坑爹,线上同步近 3w 个用户导致链路阻塞引入发的线上问题,你经历过吗?
分享一个印象深刻的线上问题,希望能够给 xdm 带来一点思考
一个稀松平常的工作日,正准备下班的时候,不巧,突发线上紧急问题,心中一万个不情愿,可还是要硬着头皮去定位问题
简单的表象为微服务之间 gRPC通信的通道默认是用了默认值,并没有按照实际业务去设置通道接受和发送的字节大小
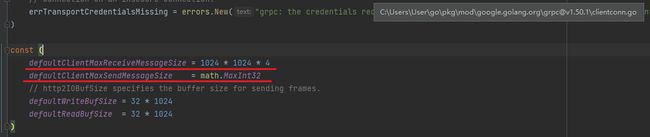
用过 golang grpc 通信的 xdm 就知道,grpc 通道默认的发送和接收的消息大小为 4M,由于传送的数据包大于了 4M,导致通道阻塞,一直报错 rpc 错误,
rpc error: code = ResourceExhausted desc = grpc: received message larger than max (6394324 vs. 4194304)
于是便有了一个定位并想办法解决或者规避问题的慢慢长夜
简述基本介绍通信流程
整个业务架构比较复杂,我们简单的提出出问题的服务链路来进行阐述
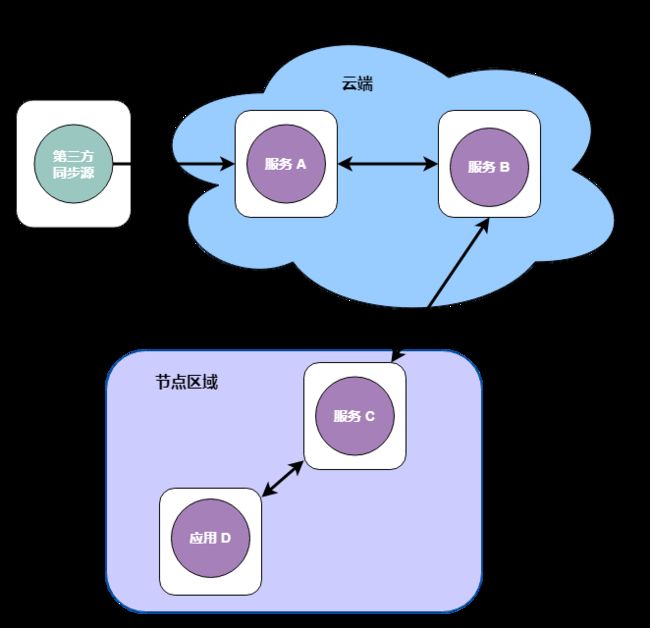
服务 A - 专门和第三方对接
有一个服务 A 是专门找第三方同步源读取第三方系统的用户组织结构,并转换成咱们平台自己的数据结构,将数据发送给 服务 B
服务 B - 专门处理用户相关数据
服务 B 专门处理关于用户组织结构数据的,处理完毕之后落盘,并将数据给到服务 C
服务 C - 主要做数据转发
服务 C 主要是做数据的通道,会将数据转发给到节点中的应用 D,因为 应用 D 和 服务 A 和 服务 B 没有办法直接通信
应用 D,处理处理实际的流量即管控
应用 D 接收或者去找 服务 C 拉取数据后做相应的业务,做基本的流量管控和用户认证等
其中上述两者之间都是通过 gRPC 的方式通信
问题 1 - rpc 通道发送和接收消息设置过小
万万没想到的是,在做第三方组织结构同步的时候,居然是服务 A 从第三方同步源中获取所有的用户组织结构(包括所有的组,所有的用户),不管总量多少,一口气全部弄过来,然后再一口气全部推给 服务 B
可这一次线上问题,正是因为这么 low 的做法和处理方式,导致超出了 gRPC 的默认消息大小 4M,显现就是服务 A 将数据发送给到服务 B 的时候,发送没有问题,但是服务 B 接收的时候出了问题,日志中疯狂打印上述的 rpc 错误
rpc error: code = ResourceExhausted desc = grpc: received message larger than max (6394324 vs. 4194304)
当然,这个时候不允许我们停下来去思考如何优化的事项,必须第一时间解决或者规避问题
立刻评估,将涉及到的服务,gRPC 的 send 和 receive 的地方全部统一修改为 32 M(1024102432) ,这个问题暂时得以规避
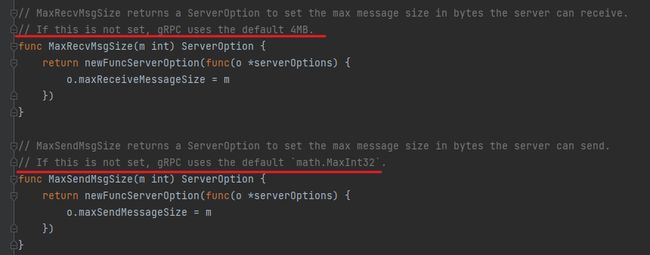
可以查看到 grpc 源码中的说明
MaxRecvMsgSize 接受消息 在 grpc 中默认大小为 $$ 4 M − − ( 1024 ∗ 1024 ∗ 4 ) = 2 22 4M --(1024*1024*4)= 2^{22} 4M−−(1024∗1024∗4)=222$$
MaxSendMsgSize 发送消息在 grpc 中默认是$$ M a x I n t 32 = 1 < < 31 − 1 也就是 4 M ∗ 2 9 − 1 即 2048 M = 2 G MaxInt32 = 1<<31 - 1 也就是 4M * 2^9 -1 即 2048 M = 2G MaxInt32=1<<31−1也就是4M∗29−1即2048M=2G$$
则在 grpc.NewServer 的时候,将上述的 option 加上去就可以了,例如这样
// 例如设置接收消息大小为 math.MaxInt32
var opts []grpc.ServerOption
opts = append(opts, grpc.MaxRecvMsgSize(math.MaxInt32))
newSvr := grpc.NewServer(opts...)
// grpc RegisterxxxxServer()
问题 2 - 组织结构同步的层级太小,不支持 16 层
本以为问题就这么规避了,然而还是太年轻

当服务 A 将数据全部打包发送到服务 B 的时候,才发现,原来问题才刚刚开始,由于数据量比之前测试过的数据量大了好几倍,导致各种问题接二连三的出来,这也体现了整个平台的健壮性太差
当前遇到的问题是服务 B 处理的组织结构层数,最大只能有 8 层,超过 8 层的数据就直接不要了,看到这里,what??? 之前是谁设计的

迅速阅读源码,查看相关联的逻辑,调整关联代码,火速将支持的 8 层,调整为 16 层组织结构,还好代码不是太复杂,否则这么大半夜的,真的不敢大动,毕竟这个时候已经不是一个人了,只是半个人
此处的组织结构好在不是传递的一棵树,如果是一棵树的话,大概率是要栈空间超限的,我们知道栈空间一般 2M,超过就要溢出了
好在是传递的是一个用户的 list,元素是关于用户的绝对路径,例如 /a/b/c/小花
问题 3 - 同步近 3 w 个用户居然花了近 8 分钟,近 3w 用户放到一个消息里
处理完问题 2 之后,尝试同步一次组织结构,发现近 3 w 的用户,居然同步花费了 8 分钟左右,其中 服务A 到服务B耗时近 2 分钟,然后服务 B 就处理了4 分钟,其余时间花费在别的服务处理
这个时候,就看到页面上一直在转圈,如果是用户看到一幕,那可能直接就是退货的节奏了
不过好在是同步成功了,暂时先把同步的按钮先关了吧,毕竟数据都过来了,接下来的事情都是可以调整的

其实看到这里,一个消息放近 3 w 个用户,只能说这一块根本没有设计,需求是赶鸭子上架赶出来的吧?对于这一块的优化放到下一篇来分享
问题 4 - 操作界面一直转圈,前端处理数据极慢
然而,当上一个问题还没有完全解决的时候,发现又爆出另外一个问题,看来年轻的不仅仅是一点点大,这个时候甲方爸爸要开始喊 细狗你行不行啊
打开平台,查看用户相关页面,卡的一匹,足以和上世纪打开网页的程度比慢了,简直没眼看,。处理 3 w 数据耗时 20 分钟,才看到正常的页面
原来处理方式是这样的:
前端找后台查询这个租户所有的用户,然后前端再进行树形展示,看到这里是不是蒙圈了???
哪有这么去实现功能的?基本的懒加载不会吗?暂时后端提供相应的接口, 前端 调整逻辑得以规避
懒加载, 是一种独特而又强大的数据获取方法,它能够在用户滚动页面的时候自动获取更多的数据,而新得到的数据不会影响原有数据的显示,同时最大程度上减少服务器端的资源耗用
然后,大部人的回答是,我也不知道会有那么多数据呀,诶,还是吃亏在太年轻,不够专业,甚至还有人提议,这个页面暂时让客户不要点

问题 5 - 大数据日志上报,由于数据量猛增,导致日志通道阻塞
真是福无双至,祸不单行啊
由于大数据日志上报模块也需要通过 grpc 根用户数据更新时间来一次性查询用户,同样的问题,这一条链路也卡的要死,显示由于请求超时,因为 rpc 超时时间代码中默认就设置了 10 s , 后面将时间改大了之后得以规避,最终由于大数据模块处理数据慢,花费了 2 个小时才把近 3w 的数据搞定
心中想,这也是大数据??,感觉这个产品要完蛋了
问题 6 - 系统本身仅支持 1 w 用户,前线默默的揽了一个 5w 用户的客户
处理到这里,天也渐渐蒙蒙亮了,从性能测试的小伙伴报告中了解到,之前做的性能测试最多就支持 1 个租户下有 1w 个用户,然而,销售吹牛皮招揽了远远大于这个数的客户,且还不告知研发内部
其实销售也没想到,怎么我们的平台这么弱鸡?逐步丧失信心。。
实际上出现的问题远远不止上述几个,接下来便是无尽的优化和思考,希望暴露的问题能给 xdm 带来一些提醒和思考
无论之前架构如何,对于第三方组织结构同步的时候,咱们需要考虑这些问题
- 产品的基本数据指标要同步给前线等相关方,避免自己人坑自己人,火急火燎的,很难有效的解决好问题
- 从第三方获取组织结构的时候,基本的分页要有,不仅仅是分页从第三方同步源获取,还要分页的给出去
- 对于服务 A 将数据给到服务 B 的时候,先分页给组,再分页给用户
- 对于 rpc 中消息大小设计,需要在设计之初根据业务考虑到可能的消息情况,去设置一个合理的数值
- 对于同步数据的时候,需要分步骤,分状态来进行处理,需要实现断点续传,需要能够应对各种异常场景
- 对于前端从后台获取用户树的时候,务必记得使用懒加载(简单来说就是可以先获取最外层的组,当点击到某个组的时候,再去查询这个组下面的用户信息和子组信息,而不是一口气将整个租户的组织结构加载出来,这也太心大了)
自然,实际落地的时候还需要考虑很多,我们需要更多的往前看一步,不给别人留坑,也不给自己挖坑
自然我们需要提升自己的能力,提升自己的思维,不断向大佬看齐,可能低级问题我们都会犯,但要有进步,要有变化,做需求,做设计,需要考虑更加全面,否则你永远不知道你带来的影响有多大
关于如何去优化第三方组织结构同步这个功能,感兴趣的朋友可以思考一下,评论区讨论一下哦,下一篇会进行阐述对其优化的方法,以及落地的方案
文中提到的技术感兴趣的可以查看如下相关文章,或者自行扩展:
- 【性能优化上】第三方组织结构同步优化一,你 get 到了吗?
- 【性能优化下】组织结构同步优化二,全量同步/增量同步,断点续传
- gRPC介绍
- gRPC 客户端调用服务端需要连接池吗?
- gRPC-Gateway 快速实战
- 懒加载
- 分页,同步
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
可以进入地址进行体验和学习:https://xxetb.xet.tech/s/3lucCI