用 equals,String 已经对 eqauls 方法进行了覆盖
注意:只要采用双引号赋值字符串,那么在编译期将会放到方法区中的字符串的常量池里,如果是运行时对字符串相加或相减会放到堆中(放之前会先验证方法区中是否含有相同的字符串常量,如果存在,把地址返回,如果不存在,先将字符串常量放到池中,然后再返回该对象的地址)
6,String 面试题分析
String s1 = new String("hello") ;
String s2 = new String("hello") ;
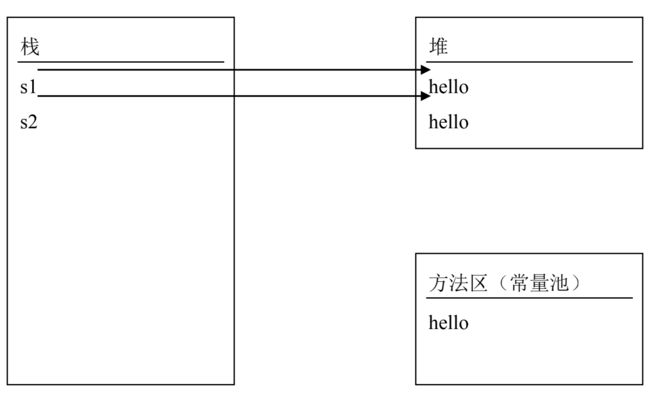
通过以上分析,大家会看到创建了 3 个对象,堆区中 2 个,常量池中 1 一个
通过以上分析,使用 String 时,不建议使用 new 关键字,因为使用 new 会创建两个对象
记住:堆区中是运行期分配的,常量池中是编译器分配的
3,String 常用方法简介
- endsWith:判断字符串是否以指定的后缀结束
- startsWith,判断字符串是否以指定的前缀开始
- equals,字符串相等比较,不忽略大小写
- equalsIgnoreCase,字符串相等比较,忽略大小写
- indexOf,取得指定字符在字符串的位置
- lastIndexOf,返回最后一次字符串出现的位置
- length,取得字符串的长度
- replaceAll,替换字符串中指定的内容
- split,根据指定的表达式拆分字符串
- substring,截子串
- trim,去前尾空格
- valueOf,将其他类型转换成字符串
4,使用 String 时的注意事项
因为 String 是不可变对象,如果多个字符串进行拼接,将会形成多个对象,这样可能会造成内存溢出,会给垃圾回收带来工作量,如下面的应用最好不要用 String
public class StringTest04 {
public static void main(String[] args) {
String s = "";
for (int i=0; i<100; i++) {
//以下语句会生成大量的对象
//因为 String 是不可变对象
//存在大量的对象相加或相减一般不建议使用 String
//建议使用 StringBuffer 或 StringBuilder
s+=i;// s = s+i; }
}
}
5,StringBuffer和 StringBuilder
StringBuffer
StringBuffer 称为字符串缓冲区,它的工作原理是:预先申请一块内存,存放字符序列,如果字符序列满了,会重新改变缓存区的大小,以容纳更多的字符序列。StringBuffer 是可变对象,这个是 String 最大的不同
public class StringBufferTest01 {
public static void main(String[] args) {
StringBuffer sbStr = new StringBuffer();
for (int i=0; i<100; i++) {
//sbStr.append(i);
//sbStr.append(",");
//方法链的编程风格
sbStr.append(i).append(",");
//拼串去除逗号
//sbStr.append(i);
//if (i != 99) {
// sbStr.append(",");
//}
}
//可以输出
System.out.println(sbStr);
System.out.println("");
System.out.println(sbStr.toString());
System.out.println("");
//去除逗号
System.out.println(sbStr.toString().substring(0,sbStr.toString().length()-1));
System.out.println("");
System.out.println(sbStr.substring(0, sbStr.length()-1));
}
}
StringBuilder
用法同 StringBuffer,StringBuilder 和 StringBuffer 的区别是 StringBuffer 中所有的方法都是同步的,是线程安全的,但速度慢,StringBuilder 的速度快,但不是线程安全的
B站关于string创建的视频详解