yum 快速安装zookeeper、Kafka集群部署
Kafka集群部署并启动
在本文中将从演示如何搭建一个Kafka集群开始,然后简要介绍一下关于Kafka集群的一些基础知识点。但本文仅针对集群做介绍,对于Kafka的基本概念不做过多说明,这里假设读者拥有一定的Kafka基础知识。
首先,我们需要了解Kafka集群的一些机制:
- Kafka是天然支持集群的,哪怕是一个节点实际上也是集群模式
- Kafka集群依赖于Zookeeper进行协调,并且在早期的Kafka版本中很多数据都是存放在Zookeeper的
- Kafka节点只要注册到同一个Zookeeper上就代表它们是同一个集群的
- Kafka通过brokerId来区分集群中的不同节点
Kafka的集群拓扑图如下:
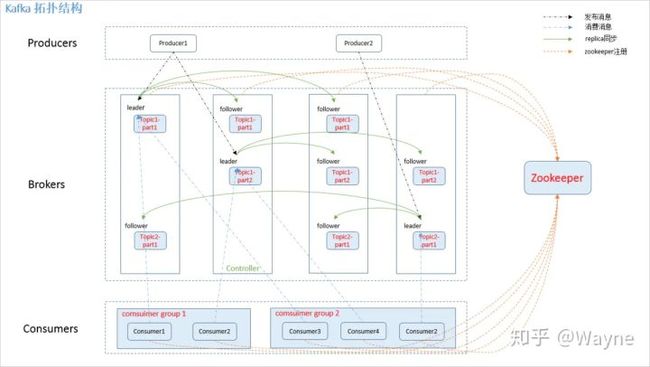
Kafka集群中的几个角色:
-
Broker:一般指Kafka的部署节点
-
Leader:用于处理消息的接收和消费等请求,也就是说producer是将消息push到leader,而consumer也是从leader上去poll消息
-
Follower:主要用于备份消息数据,一个leader会有多个follower
前期准备
-
三台主机都需要安装好jdk
-
三台主机都要配置好zookeeper
-
准备好kafka压缩包
在本例中,为了更贴近实际的部署情况,使用了3台虚拟机作演示:
| IP地址 | |
|---|---|
| 192.168.100.85 | kafka01 |
| 192.168.100.86 | kafka02 |
| 192.168.100.36 | kafka03 |
Zookeeper安装
Kafka是基于Zookeeper来实现分布式协调的,所以在搭建Kafka节点之前需要先搭建好Zookeeper节点。而Zookeeper和Kafka都依赖于JDK,我这里先安装好了JDK:
yum install java-1.8.0-openjdk* -y
[[email protected] ~]# java --version
java 11.0.5 2019-10-15 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.5+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.5+10-LTS, mixed mode)
[root@txy-server2 ~]#
准备好JDK环境后,然后到Linux中使用wget命令进行下载,如下:
#下载压缩包
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
#解压
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
#进入目录
cd apache-zookeeper-3.5.8-bin
#创建id
mkdir tmp
echo 1 > tmp/myid
#复制文件
cp conf/zoo_sample.cfg conf/zoo.cfg
#修改配置文件
vi zoo.cfg (进入文件进行编辑)
修改如下
#将dataDir后边的路径修改为自己tmp 的路径,此处为
dataDir=./tmp
#继续添加如下内容:
server.1=192.168.100.85:2888:3888
server.2=192.168.100.86:2888:3888
server.3=192.168.100.36:2888:3888
#这里的192.168.100.36,192.168.100.85,192.168.100.86换成自己对应的主机名
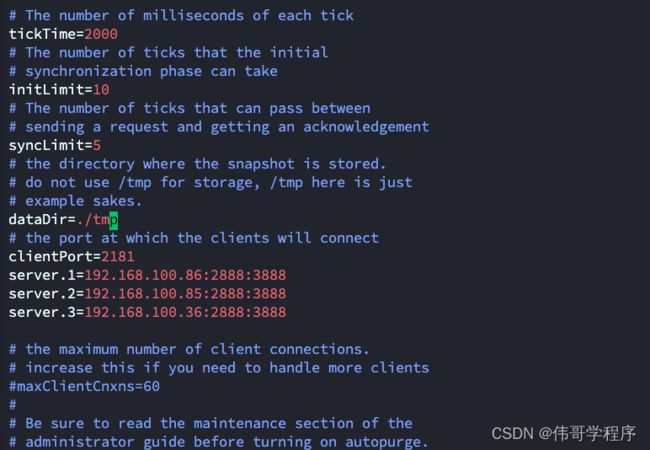
注:dataDir=./tmp是缓存数据路径
2888为组成zookeeper服务器之间的通信端口3888为用来选举leader的端口 三台虚拟机都需操作
同上操作另外2台服务器、进入tmp目录,将myid里边的1改为2, 在kafka03主机下,进入tmp目录,将myid里边的1改为3。
配置zookpeeper 环境变量(可选)
export ZOOKEEPER_HOME=/root/apache-zookeeper-3.5.8-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
#/root/apache-zookeeper-3.5.8-bin 要换为自己对应存放zookeeper-3.4.5路径
集群测试
bin/zkServer.sh stop 停止运行
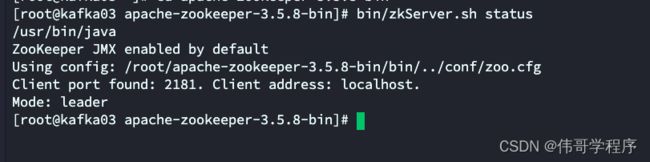
bin/zkServer.sh status 查询状态
bin/zkServer.sh start 启动
- 启动zookeeper集群,在zookeeper-3.4.5 目录下执行 bin/zkServer.sh start ,出现如下图内容就算完成啦。
注:三台主机都要分别启动

-
查看集群状态:
(1) 在kafka01下查看
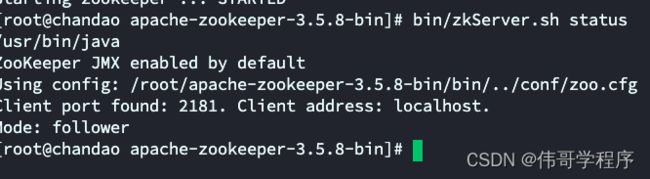
(2)在kafka02下查看
(3)在kafka03下查看
Kafka安装
安装完Zookeeper后,接下来就可以安装Kafka了,同样的套路首先去Kafka的官网下载地址,复制下载链接:
- https:// zookeeper.apache.org/re leases.html#download
然后到Linux中使用wget命令进行下载,如下:
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz
# 2.11是scala的版本,2.4.1是kafka的版本
tar -xzf kafka_2.11-2.4.1.tgz
进入Kafka的配置文件目录,修改配置文件:
cd kafka_2.11-2.4.1
vim config/server.properties
# 指定该节点的brokerId,同一集群中的brokerId需要唯一
broker.id=0
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.100.86:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.100.86:9092
# 指定kafka日志文件的存储目录
log.dirs=/usr/local/kafka/kafka-logs
# 指定zookeeper的连接地址,若有多个地址则用逗号分隔
zookeeper.connect=192.168.100.86:2181,192.168.100.85:2181,192.168.100.36:2181
在完成配置文件的修改后,为了方便使用Kafka的命令脚本,我们可以将Kafka的bin目录配置到环境变量中:
[[email protected] ~]# vim /etc/profile
export KAFKA_HOME=/root/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
[[email protected] ~]# source /etc/profile # 让配置生效
这样就可以使用如下命令启动Kafka了:
kafka-server-start.sh /root/kafka_2.11-2.4.1/config/server.properties &
执行以上命令后,启动日志会输出到控制台,可以通过日志判断是否启动成功,也可以通过查看是否监听了9092端口来判断是否启动成功:
netstat -lntp |grep 9092
同样的,开启了防火墙的话,还需要开放相应的端口号:
firewall-cmd --zone=public --add-port=9092/tcp --permanent
firwall-cmd --reload
到此为止,我们就完成了第一个Kafka节点的安装,另外两个节点的安装步骤也是一样的,只需要修改一下配置文件中的brokerId和监听的ip就好了。]然后修改一下这两个节点的brokerId和监听的ip:
# 修改brokerId
broker.id=1
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.100.85:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.100.85:9092
# 指定zookeeper的连接地址,若有多个地址则用逗号分隔
zookeeper.connect=192.168.100.86:2181,192.168.100.85:2181,192.168.100.36:2181
# 修改brokerId
broker.id=2
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.100.36:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.100.36:9092
# 指定zookeeper的连接地址,若有多个地址则用逗号分隔
zookeeper.connect=192.168.100.86:2181,192.168.100.85:2181,192.168.100.36:2181
配置修改完成后,按之前所介绍的步骤启动这两个节点。启动成功后进入Zookeeper中,在/brokers/ids下有相应的brokerId数据代表集群搭建成功:
[[email protected] ~]# /usr/local/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 4] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 5]