Hadoop的YARN高可用
一、YARN简介
Hadoop2.0即第二代Hadoop,由分布式存储系统HDFS、并行计算框架MapReduce和分布式资源管理系统YARN三个系统组成,其中YARN是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上的离线处理框架。

YARN 一种开源的分布式资源管理和作业调度技术,它是作为Apache Hadoop 的核心组件之一,负责将系统资源(计算、存储和网络资源)分配给运行在Hadoop集群中的各种应用程序,并对运行在各集群节点上的任务进行调度。在生产环境中,通常采用分布式模式安装部署YARN集群。
YARN集群是一个标准的Master/Slave 结构(主从结构),其中ResourceManager(RM) 为Master, NodeManager(NM) 为 Slave。常见的是一主多从集群,也可以搭建RM的HA高可用集群。
ResourceManager作为主节点,是集群所有可用资源的唯一仲裁者,通过NodeManage管理整个集群的资源,其核心职责是调度分配资源。NodeManage负责在每台具体的机器节点上管理资源。
二、Yarn的高可用架构
ResourceManager的HA通过Active/Standby体系实现,其底层通过ZooKeeper集群来存储RM的状态信息、应用程序的状态。如果Active状态的RM遇到故障,会通过切换Standby状态的RM为Active来继续为集群提供正常服务。
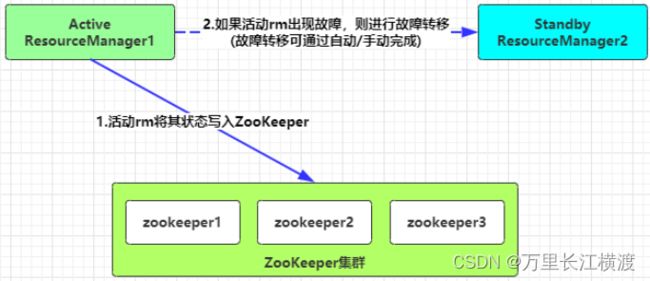
故障转移机制支持自动故障转移和手动故障转移两种方式实现。在生产环境中,自动故障转移应用更为广泛。
第一种:手动故障转移
当没有启用自动故障转移时,管理员必须手动将一个RM转换为活动状态。要从一个RM到另一个RM进行故障转移,需要先把Active状态的RM转换为Standby状态的RM,然后再将Standby状态的RM转换为Active状态的RM。这些操作可用yarn rmadmin 命令来完成。
第二种:自动故障转移
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector(org.apache.hadoop.ha.ActiveStandbyElector类)来实现自动故障转移,以确定哪个RM应该是Active。当Active状态的RM发生故障或无响应时,另一个RM被自动选为Active,然后接管服务。YARN的故障转移不需要像HDFS那样运行单独的ZKFC守护程序,因为ActiveStandbyElector是一个嵌入在RM中充当故障检测器和Leader选举的线程,而不是单独的ZKFC守护进程。
当有多个RM时,Clients和NMs通过读取yarn-site.xml配置找到所有ResourceManager。Clients、AM和NM会轮训所有的ResourceManager并进行连接,直到找着Active状态的RM。如果Active状态的RM也出现故障,它们就会继续查找,直到找着新的Active状态的RM。
三、自动故障转移原理
故障转移原理
YARN这个Active/Standby模式的RM HA架构在运行期间,会有多个RM同时存在,但只能有一个RM处于Active状态,其他的RM则处于Standby状态,当Active节点无法正常提供服务,其余Standby状态的RM则会通过竞争选举产生新的Active节点。以基于ZooKeeper这个自动故障切换为例,切换的步骤如下:
【主备切换】,RM使用基于ZooKeeper实现的ActiveStandbyElector组件来确定RM的状态是Active或Standby。
【创建锁节点,】在ZooKeeper上会创建一个叫做ActiveStandbyElectorLock的锁节点,所有的RM在启动的时候,都会去竞争写这个临时的Lock节点,而ZooKeeper能保证只有一个RM创建成功。创建成功的RM就切换为Active状态,并将信息同步存入到ActiveBreadCrumb这个永久节点,那些没有成功的RM则切换为Standby状态。
【注册Watcher监听】,所有Standby状态的RM都会向/yarn-leader-election/cluster1/ActiveStandbyElectorLock节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的RM的运行情况。
【准备切换】,当Active状态的RM出现故障(如宕机或网络中断),其在ZooKeeper上创建的Lock节点随之被删除,这时其它各个Standby状态的RM都会受到ZooKeeper服务端的Watcher事件通知,然后开始竞争写Lock子节点,创建成功的变为Active状态,其他的则是Standby状态。
【Fencing(隔离)】,在分布式环境中,机器经常出现假死的情况(常见的是GC耗时过长、网络中断或CPU负载过高)而导致无法正常对外进行及时响应。如果有一个处于Active状态的RM出现假死,其他的RM刚选举出来新的Active状态的RM,这时假死的RM又恢复正常,还认为自己是Active状态,这就是分布式系统的脑裂现象,即存在多个处于Active状态的RM,可以使用隔离机制来解决此类问题。
【YARN的Fencing机制是借助ZooKeeper数据节点的ACL权限控制来实现不同RM之间的隔离
。这个地方改进的一点是,创建的根ZNode必须携带ZooKeeper的ACL信息,目的是为了独占该节点,以防止其他RM对该ZNode进行更新。借助这个机制假死之后的RM会试图去更新ZooKeeper的相关信息,但发现没有权限去更新节点数据,就把自己切换为Standby状态。
四、YARN的组件和功能
YARN 总体上仍然是 Master/Slave 结构(主从结构),在整个资源管理框架中, ResourceManager 为Master, NodeManager 为 Slave, ResourceManager 负责对各个 NodeManager 上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的任务。由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。

YARN 主要由 ResourceManager、 NodeManager、ApplicationMaster(图中给出了 MapReduce 和 MPI 两种计算框架的 ApplicationMaster,分别为 MR AppMstr 和 MPI AppMstr)和 Container 等几个组件构成。
