数据结构——时间复杂度与空间复杂度
目录
一.什么是空间复杂度与时间复杂度
1.1算法效率
1.2时间复杂度的概念
1.3空间复杂度的概念
二.如何计算常见算法的时间复杂度
2.1大O的渐近表示法
使用规则
三.如何计算常见算法的空间复杂度
3.1 大O渐近表示法
3.2 面试题——消失的数字
3.3 面试题——旋转数组
一.什么是空间复杂度与时间复杂度
1.1算法效率
分为两种,一种是时间效率,又称时间复杂度,主要衡量算法的运行速度。另一种是空间效率,称空间复杂度,衡量算法所需要的额外空间。
1.2时间复杂度的概念
简单来说,算法中的基本操作的执行次数,就是算法的时间复杂度。
1.3空间复杂度的概念
空间复杂度是对一个算法运行过程中临时占用储存空间大小的量度。一般使用大O渐近表示法表示。
二.如何计算常见算法的时间复杂度
2.1大O的渐近表示法
//实例一.请计算一下Func1基本操作执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}我们可以知道准确的次数应该是N*N(每一次循环中嵌套循环都会循环N次,共N次循环所以是N*N次)+2*N(只循环2*N次)+10
这时候就会有关系:
令F(N)=N*N+2*N+10
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010
注意点:
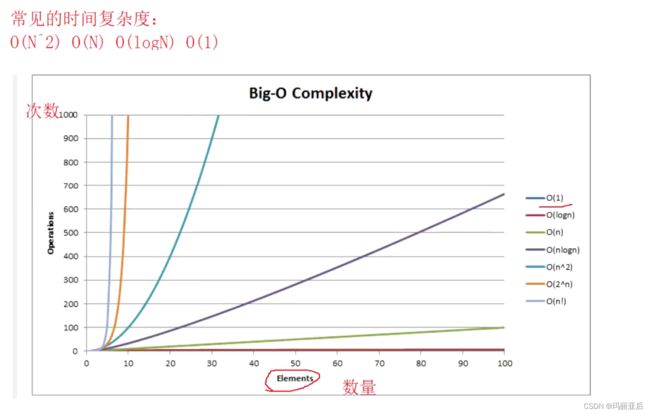
- 随着N的增大,这个表达式中N^2对结果的影响是最大的。
- 时间复杂度是一个估算,是去看表达式中影响最大的那一项。
- 大O的渐进表示法,估算时间复杂度:O(N*2)。
使用规则
- 用常数1取代运行时间中的所有加法常数。
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
//实例二,计算Func2的时间复杂度
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
结果是O(N),准确是2*N+10,之所以忽略2是因为随着N无限增大,2已经无法过多影响N。
//实例三.计算Func3的时间复杂度
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}O(M+N)毕竟2个未知数 但如果有条件说M远大于N,那么结果就为O(M)
如果条件是M与N差不多,那么结果为O(N)或O(M)。
//实例四.计算Func4的时间复杂度
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}O(1) 只要是确定的常数次,都是O(1)
//实例五.计算strchr的时间复杂度
const char* strchr(const char* str, char character)
{
while (*str != '\0')
{
if (*str == character)
return str;
++str;
}
return NULL;
}相当于在一个字符数组中查找字符 。假设字符串长度是N,在下面字符串中找到字符’s‘,'d','x'的运行次数都是不一样的。
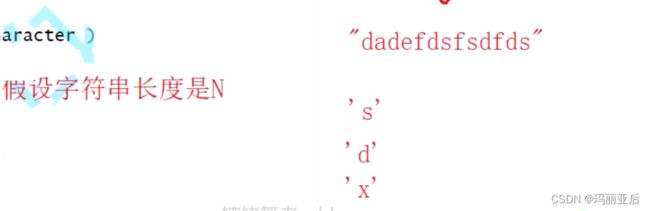
我们会发现有多种情况:
- 最坏情况:任意输入规模的最大运行次数(上界)
- 平均情况:任意输入规模的期望运行次数
- 最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所有数组中搜索数据时间复杂度为O(N)
//案例六.计算BubbleSort的时间复杂度
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}怎么说呢,有点抽象吧。毕竟这个不是像之前一样纯看代码,这一次是需要靠自己的理解把抽象代码具体化,就比如本质是冒泡排序,那我们就假想冒泡每一次执行的过程是怎么样的。
如数组arr[5]={0,1,2,3,4},0要换到4处最坏情况是4次(1,2,3,4,0),1换到3处最坏情况是3次,以此类推最后一个数为4时反而不用换了次数是0。
如下图所示。(为方便理解这里把N-1~0换成N~1)
可以看到在列出所以结果后发现这是一个等差数列,最终我们用求和方式求出准确次数。再进行估算后得出O(N^2)
//案例七.计算BinarySearch的时间复杂度
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n;
while (begin < end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid;
else
return mid;
}
return -1;
}这是一个经典的二分查找案例,如果不懂其内核的友友们可以移步这篇文章:
二分查找详解
这里我们可以把这个数组想象成一张纸,里面的N个数想象成长度为N的纸,然后进行不断的折半,不断折半,这样折半X次后,要么找到了,要么找不到。最后我们再把它还原回去。
通过这样,我们得出了一个表达式:


//案例八.计算阶乘递归Factorial的时间复杂度
long long Factorial(size_t N)
{
return N < 2 ? N : Factorial(N - 1) * N;
} 
每次递归运算都是常数次,又因为递归调用N次,所以就是O(N)了。
//案例九.计算斐波那契递归Fib的时间复杂度
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}执行次数像一个金字塔一样,1变2,2变3,次数不断乘2.

可以看出最终的时间复杂度是一个等比数列求和公式
时间复杂度:O(2^N)
三.如何计算常见算法的空间复杂度
3.1 大O渐近表示法
//案例一.计算BubbleSort的空间复杂度
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
} 
我们可以发现一共有5个变量,相当于开辟了5个空间,这样一来:O(1),因为5是常数。
在循环中走了N次,重复利用的是一个空间,只不过是变量出去会销毁,但空间不会。时间是累计的,空间不是累计。
//案例二.计算Fibonacc1的空间复杂度
long long* Fibonacc1(size_t n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
} 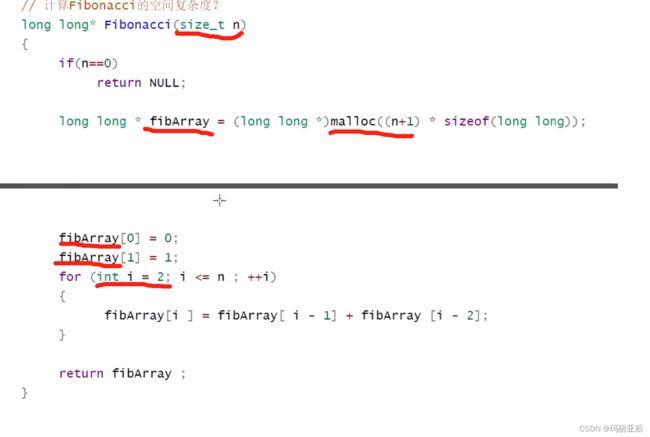
我们可以知道准确的空间复杂度有O(N+6) 但实际是O(N)
其中malloc表达的含义是连续开辟了n+1的long long类型的数组。
//案例三.计算阶乘递归Factorial的空间复杂度
long long Factorial(size_t N)
{
return N < 2 ? N : Factorial(N - 1) * N;
} 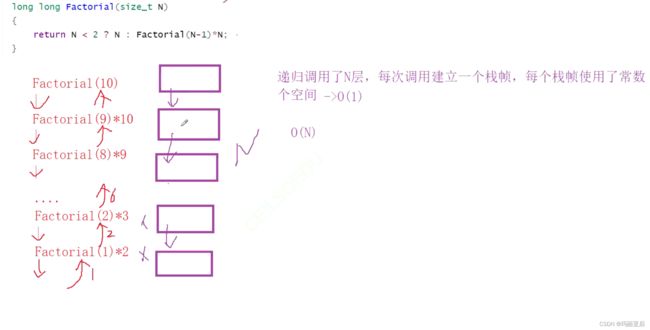
虽然最后会销毁,但空间复杂度计算的是累计最多使用的空间大小。
//案例四.计算斐波那契递归Fib的空间复杂度
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
} 我们已经知道时间复杂度是O(2^N)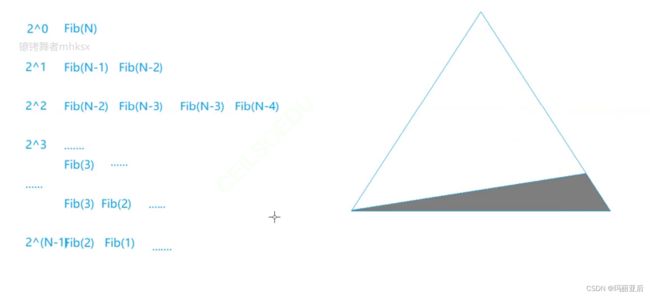
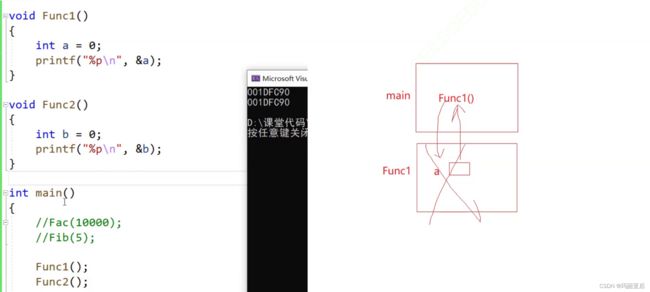
我们先来用栈帧图来表示:
一开始main开辟空间里面调用了Func1,Func1也会开辟空间存储变量a,结束后这个空间就销毁了。接着又有Func2的调用,之所以能够复用Func1的空间是因为它们都是类似的,都是创造一个int整型的变量(与值无关)。这就是地址相同的原因。
备注:两个函数的地址是不一样的,函数地址跟栈帧是没有关系的!
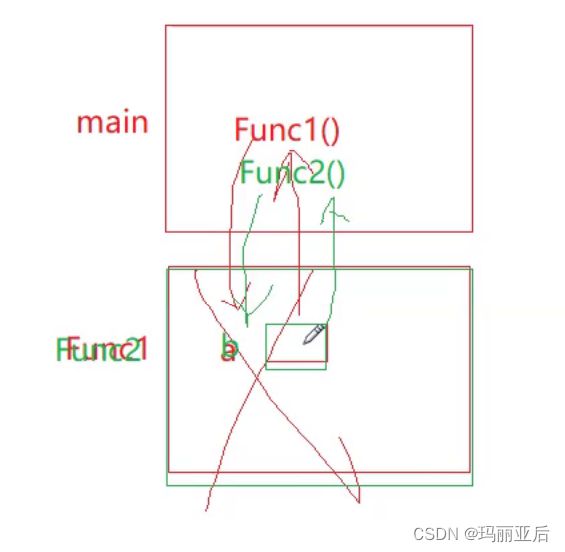
在开辟空间的时候并不会Fib(N-1)和Fib(N-2)同时调用开辟,而是优先顺着Fib(N-1)往下继续开辟空间,直到往下调用到Fib(2)时开始回归,这时候Fib(2)的空间虽然销毁了,但是只是把空间权限交还给了系统,当递归来到Fib(3)又会调用Fib(2)和Fib(1),而这时候Fib(2)并不会重新开辟出新的空间,而是前往之前已经销毁的空间,相当于系统又重新把该处空间的开放权限交给了Fib(2),所有顺着箭头我们会发现左侧都是已经开辟好的空间,一共有N处,这里的N处相当于一次性深入最多开辟的空间数,当递进完成需要销毁该处空间,回归调用遇到曾经已经开辟(销毁)过的空间时又重新使用这个空间。
换一种说法就是:酒店开了10间房,遇到Fib(2)递进结束开始往上回归时,相当于退房了。但房间还是在的,Fib(2)结束后就要调用Fib(1).而Fib(1)住进的房间就是Fib(2)退出的房间。
本质还是最多房间数代表一次递进所达到的最深程度,后面的都是重复利用罢了。不断的退房,开房,直到所有人都退房的时候也就代表着递归结束了。
时间是累积的,一去不复返,但空间是可以重复利用的。因此空间复杂度为O(N)

3.2 面试题——消失的数字
原题链接:力扣——消失的数字


排序+遍历:下一个数不等于下一个数据+1,这个下一个数就是消失的数字), 不过光排序(qsort)就花了很长时间了。

时间复杂度为O(N)
int missingNumber(int* nums, int numsSize)
{
int N = numsSize;
int i = 0;
int ret = N * (N + 1) / 2;
for (i = 0; i < N; i++)
{
ret -= nums[i];
}
return ret;
} 
异或特点:先把二进制表示出来,然后相同为0,相异为1。无论什么数,相同的数异或就没了。

重点是不需要顺序。

int missingNumber(int* nums, int numsSize)
{
int i = 0;
int j = 0;
int x = 0;
int N = numsSize;
for (i = 0; i < N; i++)
{
x ^= nums[i];
}
for (j = 0; j <= N; j++)
{
x ^= j;
}
return x;
}3.3 面试题——旋转数组
原题链接:力扣——旋转数组


把最后一个元素放在tmp中,前面数组元素全部往右移,再把tmp放到第一位,以此类推。
至于它的时间与空间复杂度是有说法的,右旋一次执行N次,那右旋K次应该是K*N次才对。
可是这是旋转数组,你右旋0次与右旋7次结果是一样的,所以k也分情况,最好的是只右旋了0次,最坏是右旋N-1次(第N次就又进入了轮回),所以时间复杂度也被分为O(1)与O (N^2),按照规则我们取最坏情况O (N^2)。
故该方法不符合条件,pass~。附上代码:
void rotate(int* nums, int sumsSize, int k) { int N = sumsSize; if (k >= N) { k %= N; } while (k--) { int tmp = nums[N - 1]; for (int end = N - 2; end >= 0; end--) { nums[end + 1] = nums[end]; } nums[0] = tmp; } }



void rotate(int* nums, int sumsSize, int k)
{
int N = sumsSize;
int* tmp = (int*)malloc(sizeof(int) * N);//开辟与原数组空间同样大小的新数组
k %= N;
memcpy(tmp, nums + N - k, sizeof(int) * k);//把原数组中从下标第N-k开始拷贝k个
memcpy(tmp, nums, sizeof(int) * (N - k));//把原数组从下标为0开始拷贝N-k个
memcpy(nums, tmp, sizeof(int) * N);//把tmp数组中所有的k个元素都拷贝回nums中去
free(tmp);//释放空间
tmp = NULL;//置空
}
就是一次性挪好几个,把后k个拷贝到新数组里,再把前N-k个2拷贝到新数组,最后再把新数组一起拷贝回去,以空间换时间,但还是老问题,如果数组太大,空间可能达不到要求。

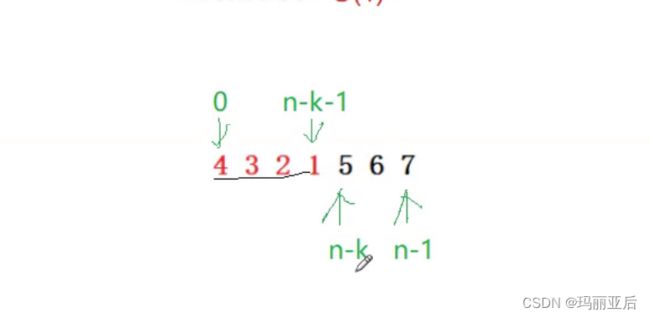
最妙的方法!!!
void Reverse(int* nums, int left, int right)
{
while (left < right)
{
int tmp = nums[left];
nums[left] = nums[right];
nums[right] = tmp;
left++;
right--;
}
}
void rotate(int* nums, int sumsSize, int k)
{
int N = sumsSize;
k %= N;
Reverse(nums, 0, N - k - 1);
Reverse(nums, N-k, N - 1);
Reverse(nums, 0, N-1);
}四.结语
关于复杂度的讲解就此结束,希望可以帮助到大家理解。另外由于学校的课程紧张,我会停更一段时间的C语言专栏,目前先把数据结构搞定~