Hive 进阶篇
Hive 进阶篇
- 1. CTE与CTAS 语法
-
-
- 1.1 CTE语句
- 1.2 CTAS语句
-
- 2. join 连接
-
-
- 2.0 表的创建
- 2.1 内连接
- 2.2 左右连接
- 2.3 全外连接
- 2.4 左半开连接
- 2.5 交叉连接
- 2.6 Hive join 使用注意事项
-
- 3. Hive函数 以及 Linux终端执行
-
-
- 3.1 终端执行Hive sql语句
- 3.2 Hive 内置函数
- 3.3 Hive 自定义函数
-
- 4. Hive 函数高阶
-
-
- 4.1 爆炸函数
- 4.2 Lateral View 侧视图
- 4.3 行列转换
-
-
- 4.3.1 多行转单列
- 4.3.2 单列转多行
- 4.3.3 行转列,列转行
-
-
- 5. Json 数据处理
-
-
- 5.1 Hive自带的json处理函数
- 5.2 JSONSerde
-
- 6. 窗口函数 (Window functions)
-
-
- 6.1 窗口函数概述
- 6.2 滑动窗口( 聚合窗口函数)
- 6.3 窗口排序函数
- 6.4 分析类窗口函数
-
- 7. 分组函数
-
- 以下代码适合在Presto中运行,切记!
-
- 7.0 数据准备
- 7.1 分组函数:rollup
- 7.2 分组函数:cube
- 7.3 分组函数:grouping sets
- 7.4 grouping 函数调用分组
- 7.5 Hive中执行
1. CTE与CTAS 语法
1.1 CTE语句
公用表表达式(CTE)是一个临时结果集,该结果集是从with子句中指定的简单查询派生而来的,该查询紧接在select或insert关键字之前。
-- 基本CTE
with new_table as (select * from student where sex='male')
select name,age,money,sex from new_table;
-- from前置CTE
with new_table as (select * from student where sex='female')
from new_table select name,age,money,sex;
-- 链式调用的CTE
with new_tb1 as (select name,age,sex,money from student where money>=5000),
new_tb2 as (select *,count(1) over() from new_tb1 where sex='female')
select * from new_tb2;
-- 结合union的CTE
with new_tb1 as (select * from student where sex='male' and money>5000),
new_tb2 as (select * from student where sex='female' and money>5000)
select name,age,money,sex from new_tb1
union
select name,age,money,sex from new_tb2;
1.2 CTAS语句
CTAS是利用CTE产生的结果集来创建的新表,建表的数据来源于select。
-- 基本CTAS
create table if not exists student_ctas
as
with new_tb as (select * from student where money<5000)
select * from new_tb;
-- 上面的语句等价于下面这个
create table student_ctas_test like student;
with new_tb as (select * from student where money<5000)
insert into student_ctas_test
select * from new_tb;
2. join 连接
在Hive中共支持6种join语法。分别是:
inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左半开连接)、cross join(交叉连接,也叫做笛卡尔乘积)。
2.0 表的创建
-- 职工表
create table employee(
id int comment '职工id',
name string comment '名字',
level string comment '职务',
salary int comment '薪资',
dept string comment '部门'
)row format delimited fields terminated by ',';
-- 职工地址信息表
create table employee_add(
id int comment '职工id',
homeno string comment '具体住所',
area string comment '居住地方',
city string comment '居住城市'
)row format delimited fields terminated by ',';
-- 职工联系方式表
create table employee_conn(
id int comment '职工id',
phno string comment '电话',
email string comment '邮箱'
)row format delimited fields terminated by ',';
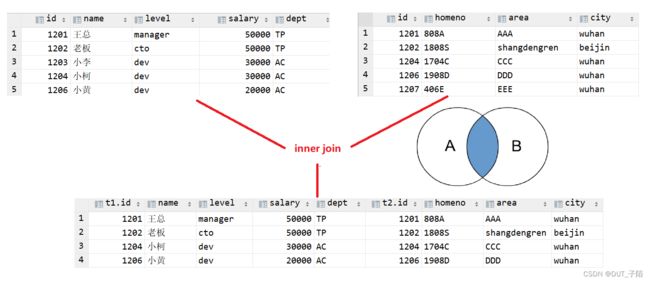
2.1 内连接
只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。内连接是最常见的一种连接,它也被称为普通连接或自然连接。其中inner可以省略,inner join == join。
-- 以下三种都是内连接的使用方法
select * from employee inner join employee_add on employee.id =employee_add.id;
select * from employee join employee_add on employee.id =employee_add.id;
-- 隐式调用
select * from employee t1 ,employee_add t2 where t1.id=t2.id;
![]()
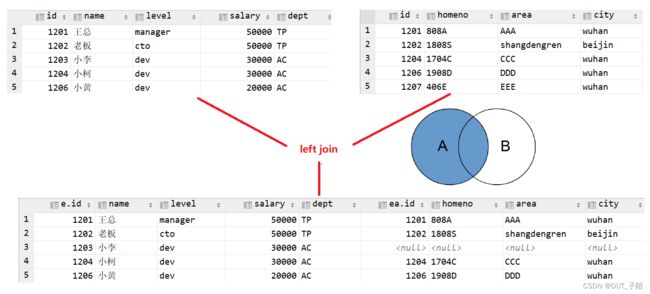
2.2 左右连接
left join中文叫做是左外连接(Left Outer Jion)或者左连接,其中outer可以省略,left outer join是早期的写法。left join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。
-- 左连接
select * from employee e left outer join employee_add ea on e.id=ea.id;
select * from employee e left join employee_add ea on e.id=ea.id;
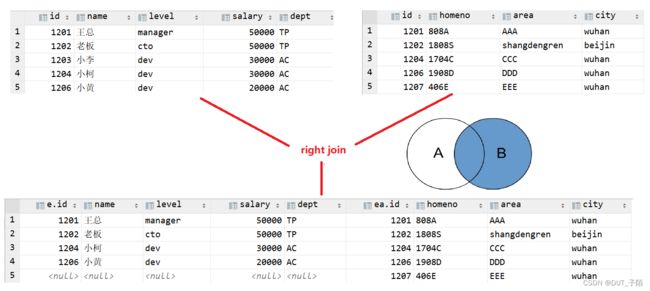
right join中文叫做是右外连接(Right Outer Jion)或者右连接,其中outer可以省略。right join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回 。
-- 右连接
select * from employee e right outer join employee_add ea on e.id=ea.id;
select * from employee e right join employee_add ea on e.id=ea.id;
![]()
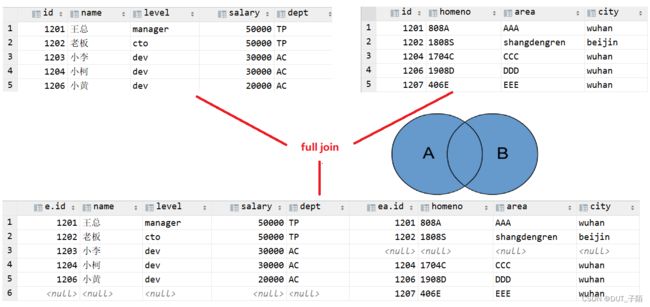
2.3 全外连接
full outer join 等价 full join ,中文叫做全外连接或者外连接。包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
-- 全外连接
select * from employee e full outer join employee_add ea on e.id=ea.id;
select * from employee e full join employee_add ea on e.id=ea.id;
![]()
2.4 左半开连接
left semi join 会返回左边表的记录,前提是其记录对于右边的表满足ON语句中的判定条件。从效果上来看有点像inner join之后只返回左表的数据。
-- 左半开连接
select * from employee e left semi join employee_add ea on e.id=ea.id;
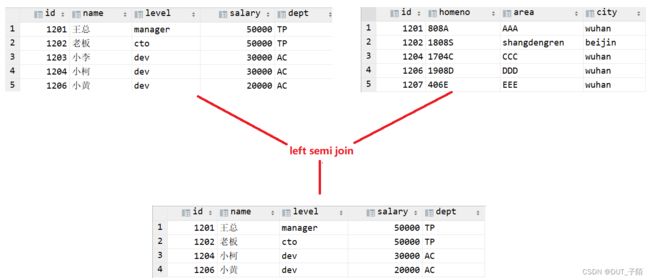
![]()
2.5 交叉连接
cross join ,将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。对于大表来说,cross join慎用。在SQL标准中定义的cross join就是无条件的inner join。在HiveSQL语法中,cross join 后面可以跟where子句进行过滤,或者on条件过滤。
-- 交叉连接
--隐式交叉连接
select * from employee t1 ,employee_add t2;
select * from employee e cross join employee_add; -- 25条数据
select * from employee e cross join employee_add ea on e.id=ea.id; -- 4条数据
笛卡尔积 :
例如,A={a,b}, B={0,1,2},则
A×B = { (a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2) }
B×A = { (0, a), (0, b), (1, a), (1, b), (2, a), (2, b) }
![]()
2.6 Hive join 使用注意事项
这里的特效针对Hive 3.1版以上的。
-
使用复杂的联接表达式
select b.* from a join b on (a.id = b.id and a.dept = b.dept); select a.* from a left outer join b on (a.id <> b.id); -
同一查询中可以连接2个以上的表
select * from employee e join employee_add ea join employee_conn ec on e.id=ea.id and e.id=ec.id; -
不等数据展示
select * from employee e join employee_add ea join employee_conn ec on e.id<>ea.id and e.id<>ec.id;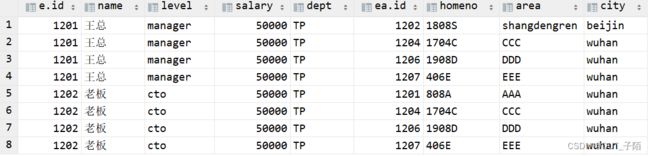
-
若每个表在联接子句中使用相同的列,则Hive将多个表上的连接转换为单个MR作业
-- 当多张表关联相同的字段时,是在一个 Reduce 中计算 select * from employee e join employee_address ea join employee_connection ec on e.id=ea.id and e.id=ec.id; -- 当多张表关联使用不相同的字段,有几个不同的字段,就有几个Reduce 进行计算 select * from employee e join employee_address ea join employee_connection ec on e.id=ea.id and ea.hno=ec.phno; -
关联数据的传递
join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置最后有助于减少reducer阶段缓存数据所需要的内存
3. Hive函数 以及 Linux终端执行
3.1 终端执行Hive sql语句
hive -e SQL语句
hive -e "select * from zimo.student"
hive -f SQL脚本
hive -f /home/zimodata/test.sql
3.2 Hive 内置函数
-
字符串函数
----- 字符串函数 ----- --截取字符串substr(字符串,起始位置,共截取数) select substr("abcdef",3,3); --拼接字符串concat(字符串,字符串) select concat("hello","zimo"); --如果有null返回null select concat("hello","zimo",null); --拼接字符串指定分隔符(分隔符,字符串,字符串,……) select concat_ws("|","hello","zimo","love"); --如果有null则忽略null select concat_ws("|","hello",null,"zimo","love"); --替换字符串(原字符串,要替换的子串,替换后的字串) select replace("hello zimo","hello","nihao"); --切割字符串,返回的是数组 select split("hello_zimo","_"); select split("hello_zimo","_")[1]; -
日期函数
----- 日期函数 ----- --减天数date_sub(日期,要减的天数) select date_sub('2022-5-5',10); --加天数date_add(日期,要加的天数) select date_add('2022-4-21',10); --时间戳转日期from_unixtime(时间戳) select from_unixtime(1651999999); --输出年月日时分秒 select year('2022-5-5 20:13:14'); select month('2022-5-5 20:13:14'); select day('2022-5-5 20:13:14'); select hour('2022-5-5 20:13:14'); select minute('2022-5-5 20:13:14'); select second('2022-5-5 20:13:14'); -
数学函数
----- 数学函数 ----- -- 保留小数round(数字,保留位数) select round(3.14159265857,5); --取随机数(0,1] select rand(); --取绝对值 select abs(-4.5); --向下取整 select floor(4.5); --向上取整 select ceil(4.5); -
其他函数
----- 其他函数 ----- --三元运算符if(判断,成立返回值,不成立返回值) select if(20>rand()*40,'hello','zimo'); --从左到右返回第一个不为空的值coalesce(……) select coalesce(null,null,null,3,null,4); -
case when 函数
----- case/when-then函数 ----- select age,case when age <22 then '小菜鸡' when age <=24 then '雏鸡' else '老油鸡' end as age_type_chicken from student; select age, case age when 20 then '小菜鸟' when 21 then '菜鸟' when 22 then '中鸟' when 25 then '老鸟' else '猛鸟' end as age_type_bird from student; select case when age <23 then '小毛孩' when age <25 then '猛男' else '老油条' end as age_level,count(1) as cn from student group by case when age <23 then '小毛孩' when age <25 then '猛男' else '老油条' end;
3.3 Hive 自定义函数
用户自定义函数简称UDF (user-defined function)自定义函数总共有3类,是根据函数输入输出的行数来区分的,分别是
- udf 函数 【普通函数,一进一出】
- udaf 函数 【聚合函数,多进一出】
- udtf 函数 【表生成函数,一进多出】
用户自定义函数,即用户自己开发的函数。开发步骤如下:
- 加入依赖
- 自定义类,集成UDF
- 重写方法
- 打包
- 上传
- 重启
- 注册,使用
4. Hive 函数高阶
4.1 爆炸函数
explode函数,又叫“爆炸函数”,可以炸开数据。explode函数接收map或者array类型的数据作为参数,然后把参数中的每个元素炸开变成一行数据,一个元素一行。一般情况下,explode函数可以直接使用即可,也可以根据需要结合lateral view侧视图使用。
爆炸函数的例子:
select explode(`array`('hello','zimo','dashuaibi')) as element;
select explode(`map`('id',1314,'name','zimo','age',18)) as (k,v);
select explode(split('hello_zimo_shi_dashuaibi','_')) as item;
创建表加入数据:
create table NBA_Championship(
teamname string,
winyear array<string>
)row format delimited fields terminated by ','
collection items terminated by '|';
explode语法的限制
- explode函数属于UDTF函数,即表生成函数,explode函数执行返回的结果可以理解为一张虚拟的表,其数据来源于源表;
- 不能在查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段。通俗点讲,两张表,不能只查询一张表但是返回分别属于两张表的字段;
-
-- 报错语句,UDTF函数返回的是一个虚拟表, 因为不能将字段与表一起查看,所以报错 select teamname,explode(winyear) from NBA_Championship;
![]()
4.2 Lateral View 侧视图
Lateral View 侧视图,用于搭配UDTF类型功能的函数使用,以解决UDTF函数 查询限制的问题。侧视图的原理:将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。一般只要使用UDTF,就会固定搭配lateral view使用。
select teamname,year from NBA_Championship a lateral view explode(winyear)
b as year;
--倒序排序
select teamname,year from NBA_Championship a lateral view explode(winyear)
b as year order by year desc;

![]()
4.3 行列转换
建表语句以及数据:
表一:
create table class_score(
id int,
name string,
sub string,
score int
)row format delimited fields terminated by ',';
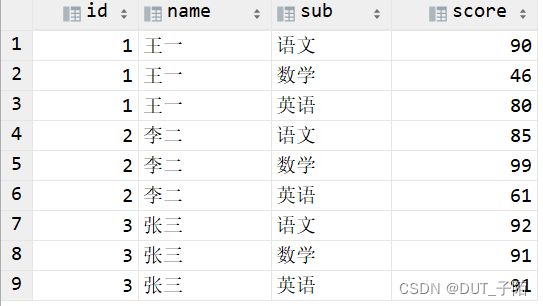
表二:
create table class_score_merge(
id int,
name string,
SCORE_chinese_math_English array<int>
)row format delimited fields terminated by ','
collection items terminated by '_';

表三:
create table class_score_row (
id int,
name string,
chinese int,
math int,
english int
) row format delimited fields terminated by ',';

4.3.1 多行转单列
--字符串拼接(有null返回null)
select concat("hello","dashuaibi","zimo");
select concat("hello","dashuaibi","zimo",null);
--字符串拼接,可以指定分隔符(有null忽略null)
select concat_ws("_","hello","dashuaibi","zimo");
select concat_ws("_","hello",null,"dashuaibi","zimo");
--将一列中的多行合并为一行,不进行去重
select collect_list(name) from class_score;
--将一列中的多行合并为一行,去重
select collect_set(name) from class_score;

select id,name,collect_list(score) as chinese_math_English
from class_score group by id,name;
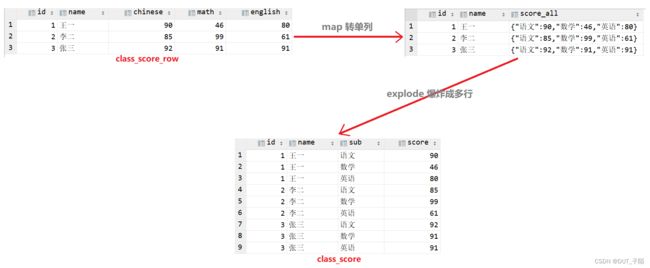
4.3.2 单列转多行
--将一个集合或者数组中的每个元素展开,将每个元素变成一行
select explode(`array`('hello','dashuaibi','zimo'));

--实现上述图示功能:
select id,name, b.score from class_score_merge a lateral view
explode(a.score_chinese_math_english) b as score;
4.3.3 行转列,列转行
行转列
-- 默认case匹配不到的就是null
select id,name,case when sub='语文' then score else null end chinese,
case when sub='数学' then score else null end math,
case when sub='英语' then score else null end English
from class_score;
select id,name,max(case when sub='语文' then score end) chinese,
max(case when sub='数学' then score end) math,
max(case when sub='英语' then score end) English
from class_score group by id,name;
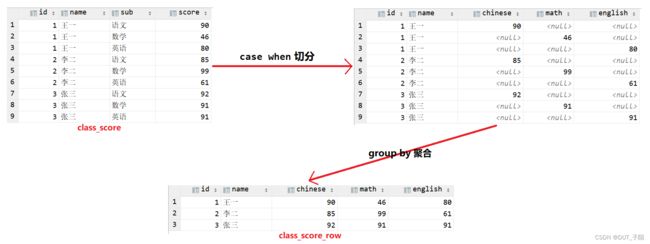
列转行:
select id,name,`map`('语文',chinese,'数学',math,'英语',english)
score_all from class_score_row;
select id,name, sub, score from (
select id,name,`map`('语文',chinese,'数学',math,'英语',english) score_all
from class_score_row) as t1
lateral view explode(score_all) t2 as sub,score;
![]()
5. Json 数据处理
数据集:
create table json_table(
json string
);

5.1 Hive自带的json处理函数
如果数据中每一行只有个别字段是JSON格式字符串,就可以使用JSON函数来实现处理。
get_json_object 与 json_tuple 函数
--获取json对象:get_json_object(json,"$.(对象名)"
select get_json_object(json,'$.device') as device,
get_json_object(json,'$.deviceType') as deviceType,
get_json_object(json,'$.signal') as signal,
get_json_object(json,'$.time') as stime
from json_table limit 10;
--获取json对象:json_tuple(json,'(对象名1)',……) as (字段名1,……)
select json_tuple(json,'device','deviceType','signal','time')
as (device,deviceType,signal,stime)
from json_table limit 5;
5.2 JSONSerde
如果数据中每一行数据就是一个JSON数据,那么建议直接使用JSONSerde。
drop table json_table_immediately;
create table json_table_immediately(
device string,
deviceType string,
signal double,
`time` string
)row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
stored as textfile;
load data local inpath '/home/zimodata/device.json' into table json_table_immediately;
select * from json_table_immediately limit 10;
![]()
6. 窗口函数 (Window functions)
建表:
create table cookie_pv(
cookie string ,
createday string ,
pv int
)row format delimited fields terminated by ',';
create table cookie_url(
cookie string,
createtime string,
url string
)row format delimited fields terminated by ',';
6.1 窗口函数概述
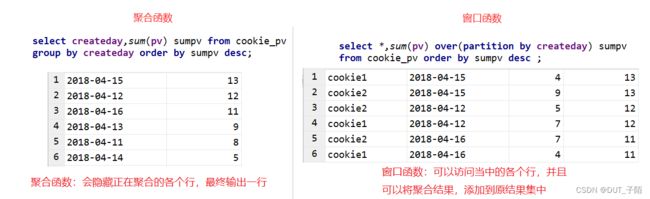
窗口函数(Window functions)是一种SQL函数,适合于数据分析,因此也叫做OLAP函数,其最大特点是:输入值是从select语句的结果集中的一行或多行的“窗口”中获取的。你也可以理解为窗口有大有小(行有多有少)。
聚合函数和窗口函数的区别:
聚合函数 聚合会隐藏正在聚合的各个行,最终输出一行;
窗口函数 聚合可以访问当中的各个行,并且可以聚合结果,添加回原结果集中。
--聚合函数
select createday,sum(pv) sumpv from cookie_pv
group by createday order by sumpv desc;
--窗口函数
select *,sum(pv) over(partition by createday) sumpv
from cookie_pv order by sumpv desc ;
![]()
6.2 滑动窗口( 聚合窗口函数)
| 关键字是rows between | 包括下面这几个选项 |
|---|---|
| preceding | 往前 |
| following | 往后 |
| current row | 当前行 |
| unbounded | 边界 |
| unbounded preceding | 表示从前面的起点 |
| unbounded following | 表示到后面的终点 |
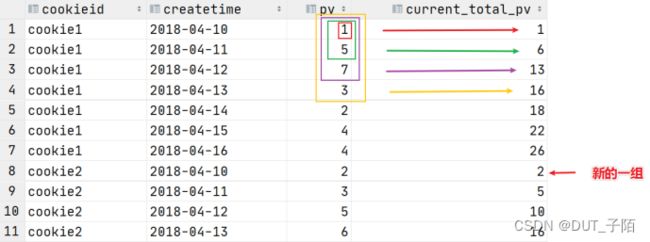
--从头滑动
select *,sum(pv) over(partition by cookie order by createday)
as sumpv from cookie_pv;
--等价于上面
select *,sum(pv) over(partition by cookie order by createday
rows between unbounded preceding and current row )
as sumpv from cookie_pv;
--滑动整个分区
select *,sum(pv) over(partition by cookie) sumpv from cookie_pv;
--等价于上面
select *,sum(pv) over(partition by cookie
rows between unbounded preceding and unbounded following) as sumpv
from cookie_pv;
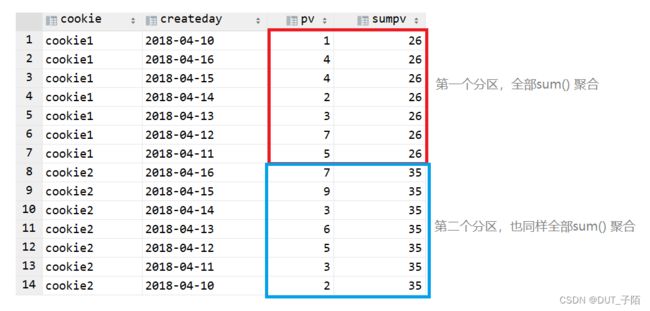
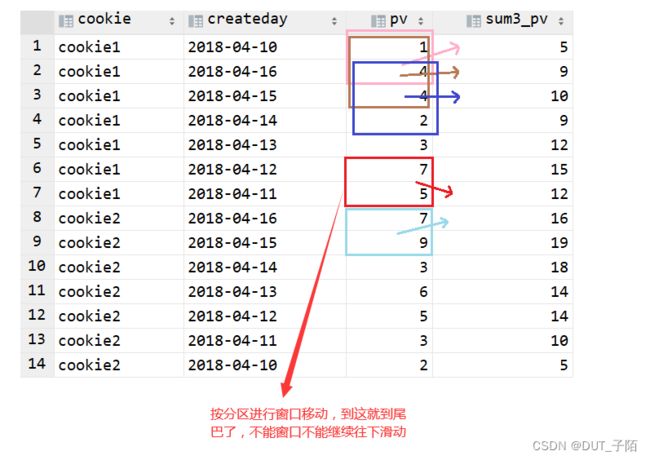
--向前1行,向后1行,以3个为窗口进行滑动
select * , sum(pv) over(partition by cookie
rows between 1 preceding and 1 following ) as sum3_pv
from cookie_pv;
6.3 窗口排序函数
| 窗口排序函数 | |
|---|---|
| rank() | 从1开始递增,考虑重复,挤占后续位置 |
| dense_rank() | 从1开始递增,考虑重复,不挤占后续位置 |
| row_number() | 从1开始递增,不考虑重复 |
| ntile(N) | 将每个分组内的数据分为指定的若干个桶里(分为N个部分),并且为每一个桶分配一个桶编号,并且各个桶中能放的行数最多相差1 |
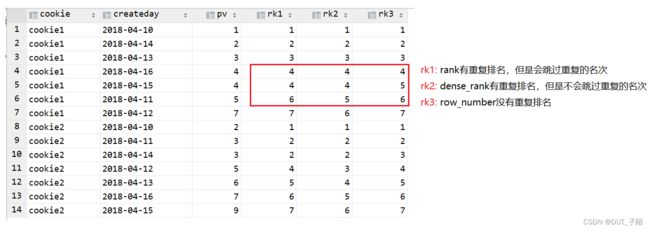
-- 排序
select *,
rank() over (partition by cookie order by pv) rk1,
dense_rank() over (partition by cookie order by pv) rk2,
row_number() over (partition by cookie order by pv) rk3
from cookie_pv;
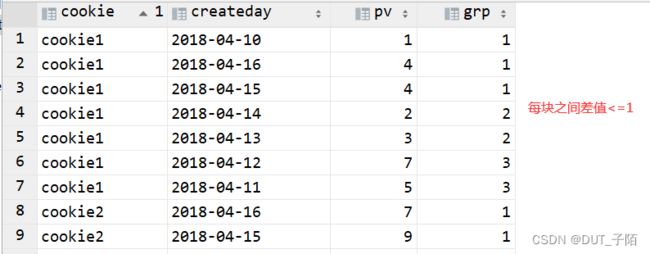
-- 在分区中再等分成3块
select * ,ntile(5) over (partition by cookie) grp
from cookie_pv;
![]()
6.4 分析类窗口函数
| 分析类窗口函数 | |
|---|---|
| lead(字段,N,null的填空值) | |
| lag(字段,N,null的填充值) | |
| first_value(字段) | |
| last_value(字段) |
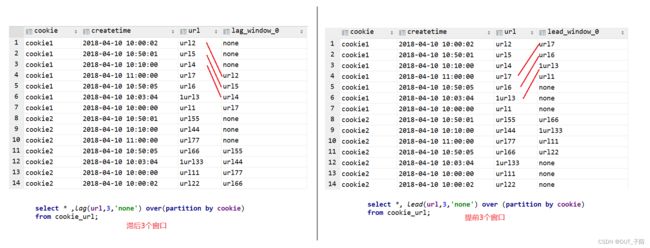
--默认值为lag(字段,1,null)【滞后】
select * ,lag(url,3,'none') over(partition by cookie) from cookie_url;
-- 默认值为lead(字段,1,null)【提前】
select *, lead(url,3,'none') over (partition by cookie) from cookie_url;
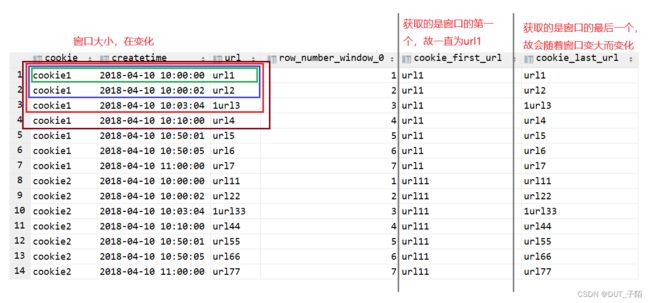
select *,row_number() over (partition by cookie order by createtime ),
first_value(url) over(partition by cookie order by createtime) cookie_first_url,
last_value(url) over(partition by cookie order by createtime) cookie_last_url
from cookie_url;
7. 分组函数
以下代码适合在Presto中运行,切记!
7.0 数据准备
-- 建表
create table stu(
name string comment '姓名',
age int comment '年龄',
score int comment '成绩',
sex string comment '性别',
class string comment '班级',
from_province string comment '省份',
from_city string comment '城市'
)
row format delimited fields terminated by '\t';
-- 插入数据
insert into table stu
values ('珂一',21,91,'female','土木1班','江西省','南昌市')
,('王二',21,84,'male','土木1班','江西省','吉安市')
,('张三',25,65,'male','土木2班','福建省','厦门市')
,('李四',21,77,'female','土木2班','浙江省','杭州市');

![]()
7.1 分组函数:rollup
假设有n个维度,那么rollup会有n+1个聚合,如:
| rollup(A,B) | 3种 | () , ( A ) , ( A,B ) |
| rollup(A,B,C) | 4种 | () , ( A ) , ( A,B ) , ( A,B,C ) |
| rollup(A,(B,C) | 3种 | () , ( A ) , ( A,(B,C) ) |
select
null as name
,avg(age) as avgage
,avg(score) as avgscore
,sex
,class
,from_province
,from_city
from stu group by
rollup (sex,from_province,from_city,class);
分组共分成5组,分别如下
1: null
2: sex
3: sex , from_province
4: sex , from_province , from_city
5: sex , from_province , from_city , class
![]()
7.2 分组函数:cube
假设有n个维度,那么cube会有2n个聚合,如:
| cube(A,B) | 3种 | () , ( A ) , ( B ) , ( A,B ) |
| cube(A,B,C) | 4种 | () , ( A ) , ( B ) , ( C ) , ( A,B ) , ( A,C ) , ( B,C ) , ( A,B,C ) |
| cube(A,(B,C) | 3种 | () , ( A ) , ( (B,C) ) , ( A,(B,C) ) |
select
null as name
,avg(age) as avgage
,avg(score) as avgscore
,sex
,class
,from_province
,from_city
from stu group by
cube (sex,from_province,from_city,class);
分组共分成16组,分别如下
1: null
2: sex
3: class
4: class , sex
5: from_city
6: from_city , sex
7: from_city , class
8: from_city , sex , class
9: from_province
10: from_province , sex
11: from_province , class
12: from_province , sex , class
13: from_province , from_city
14: from_province , sex , from_city
15: from_province , class , from_city
16: from_province , sex , class , from_city
![]()
7.3 分组函数:grouping sets
select
null as name
,avg(age) as avgage
,avg(score) as avgscore
,sex
,class
,from_province
,from_city
from stu group by
grouping sets (sex
,from_province
,from_city
,class
,(from_province,from_city)
,(sex,class)
,(sex,class,from_province,from_city)
);
分组共分成7组,分别如下
1: sex
2: from_province
3: from_city
4: class
5: from_province , from_city
6: sex , class
7: sex , class , from_province , from_city
![]()
7.4 grouping 函数调用分组
在分组函数中分的组,可用二进制进行表示。如在7.2 中的cube (sex,from_province,from_city,class);
可以映射成下表:

因此上述的grouping sets可以修改成如下代码:
select
null as name
,avg(age) as avgage
,avg(score) as avgscore
,grouping (sex,from_province,from_city,class) as groupnum
,case grouping (sex,from_province,from_city,class)
when 14 then 'class'
when 13 then 'from_city'
when 11 then 'from_province'
when 7 then 'sex'
when 9 then '(from_province,from_city)'
when 6 then '(sex,class)'
else 'all' end as group_type
,sex
,class
,from_province
,from_city
from stu group by
grouping sets (sex
,from_province
,from_city
,class
,(from_province,from_city)
,(sex,class)
,(sex,class,from_province,from_city)
);
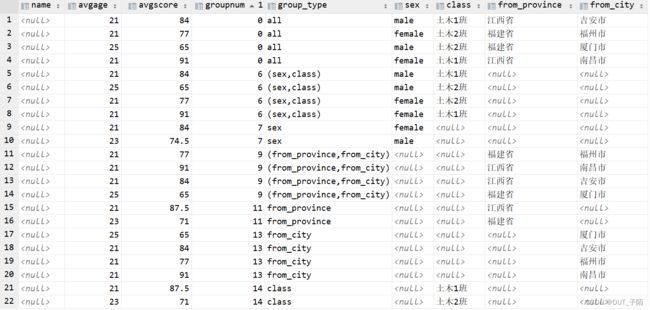
![]()
7.5 Hive中执行
有两个注意点:
- 使用group__id获取分组,且使用哪个分组,group__id的值就为多少
- group by 后面必须跟上分组字段,然后再接分组函数
select
avg(age) as avgage
,avg(score) as avgscore
--grouping__id获取根据sets中的哪一个进行分组
,grouping__id as group_num
,case when grouping__id =1
then 'sex'
when grouping__id =2
then 'class'
when grouping__id =3
then 'all'
end as group_type
,sex
,class
from stu group by sex,class
grouping sets (sex,class,(sex,class));