麻省理工学院新进展!人工智能协助机器人使用整体操控技术
原创 | 文 BFT机器人

麻省理工学院的研究人员开发了一种人工智能技术,使机器人能够制定复杂的计划,利用整只手而不仅仅是指尖来操控物体。这个模型可以在约一分钟内使用标准笔记本生成有效的计划。上图为一个机器人尝试将一个桶旋转180度。
想象一下,你想要把一个又大又重的箱子搬上楼梯。你可能会将手指张开,用双手抬起箱子,然后将其放在前臂上,靠近胸部保持平衡,利用整个身体来操控箱子。人类通常擅长整体操控,但机器人在这种任务上往往遇到困难。对于机器人来说,箱子可能与搬运者的手指、手臂和躯干的任何点接触的地方都代表着必须思考的接触事件。由于潜在的接触事件数量庞大,规划这个任务很快变得难以处理。
现在,麻省理工学院的研究人员找到了一种简化这个过程的方法,称为接触丰富的操控规划。他们使用了一种名为“平滑”的人工智能技术,将许多接触事件总结为较少的决策,从而使即使是简单的算法也能够快速识别出机器人的有效操控计划。
尽管还处于早期阶段,这种方法有潜力让工厂使用更小型、移动的机器人,这些机器人可以用整只手臂或整个身体来操控物体,而不是仅能使用指尖抓取的大型机械臂,这可能有助于降低能源消耗并降低成本。此外,这项技术还可以在被派往火星或其他太阳系天体的探险任务中派上用场,因为它们可以仅依靠机载计算机快速适应环境。
“如果我们能够利用这类机器人系统的结构,而不是将其视为黑匣子系统,那么就有机会加速尝试做出这些决策和制定接触丰富计划的整个过程,” 电气工程与计算机科学(EECS)研究生,以及这项技术的共同主要作者之一 H.J. Terry Suh 表示。在这篇论文上与 Suh 一起合作的还有共同主要作者 Tao Pang(博士生),他是波士顿动力人工智能研究所的机器人学家;Lujie Yang,一名电气工程与计算机科学研究生;以及资深作者 Russ Tedrake,他是电气工程与计算机科学、航空航天学和机械工程的丰田教授,同时也是计算机科学与人工智能实验室(CSAIL)的成员。这项研究发表在本周的《IEEE Transactions on Robotics》杂志上。
强化机器学习
强化学习是一种机器学习技术,其中代理者(如机器人)通过不断尝试和错误来学习完成任务,每当它接近目标时,会得到一定的奖励。研究人员表示,这种类型的学习采用了黑匣子方法,因为系统必须通过试错来学习关于世界的一切。
强化学习已经在接触丰富的操控规划中取得了有效的应用,其中机器人试图学习以指定方式移动物体的最佳方法。
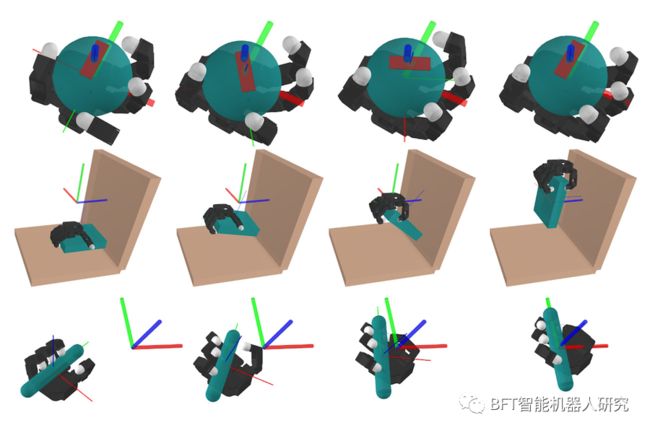
在这些图中,一个模拟的机器人执行了三个接触丰富的操控任务:手中操控一个球,拾取一个盘子,以及将一支笔调整到特定的方向。
但是,当机器人确定如何使用其手指、手、臂和身体与物体互动时,可能会有数十亿潜在的接触点需要机器人进行推理,因此这种试错方法需要大量计算。另一方面,如果研究人员专门设计一个基于物理的模型,利用他们对系统和他们希望机器人完成的任务的知识,那么这个模型会融入关于这个世界的结构,从而使其更加高效。
然而,在接触丰富的操控规划方面,基于物理的方法并不像强化学习那样有效。研究人员进行了详细的分析,并发现一种称为“平滑”的技术使强化学习表现出色。机器人在确定如何操控物体时可能会做出许多决策,但在总体上并不重要。例如,每次手指的微小调整,无论是否与物体接触,都并不重要,平滑会对许多不重要的、中间的决策进行平均,留下一些重要的决策。
强化学习通过尝试许多接触点,然后计算结果的加权平均值来隐式地进行平滑。基于这一见解,麻省理工学院的研究人员设计了一个简单的模型,执行类似类型的平滑操作,使其能够专注于核心的机器人-物体交互并预测长期行为。他们表明,这种方法在生成复杂计划方面可能与强化学习一样有效。
一个成功的组合
尽管平滑大大简化了决策,但搜索剩下的决策仍然可能是一个困难的问题。因此,研究人员将他们的模型与一种可以快速高效地搜索机器人可能做出的所有可能决策的算法结合在一起。通过这种组合,计算时间在标准笔记本电脑上缩短到大约一分钟。
他们首先在模拟中测试了他们的方法,其中机械手被分配了任务,比如将一支笔移动到所需的配置,打开一扇门或者拾取一个盘子。在每个实例中,他们的基于模型的方法都达到了与强化学习相同的性能,但时间仅为其一小部分。当他们在真实机械臂上的硬件中测试他们的模型时,他们也看到了类似的结果。

关于IiwaBimanual设置的硬件,目标是将桶旋转180度。左边和右边的图片分别对应于开环计划执行前的初始状态和最终状态。连接在运动捕捉标记之间的线条用于说明桶的姿态变化。
Tedrake说:“使整体操控成为可能的相同思想也适用于具有灵巧、类似人类手的计划。以前,大多数研究人员认为强化学习是唯一适用于灵巧手的方法,但Terry和Tao表明,通过从强化学习中采取(随机)平滑的这一关键思想,他们也可以使传统的规划方法非常有效。”
然而,他们开发的模型依赖于对真实世界的较简单的近似,因此无法处理非常动态的运动,例如物体下落。虽然对于较慢的操控任务有效,但他们的方法无法创建一个计划,例如使机器人能够将一个罐头扔进垃圾桶。在未来,研究人员计划改进他们的技术,以应对这些高度动态的运动。
作者 | LJH
排版 | 小河
审核 | 猫
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。如果想要了解更多的前沿资讯,记得点赞关注哦~