【DL】使用pytorch从零实现线性回归
1.线性回归简介
此内容主要依据李沐老师的《动手学深度学习》课程,同时结合了网络上其它资料和自己的理解。
线性回归沐神的b站视频课程链接:https://www.bilibili.com/video/BV1PX4y1g7KC
电子书链接:https://zh-v2.d2l.ai/chapter_linear-networks/linear-regression.html
1.1 线性回归
回归通常用来表示输入和输出之间的关系,在机器学习领域中可以用其来解决预测问题,例如预测房价等。线性回归是回归的一种,它基于几个简单的假设:
- 自变量 x 和因变量 y 之间的关系是线性的;
- 允许添加正常的噪声,例如遵循正态分布的噪声等。
我们举一个实际的例子: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。 在机器学习的术语中,该数据集称为 训练数据集 (training data set) 或 训练集 (training set)。 每行数据(比如一次房屋交易相对应的数据)称为 样本 (sample), 也可以称为 数据点 (data point)或 数据样本 (data instance)。 我们把试图预测的目标(比如预测房屋价格)称为 标签 (label)或 目标 (target)。 预测所依据的自变量(面积和房龄)称为 特征 (feature)或 协变量 (covariate)。
1.2 梯度下降
粗略地讲,在最开始我们会设置一个随机的权重 w0,它对应着函数的一组解。因为我们需要获取函数的最优解,就需要让梯度往最优解方向走,而梯度本身是使函数值上升最快的方向,我们就需要往负梯度方向走,即梯度下降:

这里我们引入了**学习率 ŋ**(步长的超参数,不能太小也不能太大),它指我们的 w0 沿着负梯度方向每次走多远。如下面公式所示,最右边的项对应着上图中的一个向量,即学习率与**损失函数 l 在上一权重处的梯度**相乘:
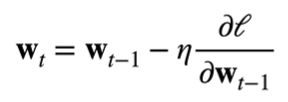
我们用上一个权重减去这个向量,就得到了新的权重。反复进行如上迭代,每次迭代都沿着损失函数下降最快的方向,损失函数值越来越小,从而逼近真实值。
1.3 小批量随机梯度下降
在实际中,由于在整个训练集上算梯度太耗费资源与时间,我们通常使用小批量(mini-batch) 随机梯度下降的方法。我们随机采样 b 个样本,求出此批量的损失值再求平均,从而近似损失。
2. 实战
此代码源于李沐老师的《动手学深度学习》课程
本小节b站视频课程链接:https://www.bilibili.com/video/BV1PX4y1g7KC
电子书链接:https://zh-v2.d2l.ai/chapter_linear-networks/linear-regression.html
本人运行环境:ubuntu22.04 + Conda + Python310 + jupyter + pytorch
依赖:
%matplotlib inline
import random
import torch
from d2l import torch as d2l
2.1 数据集创建
综上,在进行预测前,我们需要创建一个数据集,代码如下:
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
# 人为设置 w 和 b 的真实值
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
其中,w 代表模型的权重(这里是列向量),b 代表偏置(这里是标量),在真实情况中,w 和 b 是未知的。由于在机器学习中通常使用高维数据集,因此通常使用向量或张量来构造。预测值 y 表示如下:
y = X w + b + ɛ y = Xw + b + ɛ y=Xw+b+ɛ
-
X 生成为 均值=0、标准差=1、num_examples行、len(w)列的随机张量
-
y 按上述线性回归公式计算,并将其变为列向量返回。
此处b是个一维向量,当 matmul 的第一个参数是2维向量,第2个参数是一维向量时,返回的是矩阵和向量的乘积,结果是向量(来自b站弹幕)。因此,y需要reshape为列向量,其中 -1 代表自动计算。
-
我们设置线性模型参数为 w = [2, -3.4]T, b = 4.2,将结果保存为 features 和 labels
注意,
features中的每一行都包含一个二维数据样本,labels中的每一行都包含一维标签值(一个标量)。
通过生成features和labels的散点图, 可以直观观察到两者之间的线性关系:
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);

2.2 读取数据集
通常在机器学习中,训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。
为了模仿上述目的,在下面的代码中,我们定义一个data_iter函数, 用来打乱数据集中的样本并以小批量方式获取数据。该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
# 生成索引列表
indices = list(range(num_examples))
# 打乱索引列表
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
注:带 yield 关键字的函数是一个生成器,它类似于 return,在程序执行到 yield 时return 出生成的数,再此进入迭代时,从上一步停止的地方,即 yield 后开始。
我们设置小批量为10(不能太小或太大),然后开始迭代生成小批量处理后的 X、y。由于数据较多,这里我们只打印一次:
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
结果为:
tensor([[ 0.3145, 0.1654],
[ 2.0859, -1.2568],
[ 0.3655, 1.1703],
[ 0.8599, -0.6612],
[ 0.3118, -0.4277],
[ 1.3142, 0.3179],
[ 0.2688, -0.6435],
[-1.5495, 0.4066],
[-0.3208, -0.5531],
[-1.7611, 0.4214]])
tensor([[ 4.2507],
[12.6318],
[ 0.9561],
[ 8.1628],
[ 6.2739],
[ 5.7383],
[ 6.9305],
[-0.2778],
[ 5.4270],
[-0.7713]])
这就是我们第一个批量的数据。
2.3 初始化模型
首先初始化模型的参数:
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
lr = 0.03
num_epochs = 3
我们初始化权重为 均值=0、标准差=0.01、2行1列的随机二维列向量,因为我们需要计算梯度,所以requires_grad=True。
偏置直接设置为标量0,学习率为 0.03,设置迭代周期为3,即进行三轮训练。
之后,创建线性回归模型:
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
2.4 定义损失函数
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape))**2 / 2
关于均方损失(Mean Squared Error, MSE):
均方差损失函数是预测数据和原始数据对应点误差的平方和的均值,公式为:
N为样本个数。
引自:https://blog.csdn.net/qq_40210586/article/details/115470696

在实现中,我们需要将真实值y的形状转换为和预测值y_hat的形状相同
2.5 小批量随机梯度下降
定义优化算法,实现小批量随机梯度下降更新。 该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率lr决定。 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad(): # 不计算梯度
for param in params: # 更新参数
param -= lr * param.grad / batch_size
param.grad.zero_() # 将梯度设置为0,防止与下一个梯度相关
注:
由于 sgd 函数中传递的参数是由 w 和 b 构成的多维列表,所以传递时 param 得到的是列表中元素的引用,因此在函数内部更改 param ,在外部 w 和 b 也发生变更。
同时要注意,在更新参数时,使用了 -= 运算符,会执行原地操作(in-place operation),也就是运算结果会赋给同一块内存。如果修改为 param = param - …形式,测试代码如下:
for param in params: print(type(param), 'id:', id(param)) param -= lr * param.grad / batch_size print(type(param), 'id:', id(param)) param = param - lr * param.grad / batch_size print(type(param), 'id:', id(param))结果如下:
<class 'torch.Tensor'> id: 140296289112448 <class 'torch.Tensor'> id: 140296289112448 <class 'torch.Tensor'> id: 140295014093344可以看出,param 被存储在了一个新的内存空间中,从而无法改变全局变量的值。
在每个迭代周期中,我们使用data_iter函数遍历整个数据集,从中取出小批量数据 X、y,将 X 放入线性回归模型中计算出预测值,然后将预测值和真实值放入损失函数中,求出小批量损失。
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
# 更新参数
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # 计算 X 和 y 的小批量损失
l.sum().backward()
sgd([w, b], lr, batch_size) # 更新梯度
# 测试使用更新后的w和b得到的损失
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
结果为:
epoch 1, loss 0.037120
epoch 2, loss 0.000136
epoch 3, loss 0.000048
关于
backward()方法:即反向传播函数,用于反向求导,例如,在上述代码中执行
l.sum().backward()后,再执行w.grad即可获得损失函数对 w 的导数,即梯度。