【Linux】:Kafka组件介绍
目录
环境简介
一、消息
二、主题
三、分区
四、副本
五、生产者
六、消费者
七、消费者组
八、offsets【偏移量】
环境简介
Linux内核:Centos7
Kafka版本:3.5.1
执行命令的目录位置:Kafka安装目录的bin目录下:/usr/local/kafka/bin/
一、消息
kafka中消息可以分为单播类型消息和多播类型消息
单播消息:多个消费者监听同一个主题,有且只有一个消费者能消费该主题下的消息。
多播消息:多个消费者监听同一个主题,每一个消费者都能完整的消费该主题下的消息。
单播消息、多播消息如何实现,请参考【消费者组】说明
二、主题
1.消息按主题分类
2.消费者通过监听主题名称来消费消息
3.消息是以log文件的方式存储,存储在配置文件中配置的log.dirs目录下
4.该目录下存在以主题命名对的文件夹,该文件夹下就存储了当前主题的消息文件(分为三种形式同时存储):
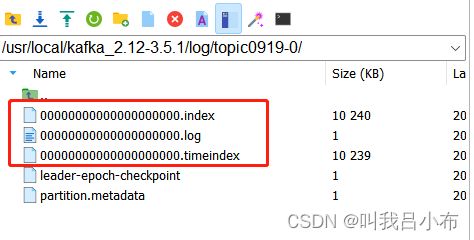
.log:日志文件
.index:索引文件,以稀疏索引方式存储 某个时间段以内的索引是在.index中的哪个位置
.timeIndex:时间索引文件
5.如果同一个TOPIC下的消息数量过多,多到需要几T来存储,因为消息时以log文件的方式存储的,可以使用Partition分区来管理消息文件。
三、分区
1.如果同一个主题下的消息数量过多,多到需要几T来存储,此时单一的log文件就会过大,此时可以通过分区Partitions来管理消息文件。
2.kafka配置文件中默认的主题分区数是1
3.创建主题时,如果不指定分区数的话,则使用默认分区数
4.创建主题时,如果指定分区数量,则需要同时指定副本数量
5.主题创建完成后,可以二次更改主题的分区数,只不过修改后的分区数只能大于修改前的分区数
6.创建主体时,如果指定了多个分区,那么在log.dirs配置的目录下,就会存在多个该主题命名的文件夹,每一个文件夹下,就存储当前分区下的日志,如图(topic0918是创建了两个分区):

7.优点:
解决单存储文件过大的问题
可以分布式存储
可以提高消息的吞吐量(消息的读取可以同时从多分区中进行)
四、副本
在集群中使用到的概念
五、生产者
消息的发送者,不再赘述
六、消费者
1.消息的监听者
2.可以从主题的第一条消息开始监听【--from-begging】
3.也可以从主题的最新一条消息开始监听
4.其他不再赘述
七、消费者组
1.在使用kafka原生名称创建消费者时,可以同时将创建的消费者给放入一个自定义名称的消费者组中。
2.消费者组的作用:
实现单播消息:同一个消费者组下的多个消费者同时监听同一个消息主题,只有一个消费者可以监听到主题中的消息,且在该消费者存货期间,一直由该消费者监听。如果该消费者down掉以后,再由当前消费者组中的其他任一消费者监听。
八、offsets【偏移量】
1.kafka消费者在消费消息是,会自动提交偏移量,来记录消息的消费位置,以保证后续的正常继续消费。
2.kafka可设置为手动提交偏移量
3.在kafka的dir.logs目录的日志文件夹下,除了用户创建的主题文件夹外,还有默认的_consumer_offset-0 ~ _consumer_offset-49,共50个文件夹(其实就是50个分区)

4.kafka通过这些文件夹用来记录消费者消费主题的偏移量(即kafka提交的消费偏移量以k-v形式存储在了_consumer_offset中):
key值是consumerGroupId+topic+分区, value值是当前消费的offset
5.kafka默认分配50个分区,通过offset.topic.num.partitions来设置, 通过如下公式,可选出consumer消费的offset要提交到哪个_consumer_offsets分区中:
hash(consumerGroupId)%_consumer_offset主题的分区数