mysql 查找相似数据_MySQL慢查询优化 | 联结原理
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源![]()




前段时间笔者开发某个项目遇到了MySQL性能问题,每张表的数据量都在五千万以上,个别表数据量甚至在一个亿以上,在开发的过程中遇到了非常多的数据库性能优化难点,笔者在开发过程中查询了很多资料,很多查询语句也在优化过程中取得了比较好的效果。笔者也将开发过程中遇到的sql优化问题总结为文章,以便日后回顾。这篇文章主要讲解mysql执行联结运算的原理。为了避免泄露公司业务及数据,在文章中涉及的sql语句都和公司业务无关。
1. Simple Nested Loop Join
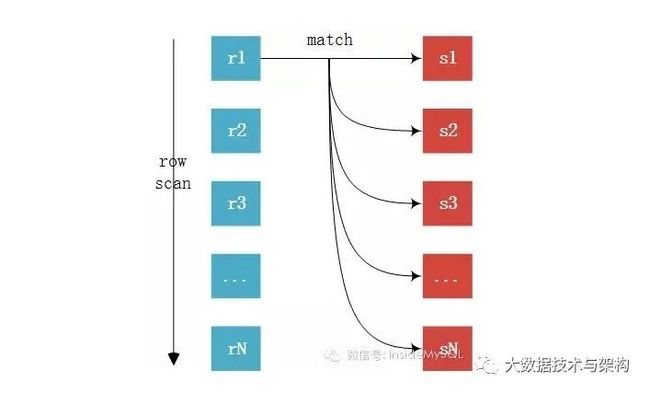
在联接计算时候,Mysql会以某张表作为驱动表,利用驱动表中的每一条数据到关联表中根据联接条件查询数据,如下图r表联结s表,mysql会以r表中每一条数据关联计算s表。这种联结查询开销很大,如果r表有M条数据,s表有N条数据,那么匹配总数是MN次。这种关联方式性能最差,尤其是深分页联结计算。
2. Index Nested Loop Join
在A表关联B表的时候,如果B表的关联字段上存在索引,mysql就会在索引上判断联接条件,如果联接条件满足,那么就从索引列拿到rowid,然后回表查找想要的列,回表数据查找是随机IO的过程,并且每次只能对一个rowid进行回表查找数据。在谈Index Nested Loop Join回表查询优化之前,笔者先了解了下MRR机制,看如下sql语句,其中price列存在索引
select * from tb_book_base where price > 15 limit 1000,20;
Mysql在执行上述语句的时候,首先会根据索引列获取rowid,再根据rowid回表查询基础信息,这样查询和Index Nested Loop Join一样存在回表随机IO的问题,mysql的MRR机制可以优化性能,原理如下:
Mysql根据price列条件从索引列拿到rowid后不立即回表查找数据行,而是缓存在一个buffer,当缓存的buffer rowid达到一定数量的时候,再进行回表,回表之前我们将buffer中rowid先进行排序,如此一来我们就能将完全的随机IO优化为顺序跳跃IO,因为顺序跳跃IO仍然有机会能利用操作系统预读的磁盘块,所以性能要优于随机IO。MySQL中这种优化方式称为MRR,其中的rowid buffer称为read_rnd_buffer。如果我们需要使用mrr机制,需要将mrr_cost_based参数设置为false

如果mysql使用了MRR机制会在Extra列中显示该信息

但是遗憾的是MRR机制根据索引列查询必须是范围查询,between,因为只有范围查询才能获取一批rowid,笔者也想到如果获取价格为15元的图书信息(=查询),因为价格为15元的图书不止一本,也能获取一批rowid,mysql是否还能使用MRR机制呢,笔者进行了实验,发现mysql并没有使用MRR机制

只能对索引进行范围查找是MRR的缺陷,于是又有了BKA优化,batch key access join是mysql 5.6提出优化方案,它在关联查询中获取一批rowid,然后将这批rowid进行排序,再回表查找,它将随机IO转换成了顺序跳跃IO。举一个具体的例子,如果R表关联S表, 并且mysql选择了R表作为驱动表,如果想利用BKA优化,关键在于选取一批rowid,mysql会选取R表中一批数据行存放在join_buffer,然后利用索引查到S表rowid关联S表,获取到一批S表rowid,将rowid排序再回S表查询。BKA算法默认关闭,需要通过如下参数打开
比如我们执行如下sql,查询某本书的相关的作者,翻译,出版社信息,如果使用BKA算法,那么在Extra列中会显示

3. Blocked Nested Loop Join
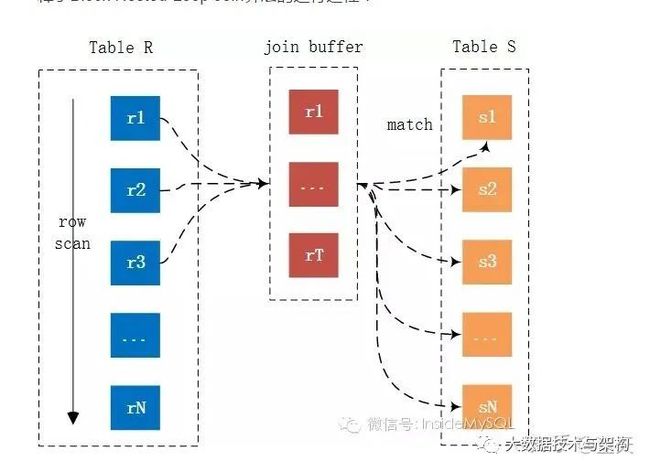
存在索引的时候,mysql会使用Index Nested Loop Join,但是有时候关联表的关联列可能不存在索引,此种情况下,如果Mysql使用Simple Nested Loop Join每次都用一条驱动表数据与关联表比对计算,那么性能会非常差。Mysql针对不存在索引的情况进行了一些优化。优化算法如下:mysql将驱动表的关联字段列缓存起来(避免回表查找),放在join buffer当中,然后批量与关联表每条数据比较,需要注意的是mysql在执行Blocked Buffer Join的时候,mysql不仅仅将驱动表的关联列放到join buffer中,同时也会将select列放到join buffer中,目的是避免回表查找以提高性能。下图概述了上述Blocked Nested Loop Join原理
如果mysql使用了join buffer,explain命令的Extra列会显示该信息

Join Buffer 大小也可以通过如下命令查看
SHOW VARIABLES LIKE '%join_buffer_size%';3.1 缺陷
磁盘IO是性能杀手,一次磁盘IO需要接近10ms(5ms寻道时间,4ms旋转时间)。为了加快查询速度,避免磁盘IO,MySQL中有缓存热数据页的Buffer Poll。内存命中率是评估buffer pool的重要指标。有资料显示一个稳定服务的线上系统,要保证响应时间符合要求的话,内存命中率需要达到99%。我们可以通过如下命令查看内存命中率,其中buffer pool hit 表示内存命中率。
Show engine innodb status
BNL确实能够优化联结查询,但是BNL算法会扫描非常多关联表的行数,如果BNL算法多次扫描一个大的关联冷表,冷数据页会不断的加载进入Join Buffer,因为Join Buffer大小也是有限制的,那么热数据页就会被替换出Join Buffer,所以大冷表BNL 联结不仅仅会加大磁盘IO压力,同时BNL会对Buffer Pool造成持续性影响,要想提高内存命中率只能依靠后续的请求慢慢恢复。
4. MySQL不支持的Join
除了上述的三种join 方式,还有Hash Join和Merge Join两种常用的Join方式,但是MySQL并不支持这两种Join方式,笔者学习之后,觉得也有必要将资料进行整理,以便日后学习回顾。
4.1 Hash Join
看到Hash Join笔者想起了HashSet,HashSet可以在O(1)时间内判断某个值是否存在于集合中,原理是利用hashCode定位到指定的哈希桶,发生碰撞时,再取出链表逐一比对(碰撞时时间复杂度降为O(N))。Hash Join利用的也是相似的原理,比如R表联结S表,mysql会选取较小的表的关联键join key在内存中建立散列表,然后利用大表中的每一条记录探测散列表。但是内存可能会不足,不能完全放下小表散列键,数据库会利用一个hash函数将R表和S表分割成不同的分区,比如R表被切分为R1,R2,R3,S表被切分为S1,S2,S3,然后R1和S1进行Hash Join,R2和S2进行Hash Join。需要注意的是Hash Join只能用于等值联结,而且hash join会涉及到散列函数会CPU的消耗会比较高,内存占用也会比较高,并且hash是无序的,所以输出结果也是无序的。
4.2 Merge Join
Merge Join只能对已经排过序的Join Key操作(索引),如果未排序,那么会先排序再操作,未排序时,开销会很大。举个例子如果R表的Join Key为[a,b,c,d,e],S表的Join Key为[a,c,d,e,f],数据库执行Merge Join时会随机选择一张表作为驱动表,如果选择了R表作为驱动表,当扫描到S表join key 为a的时候则匹配,然后当扫描S表join key = c的时候,再以S表=c处作为驱动表扫描R表,此时会从R表的值为b的位置开始扫描,Merge Join整体时间复杂度是O(max(n1,n2))。注n1,n2分别为R表S表的长度
5. 驱动表优化
文末笔者还想谈一谈表联结中驱动表。Mysql联接优化的目标是尽可能减少nested loop join 总数,关联查询时候,必须以某张表作为驱动表。我们可以使用explain命令查看mysql到底使用了哪张表作为驱动表?Explain第一行显示的表就是驱动表。

mysql是如何选择驱动表的呢?mysql查询优化器优先选择小表作为驱动表,小表不仅仅指表的真实行数或者磁盘空间大小,也包括了两个表按照各自条件过滤后的表。比如上图,mysql使用tb_book_main作为驱动表,tb_book_main有4000万行数据,tb_book_base只有1000万行数据,但是mysql使用了tb_book_main作为驱动表,原因就在于mysql是用过滤条件后的结果集判断表大小,经过`code`= '0413558924'条件比对后的tb_book_main表小于tb_book_base。
但是mysql查询优化器有时候会判断出错,选择了大表作为驱动表。或者因为另外一种情况,MySQL使用了小表作为驱动表,但是索引位于大表上,这可能会造成using temporary,file sort的情况,看如下这个实例
SELECT
t1.`isbn`,
`title`,
`sub_title`
FROM
`tb_book_base` t1
INNER join
`tb_book_main` t2 ON t1.`isbn` = t2.`isbn`
WHERE
t2.`code` = ( SELECT `code` FROM tb_book_press WHERE `name` = '6215981117' )
AND t1.publish_time > 20150101
ORDER BY
t1.`publish_time`;上述这个例子,mysql判断经过条件筛选之后的t2表要比t1表小,所以mysql选择t2表作为驱动表,因为mysql只会使用驱动表上的索引,索引mysql不会使用t1表的publish_time索引,这会造成磁盘排序,sql语句的性能会很差,我们可以通过Explain证实上述的判断
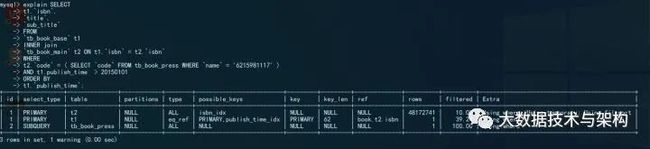
如果我们需要使用大表上的索引帮助排序,所以我们需要手动指定驱动表。我们可以通STRAIGHT_JOIN语法
SELECT
t1.`isbn`,
`title`,
`sub_title`
FROM
`tb_book_base` t1 FORCE INDEX (`publish_time_idx`)
STRAIGHT_JOIN `tb_book_main` t2 ON t1.`isbn` = t2.`isbn`
WHERE
t2.`code` = ( SELECT `code` FROM tb_book_press WHERE `name` = '6215981117' )
AND t1.publish_time > 20150101
ORDER BY
t1.`publish_time`;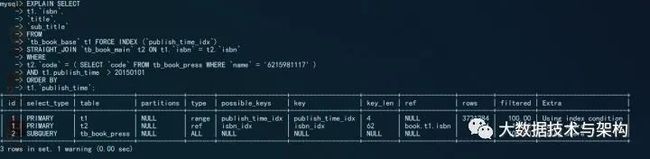


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。 编辑|冷眼丶 微信公众号|import_bigdata 欢迎点赞+收藏+转发朋友圈素质三连
文章不错?点个【在看】吧!