一次记录 flink job 消费kafka 迁移pulsar踩坑过程
背景简述
业务上,原有的kafka集群迁移pulsar 后续会下线kafak集群,原有的一些消费kafka topic 的任务和进程需要迁移至pulsar 并下线旧的消费kafka任务。目前在迁移期间,上报的消息会双写到kafka pulsar,消费组的offset二者是独立的。
待迁移的flink job 之前flink 版本是 1.9.1(scala 2.12) 消费kafak
FlinkKafkaConsumer myConsumer = KafkaConsumerFactory.get(topic, group);
env.addSource(myConsumer )...
这次迁移 job的版本集群环境需要 升级为 1.13(scala 2.12) 消费pulsar
/*job main 方法 消费topic 迁移到pulsar*/
FlinkPulsarSource myConsumer = PulsarSourceFactory.getSource(topic, group);
env.addSource(myConsumer)...
/**
* @author: xiejiahao
* Date: 2021/12/22 11:28
* Description:
*/
public class PulsarSourceFactory {
public static final String serviceUrl =
"pulsar://pulsar-***:6651";
public static final String adminUrl =
"http://pulsar-*****:8441";
public static FlinkPulsarSource getSource(String topic, String group) {
FlinkPulsarSource flinkPulsarSource =
new FlinkPulsarSource<>(
serviceUrl,
adminUrl,
PulsarDeserializationSchema.valueOnly(new SimpleStringSchema()),
buildProperties(topic, group)).setStartFromSubscription(group);
return flinkPulsarSource;
}
private static Properties buildProperties(String topic, String group) {
Properties props = new Properties();
props.put("topic", "persistent://****/" + topic);
props.put("pulsar.reader.subscriptionRolePrefix", group);
props.setProperty("auth-plugin-classname", "org.apache.pulsar.client.impl.auth.AuthenticationToken");
props.setProperty("auth-params", "token:" + AppConfig.get("pulsar_topic_token"));
// earliest
// 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
// latest
// 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
// none
// topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
String offset = AppConfig.get("kafka.offset", "");
if (!StringUtils.isBlank(offset)) {
props.put("auto.offset.reset", offset);
}
// props.put("client.id", "h_c_" + ThreadLocalRandom.current().nextLong());
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", ByteArrayDeserializer.class.getName());
return props;
}
}
开发过程需要注意的点(踩坑记录)
flink支持消费pulsar 必备的依赖
org.apache.flink
flink-connector-pulsar_2.12
1.13.0
${scope.version}
org.apache.pulsar
pulsar-client-all
2.8.0
${scope.version}
pom文件里面依赖配置的 ${scope.version} 本地测试时设置为compile 打包提交到集群时 为避免和集群依赖冲突 改为provided 然后再打包上传
上传jar包时,应确认jar包中不存在与flink, pulsar相关的依赖包,避免运行作业时与平台自带的依赖包发生冲突。
当在本地进行测试时,因为job之前的版本是1.9.1 本地测试时需要/org/apache/flink/flink-core/1.13.0/flink-core-1.13.0.jar下载依赖包到本地并进行替换。
依赖冲突解决
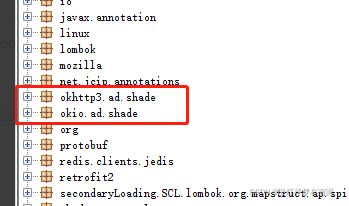
这里 我的flink job中需要使用到consul 用来服务发现 codis集群,但是consul内置的okhttp okio版本都要高于flink集群上的版本,因为版本冲突 运行Job时直接报错 NoSuchMethodError
这类问题的解决办法是 使用maven-shade-plugin 对版本冲突的报的类名直接重命名 然后才重新编译
org.apache.maven.plugins
maven-shade-plugin
3.1.1
package
shade
com.test.App
okio
okio.ad.shade
okhttp3
okhttp3.ad.shade
在重新打包后, 通过jd-gui 查看jar 可发现pom 依赖的 okio okhttp3 已经重命名,这样可解决job 自身依赖的jar 与平台不兼容问题
日志框架冲突导致job 运行时无业务日志输出
我的flink job自身使用的日志框架是 common-log, 但是flink集群默认使用的日志框架是log4j 二者发生冲突导致 job 自身的业务日志无法输出, 这里改为slf4j + log4j2
具体操作是
org.slf4j
slf4j-api
1.7.25
${scope.version}
org.slf4j
slf4j-log4j12
1.7.21
${scope.version}
log4j
log4j
1.2.17
${scope.version}
并配置log4j.properties
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Threshold=INFO
log4j.appender.console.ImmediateFlush=true
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n
这里具体的配置 参考的是:https://www.shuzhiduo.com/A/gAJGqkEodZ/
值得注意的是 log4j 已经报出有安全漏洞问题,当你的项目pom文件中 配置log4j依赖 打包到平台一定要确定scop为provided 以便使用集群上统一的高版本的log4j。
timewindow算子过期不能使用导致sink输出没有数据
这个坑 应该是本次迁移 折腾最久的一个坑了,因为之前日志框架冲突的问题没有解决 sink输出没有数据 也无法定位到是哪一块出现问题。
job 自身逻辑中 对数据的唯一id hashcode keyBy分区之后 timeWindow(60s) 将批量的数据 写入db中进行存储,但是日志观察window函数 一直没有正常日志输出,sink输出的db 也一直没有数据。
这里对flink 环境设置
if (arg.contains("TEST")){
env.disableOperatorChaining();
}
重新提交 观察数据在各个算子建的流动情况时发现 window算子这里只有记录接收 无记录发送到下游
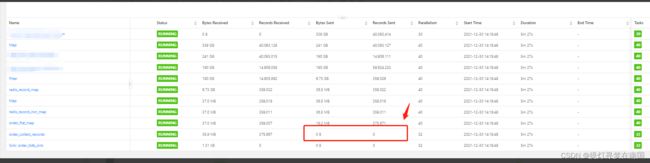
初步怀疑是历史代码的timewindow算子 在flink 1.13的版本里面有bug 导致window执行出现异常
解决办法:
这里测试 将keyBy+window 简化成一个flatmap 算子有正常输入输出了
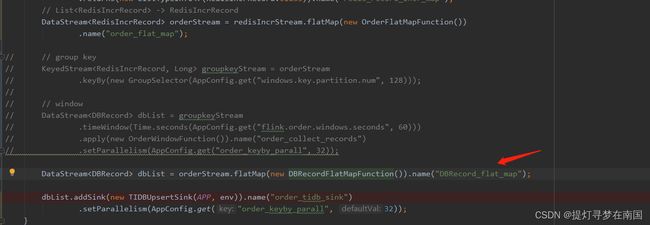
考虑到业务场景 最好是批量写入tidb 减少tidb的连接数, 这里后面改用了countwindow来做window函数 默认的size是100
int tidbCountWindowsSize = AppConfig.get("main.tidb.countWindowsSize", 100);
int tidbCountTriggerTimeout = AppConfig.get("main.tidb.CountTriggerTimeout", 1000);
LogCountWithTimeoutTrigger tidbCountWithTimeoutTrigger = LogCountWithTimeoutTrigger.of(tidbCountWindowsSize,
tidbCountTriggerTimeout);
DataStream dbList = groupkeyStream
.countWindow(tidbCountWindowsSize).trigger(tidbCountWithTimeoutTrigger)
.process(new OrderCountWindowFunction(tidbCountWindowsSize)).name("order_countWindow_records");
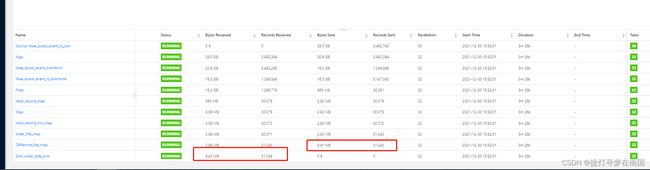
部署后 数据在各个算子的流动情况一切正常
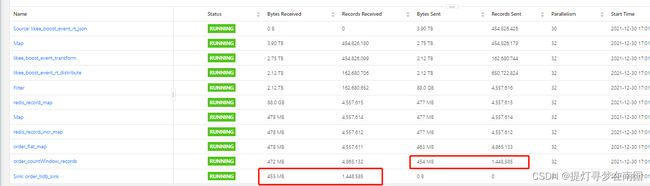
对比测试环境tidb和线上消费kafka sink输出到tidb 的数据情况,因为测试环境使用的countwindow(默认是100) 数据从redis获取去重的数据更新到tidb 更快,性能要优于之前逻辑。