联邦学习中一种低成本的从攻击中恢复的办法——FedRecover: Recovering from Poisoning Attacks 的背景与相关工作、问题定义、FEDRECOVER、评估 研读报告
目录
-
- II.背景与相关工作
-
- A. 联邦学习(FL)背景
- B. 联邦学习中的投毒攻击
- C. 检测恶意客户端
- D.机器遗忘
- III.问题定义
-
- A. 威胁模型
- B. 设计目标
- C. 服务器要求
- IV. FEDRECOVER
-
- A. 概述
- B. 估计客户端的模型更新
-
- 运用L-BFGS算法近似集成的Hessian矩阵
- D. 完整算法
- Algorithm 1: FedRecover
- FEDRECOVER详解
- 预热阶段的解释
- 后预热的更新阶段
- 最终调整阶段
- 返回最终的恢复模型
- Algorithm 2: L-BFGS
- Algorithm 3: ExactTraining
- E. Theoretical Analysis
-
- 计算和通信成本对客户端的影响:
- 通过FedRecover和从零开始训练恢复的全球模型之间的差异的边界:
- 假设1
- 假设2
- 定理1
- 推论1
- 准确性与成本之间的权衡
- V. 评估
-
- A. 实验设置
- B. 实验结果
- VI. 讨论与局限性
-
- A. 存储历史信息的安全/隐私关注
- B. 客户端退出
- C. 服务器的存储和计算成本
- VII. 结论与未来工作
II.背景与相关工作
A. 联邦学习(FL)背景
联邦学习系统构成:
- 存在 n n n 个客户端,每个客户端都有其本地训练数据集 D i D_i Di。
- 使用 D D D 来表示所有客户端的本地训练数据集的并集: D = ⋃ i = 1 n D i D = \bigcup_{i=1}^{n} D_i D=⋃i=1nDi。
共同目标:
- 客户端的目标是基于整体训练数据集合作训练一个共享的机器学习模型,称为全局模型。
损失函数:
- 客户端共同优化一个损失函数,表示为:
min w L ( D ; w ) = min w ∑ i = 1 n L ( D i ; w ) \min_w L(D; w) = \min_w \sum_{i=1}^{n} L(D_i; w) wminL(D;w)=wmini=1∑nL(Di;w)
其中 w w w 为全局模型参数,并且简化表示为 L i ( w ) = L ( D i ; w ) L_i(w) = L(D_i; w) Li(w)=L(Di;w)。
服务器的角色:
- 由服务提供商(例如Google、Facebook、Apple)提供的服务器维护全局模型。
联邦学习的过程:
- 步骤 I: 服务器向所有客户端广播当前的全局模型 w t w_t wt。
- 步骤 II: 每个客户端基于接收到的全局模型和其本地训练数据使用梯度下降计算模型更新 g t i g^i_{t} gti,然后将其报告给服务器。
- 步骤 III: 服务器根据某个汇总规则
A聚合客户端的模型更新。
B. 联邦学习中的投毒攻击
-
联邦学习的脆弱性:
- 联邦学习容易受到投毒攻击,恶意客户端通过在FL的第二步发送恶意模型更新来污染全局模型。
-
恶意客户端的操作:
- 它们可以通过污染其本地训练数据和/或直接操纵模型更新来构建恶意模型更新。
-
投毒攻击的分类:
- 非针对性投毒攻击: 污染的全局模型对于大量的测试输入都有较高的测试错误率。
- 针对性投毒攻击: 污染的全局模型对攻击者选择的测试输入预测一个攻击者选择的目标标签,但对其他测试输入的测试错误率不受影响。
- 例如: 后门攻击是一种流行的针对性投毒攻击,其中攻击者选择的测试输入是嵌入触发器的任何输入。
-
主要攻击方法的简介:
- Trim攻击: Fang等人提出了一个非针对性的投毒攻击框架,该框架旨在制定能够最大化攻击前后聚合模型更新之间差异的恶意模型更新。该攻击方法是基于Trimmed-mean汇总规则构建的,但也适用于其他汇总规则,如FedAvg和Median。
- 后门攻击: 在后门攻击中,攻击者通过增加带有触发器的重复项来污染恶意客户端的本地训练数据。为了增加模型更新的影响,恶意客户端在向服务器报告之前将它们放大。例子:想象一个图像分类系统。攻击者可以将一个不起眼的标记(如一个小红点)添加到某些训练图片上,并为这些图片分配一个特定的、可能是错误的标签。在正常使用中,这个小红点可能不会出现,所以模型的行为看起来是正常的。但是,当输入图像中包含这个小红点时,模型可能会错误地将其分类为攻击者指定的那个特定标签,即使这个标签在其他方面都与图像的实际内容不符。
-
存在的缺陷与问题:
- 虽然已有一些方法试图检测和移除神经网络中的后门,但它们对于联邦学习来说是不够的。例如,某些方法假设有一个干净的训练数据集,但对于FL服务器来说这通常是不成立的。
C. 检测恶意客户端
-
目的与基本问题:
- 恶意客户端检测的目的是区分恶意客户端和良性客户端,这实质上是一个二分类问题。
-
关键思想:
- 主要思想是利用恶意客户端和良性客户端的特征(例如,模型更新)之间的某些统计差异。
-
检测方法:
- 不同的检测方法使用不同的特征和二元分类器进行检测。
- 对于每个客户端,这些检测方法首先从其在一个或多个轮次中的模型更新中提取特征,然后使用分类器预测它是否是恶意的。
-
具体实例:
- Zhang等人提出通过检查客户端的模型更新一致性来检测恶意客户端。具体来说,服务器根据每一轮中的历史模型更新来预测客户端的模型更新。如果在多轮中收到的模型更新与预测的不一致,那么服务器将该客户端标记为恶意。
- Zhang等人还利用了Cauchy均值定理和L-BFGS算法来预测客户端的模型更新,但他们为所有客户端使用了相同的近似Hessian矩阵,这在模型恢复中被实验证明是无效的。
-
与Sybil检测的关系:
- 检测恶意客户端也与分布式系统中的Sybil检测有关。
- 传统的Sybil检测方法也可以用来检测恶意客户端,其中恶意客户端被视为Sybil。特别是,这些Sybil检测方法利用客户端的IP、网络行为和(如果可用的话)社交图表。
D.机器遗忘
-
定义:机器遗忘旨在使机器学习模型“忘记”某些训练样本。例如,由于隐私问题,用户可能希望模型忘记其数据。
-
方法:
- Cao等人的方法 :提议将用于训练机器学习模型的学习算法转化为求和形式,从而只需要更新少量的求和来遗忘一个训练样本。
- Bourtoule等人的方法:将模型训练分解为多个组成模型的聚合,每个训练样本只对一个组成模型作出贡献。因此,只需要重新训练一个组成模型来遗忘一个训练样本。
- Wu等人的DeltaGrad方法 :使用要遗忘的训练样本的梯度来估计剩余训练样本上的损失函数的梯度。
-
与FL中的投毒攻击恢复的关系:模型从FL中的投毒攻击中恢复可以被视为遗忘检测到的恶意客户,即使全局模型忘记了从检测到的恶意客户那里得到的模型更新。
-
现有遗忘方法的局限性:现有的机器遗忘方法对FL来说是不足够的,因为:
- 它们需要更改FL算法来训练多个组成模型,并且当多个组成模型涉及检测到的恶意客户并因此需要重新训练时,它们是低效的。
- 它们需要访问客户的私有本地训练数据。
III.问题定义
A. 威胁模型
-
攻击者的目标:
- 非针对性投毒攻击:攻击者希望增加全局模型对大量测试输入的测试错误率。
- 针对性投毒攻击:攻击者的目的是使全局模型对攻击者选择的目标测试输入预测出攻击者选择的目标标签,但其他测试输入的预测不受影响。
- 后门攻击:这是针对性投毒攻击的一个子类,目标测试输入包括任何嵌入攻击者选择的触发器的输入,例如特定的特征模式。
-
攻击者的能力:
- 假设攻击者控制了一些恶意客户端,但没有侵入服务器。
- 恶意客户端可能是攻击者注入到FL系统中的伪造客户端,或是被攻击者妥协的FL系统中的真实客户端。
- 恶意客户端可以向服务器发送任意模型更新。
-
攻击者的背景知识:
- 部分知识设置:攻击者知道全局模型、损失函数、恶意客户端上的本地训练数据和模型更新。
- 完全知识设置:除了部分知识设置中的内容外,攻击者还知道所有客户端上的本地训练数据、模型更新以及服务器的汇聚规则。在完全知识设置中,投毒攻击往往比在部分知识设置中更强大。
- 本文考虑的是完全知识设置中的强投毒攻击。
B. 设计目标
-
目的:我们的目标是为FL设计一个准确且高效的模型恢复方法。我们使用从零开始训练作为衡量恢复方法准确性和效率的基准。
-
准确性:
- 对于非针对性的投毒攻击,恢复的全局模型的测试错误率应接近从零开始训练恢复的全局模型的测试错误率。
- 对于针对性的投毒攻击,我们的方法恢复的全局模型的攻击成功率应该和从零开始训练恢复的全局模型的攻击成功率一样低。
-
效率:
- 我们的恢复方法应该降低客户端的计算和通信成本。
- 由于客户端通常是资源有限的设备,所以我们关注客户端的效率。
- 模型恢复会在每轮询问客户端计算其确切的模型更新时给客户端带来通信和计算的成本。
- 因此,我们通过要求客户端在多少轮中计算其确切的模型更新来衡量恢复方法的效率。我们的目标是设计一个高效的恢复方法,只在少数轮次中要求客户端计算它们的确切模型更新。
-
独立于检测方法:
- 已经提出了不同的检测方法来检测恶意客户端。
- 我们的目标是设计一个与任何检测方法都兼容的通用恢复方法。
- 所有检测方法都预测恶意客户端的列表,而我们的恢复方法应该能够使用这个列表恢复一个全局模型,而不需要关于检测过程的任何其他信息。
- 在实践中,检测器可能会错过一些恶意客户端或错误地将一些良性客户端检测为恶意的。即使检测器的假阴性率和假阳性率不为零,我们的恢复方法仍然应该和从零开始训练一样准确,而且效率更高。
-
独立于汇聚规则:
- FL中提出了各种汇聚规则,而中毒的全局模型可能使用不同的汇聚规则进行训练。
- 我们的目标是设计一个与任何汇聚规则都兼容的通用恢复方法。
- 我们的恢复方法不应该依赖于FL的汇聚规则。
C. 服务器要求
- 我们假设服务器有存储容量来保存在恶意客户端被检测到之前训练中毒的全局模型时收集的全局模型和客户端的模型更新。
- 我们还假设服务器有计算能力在恢复期间估计客户端的模型更新。
- 这些要求是合理的,因为服务器(例如数据中心)通常很强大。
IV. FEDRECOVER
A. 概述
-
在检测到的恶意客户端被移除后,FedRecover初始化一个新的全局模型,并在多个轮次中迭代训练它。
-
在每一轮,FedRecover在服务器上模拟我们在第II-A节中讨论的FL的三个步骤。
-
服务器不再要求剩余的客户端计算和通信模型更新,而是使用存储的历史信息(包括原始的全局模型和原始的模型更新)来估计模型更新。
-
多轮中的客户端模型更新的估计误差可能会累积,最终导致一个不准确的恢复的全局模型。
-
为了优化FedRecover,我们进一步提出了几种策略,包括预热、定期修正、异常修复和最终调整。
- 在这些策略中,服务器要求客户端在恢复过程的前几轮、每隔一定数量的轮次、当估计的模型更新是异常的,以及在最后几轮中分别计算他们的确切模型更新,而不是估计它们。
-
理论上,我们可以在一些假设下限制FedRecover恢复的全局模型和从零开始训练恢复的全局模型之间的差异;我们展示了,随着FedRecover增加客户端的计算/通信成本,这种差异呈指数级下降。
B. 估计客户端的模型更新
-
符号定义:我们首先定义一些有助于描述我们方法的符号(附录表I中给出)。在原始训练中(即检测到恶意客户端之前)服务器收集的全局模型和客户端的模型更新被称为原始全局模型和原始模型更新。
-
使用 w ˉ t \bar{w}_t wˉt表示原始的全局模型,使用 g ˉ i t \bar{g}_{i_t} gˉit表示在第t轮由第i个客户端报告的原始模型更新。
-
使用 w ^ t \hat{w}_t w^t表示FedRecover在第t轮的恢复的全局模型。
-
如果客户端计算它,使用 g i t g_{i_t} git表示在恢复过程的第t轮的第i个客户端的确切模型更新。
-
-
模型更新的计算:基于Cauchy均值定理的积分版本,我们可以如下计算确切的模型更新 g i t g_{i_t} git:
-
g i t = g ˉ i t + H i t ( w ^ t − w ˉ t ) g_{i_t} = \bar{g}_{i_t} + H_{i_t}(\hat{w}_t - \bar{w}_t) git=gˉit+Hit(w^t−wˉt)
-
其中 H i t H_{i_t} Hit是第t轮第i个客户端的一个集成的Hessian矩阵。直观地说,梯度g是模型参数w的函数。
-
函数值 g i t − g ˉ i t g_{i_t} - \bar{g}_{i_t} git−gˉit之间的差异可以通过变量 w ^ t − w ˉ t \hat{w}_t - \bar{w}_t w^t−wˉt之间的差异和函数g沿线的集成梯度,即 H i t H_{i_t} Hit来描述。
-
-
计算问题:上述方程涉及一个集成的Hessian矩阵,这是具有挑战性的。为了解决这一挑战,我们使用高效的L-BFGS算法来计算一个近似的Hessian矩阵。
运用L-BFGS算法近似集成的Hessian矩阵
-
L-BFGS算法:在优化中,L-BFGS算法是一个流行的工具,用于近似Hessian矩阵或其逆。该算法需要过去轮次中的全局模型差异和模型更新差异来在当前轮次进行近似。
-
定义的差异:
-
在第t轮的全局模型差异定义为: Δ w t = w ^ t − w ˉ t \Delta w_t = \hat{w}_t - \bar{w}_t Δwt=w^t−wˉt。
-
第t轮第i个客户端的模型更新差异定义为: Δ g i t = g i t − g ˉ i t \Delta g_{i_t} = g_{i_t} - \bar{g}_{i_t} Δgit=git−gˉit。
-
全局模型差异衡量了某一轮中恢复的全局模型与原始全局模型之间的差异,而模型更新差异则衡量了某一轮中客户端的确切模型更新与原始模型更新之间的差异。
-
-
L-BFGS的缓冲区:L-BFGS算法维护一个在第t轮的全局模型差异的缓冲区 Δ W t \Delta W_t ΔWt,以及每个客户端的模型更新差异的缓冲区 Δ G i t \Delta G_{i_t} ΔGit。
-
Hessian矩阵的尺寸问题:Hessian矩阵的尺寸是全局模型参数数量的平方,因此当全局模型为深度神经网络时,Hessian矩阵可能过大以至于无法存储在内存中。
-
Hessian-向量乘积:在实践中,通常需要Hessian矩阵和一个向量v的乘积,这被称为Hessian-向量乘积。例如,在FedRecover中,我们的目标是找到 H i t v H_{i_t}v Hitv,其中 v = w ^ t − w ˉ t v = \hat{w}_t - \bar{w}_t v=w^t−wˉt。因此,现代的L-BFGS算法实现接受向量v作为一个额外的输入,并直接以有效的方式近似Hessian-向量乘积。
-
L-BFGS的挑战:标准的L-BFGS算法面临一个关键的挑战,它需要在每一轮都有确切的模型更新 g i t g_{i_t} git以计算模型更新差异的缓冲区,但我们的目标是避免在大多数轮次中询问客户端来计算它们的确切模型更新。接下来,我们提出了几种优化策略来应对这个挑战。
D. 完整算法
-
算法概述:
- 附录中的算法1显示了我们的FedRecover的完整算法。
- 不失一般性地,我们假设前 m m m个客户端是恶意的。
-
预热阶段:
- 在前 T w Tw Tw轮预热阶段,服务器按照II-A节讨论的FL框架的三个步骤来更新恢复的全局模型。
-
预热后的更新:
- 在预热后的每一轮 t t t中,如果服务器在前一轮 t − 1 t-1 t−1要求客户端计算确切的模型更新,服务器首先更新L-BFGS算法的缓冲区,如IV-C节所讨论。
- 然后,服务器使用周期性修正或估计的模型更新来更新恢复的全局模型。
- 如果估计的模型更新中至少有一个坐标大于异常阈值 τ \tau τ,则要求客户端计算确切的模型更新。
-
训练结束前的最后调整:
- 在服务器终止训练过程之前,它要求客户端为最终调整计算确切的模型更新。
Algorithm 1: FedRecover
输入:
- n − m n - m n−m 剩余的要被恢复的客户端 C r = { C i ∣ m + 1 ≤ i ≤ n } C_r = \{C_i | m + 1 \leq i \leq n\} Cr={Ci∣m+1≤i≤n}
- 原始的全局模型 w ˉ 0 , w ˉ 1 , … , w ˉ T \bar{w}_0, \bar{w}_1, \dots, \bar{w}_T wˉ0,wˉ1,…,wˉT 以及原始的模型更新 g ˉ 0 i , g ˉ 1 i , … , g ˉ T − 1 i \bar{g}^{i}_0, \bar{g}^{i}_1, \dots, \bar{g}^{i}_{T-1} gˉ0i,gˉ1i,…,gˉT−1i ( m + 1 ≤ i ≤ n ) (m+1 \leq i \leq n) (m+1≤i≤n)
- 学习率 η \eta η
- 预热轮数 T w T_w Tw
- 周期性修正参数 T c T_c Tc
- 最终调整的轮数 T f T_f Tf
- L-BFGS算法的缓冲区大小 s s s
- 异常阈值 τ \tau τ
- 聚合规则 A A A
输出:
- 恢复的全局模型 w ^ T \hat{w}_T w^T
算法过程:
- w ^ 0 ← w ˉ 0 \hat{w}_0 \leftarrow \bar{w}_0 w^0←wˉ0 // 初始化恢复的全局模型
- 对于 t = 0 , 1 , … , T w − 1 t = 0, 1, \dots, Tw - 1 t=0,1,…,Tw−1 // 预热
- w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
- 对于 t = T w , T w + 1 , … , T − T f − 1 t = Tw, Tw + 1, \dots, T - T_f - 1 t=Tw,Tw+1,…,T−Tf−1
- 如有必要,更新缓冲区 Δ W t \Delta W_t ΔWt 和 Δ G t i \Delta G^i_t ΔGti
- 如果 ( t − T w + 1 ) m o d T c = = 0 (t-Tw+1) \mod Tc == 0 (t−Tw+1)modTc==0 // 周期性修正
- w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
- 否则
- 对于 i = m + 1 , m + 2 , … , n i = m + 1, m + 2, \dots, n i=m+1,m+2,…,n
- H ~ t i ( w ^ t − w ˉ t ) ← \tilde{H}^i_t(\hat{w}_t - \bar{w}_t) \leftarrow H~ti(w^t−wˉt)← L-BFGS( Δ W t , Δ G t i , w ^ t − w ˉ t \Delta W_t, \Delta G^i_t, \hat{w}_t - \bar{w}_t ΔWt,ΔGti,w^t−wˉt)
- g ^ t i = g ˉ t i + H ~ t i ( w ^ t − w ˉ t ) \hat{g}^i_t = \bar{g}^i_t + \tilde{H}^i_t(\hat{w}_t - \bar{w}_t) g^ti=gˉti+H~ti(w^t−wˉt)
- 如果 ∥ g ^ t i ∥ ∞ > τ \|\hat{g}^i_t\|_\infty > \tau ∥g^ti∥∞>τ // 异常修复
- 服务器将 w ^ t \hat{w}_t w^t 发送给第i个客户端
- 第i个客户端计算 g t i = ∂ L i ( w ^ t ) ∂ w ^ t g^i_t = \frac{\partial L_i(\hat{w}_t)}{\partial \hat{w}_t} gti=∂w^t∂Li(w^t)
- 第i个客户端向服务器报告 g t i g^i_t gti
- g ^ t i ← g t i \hat{g}^i_t \leftarrow g^i_t g^ti←gti
- w ^ t + 1 ← w ^ t − η ⋅ A ( g ^ t m + 1 , g ^ t m + 2 , … , g ^ t n ) \hat{w}_{t+1} \leftarrow \hat{w}_t - \eta \cdot A(\hat{g}^{m+1}_t, \hat{g}^{m+2}_t, \dots, \hat{g}^n_t) w^t+1←w^t−η⋅A(g^tm+1,g^tm+2,…,g^tn)
- 对于 i = m + 1 , m + 2 , … , n i = m + 1, m + 2, \dots, n i=m+1,m+2,…,n
- 对于 t = T − T f , T − T f + 1 , … , T − 1 t = T - T_f, T - T_f + 1, \dots, T - 1 t=T−Tf,T−Tf+1,…,T−1 // 最终调整
- w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
- 返回 w ^ T \hat{w}_T w^T
FEDRECOVER详解
预热阶段的解释
2. 对于 t = 0 , 1 , … , T w − 1 t = 0, 1, \dots, Tw - 1 t=0,1,…,Tw−1 // 预热
这一行启动了一个循环,持续 $Tw$ 轮的预热阶段。预热阶段是算法开始之前的一个步骤,旨在为后续的计算提供一个良好的起点。
2.1. w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
这一行表示,在每一轮的预热中,服务器将使用所有诚实客户端(由 $Cr$ 表示)提供的模型更新来进行精确的训练。此处的“精确的训练”意味着服务器将完全依赖于从诚实客户端接收到的模型更新,而不会进行任何近似或猜测。
- w ^ t \hat{w}_t w^t: 当前轮次 t t t的恢复的全局模型。
- C r Cr Cr: 所有诚实客户端的集合。
- η \eta η: 学习率,控制每次模型更新的步长。
- A A A: 聚合规则,定义了如何将来自多个客户端的模型更新聚合在一起。
预热阶段确保算法从一个合适的起始点开始,从而在后续步骤中提高模型恢复的效率和准确性。
后预热的更新阶段
3. 对于 t = T w , T w + 1 , … , T − T f − 1 t = Tw, Tw + 1, \dots, T - T_f - 1 t=Tw,Tw+1,…,T−Tf−1
这是算法的主体部分,在预热阶段之后,开始对模型进行后预热的更新。这个循环从预热结束时的轮次开始,一直到训练结束前的最后几轮。
3.1. 如有必要,更新缓冲区 Δ W t \Delta W_t ΔWt 和 Δ G t i \Delta G^i_t ΔGti
根据上下文可能的变化或数据的新信息,可能需要更新L-BFGS算法的缓冲区。
3.2. 如果 ( t − T w + 1 ) m o d T c = = 0 (t-Tw+1) \mod Tc == 0 (t−Tw+1)modTc==0 // 周期性修正
这一步检查当前的轮次是否是预定的周期性修正的轮次。如果是,就进行精确的训练。
- 3.2.1. w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
在这个步骤中,进行精确的模型训练,不进行任何近似或估计。
3.3. 否则
如果不是周期性修正的轮次,执行以下步骤:
- 3.3.1. 对于 i = m + 1 , m + 2 , … , n i = m + 1, m + 2, \dots, n i=m+1,m+2,…,n
对于每一个诚实的客户端进行如下操作:- 3.3.1.1. 使用L-BFGS算法估计模型的更新。
- 3.3.1.2. 计算模型更新的估计值。
- 3.3.1.3. 如果 ∥ g ^ t i ∥ ∞ > τ \|\hat{g}^i_t\|_\infty > \tau ∥g^ti∥∞>τ // 异常修复
如果模型的估计更新超出了预定的异常阈值,则:- 3.3.1.3.1. 服务器发送当前的模型到第i个客户端。
- 3.3.1.3.2. 该客户端计算模型的精确更新。
- 3.3.1.3.3. 该客户端将精确更新发送回服务器。
- 3.3.1.3.4. 使用客户端发送的精确更新来更新模型。
- 3.3.1.4. 使用聚合规则和学习率来更新模型。
该部分是FedRecover算法的核心,确保恢复的模型随着每一轮的训练逐渐改进,并且能够及时识别并纠正任何异常的模型更新。
最终调整阶段
4. 对于 t = T − T f , T − T f + 1 , … , T − 1 t = T - T_f, T - T_f + 1, \dots, T - 1 t=T−Tf,T−Tf+1,…,T−1 // 最终调整
在模型训练的最后几轮,这部分的目的是确保在返回最终的模型之前,模型已经进行了足够的精确训练和校正。
4.1. w ^ t + 1 ← \hat{w}_{t+1} \leftarrow w^t+1← ExactTraining( C r , w ^ t , η , A Cr, \hat{w}_t, \eta, A Cr,w^t,η,A)
在这个步骤中,与之前的周期性修正类似,使用ExactTraining函数进行精确的模型训练,不进行任何近似或估计。这确保了在训练结束时,模型是最优的并且尽可能地减少了错误。
返回最终的恢复模型
5. 返回 w ^ T \hat{w}_T w^T
在完成所有的预热、主体训练和最终调整后,算法返回最终的恢复模型 w ^ T \hat{w}_T w^T。这是FedRecover算法目的的产物,一个在联邦学习环境中,尽量减少异常和错误的模型。
Algorithm 2: L-BFGS
输入:
- 一个全局模型差异缓冲区 Δ W = [ Δ w b 1 , Δ w b 2 , … , Δ w b s ] \Delta W = [\Delta w_{b1}, \Delta w_{b2}, \dots, \Delta w_{bs}] ΔW=[Δwb1,Δwb2,…,Δwbs]
- 一个模型更新差异缓冲区 Δ G = [ Δ g b 1 , Δ g b 2 , … , Δ g b s ] \Delta G = [\Delta g_{b1}, \Delta g_{b2}, \dots, \Delta g_{bs}] ΔG=[Δgb1,Δgb2,…,Δgbs]
- 向量 v v v
输出:
- 近似的Hessian-vector乘积 H ~ v \tilde{H}v H~v
算法过程:
- A = Δ W T Δ G A = \Delta W^T \Delta G A=ΔWTΔG
- D = diag ( A ) D = \text{diag}(A) D=diag(A) // A A A的对角矩阵
- L = tril ( A ) L = \text{tril}(A) L=tril(A) // A A A的下三角矩阵
- σ = Δ g b s − 1 T Δ w b s − 1 Δ w b s − 1 T Δ w b s − 1 \sigma = \frac{\Delta g_{bs-1}^T \Delta w_{bs-1}}{\Delta w_{bs-1}^T \Delta w_{bs-1}} σ=Δwbs−1TΔwbs−1Δgbs−1TΔwbs−1
- p = [ − D L T L σ Δ W T Δ W ] − 1 [ Δ G T v σ Δ W T v ] p = \left[ \begin{array}{c} -D \\ L^T \\ L \\ \sigma \Delta W^T \Delta W \end{array} \right]^{-1} \left[ \begin{array}{c} \Delta G^T v \\ \sigma \Delta W^T v \end{array} \right] p= −DLTLσΔWTΔW −1[ΔGTvσΔWTv]
- H ~ v = σ v − [ Δ G σ Δ W ] p \tilde{H}v = \sigma v - \left[ \begin{array}{c} \Delta G \\ \sigma \Delta W \end{array} \right] p H~v=σv−[ΔGσΔW]p
- 返回 H ~ v \tilde{H}v H~v
Algorithm 3: ExactTraining
输入:
- 客户端 C C C
- 当前的全局模型 w ^ t \hat{w}_t w^t
- 学习率 η \eta η
- 聚合规则 A A A
输出:
- 更新后的全局模型 w ^ t + 1 \hat{w}_{t+1} w^t+1
算法过程:
- 服务器向客户端广播 w ^ t \hat{w}_t w^t
fori = 1 , 2 , … , ∣ C ∣ i = 1, 2, \dots, |C| i=1,2,…,∣C∣do
3. 第 i i i个客户端计算精确模型更新 g i , t = ∂ L i ( w ^ t ) ∂ w ^ t g_{i,t} = \frac{\partial L_i(\hat{w}_t)}{\partial \hat{w}_t} gi,t=∂w^t∂Li(w^t)
4. 第 i i i个客户端向服务器报告 g i , t g_{i,t} gi,tend for- w ^ t + 1 = w ^ t − η ⋅ A ( g t , 1 , g t , 2 , … , g t , ∣ C ∣ ) \hat{w}_{t+1} = \hat{w}_t - \eta \cdot A(g_{t,1}, g_{t,2}, \dots, g_{t,|C|}) w^t+1=w^t−η⋅A(gt,1,gt,2,…,gt,∣C∣)
- 返回 w ^ t + 1 \hat{w}_{t+1} w^t+1
E. Theoretical Analysis
首先,我们分析了由从零开始训练和FedRecover引入的客户端的计算和通信成本。接着,我们展示了在一些假设下,每一轮由FedRecover恢复的全局模型与从零开始训练恢复的全局模型之间的差异是有界的。最后,我们展示了这种差异与客户端的计算/通信成本之间的关系,即在FedRecover中恢复的全局模型的准确性与客户端的计算/通信成本之间的权衡。我们注意到,我们的理论边界分析基于一些假设,这些假设可能不适用于复杂的模型,如神经网络。因此,我们在下一节对神经网络的FedRecover进行实证评估。
计算和通信成本对客户端的影响:
当要求客户端计算模型更新时,我们向客户端引入了一些计算和通信成本。此外,这种计算/通信成本大致不取决于要求客户端在哪一轮计算模型更新。因此,我们可以将这种成本视为一个成本单位。从零开始训练要求每个客户端在每一轮都计算模型更新。因此,从零开始训练的客户端平均计算/通信成本是 O ( T ) O(T) O(T),其中 T T T是总轮数。在FedRecover中,成本取决于热身轮数 T w Tw Tw、周期性修正参数 T c Tc Tc、触发异常修复的轮数以及最终调优轮数 T f T_f Tf。异常修复的轮数取决于数据集、FL方法和阈值 τ \tau τ,这使得很难理论上分析FedRecover的成本。但是,当不使用异常修复时,即 τ = ∞ \tau = \infty τ=∞,我们可以显示FedRecover的客户端平均计算/通信成本为 O ( T w + T f + ⌊ ( T − T w − T f ) / T c ⌋ ) O(T_w + T_f + ⌊(T - T_w - T_f )/Tc⌋) O(Tw+Tf+⌊(T−Tw−Tf)/Tc⌋)。
通过FedRecover和从零开始训练恢复的全球模型之间的差异的边界:
我们首先描述了我们的理论分析所基于的假设。然后,我们展示了由FedRecover和从零开始训练恢复的全球模型之间的差异的界限。
假设1
损失函数是 μ \mu μ-强凸和 L L L-平滑的。对于每个客户 i i i,我们有以下两个不等式,对于任何 w w w和 w ′ w' w′:
⟨ w − w ′ , ∇ L i ( w ) − ∇ L i ( w ′ ) ⟩ ≥ μ ∥ w − w ′ ∥ 2 ( 3 ) \langle w - w', \nabla L_i(w) - \nabla L_i(w') \rangle \geq \mu \| w - w' \|^2 \quad (3) ⟨w−w′,∇Li(w)−∇Li(w′)⟩≥μ∥w−w′∥2(3)
⟨ w − w ′ , ∇ L i ( w ) − ∇ L i ( w ′ ) ⟩ ≥ 1 L ∥ ∇ L i ( w ) − ∇ L i ( w ′ ) ∥ 2 ( 4 ) \langle w - w', \nabla L_i(w) - \nabla L_i(w') \rangle \geq \frac{1}{L} \| \nabla L_i(w) - \nabla L_i(w') \|^2 \quad (4) ⟨w−w′,∇Li(w)−∇Li(w′)⟩≥L1∥∇Li(w)−∇Li(w′)∥2(4)
其中 L i L_i Li是客户 i i i的损失函数, ⟨ ⋅ , ⋅ ⟩ \langle \cdot, \cdot \rangle ⟨⋅,⋅⟩表示两个向量的内积, ∥ ⋅ ∥ \| \cdot \| ∥⋅∥表示向量的 ℓ 2 \ell_2 ℓ2范数。
假设2
在L-BFGS算法中近似Hessian-向量乘积的误差是有界的。形式上,每个近似的Hessian-向量乘积满足以下条件:
∀ i , ∀ t , ∥ H ~ i t ( w ^ t − w ˉ t ) + g i ˉ t − g i t ∥ ≤ M ( 5 ) \forall i, \forall t, \| \tilde{H}_i^t(\hat{w}_t - \bar{w}_t) + g\bar{i}_t - g_i^t \| \leq M \quad (5) ∀i,∀t,∥H~it(w^t−wˉt)+giˉt−git∥≤M(5)
其中 M M M是一个有限的正值。
定理1
假设1-2成立,FedAvg被用作聚合规则,阈值 τ = ∞ \tau = \infty τ=∞(即,不使用异常修复),学习率 η \eta η满足 η ≤ min ( 1 μ , 1 L ) \eta \leq \min(\frac{1}{\mu}, \frac{1}{L}) η≤min(μ1,L1),并且所有恶意客户都被检测到。那么,每一轮 t > 0 t > 0 t>0由FedRecover恢复的全局模型与从零开始训练恢复的模型之间的差异可以如下界定:
∥ w ^ t − w t ∥ ≤ ( 1 − η μ ) t ∥ w ^ 0 − w 0 ∥ + 1 − ( 1 − η μ ) t 1 − 1 − η μ η M ( 6 ) \| \hat{w}_t - w_t \| \leq \left( \sqrt{1 - \eta \mu} \right)^t \| \hat{w}_0 - w_0 \| + \frac{1 - \left( \sqrt{1 - \eta \mu} \right)^t }{1 - \sqrt{1 - \eta \mu}} \eta M \quad (6) ∥w^t−wt∥≤(1−ημ)t∥w^0−w0∥+1−1−ημ1−(1−ημ)tηM(6)
其中, w ^ t \hat{w}_t w^t和 w t w_t wt分别是在轮次 t t t由FedRecover和从零开始训练恢复的全局模型。
推论1
当L-BFGS算法可以精确计算积分Hessian-向量乘积(即, M = 0 M = 0 M=0)时,由FedRecover恢复的全局模型与从零开始训练恢复的模型之间的差异被界定为
∥ w ^ t − w t ∥ ≤ ( 1 − η μ ) t ∥ w ^ 0 − w 0 ∥ \| \hat{w}_t - w_t \| \leq \left( \sqrt{1 - \eta \mu} \right)^t \| \hat{w}_0 - w_0 \| ∥w^t−wt∥≤(1−ημ)t∥w^0−w0∥
因此,由FedRecover恢复的全局模型收敛于从零开始训练恢复的全局模型,即,我们有 lim t → ∞ w ^ t = lim t → ∞ w t \lim_{t \to \infty} \hat{w}_t = \lim_{t \to \infty} w_t limt→∞w^t=limt→∞wt。
准确性与成本之间的权衡
鉴于推论1,当FedRecover运行 T T T轮时,我们有差异边界为
∥ w ^ T − w T ∥ ≤ ( 1 − η μ ) T ∥ w ^ 0 − w 0 ∥ \| \hat{w}_T - w_T \| \leq \left( \sqrt{1 - \eta \mu} \right)^T \| \hat{w}_0 - w_0 \| ∥w^T−wT∥≤(1−ημ)T∥w^0−w0∥
差异界限随着 T T T的增加呈指数下降。此外,当 τ = ∞ \tau = \infty τ=∞时,FedRecover的计算/通信成本与 T T T成线性关系。因此,随着成本的增加,差异界限呈指数下降。换句话说,我们观察到FedRecover的准确性-成本权衡,即,当为客户端引入更多的成本时,由FedRecover恢复的全局模型更为准确(即,更接近从零开始训练的全球模型)。
V. 评估
A. 实验设置
-
数据集:我们考虑了多个不同的学习任务数据集进行评估。具体来说,我们使用了两个图像分类数据集(MNIST和Fashion-MNIST)、一个购买风格预测数据集(Purchase)和一个人类活动识别数据集(HAR)。除非另有说明,为简便起见,我们展示的实验结果基于MNIST。
-
MNIST:MNIST [22] 是一个10类数字图像分类数据集,包含60,000张训练图像和10,000张测试图像。每张图像的高和宽都是28。我们采用[18]中的卷积神经网络(CNN)作为全局模型架构。这个CNN由两个卷积层组成,每个卷积层后都跟着一个池化层,然后是两个全连接层。我们假设有100个客户,并使用[18]中的方法向他们分配训练图像,该方法有一个叫做非iid程度的参数,范围在0.1到1之间。当非iid程度大于0.1时,客户的本地训练数据是非iid的,而且非iid程度越大,非iid性也越大。默认情况下,我们在向客户分配训练图像时,将非iid程度设为0.5,但我们会探索其对FedRecover的影响。
-
Fashion-MNIST:Fashion-MNIST [35] 是另一个10类图像分类数据集。与包含数字图像的MNIST不同,Fashion-MNIST包含70,000张时尚图像。数据集被分为60,000张训练图像和10,000张测试图像,每张图像的大小为28×28。我们采用与MNIST相同的CNN。此外,我们也假设有100个客户,并在将训练图像分发给他们时,默认的非iid程度为0.5。
-
Purchase:Purchase是[1]发布的一个零售数据集。任务是预测客户属于哪种购买风格。数据集总共包含197,324个购买记录,每个记录有600个二进制特征,属于100个不平衡的类别之一。数据集被分为180,000个训练记录和17,324个测试记录。按照[29]的方法,我们采用一个只有一个隐藏层的全连接神经网络作为全局模型架构,隐藏层中的神经元数量为1,024,激活函数为Tanh。我们还假设总共有100个客户。按照[29]的方法,我们将训练记录均匀分配给他们。
-
人类活动识别(HAR):HAR [4] 是一个6类人类活动识别数据集。数据集是从30个真实世界用户的智能手机中收集的。每个数据样本包含561个特征,代表用户智能手机的多个传感器收集的信号,并属于6种可能的活动之一(例如,步行、坐着和站立)。我们认为数据集中的每个用户都是一个客户。此外,按照[11]的建议,我们使用每个客户的数据的75%作为本地训练数据,剩下的25%作为测试数据。我们采用一个包含两个隐藏层的全连接神经网络作为全局模型架构,其中每个隐藏层由256个神经元组成,并使用ReLU作为激活函数。
-
-
FL 设置:回忆原始的FL训练在每一轮中有三个步骤。我们考虑客户使用随机梯度下降来计算模型更新。考虑到数据集的不同特点,我们为原始FL训练采用以下参数设置:对于MNIST和Fashion-MNIST,我们进行2,000轮训练,学习率为 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,批量大小为32;对于Purchase,我们进行1,000轮训练,学习率为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,批量大小为2,000;对于HAR,我们进行1,000轮训练,学习率为 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,批量大小为32。我们考虑三种聚合规则:FedAvg [24]、Median [36] 和 Trimmed-mean [36]。我们不考虑Krum [8],因为它既不准确也不稳健[18], [5],我们也不考虑FLTrust [11],因为它要求服务器有额外的干净数据集。在所有数据集中,我们为Trimmed-mean设置trim参数 k = n × 20 % k = n \times 20\% k=n×20%。具体来说,对于MNIST、Fashion-MNIST、Purchase和HAR数据集,k分别为20、20、20和6。
-
攻击设置:默认情况下,我们随机抽样20%的客户作为恶意客户。具体来说,对于MNIST、Fashion-MNIST、Purchase和HAR数据集,恶意客户的数量分别为20、20、20和6。此外,我们假设攻击者执行全知识攻击。我们考虑Trim攻击(一种非定向的投毒攻击)[18]和后门攻击(一种定向的投毒攻击)[5]。我们采用[18]中的Trim攻击的默认参数设置。我们按照[11]的方法设计后门攻击中的触发器。具体来说,对于MNIST和Fashion-MNIST,我们采用位于右下角的同样的白色像素作为触发器。对于Purchase和HAR,我们将每20个特征值设置为0作为触发器。我们为所有数据集选择0作为目标标签。在后门攻击中,每个恶意客户都会放大其恶意模型更新。对于MNIST,我们将放大因子设置为10,对于Fashion-MNIST和HAR,我们将放大因子设置为5,因为在这些设置下后门攻击的成功率很高。我们注意到,当放大因子从1变化到100时,Purchase的攻击成功率相似。因此,为了更加隐蔽,我们将Purchase的放大因子设置为1。在原始FL训练的每一轮中,恶意客户都执行Trim攻击或后门攻击。此外,在恢复过程中,当一些恶意客户没有被检测到时,它们在每次预热、定期校正、异常修复和最终调整轮次中都进行攻击。
B. 实验结果
-
FedRecover的准确性和效率:
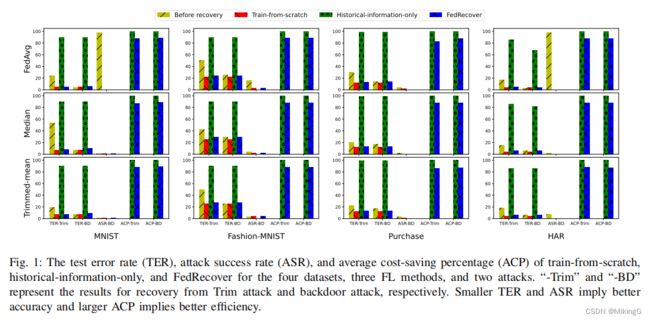
- 根据图1,对于四个数据集、三种聚合规则和两种攻击,展示了从头开始训练、只使用历史信息以及FedRecover的TER、ASR和ACP。
- 观察到FedRecover在从被污染的模型中恢复全局模型时既准确又高效。
- FedRecover可以达到与从头开始训练相似的TER和ASR,而且可以获得大量的ACP,即FedRecover可以显著减少客户端的计算/通信成本。
- 只使用历史信息不会向客户端引入成本(即ACP为100),但其恢复的全局模型的TER较大(近似于随机猜测)。
-
恶意客户数量的影响:
- 图2显示了恶意客户数量对从Trim攻击中恢复的影响。
- 观察到,当不同数量的客户端是恶意的时,FedRecover可以恢复与从头开始训练一样准确的全局模型,即FedRecover的TER(和ASR)接近于从头开始训练。
- 此外,与从头开始训练相比,FedRecover可以为客户端节省大部分成本。

-
非iid程度的影响:
- 图3显示了客户端本地训练数据的非iid程度对从Trim攻击中恢复的影响。
- 观察到,对于非iid的广泛范围,FedRecover可以恢复与从头开始训练一样准确的全局模型。

-
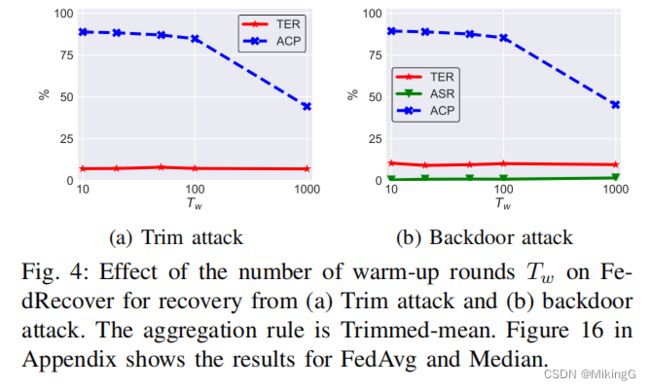
预热轮数 T w Tw Tw的影响:
- 图4显示了 T w Tw Tw对FedRecover从两种攻击中恢复时的影响。
- TER和ASR保持稳定,而ACP随着预热轮数的增加而减少。
-
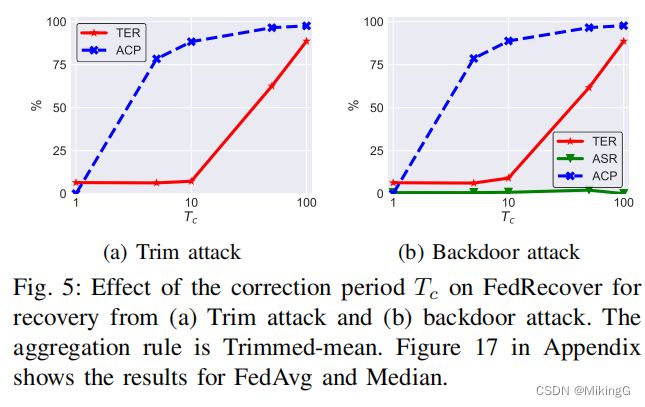
纠正周期 T c Tc Tc的影响:
- 图5显示了 T c Tc Tc对FedRecover从两种攻击中恢复时的影响。
- 观察到 T c Tc Tc在精度和效率之间进行权衡。
-
容忍率 α \alpha α的影响:
- 图6显示了 α \alpha α对FedRecover的影响。

- 图6显示了 α \alpha α对FedRecover的影响。
-
最终调整轮数 T f T_f Tf的影响:
- 图7显示了 T f T_f Tf对FedRecover从两种攻击中恢复时的影响。
- TER和ASR保持稳定,而ACP随着最终调整轮数的增加而略有下降。

-
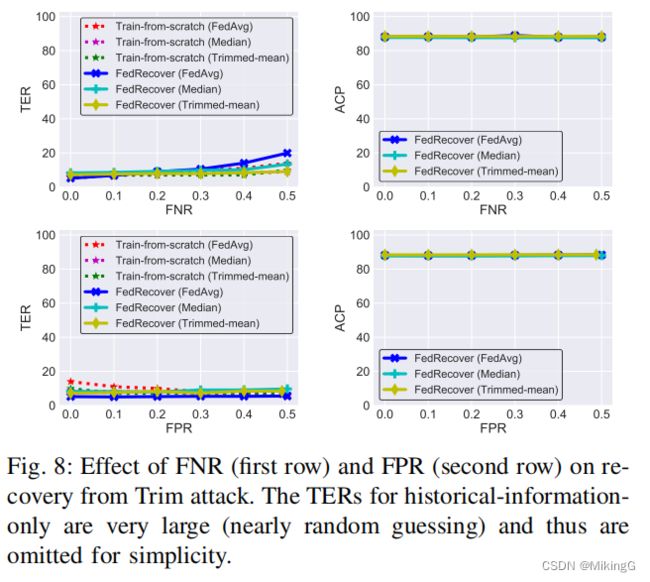
检测恶意客户时的假阴性率(FNR)和假阳性率(FPR)的影响:
- 图8显示了FNR和FPR对从Trim攻击中恢复的影响。
- 观察到,即使FNR或FPR非零,FedRecover仍然可以恢复与从头开始训练一样准确的全局模型。
VI. 讨论与局限性
A. 存储历史信息的安全/隐私关注
- 基本观点:在FedRecover中,服务器存储了客户端的历史信息,包括每一轮的模型更新。
- 安全/隐私问题:存储的历史信息是否为客户端带来额外的安全/隐私问题?
- 在我们的威胁模型中,假设服务器没有被攻击者入侵,这样存储的历史信息不会引入额外的安全/隐私问题。
- 如果服务器可能被攻击者入侵,则FedRecover为客户端带来的安全/隐私问题取决于服务器何时被入侵。
- 未来工作方向:研究此种场景中可能的额外安全/隐私风险是一个有趣的未来工作方向。
B. 客户端退出
- 核心思想:本文主要研究的是,在某些恶意客户端被服务器检测并移除后,如何恢复全局模型。
- 在实际中,良性客户端也可能由于隐私等各种原因在全局模型训练后退出FL系统。
- 退出的客户端可能希望全局模型忘记从其私有本地训练数据中学到的知识,甚至忘记其存在。
- 使用FedRecover:可以通过将退出的良性客户端视为检测到的“恶意”客户端,来使用FedRecover恢复全局模型。
- 未来工作方向:研究恢复后的全局模型为退出的良性客户端提供的隐私保证是一个有趣的未来工作方向。
C. 服务器的存储和计算成本
- 额外的存储和计算成本:FedRecover为服务器带来额外的存储和计算成本。
- 假设本地/全局模型有 M M M个参数。服务器需要 O ( n M T ) O(nMT) O(nMT)的额外存储来保存原始模型更新和全局模型,其中 n n n是客户端的数量, T T T是全局轮次的数量。
- 服务器需要估计大约 O ( ( n − m ) T ) O((n - m)T) O((n−m)T)的模型更新,其中 m m m是恶意客户端的数量。估计一个模型更新的复杂性是 O ( M 2 s ) O(M^2s) O(M2s),其中 s < M s < M s<M是缓冲区的大小。
- 存储和计算成本:对于强大的服务器(例如现代数据中心)来说,存储和计算成本是可以接受的。
VII. 结论与未来工作
- FedRecover介绍:我们提出了一个称为FedRecover的模型恢复方法,旨在消除全局模型在FL中的后门攻击影响。
- 历史信息的价值:我们的理论和实证结果显示,在检测到恶意客户端之前,服务器在训练被毒化的全局模型过程中收集的历史信息对于在检测到恶意客户端后有效地恢复准确的全局模型是有价值的。
- 未来工作方向:
- 探索在适应性后门攻击下FedRecover的准确性和效率。
- 扩展FedRecover到其他领域的FL。