【链表篇】速刷牛客TOP101 高效刷题指南
文章目录
- 1、BM1 反转链表
- 2、BM2 链表内指定区间反转
- 3、BM3 链表中的节点每k个一组翻转
- 4、BM4 合并两个排序的链表
- 5、BM5 合并k个已排序的链表
- 6、BM6 判断链表中是否有环
- 7、BM7 链表中环的入口结点
- 8、BM8 链表中倒数最后k个结点
- 9、BM9 删除链表的倒数第n个节点
- 10、BM10 两个链表的第一个公共结点
- 11、BM11 链表相加(二)
- 12、BM12 单链表的排序
- 13、BM13 判断一个链表是否为回文结构
- 14、BM14 链表的奇偶重排
- 15、BM15 删除有序链表中重复的元素-I
- 16、BM16 删除有序链表中重复的元素-II
1、BM1 反转链表

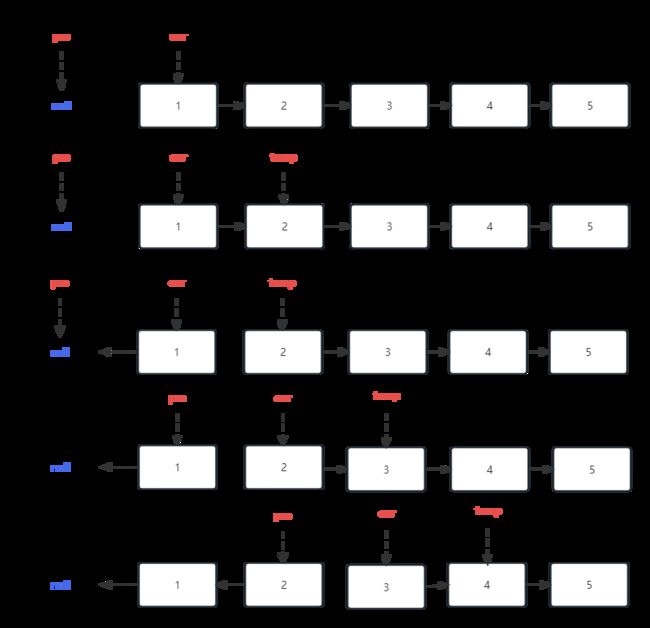
题意:反转一个单链表。
示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
思路步骤:
-
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
-
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
-
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
-
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
-
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
画图演示:
public class Solution {
public ListNode ReverseList(ListNode head) {
//pre指针:用来指向反转后的节点,初始化为null
ListNode pre = null;
//当前节点指针
ListNode cur = head;
//循环迭代
while(cur!=null){
//temp节点,永远指向当前节点cur的下一个节点
ListNode temp = cur.next;
//反转的关键:当前的节点指向其前一个节点(注意这不是双向链表,没有前驱指针)
cur.next = pre;
//更新pre
pre = cur;
//更新当前节点指针
cur = temp ;
}
//为什么返回pre?因为pre是反转之后的头节点
return pre;
}
}
2、BM2 链表内指定区间反转

思路步骤:
-
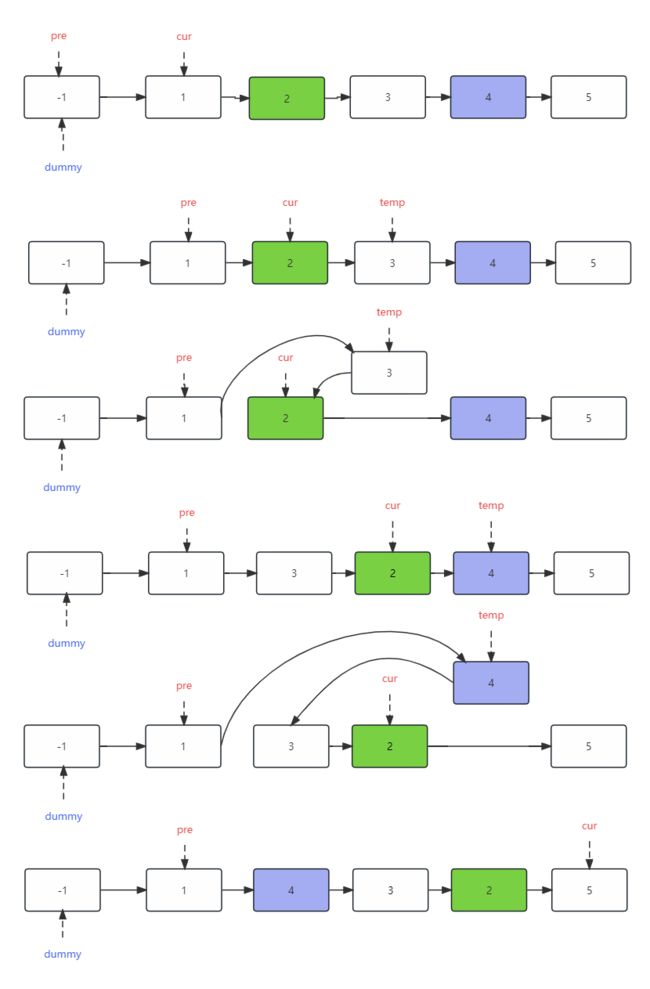
构建一个虚拟结点,让它指向原链表的头结点。
-
设置两个指针,pre 指针指向以虚拟头结点为链表的头部位置,cur 指针指向原链表的头部位置。
-
让着两个指针向前移动,直到 pre 指向了第一个要反转的结点的前面那个结点,而 cur 指向了翻转区域里面的第一个结点。
-
开始指向翻转操作
- 设置临时变量 temp,temp 是 cur 的 next 位置,保存当前需要翻转结点的后面的结点,我们需要交换 temp 和 cur
- 让 cur 的 next 位置变成 temp 的下一个结点
- 让 temp 的 next 位置变成 cur
- 让 pre 的 next 位置变成 temp
画图演示:
public class Solution {
public ListNode reverseBetween (ListNode head, int m, int n) {
if (head == null || head.next == null) {
return head;
}
// 一开始设置一个虚拟节点,它的值为 -1,它的值可以设置为任何的数,因为我们根本不需要使用它的值
// 设置虚拟节点的目的是为了让原链表中所有节点就都可以按照统一的方式进行翻转
// 比如如果翻转的区间包含了原链表中的第一个位置,那么如果不设置 dummy
// 在翻转的过程中需要设置其它的临时变量来保持第一位置节点的指针
// 具体可以通过动画来理解
ListNode dummy = new ListNode(-1);
// 让虚拟节点指向原链表的头部
dummy.next = head;
// 设置一个指针,指向以虚拟头节点为链表的头部位置
ListNode pre = dummy;
// 设置一个指针,指向原链表的头部位置
ListNode cur = head;
// 从虚拟头节点出发,pre 走 m - 1 步找到需要翻转的左区间
// for 循环结束后,pre 的右节点是需要翻转的节点
// for 循环结束后,cur 指向的就是需要翻转的节点
for (int i = 0; i < m - 1; i++) {
// pre 不断的向右移动,直到走到翻转的左区间为止
pre = pre.next;
// cur 不断的向右移动,找到了需要翻转的第一个节点
cur = cur.next;
}
// 开始翻转这些节点
for (int i = 0; i < n - m; i++) {
// 设置临时变量,保存当前需要翻转节点的后面的节点
ListNode temp = cur.next;
// 这个时候,让 temp 和 cur 两个节点翻转一下
// cur.next = cur.next.next;
// 两行代码等价
cur.next = temp.next;
temp.next = pre.next;
pre.next = temp;
}
// 最后返回虚拟头节点的下一个节点,因为虚拟节点不在链表中
return dummy.next;
}
}
3、BM3 链表中的节点每k个一组翻转

思路步骤:
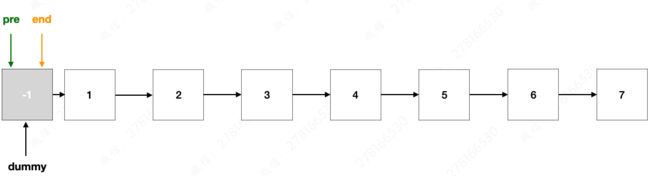
- 对于原链表来说,除了头结点之外,其余的所有结点都有前面一个结点指向它,那么为了避免在操作这些结点(比如移动、删除操作)过程中需要判断当前结点是否是头结点,可以在原链表的前面增加一个虚拟结点,这样就可以使得原链表里面的所有结点的地位都是一样的了。
-
接下来,设置两个指针,都指向虚拟头结点的位置,一个指针是 pre,它在后续的操作过程中会始终指向每次要翻转的链表的头结点的【上一个结点】,另外一个指针是 end,它在后续的操作过程中会始终指向每次要翻转的链表的尾结点。
-
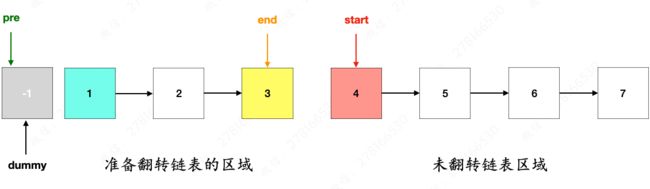
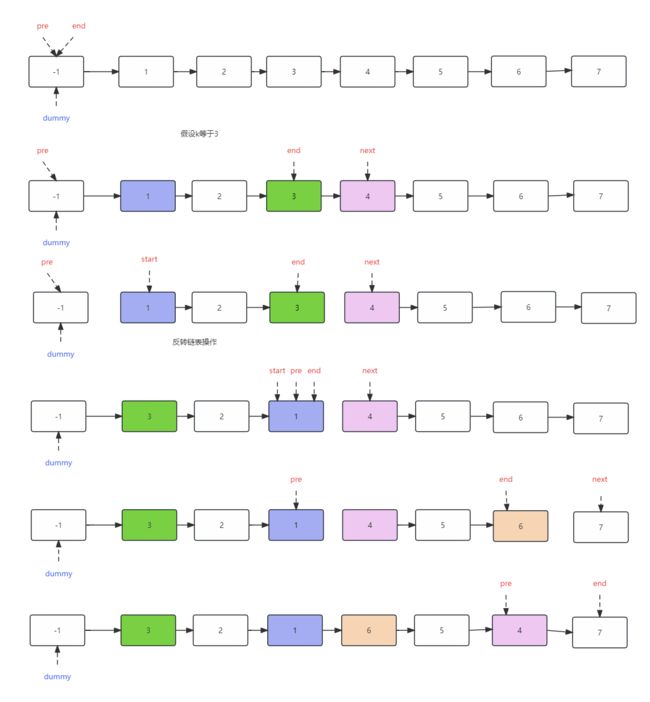
以 k 为 3 作为示例,那么 pre 和 end 不断的向后移动,当 end 来到 3 这个结点的时候,已经寻找出来需要翻转的那 3 个结点,并且 pre 依旧指向 dummy,因为 1 这个结点是翻转区域的头结点,前面那个则是上一个结点,因此 pre 还停留在原地。

- 那么需要去翻转 1 、2 、3 这个结点,为了避免翻转过程会影响其它区域的结点,这个时候就需要把翻转区域和其它区域断开连接,同时又为了保证翻转成功之后能顺利连接回去,因此需要记录一下后续的结点,这个结点也就是 end.next ,接下来再断开准备翻转链表区域的前后区域,如下图所示。
-
而 1 、2 、3 的翻转过程可以直接套用**反转链表**这题的思路和代码。
-
该区域的结点翻转成功之后,连接回去,回到第 2 点提到的 pre 这个指针是始终指向每次要翻转的链表的头结点的【上一个结点】,实际上也就是已经翻转区域的尾结点位置,所以 pre 需要来到 end 的位置,即 1 这个结点位置。

- 接下来,继续让 end 向后移动,找到 k 个结点来。

-
每次 end 寻找出 k 个结点之后,都会执行同样的逻辑,记录接下来需要翻转区域的头结点, 断开前后的区域,翻转本区域的结点,再让 pre 来到 end 的位置,end 来到 start 的位置。
-
最后,直到 end 遍历不到 k 个结点或者指向了 null 的时候也就完成了整个翻转过程。
接下来看完整的图:
画图演示:
public class Solution {
public ListNode reverseKGroup (ListNode head, int k) {
// 一开始设置一个虚拟结点
ListNode dummy = new ListNode(-1);
// 虚拟头结点的下一结点指向 head 结点
dummy.next = head;
// 设置一个指针,指向此时的虚拟结点,pre 表示每次要翻转的链表的头结点的【上一个结点】
ListNode pre = dummy;
// 设置一个指针,指向此时的虚拟结点,end 表示每次要翻转的链表的尾结点
ListNode end = dummy;
// 通过 while 循环,不断的找到翻转链表的尾部
while (end.next != null) {
// 通过 for 循环,找到【每一组翻转链表的尾部】
for (int i = 0 ; i < k && end != null ; i++) {
// end 不断的向后移动,移动 k 次到达【每一组翻转链表的尾部】
end = end.next ;
}
// 如果发现 end == null,说明此时翻转的链表的结点数小于 k ,保存原有顺序就行
if (end == null) {
break;
}
// next 表示【待翻转链表区域】里面的第一个结点
ListNode next = end.next;
// 【翻转链表区域】的最尾部结点先断开
end.next = null ;
// start 表示【翻转链表区域】里面的第一个结点
ListNode start = pre.next;
// 【翻转链表区域】的最头部结点和前面断开
pre.next = null;
// 这个时候,【翻转链表区域】的头结点是 start,尾结点是 end
// 开始执行【反转链表】操作
// 要翻转的链表的头结点的【上一个结点】的 next 指针指向这次翻转的结果
pre.next = reverseList(start);
// 接下来的操作是在为【待翻转链表区域】的反转做准备
// 【翻转链表区域】里面的尾结点的 next 指针指向【待翻转链表区域】里面的第一个结点
start.next = next ;
// pre 表示每次要翻转的链表的头结点的【上一个结点】
pre = start;
// 将 end 重置为【待翻转链表区域】的头结点的上一个结点。
end = start;
}
return dummy.next;
}
private ListNode reverseList(ListNode head) {
//pre指针:用来指向反转后的节点,初始化为null
ListNode pre = null;
//当前节点指针
ListNode cur = head;
//循环迭代
while(cur!=null){
//temp节点,永远指向当前节点cur的下一个节点
ListNode temp = cur.next;
//反转的关键:当前的节点指向其前一个节点
cur.next = pre;
//更新pre
pre = cur;
//更新当前节点指针
cur = temp ;
}
//为什么返回pre?因为pre是反转之后的头节点
return pre;
}
}
4、BM4 合并两个排序的链表
解法一:递归法
思路步骤:
- 从头结点开始考虑,比较两表头结点的值,值较小的
list的头结点后面接merge好的链表(进入递归了); - 若两链表有一个为空,返回非空链表,递归结束;
- 当前层不考虑下一层的细节,当前层较小的结点接上该结点的
next与另一结点merge好的表头就ok了; - 每层返回选定的较小结点就ok;
重新整理一下:
- 终止条件:两链表其中一个为空时,返回另一个链表;
- 当前递归内容:若
list1.val <= list2.val将较小的list1.next与merge后的表头连接,即list1.next = Merge(list1.next,list2);list2.val较大时同理; - 每次的返回值:排序好的链表头;
复杂度:O(m+n) O(m+n)
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param list1 ListNode类
* @param list2 ListNode类
* @return ListNode类
*/
public ListNode Merge (ListNode list1, ListNode list2) {
// write code here
//basecase
//要是list1为空,直接返回list2,同理
if(list1 == null){
return list2;
}else if(list2 == null){
return list1;
}
//递归
if(list1.val < list2.val){
list1.next = Merge(list1.next,list2);
return list1;
}else{
list2.next = Merge(list1,list2.next);
return list2;
}
}
}
解法二:迭代法
思路步骤:
-
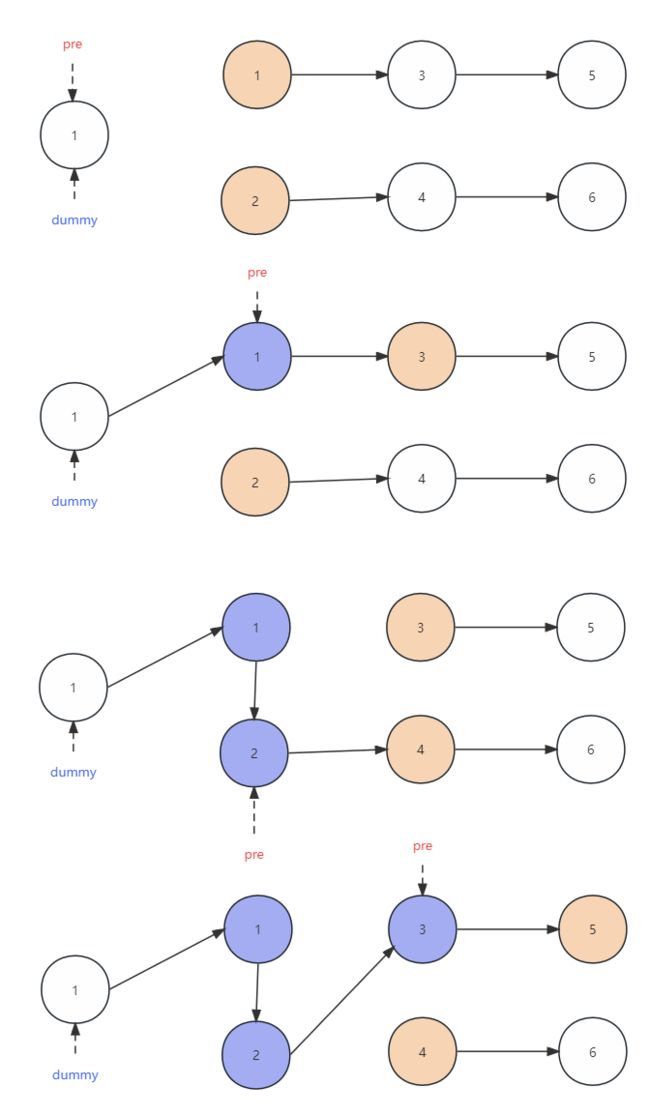
一开始设置一个虚拟结点,它的值为 -1,它的值可以设置为任何的数,因为我们根本不需要使用它的值。
-
设置一个指针 pre,指向虚拟结点,在后续的操作过程中,会移动 pre 的位置,让它指向
所有已经排好序的结点里面的最后一个结点位置。 -
借助 while 循环,不断的比较 list1 和 list2 中当前结点值的大小,直到 list1 或者 list2 遍历完毕为止。
-
在比较过程中,如果 list1 当前结点的值小于等于了 list2 当前结点的值,让 pre 指向结点的 next 指针指向这个更小值的结点,即 list1 上面的当前结点,同时继续访问 list1 的后续结点。
-
如果 list1 当前结点的值大于了 list2 当前结点的值,让 pre 指向结点的 next 指针指向这个更小值的结点,即 list2 上面的当前结点,同时继续访问 list2 的后续结点。
-
每次经过 4 、5 的操作之后,都会让 pre 向后移动,因为需要保证 pre 指向
所有已经排好序的结点里面的最后一个结点位置。
画图演示:
参考代码:
public class Solution {
public ListNode Merge (ListNode list1, ListNode list2) {
// 一开始设置一个虚拟结点,它的值为 -1,它的值可以设置为任何的数,因为我们根本不需要使用它的值
ListNode dummy = new ListNode(-1);
// 设置一个指针,指向虚拟结点
ListNode pre = dummy;
// 通过一个循环,不断的比较 list1 和 list2 中当前结点值的大小,直到 list1 或者 list2 遍历完毕为止
while (list1 != null && list2 != null) {
// 如果 list1 当前结点的值小于等于了 list2 当前结点的值
if (list1.val <= list2.val) {
// 让 pre 指向结点的 next 指针指向这个更小值的结点
// 即指向 list1
pre.next = list1;
// 让 list1 向后移动
list1 = list1.next;
} else {
// 让 pre 指向结点的 next 指针指向这个更小值的结点
// 即指向 list2
pre.next = list2;
// 让 list2 向后移动
list2 = list2.next;
}
// 让 pre 向后移动
pre = pre.next;
}
// 跳出循环后,list1 或者 list2 中可能有剩余的结点没有被观察过
// 直接把剩下的结点加入到 pre 的 next 指针位置
// 如果 list1 中还有结点
if (list1 != null) {
// 把 list1 中剩下的结点全部加入到 pre 的 next 指针位置
pre.next = list1;
}
// 如果 list2 中还有结点
if (list2 != null) {
// 把 list2 中剩下的结点全部加入到 pre 的 next 指针位置
pre.next = list2;
}
// 最后返回虚拟结点的 next 指针
return dummy.next;
}
}
5、BM5 合并k个已排序的链表
方法一:归并排序思想
思路步骤:
如果是两个有序链表合并,我们可能会利用归并排序合并阶段的思想:准备双指针分别放在两个链表头,每次取出较小的一个元素加入新的大链表,将其指针后移,继续比较,这样我们出去的都是最小的元素,自然就完成了排序。
其实这道题我们也可以两两比较啊,只要遍历链表数组,取出开头的两个链表,按照上述思路合并,然后新链表再与后一个继续合并,如此循环,知道全部合并完成。但是,这样太浪费时间了。
既然都是归并排序的思想了,那我们可不可以直接归并的分治来做,而不是顺序遍历合并链表呢?答案是可以的!
归并排序是什么?简单来说就是将一个数组每次划分成等长的两部分,对两部分进行排序即是子问题。对子问题继续划分,直到子问题只有1个元素。还原的时候呢,将每个子问题和它相邻的另一个子问题利用上述双指针的方式,1个与1个合并成2个,2个与2个合并成4个,因为这每个单独的子问题合并好的都是有序的,直到合并成原本长度的数组。
对于这k个链表,就相当于上述合并阶段的k个子问题,需要划分为链表数量更少的子问题,直到每一组合并时是两两合并,然后继续往上合并,这个过程基于递归:
- 终止条件: 划分的时候直到左右区间相等或左边大于右边。
- 返回值: 每级返回已经合并好的子问题链表。
- 本级任务: 对半划分,将划分后的子问题合并成新的链表。
具体做法:
- step 1:从链表数组的首和尾开始,每次划分从中间开始划分,划分成两半,得到左边n*/2个链表和右边n*/2个链表。
- step 2:继续不断递归划分,直到每部分链表数为1.
- step 3:将划分好的相邻两部分链表,按照两个有序链表合并的方式合并,合并好的两部分继续往上合并,直到最终合并成一个链表。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param lists ListNode类ArrayList
* @return ListNode类
*/
public ListNode mergeKLists (ArrayList<ListNode> lists) {
// write code here
//k个链表归并排序
return mergeList(lists, 0 ,lists.size() - 1);
}
private ListNode mergeList(ArrayList<ListNode> lists, int left, int right) {
//basecase
//中间一个的情况
if(left == right){
return lists.get(left);
}
if(left > right){
return null;
}
//从中间分成两段,再将合并好的两段合并
int mid = left + ((right - left)>>1);
return merge(mergeList(lists, left, mid),mergeList(lists, mid + 1,right));
}
//递归法合并两个有序链表
private ListNode merge(ListNode list1, ListNode list2){
//basecase
if(list1 == null){
return list2;
}if(list2 == null){
return list1;
}
if(list1.val < list2.val){
list1.next = merge(list1.next, list2);
return list1;
}else{
list2.next = merge(list1, list2.next);
return list2;
}
}
}
方法二:优先队列
思路步骤:
对于这道题目,我们借助优先队列这种数据结构来辅助解决,关于优先队列的概念,我们只需要先了解它是一种数据结构,它可以帮助我们把一堆数据塞进去之后获取到里面的最值即可,在于它内部是如何实现的,不理解也是可以做出本题的。
具体操作是这样的。
-
遍历链表数组,把每个链表的开头元素都填入到
优先队列里面, 优先队列会自己处理,把头节点最小的值放到前面去。 -
接下来,开始弹出优先队列的队头元素,它是里面最小的结点,把它连接到最后的结果上面去。
-
每次弹出一个结点来,再把一个新的结点加入到优先队列里面,而这个新的结点就是弹出结点所在链表的下一个结点。
-
反复执行第 3 步操作也就完成了整个排序操作。
画图演示:

public class Solution {
public ListNode mergeKLists(ArrayList<ListNode> lists) {
// 队列是遵循先进先出(First-In-First-Out)模式的,但有时需要在队列中基于优先级处理对象。
// PriorityQueue 和队列 Queue 的区别在于 ,它的出队顺序与元素的优先级有关
// 对 PriorityQueue 调用 remove() 或 poll() 方法 ,返回的总是优先级最高的元素
// Java 中 PriorityQueue 通过二叉小顶堆实现
// PriorityQueue 默认是一个【小顶堆】,可以通过传入自定义的 Comparator 函数来实现【大顶堆】
Queue<ListNode> pq = new PriorityQueue<>((v1, v2) -> v1.val - v2.val);
// 遍历所有链表
for (ListNode node: lists) {
// PriorityQueue 实现了 Queue 接口,不允许放入 null 元素
if (node != null) {
// 把所有链表都加入到优先队列当中
// 优先队列会自己处理,把头节点最小的值放到前面去
pq.offer(node);
}
// ListNode node = pq.peek();
// System.out.println(node.val);
}
// 添加一个虚拟头节点(哨兵),帮助简化边界情况的判断
ListNode dummyHead = new ListNode(-1);
// 合并成功之后的尾节点位置
ListNode tail = dummyHead;
// 遍历优先队列,取出最小值出来
while (!pq.isEmpty()) {
// 取出优先队列,即二叉堆的头节点,最小的节点
ListNode minNode = pq.poll();
// 把这个节点连接到合并链表的尾部
tail.next = minNode;
// tail 的位置也随之发生变化
tail = minNode;
// PriorityQueue 实现了 Queue 接口,不允许放入 null 元素
if (minNode.next != null) {
// 再把新的节点也加入到优先队列当中
pq.offer(minNode.next);
}
}
// 整个过程其实就是「多路归并」过程
// 返回结果
return dummyHead.next;
}
}
6、BM6 判断链表中是否有环
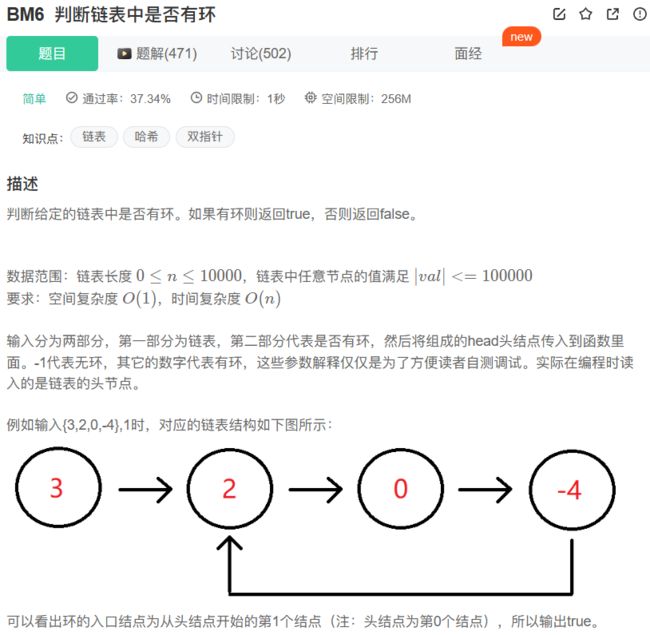
思路步骤:
我们都知道链表不像二叉树,每个节点只有一个val值和一个next指针,也就是说一个节点只能有一个指针指向下一个节点,不能有两个指针,那这时我们就可以说一个性质:环形链表的环一定在末尾,末尾没有NULL了。为什么这样说呢?仔细看上图,在环2,0,-4中,没有任何一个节点可以指针指出环,它们只能在环内不断循环,因此环后面不可能还有一条尾巴。如果是普通线形链表末尾一定有NULL,那我们可以根据链表中是否有NULL判断是不是有环。
但是,环形链表遍历过程中会不断循环,线形链表遍历到NULL结束了,但是环形链表何时能结束呢?我们可以用双指针技巧,同向访问的双指针,速度是快慢的,只要有环,二者就会在环内不断循环,且因为有速度差异,二者一定会相遇。
具体做法:
- step 1:设置快慢两个指针,初始都指向链表头。
- step 2:遍历链表,快指针每次走两步,慢指针每次走一步。
- step 3:如果快指针到了链表末尾,说明没有环,因为它每次走两步,所以要验证连续两步是否为NULL。
- step 4:如果链表有环,那快慢双指针会在环内循环,因为快指针每次走两步,因此快指针会在环内追到慢指针,二者相遇就代表有环。
public class Solution {
public boolean hasCycle(ListNode head) {
/**
快慢指针
*/
//先判断链表为空的情况
if(head == null){
return false;
}
//快慢双指针
ListNode fast = head;
ListNode slow = head;
//如果链表有环,那么无论怎么移动,fast 指向的节点都是有值的
while(fast != null && fast.next != null){
//快指针移动两步
fast = fast.next.next;
slow = slow.next;
//相遇则有环
if(fast == slow){
return true;
}
}
//到末尾则没有环
return false;
}
}
7、BM7 链表中环的入口结点
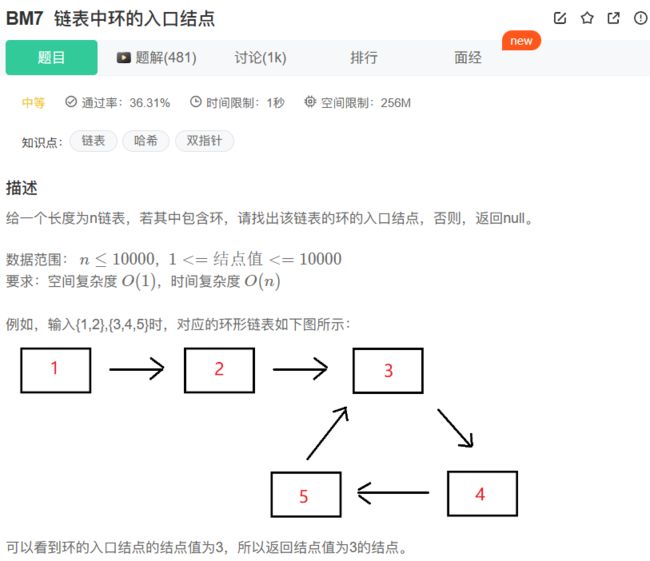
题目描述:
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
思路步骤:
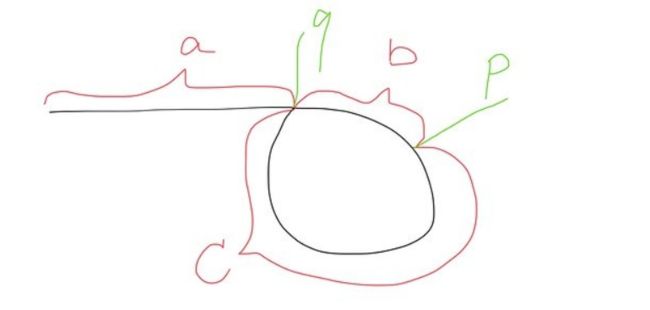
- 这题我们可以采用双指针解法,一快一慢指针。快指针每次跑两个element,慢指针每次跑一个。如果存在一个圈,总有一天,快指针是能追上慢指针的。
- 如下图所示,我们先找到快慢指针相遇的点p。我们再假设,环的入口在点q,从头节点到点q距离为A,q p两点间距离为B,p q两点间距离为C。
- 因为快指针是慢指针的两倍速,且他们在p点相遇,则我们可以得到等式 2(A+B) = A + B + n * (B + C)
- 由3的等式,我们可得,C = A。
- 这时,因为我们的slow指针已经在p,我们可以新建一个另外的指针slow2,让他从头节点开始走,每次只走下一个,原slow指针继续保持原来的走法,和slow2同样,每次只走下一个。
- 我们期待着slow2和原slow指针的相遇,因为我们知道A=C,所以当他们相遇的点,一定是q了。
- 我们返回slow2或者slow任意一个节点即可,因为此刻他们指向的是同一个节点,即环的起始点q。
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead) {
/**
快慢指针
*/
//basecase
if(pHead == null && pHead.next == null){
return pHead;
}
//定义两个指针
ListNode fast = pHead;
ListNode slow = pHead;
//如果链表有环,那么无论怎么移动,fast 指向的节点都是有值的
while (fast != null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
//快慢指针相遇,说明有环
if(fast == slow){
//开始寻找环入口
ListNode slow2 = pHead;
while(slow2 != slow){
slow2 = slow2.next;
slow = slow.next;
}
//返回 slow 和 slow2 相遇的节点位置就是环形入口节点位置
return slow;
}
}
return null;
}
}
8、BM8 链表中倒数最后k个结点

思路步骤:
这题要求链表的倒数第k个节点,最简单的方式就是使用两个指针
第一个指针先移动k步,然后第二个指针再从头开始,这个时候这两个指针同时移动,当第一个指针到链表的末尾的时候,返回第二个指针即可。
注意,如果第一个指针还没走k步的时候链表就为空了,我们直接返回null即可。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
public ListNode FindKthToTail (ListNode pHead, int k) {
// write code here
//双指针
//basecase
if(pHead == null){
return pHead;
}
//首先定义两个指针,一开始都指向链表的头结点
ListNode first = pHead;
ListNode second = pHead;
//让first指针先走k步
while(k > 0){
//如果first还没走到k步链表就为空,直接返回null
if(first == null){
return null;
}
first = first.next;
k--;
}
//然后两个指针一起走,直到前指针 first 指向 NULL
while(first != null){
first = first.next;
second = second.next;
}
//返回second节点
return second;
}
}
9、BM9 删除链表的倒数第n个节点
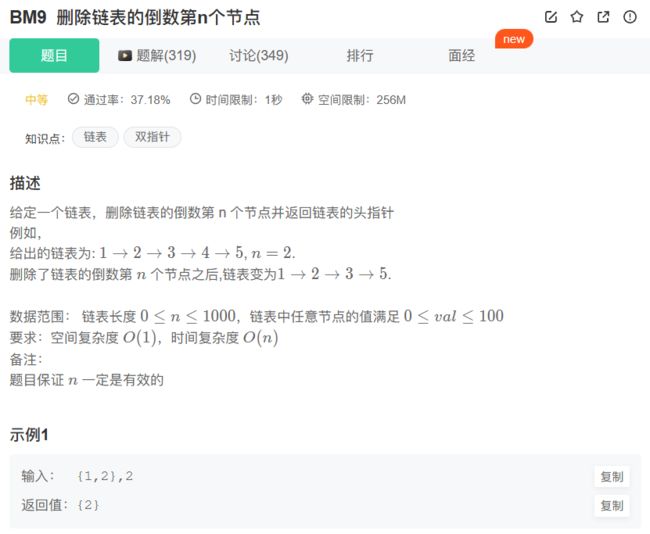
思路步骤:
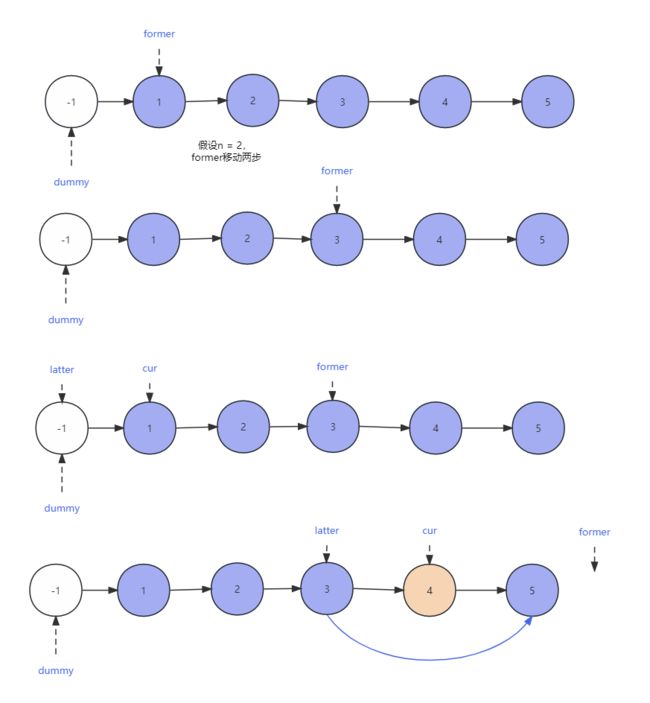
-
再原链表的前面添加一个虚拟头结点,使得原链表的头结点和其余的结点地位一样,进行删除操作时不需要进行区分处理。
-
在原链表的头部设置一个指针 former,使用 for 循环让它向后移动 n 步。
-
在原链表的头部再设置一个指针 cur,同时在虚拟头结点位置设置一个指针 latter。
-
接下来,同时让这三个指针向后移动,直到 former 指向了 null,此时 cur 指向的恰好就是倒数第 n 个结点。
-
由于 latter 一直在 cur 的上一个结点位置,这个时候只需要让 latter 指向 cur 的下一个结点,那么也就完成了删除 cur 结点的操作。
画图演示:
public class Solution {
public ListNode removeNthFromEnd (ListNode head, int n) {
// 双指针解法
// 添加表头
ListNode dummy = new ListNode(-1);
dummy.next = head;
// 寻找需要删除的节点
ListNode cur = head;
// 指针 latter 指向虚拟头结点
ListNode latter = dummy;
ListNode former = head;
// 让 former 指针先向前走 n 步
for (int i = 0 ; i < n; i++) {
// former 指针向后移动
former = former.next;
}
// 接下来,让这两个指针 former 和 latter 同时向前移动,直到前指针 former 指向 NULL
while (former != null) {
// former 指针向后移动
former = former.next;
// latter 来到 cur 的位置
latter = cur;
// cur 指针向后移动
cur = cur.next;
}
// 删除 cur 这个位置的结点
latter.next = cur.next;
// 返回虚拟头结点的下一个结点
return dummy.next;
}
}
10、BM10 两个链表的第一个公共结点
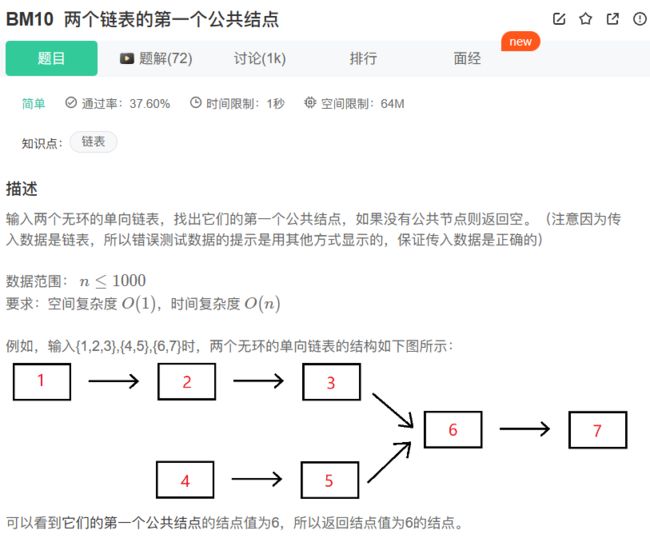
思路步骤:
我们准备两个指针分别从两个链表头同时出发,每次都往后一步,遇到末尾就连到另一个链表的头部,这样相当于每个指针都遍历了这个交叉链表的所有结点,那么它们相遇的地方一定是交叉的地方,即第一个公共结点。
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
// 边界判断
if (pHead1 == null || pHead2 == null) {
return null;
}
// 设置一个指针 pointA,指向链表 A 的头节点
ListNode pointA = pHead1;
// 设置一个指针 pointB,指向链表 B 的头节点
ListNode pointB = pHead2;
// 指针 pointA 和 指针 pointB 不断向后遍历,直到找到相交点
// 不用担心会跳不出这个循环,实际上在链表 headA 长度和链表 headB 长度的最小公倍数的情况下
// pointA 和 pointB 都会同时指向 null
// 比如 headA 的长度是 7,headB 的长度是 11,这两个链表不相交
// 那么 pointA 移动了 7 * 11 = 77 次之后,会指向 null
// pointB 移动了 7 * 11 = 77 次之后,也指向 null
// 这个时候就跳出了循环
while (pointA != pointB) {
// 指针 pointA 一开始在链表 A 上遍历,当走到链表 A 的尾部即 null 时,跳转到链表 B 上
if ( pointA == null) {
// 指针 pointA 跳转到链表 B 上
pointA = pHead2;
} else {
// 否则的话 pointA 不断的向后移动
pointA = pointA.next;
}
// 指针 pointB 一开始在链表 B 上遍历,当走到链表 B 的尾部即 null 时,跳转到链表 A 上
if ( pointB == null) {
// 指针 pointA 跳转到链表 B 上
pointB = pHead1;
} else {
// 否则的话 pointB 不断的向后移动
pointB = pointB.next;
}
}
// 1、此时,pointA 和 pointB 指向那个相交的节点,返回任意一个均可
// 2、此时,headA 和 headB 不想交,那么 pointA 和 pointB 均为 null,也返回任意一个均可
return pointA;
}
}
另一种写法:思路是一样的,更加简洁
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
//首先定义两个指针
ListNode first = pHead1;
ListNode second = pHead2;
//当两个指针不相遇的时候就一直遍历
while(first != second){
first = (first == null )? pHead2 : first.next;
second = (second == null)? pHead1 : second.next;
}
//返回任意一个
return first;
}
}
11、BM11 链表相加(二)
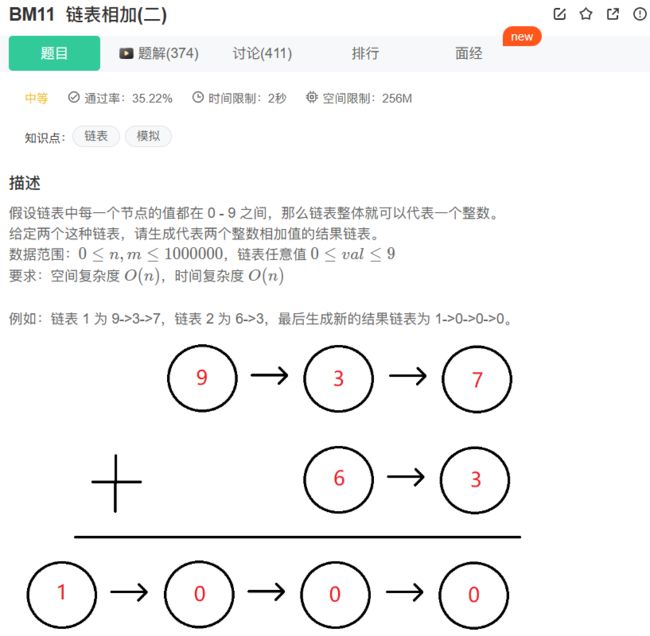
思路步骤:
既然链表每个节点表示数字的每一位,那相加的时候自然可以按照加法法则,从后往前依次相加。但是,链表是没有办法逆序访问的,这是我们要面对第一只拦路虎。解决它也很简单,既然从后往前不行,那从前往后总是可行的吧,将两个链表反转一 下,即可得到个十百千……各个数字从前往后的排列,相加结果也是个位在前,怎么办?再次反转,结果不就正常了。
具体做法:
- step 1:任意一个链表为空,返回另一个链表就行了,因为链表为空相当于0,0加任何数为0,包括另一个加数为0的情况。
- step 2:相继反转两个待相加的链表。
- step 3:设置返回链表的链表头,设置进位carry=0.
- step 4:从头开始遍历两个链表,直到两个链表节点都为空且carry也不为1. 每次取出不为空的链表节点值,为空就设置为0,将两个数字与carry相加,然后查看是否进位,将进位后的结果(对10取模)加入新的链表节点,连接在返回链表后面,并继续往后遍历。
- step 5:返回前将结果链表再反转回来。
public class Solution {
public ListNode addInList (ListNode head1, ListNode head2) {
//任意一个链表为空,直接返回另外一个
if (head1 == null)
return head2;
if (head2 == null)
return head1;
//反转两个链表
head1 = reverseList(head1);
head2 = reverseList(head2);
//添加一个表头
ListNode dummy = new ListNode(-1);
// head1 和 head2 有可能为空,所以先默认结果链表从虚拟头结点位置开始
ListNode cur = dummy;
//定义一个变量用来存放是否要进位
int carry = 0;
//只要某个链表还有或者进位还有
while (head1 != null || head2 != null || carry != 0) {
//链表不为空则取其值
int val1 = head1 == null ? 0 : head1.val;
int val2 = head2 == null ? 0 : head2.val;
//相加
int temp = val1 + val2 + carry;
//获取进位
carry = temp / 10;
//获取结果值
temp %= 10;
//添加元素
cur.next = new ListNode(temp);
//移动 cur 的位置,观察后面应该存放什么结点
cur = cur.next;
//链表中还有结点未遍历完毕就继续遍历下去
if (head1 != null) {
head1 = head1.next;
}
if (head2 != null) {
head2 = head2.next;
}
}
//结果反转回来
return reverseList(dummy.next);
}
//反转两个链表
public ListNode reverseList(ListNode head) {
//basecase
if (head == null) {
return null;
}
//定义两个节点
ListNode pre = null;
ListNode cur = head;
//反转链表
while (cur != null) {
//断开链表,要记录后续一个
ListNode temp = cur.next;
//当前的next指向前一个
cur.next = pre;
//前一个更新为当前
pre = cur;
//当前记录为刚刚记录的后一个
cur = temp;
}
return pre;
}
}
12、BM12 单链表的排序
思路步骤:
堆排序应该是最简单直观的,且时间复杂度和空间复杂度都符合题目要求。
注意点就是最后一个节点的next指针要设置为null,否则可能会出现环形链表的情况
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类 the head node
* @return ListNode类
*/
public ListNode sortInList (ListNode head) {
// 堆排序
PriorityQueue<ListNode> heap = new PriorityQueue<>((n1, n2) -> n1.val - n2.val);
while(head != null){
//将元素全部丢到堆里
heap.add(head);
//链表后移
head = head.next;
}
//定义一个虚拟头节点
ListNode dummy = new ListNode(-1);
ListNode cur = dummy;
//将堆里面的数据全部拿出来
while(!heap.isEmpty()){
cur.next = heap.poll();
cur = cur.next;
}
//最后一个节点的next指针要设置为null
cur.next = null;
return dummy.next;
}
}
13、BM13 判断一个链表是否为回文结构
思路步骤:
这题是让判断链表是否是回文链表,所谓的回文链表就是以链表中间为中心点两边对称。
我们常见的有判断一个字符串是否是回文字符串,这个比较简单
可以使用两个指针,一个最左边一个最右边,两个指针同时往中间靠,判断所指的字符是否相等。
但这题判断的是链表,因为这里是单向链表,只能从前往后访问,不能从后往前访问,所以使用判断字符串的那种方式是行不通的。
但我们可以通过找到链表的中间节点然后把链表后半部分反转,最后再用后半部分反转的链表和前半部分一个个比较即可。
画图演示:

public class Solution {
public boolean isPail (ListNode head) {
//快慢指针
//首先定义两个指针
ListNode fast = head;
ListNode slow = head;
//接着走,直到快指针为null,并且快指针的下一个为null
while(fast != null && fast.next != null){
//快指针走两步,满指针走一步
fast = fast.next.next;
slow = slow.next;
}
//链表是奇数的情况下,将慢指针再往后走一步
if(fast != null){
slow = slow.next;
}
//然后反转慢指针所在的往后的链表
slow = reverseList(slow);
//将快指针指向头节点
fast = head;
//将快指针和慢指针对应的值进行比较
while(slow != null){
//若是值不相等,返回false
if(fast.val != slow.val){
return false;
}
//快慢指针各走一步
fast = fast.next;
slow = slow.next;
}
//返回true
return true;
}
//反转链表
private ListNode reverseList(ListNode head){
//要是这个链表为空,直接返回这个链表
if(head == null){
return head;
}
//然后定义两个指针开始反转
ListNode pre = null;
ListNode cur = head;
while(cur != null){
ListNode temp = cur.next;
cur.next = pre;
pre = cur;
cur = temp;
}
//返回pre
return pre;
}
}
14、BM14 链表的奇偶重排
思路步骤:
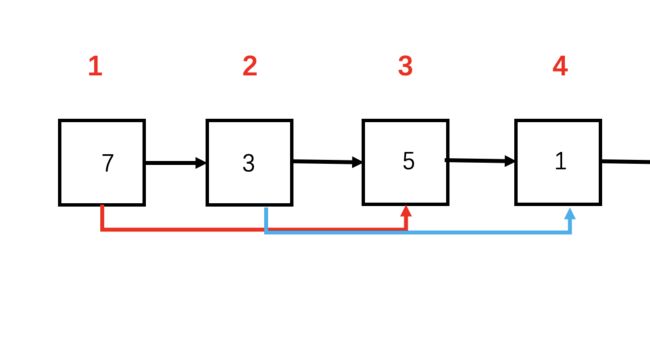
如下图所示,第一个节点是奇数位,第二个节点是偶数,第二个节点后又是奇数位,因此可以断掉节点1和节点2之间的连接,指向节点2的后面即节点3,如红色箭头。如果此时我们将第一个节点指向第三个节点,就可以得到那么第三个节点后为偶数节点,因此我们又可以断掉节点2到节点3之间的连接,指向节点3后一个节点即节点4,如蓝色箭头。那么我们再将第二个节点指向第四个节点,又回到刚刚到情况了。
//odd连接even的后一个,即奇数位
odd.next = even.next;
//odd进入后一个奇数位
odd = odd.next;
//even连接后一个奇数的后一位,即偶数位
even.next = odd.next;
//even进入后一个偶数位
even = even.next;
这样我们就可以使用了两个同方向访问指针遍历解决这道题。
具体做法:
- step 1:判断空链表的情况,如果链表为空,不用重排。
- step 2:使用双指针odd和even分别遍历奇数节点和偶数节点,并给偶数节点链表一个头。
- step 3:上述过程,每次遍历两个节点,且even在后面,因此每轮循环用even检查后两个元素是否为NULL,如果不为再进入循环进行上述连接过程。
- step 4:将偶数节点头接在奇数最后一个节点后,再返回头部。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode oddEvenList (ListNode head) {
// 判断空链表的情况,如果链表为空,直接返回
if(head == null){
return head;
}
//使用双指针odd和even分别遍历奇数节点和偶数节点
//首次定义两个指针
ListNode odd = head;
ListNode even = head.next;
//给偶数节点链表一个头
ListNode evenhead = even;
// 从偶数链表的头结点开始向后遍历
// 如果当前结点为空,或者后一结点为空,那么说明整个链表已经查看完毕,不需要再遍历了
while(even != null && even.next != null){
//odd连接even的后一个,即奇数位
odd.next = even.next;
//odd向后走一位
odd = odd.next;
//even连接odd的后一个,即偶数位
even.next = odd.next;
//even向后走一位
even = even.next;
}
//even整体接在odd后面
odd.next = evenhead;
return head;
}
}
15、BM15 删除有序链表中重复的元素-I
思路步骤:
既然连续相同的元素只留下一个,我们留下哪一个最好呢?当然是遇到的第一个元素了!
if(cur.val == cur.next.val)
cur.next = cur.next.next;
因为第一个元素直接就与前面的链表节点连接好了,前面就不用管了,只需要跳过后面重复的元素,连接第一个不重复的元素就可以了,在链表中连接后面的元素总比连接前面的元素更方便嘛,因为不能逆序访问。
具体做法:
- step 1:判断链表是否为空链表,空链表不处理直接返回。
- step 2:使用一个指针遍历链表,如果指针当前节点与下一个节点的值相同,我们就跳过下一个节点,当前节点直接连接下个节点的后一位。
- step 3:如果当前节点与下一个节点值不同,继续往后遍历。
- step 4:循环过程中每次用到了两个节点值,要检查连续两个节点是否为空。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode deleteDuplicates (ListNode head) {
// write code here
/**
* 当发现有相同的结点则删除,cur.next = cur.next.next
* 其他情况下,继续循环:cur = cur.next
*/
//basecase
if(head == null){
return null;
}
//遍历的指针
ListNode cur = head;
//遍历链表
while(cur != null && cur.next != null){
if(cur.next != null && cur.val == cur.next.val){
//跳过那个节点
cur.next = cur.next.next;
}else{
//否则指针正常遍历
cur = cur.next;
}
}
return head;
}
}
16、BM16 删除有序链表中重复的元素-II
题目描述:
- 在一个非降序的链表中,存在重复的节点,删除该链表中重复的节点
- 重复的节点一个元素也不保留
思路步骤:
这是一个升序链表,重复的节点都连在一起,我们就可以很轻易地比较到重复的节点,然后将所有的连续相同的节点都跳过,连接不相同的第一个节点。
//遇到相邻两个节点值相同
if(cur.next.val == cur.next.next.val){
int temp = cur.next.val;
//将所有相同的都跳过
while (cur.next != null && cur.next.val == temp)
cur.next = cur.next.next;
}
具体做法:
- step 1:给链表前加上表头,方便可能的话删除第一个节点。
ListNode res = new ListNode(0);
//在链表前加一个表头
res.next = head;
- step 2:遍历链表,每次比较相邻两个节点,如果遇到了两个相邻节点相同,则新开内循环将这一段所有的相同都遍历过去。
- step 3:在step 2中这一连串相同的节点前的节点直接连上后续第一个不相同值的节点。
- step 4:返回时去掉添加的表头。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode deleteDuplicates (ListNode head) {
// write code here
//空链表
if(head == null){
return null;
}
ListNode res = new ListNode(0);
//在链表前加一个表头
res.next = head;
ListNode cur = res;
//开始遍历
while(cur.next != null && cur.next.next != null){
//遇到相邻两个节点值相同
if(cur.next.val == cur.next.next.val){
//将cur.next.val存到一个临时变量
int temp = cur.next.val;
//将所有相同的都跳过
while(cur.next != null && cur.next.val == temp){
cur.next = cur.next.next;
}
}else{
//指针往后
cur = cur.next;
}
}
//返回时去掉表头
return res.next;
}
}