用Python分析《红楼梦》:见证了贾府的兴衰,你是否还能“笑道”世事无常
没读过《红楼梦》也能知道前后四十回是不是一个作者写的?很久以前,数据侠黎晨,用机器学习的算法分析了《红楼梦》,认为后四十回和前八十回内容上有明显差距。不过,数据侠楼宇却不这么认为,他觉得原先的判定方法不够严谨,于是他使用了无字典分词的方式,剔除了情节对分析的影响,再次用机器学习的算法分析了这部文学名著。
本文授权转自DT数据侠(ID:DTdatahero)
作者 | 数据侠楼宇
▍构建全文索引与全文字典
两个月以来,我通过互联网自学了一些文本处理的知识,用自然语言处理和机器学习算法对《红楼梦》进行了一些分析。这个过程中我找到了一些有趣的发现。
我开始做这件事情是因为之前看到了一篇挺好玩的文章,大概内容是,作者用“结巴分词”这个开源软件统计了红楼梦中各词汇的出现次数(也就是词频),然后用词频作为每个章回的特征,最终用“主成份分析”算法把每个章回映射到三维空间中,从而比较各个章回的用词有多么相似。(DT君注:数据侠黎晨原文《从没看过红楼梦,如何用机器学习判定后40回并非曹雪芹所写》)作者的结论是后四十回的用词和前八十回有明显的差距。
我觉得文章有两个小问题:首先,作者用的结巴分词里的词典是根据现代文的语料获得的,而《红楼梦》是半文半白的,这样的分词方法准确性存疑;其次,虽然作者用《三国演义》做了对比,但是依然没有有力地证明用词差异没有受到情节变化的影响。于是我决定自己做一遍实验,用无字典分词的方法来分词,并且尝试剔除情节对分析的影响,看看结果会不会有所不同。
在处理文章之前,我需要建立一个全文索引。这样是为了快速地查找原文内容,加速后面的计算。我使用了后缀树这个结构作为索引,用了Ukkonen算法快速地创建了整篇《红楼梦》的后缀树(Ukkonen 算法的速度非常快,用专业的语言描述,它的时间复杂度是 O(n))。这样我们就有了全文索引了。
接下来我们就要构建一个字典了。
等等,我们不是要无字典分词吗,为什么还要制作字典?其实无字典分词并不是完全不用字典,只是说字典是根据原文生成的,而不是提前制作的。为了进行分词,我们还是需要先找出文章中哪些内容像是单词,才能确定如何进行切分。
那么怎么确定哪些内容像单词呢?最容易想到的方法就是:把所有出现次数高的片段都当成单词。听上去很有道理,所以我们可以试一试,用后缀树查询红楼梦中的所有重复的片段,然后按出现次数排个序:
宝玉(3983)、笑道(2458)、太太(1982)、什么(1836)、凤姐(1741)、了一(1697)、贾母(1675)、一个(1520)、也不(1448)、夫人(1437)、黛玉(1370)、我们(1233)、那里(1182)、袭人(1144)、姑娘(1142)、去了(1090)、宝钗(1079)、不知(1074)、王夫人(1061)、起来(1059)
上面是出现频率前20的片段,括号内是出现次数。可以看到效果还不错,很多片段都是单词。然而,排在第六名的“了一”明明不是个单词,出现次数却比贾母还要高。可见这样的筛选方法还是有一定问题的。而且,这样被误当成单词的片段还有很多,例如“了的”、“的一”之类的。
为了排除这样的组合,我们可以用“凝固度”来进行进一步地筛选。凝固度可以排除单字的频率对组合频率的影响。经过实验,我发现整体效果还是不错的。
DT君注:凝固度指的是,一个片段出现的频率比左右两部分分别出现的频率的乘积高出多少倍。值得注意的是,频率表示的是出现的比例,而频数表示的是出现的次数。凝固度的思想是,如果片段实际出现的概率比被随机组合出来的概率高出很多倍,就说明这样的组合应该不是意外产生的,而是有一些关联的。这个关联很可能就是因为这个片段是一个不可分割的整体,也就是单词。
然而凝固度也有一定的问题。我们会发现还是有很多片段是半个词,且也具有很高的凝固度。例如:“香院”(完整的词应该是“梨香院”)、“太太太太”(完整的词应该是“老太太太太”)。
想想也有道理,这些片段虽然是半个词,但是它们确实也跟完整的单词一样是“凝固”在一起的。所以,光看凝固度是不够的,还要通过上下文判断这个词是否完整。
为了排除掉不完整的单词,我们可以使用自由度来继续过滤,自由度描述的是一个片段相邻的字有多么的不固定,一个真正的词应该相互之间的联系应
该是独特的,不太会出现上文说的情况。也就是说如果片段的自由度比较高,就说明这个词应该是完整的。
DT君注:自由度的思想是,如果一个组合是一个不完整的单词,那么它总是作为完整单词的一部分出现,所以相邻的字就会比较固定。比如说,“香院”在原文中出现了 23 次,而“梨香院”出现了 22 次,也就是说“梨”在“香院”的左边一起出现的频率高达 95.7%,所以我们有把握认为”香院”不是完整的单词。而自由度描述的就是一个片段的相邻字有多么的多样、不固定。
有了这些明确的评判标准,我们就可以把单词筛选出来了。我最终选择的判断标准是:出现次数大于等于5,且凝固度、左侧自由度、右侧自由度都大于1。然而这个标准还是太宽松了。于是,我又设计了一个公式,把这些数据综合起来:
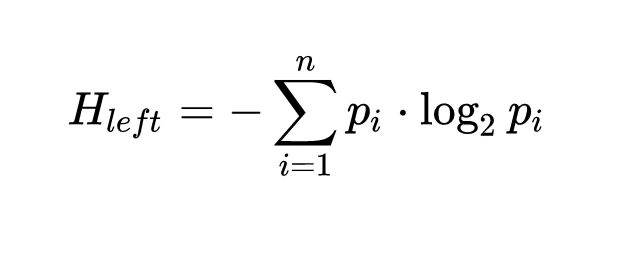
也就是说,我简单粗暴地把凝固度和自由度乘了起来,作为每个片段的分数。这样只要其中一个标准的值比较低,总分就会比较低。于是我的判断标准里又多了一条:总分还要大于等于100。
经过层层遴选之后,单词表初步成型了。我从最终结果中随机抽取了100个条目,其中有47个是希望得到的单词:这意味单词表的正确率只有一半左右。不过,在错误的条目里,很多条目的切分其实是正确的,只是有好几个词粘到了一起。所以其实我们没有必要通过调高筛选标准的方法来进行更严格的过滤了。随后分词算法将会解决单词没有被切开的问题。
此外,根据字典的正确率和字典的大小,我计算出红楼梦的词汇量大概是 1.6 万。
▍维特比算法找出最具效率的分词方案
之前在筛选单词的时候,思路就是用各种各样的数值标准进行判断。而对于“分词”这个看似更加困难的问题,思路也是类似的:制定一个评价切分方案的评分标准,然后找出评分最高的切分方案。
评分标准是什么呢?最简单的标准就是,把切分之后每个片段是单词的概率都乘起来,作为这个切分方案正确的概率,也就是评分标准。我们假设,一个片段是单词的概率,就是这个片段在原文中的出现频率。
有了评分标准之后,还有一个问题:如何找出分数最高的切分方案呢?肯定不能一个一个地尝试每一种方案,不然速度实在是太慢了。我们可以用一个数学方法来简化计算:维特比算法。
维特比算法本质上就是一个动态规划算法。它的想法是这样的:对于句子的某个局部来说,这一部分的最佳切分方案是固定的,不随上下文的变化而变化;如果把这个最佳切分方案保存起来,就能减少很多重复的计算。我们可以从第一个字开始,计算前两个字,前三个字,前四个字……的最佳切分方案,并且把这些方案保存起来。
因为我们是依次计算的,所以每当增加一个字的时候,我们只要尝试切分最后一个单词的位置就可以了。这个位置前面的内容一定是已经计算过的,所以通过查询之前的切分方案即可计算出分数。
在构造单词表的时候,我计算了每个片段有多么像单词,也就是分数。然而,后面的分词算法只考虑了片段出现的频率,而没有用到片段的分数。于是,我简单粗暴地把片段的分数加入到了算法中:把片段的频率乘上片段的分数,作为加权了的频率。这样那些更像单词的片段具有更高的权重,就更容易被切分出来了。
还有一个小优化。我们知道,一般中文单词的长度不会超过四个字,因此在程序枚举切分方法的时候,只需要尝试最后四个切分位置就可以了。这样就把最长的切分片段限制在了四个字以内,而且对于长句子来说也减少了很多不必要的尝试。
抽查程序运行结果后发现,最终程序分词算法的准确率是85.71%(意义是程序切开的位置有多少是应该切开的),召回率是75.00%(意义是应该切开的位置有多少被程序切开了)。这个结果看上去不是很高,因为大部分开源的分词软件准确率都能达到90%以上,甚至能达到97%以上。不过,毕竟我用的是无字典的分词,而且算法也比较简单,所以我还是比较满意的。
但是其中诗词的分词更难一些,准确率相比其他部分低了10%左右。这也在情理之中,因为诗词中有很多不常用词,有些词甚至只出现过一次,所以电脑很难从统计数据中发掘信息。
▍统计结果说:贾府的人很爱“笑”
完成分词以后,词频统计就非常简单了。我们只需要根据分词结果把片段切分开,去掉长度为一的片段(也就是单字),然后数一下每一种片段的个数就可以了。
这是出现次数排名前20的单词:
宝玉(3940)、笑道(2314)、凤姐(1521)、什么(1432)、贾母(1308)、袭人(1144)、一个(1111)、黛玉(1102)、我们(1068)、王夫人(1059)、如今(1016)、宝钗(1014)、听了(938)、出来(934)、老太太(908)、你们(890)、去了(879)、怎么(867)、太太(856)、姑娘(856)
通过分词后的词频,我们发现《红楼梦》中的人物戏份由多到少依次是宝玉、凤姐、贾母、袭人、黛玉、王夫人和宝钗。然而,这个排名是有问题的,因为”林黛玉”这个词的出现次数还有267次,需要加到黛玉的戏份里,所以其实黛玉的戏份比袭人多。
同理,“老太太”一般是指贾母,所以贾母的戏份加起来应该比凤姐多。正确的排名应该是宝玉、贾母、凤姐、黛玉、袭人、王夫人和宝钗。
此外,我们还发现《红楼梦》中的人物很爱笑,因为除了人名以外出现次数最多的单词就是“笑道” : )
我把完整的词频表做成了一个网页,感兴趣的话可以去看一下:红楼词表。
终于做完了分词,又离目标靠近了一大步。现在,我可以用之前看到的那篇文章里提到的PCA算法来分析章回之间的差异了。不过在此之前,我想先反思一下,到底应该用哪些词的词频来进行分析?
在很多用PCA分析《红楼梦》的博文里,大家都是用出现频率最高的词来分析的。然而问题是,万一频率最高的词是和情节变化相关的呢?为了剔除情节变化的影响,我决定选出词频随情节变化最小的单词来作为每一章的特征。而我衡量词频变化的方法就是统计单词在每一回的词频,然后计算标准方差。为了消除单词的常用程度对标准方差的影响,我把标准方差除以该单词在每一回的平均频数,得到修正后的方差,然后利用这个标准来筛选特征词。
最终,我选择了词频变化最小的50个词作为特征,每个词的修正后标准方差都小于0.85。理论上,有了特征之后,我们就可以比较各个章节的相似性了。然而问题是,现在我们有50个特征,也就是说现在的数据空间是 50 维的,这对于想象四维空间都难的人类来说是很难可视化的。对于高维数据的可视化问题来说,PCA是一个很好用的数学工具。
我利用PCA,把五十个词的词频所构成的五十个维度压缩到二维平面上。把压缩后的数据点画出来,发现是这个样子:

∆ 图中每个圆圈代表一个回目。圆圈内是回目编号,从 1 开始计数。红色圆圈是 1-40 回,绿色圆圈是 41-80回,蓝色圆圈是 81-120 回。
八十回以后的内容(蓝色)大部分都集中在左下角的一条狭长的区域内,很明显地和其他章回区分开来了!莫非《红楼梦》的最后 40 回真的不是同一个作者写的?!
别着急,分析还没结束。PCA的一个很重要的优点就是,它的分析结果具有很强的可解释性,因为我们可以知道每一个原始特征在压缩后的特征中的权重。从上图中可以看到,后40回的主要区别在于成分二(component 2)的数值。因此我们可以看一看每一个词的词频在成分2中的权重排名(括号内为权重):
笑道(0.883)、我们(0.141)、一个(0.133)、你们(0.128)、两个(0.113)、说着(0.079)、咱们(0.076)、这个(0.063)、听了(0.052)、还有(0.046)、一面(0.045)、来了(0.037)、都是(0.032)、不过(0.028)、去了(0.027)、又不(0.025)、出去(0.021)、这样(0.018)、如今(0.016)、这里(0.016)、还不(0.011)、见他(0.011)、出来(0.010)、就是(0.010)、一时(0.008)、起来(0.005)、只见(0.002)、不是(0.002)、下回分解(0.000)、不得(-0.001)、也不(-0.001)、话说(-0.002)、的人(-0.005)、不知(-0.007)、那里(-0.009)、叫他(-0.011)、不敢(-0.011)、自己(-0.011)、不能(-0.017)、什么(-0.019)、所以(-0.020)、只是(-0.023)、知道(-0.026)、进来(-0.036)、说道(-0.046)、怎么(-0.050)、只得(-0.056)、没有(-0.077)、听见(-0.092)、宝玉(-0.312)
我发现,“笑道”这个词不仅是除了人名以外出现次数最多的单词,而且在PCA结果中的权重也异常地高(0.88),甚至超过了“宝玉”的权重的绝对值(0.31)!为了搞明白这个词为什么有这么大的权重,我把“笑道”的词频变化画了出来:
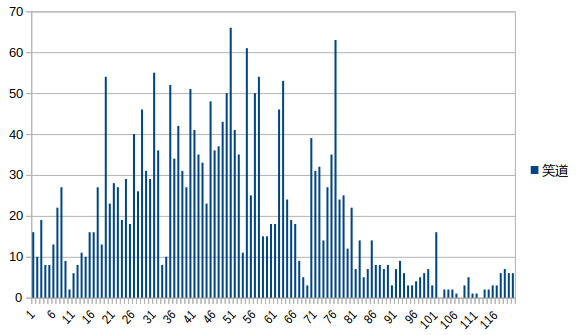
∆ 图中横坐标是章回编号,纵坐标是“笑道”的词频
可以发现,“笑道”的词频是先增加再减少的,这不禁让我联想到了贾府兴衰的过程。莫非“笑道”的词频和贾府的发展状况有关?
有趣的是,“笑道”的词频顶峰出现在第50回左右,而有些人从剧情的角度分析认为贾府的鼎盛时期开始于第48、49回,恰好重合。
也许“笑道”这一看似平常的词汇确实侧面反应了贾府的兴衰史呢。虽然因果关系有待考证,不过想想也有一点道理,毕竟只有日子过的好的时候人们才会爱笑。
“笑道”这个词似乎和情节的关系比较大,并且严重影响到了我们的分析。此外,“宝玉”作为一个人名,它的权重的绝对值也比较大,也可能是受到了情节的影响。因此,我决定把这两个词“拉黑”,用剩下的48个词的词频做特征,再次进行PCA分析。
我发现这样修改特征之后,后40回确实已经不像之前那么聚集了,不过还是可以看出一点聚集的趋势。这说明之前PCA结果确实因为“笑道”而受到了剧情的干扰。
而去掉“笑道以后四十回依然有聚集的趋势,说明去掉干扰后这些章回还是有一定的相似性的。所以,我有点把握认为《红楼梦》前八十回和后四十回的用词是有一些差异的。不过因为难以完全排除剧情的影响,所以我也还不敢下定论。
虽然没有完全解决红楼梦的作者是不是同一个人的问题,不过这个过程中误打误撞产生的发现也是挺有意思的,比如“笑道”的词频变化和贾府兴衰史的有趣重合。更重要的是,看似枯燥的数学公式可以做出这些好玩的分析。
Math is fun!
注:本文是作者《用Python分析红楼梦》文章的编辑版,文中图片均来自作者
本文数据侠楼宇,一位热爱技术的理工男。曾经的 OIer,现已退坑。同时也对机器学习、网页制作和摄影感兴趣。现在美国读本科。
猜你喜欢
详解 | 如何用Python实现机器学习算法
Python 3 尴尬了这么久,终于有救了
经验 | 如何高效学Python?
一文总结学习Python的14张思维导图
如何在Python中用LSTM网络进行时间序列预测
疯狂上涨的 Python,开发者应从 2.x 还是 3.x 着手?
2017年首份中美数据科学对比报告,Python受欢迎度排名第一,美国数据工作者年薪中位数高达11万美金
