Redis的简单使用 (实现Session持久化)

点进来你就是我的人了
博主主页:戳一戳,欢迎大佬指点!欢迎志同道合的朋友一起加油喔

目录
一、Redis数据类型的使用
1. 字符串(String)
2. 字典类型(哈希 Hashes)
3. 列表(Lists)
4. 集合(Sets)
5. 有序集合(Sorted sets)
二、SpringBoot连接Redis操作
三、Spring Session持久化
1. 引进sping session的依赖 , 配置相应的session存储方式(redis) 实现持久化
2. Spring Session的工作原理
四、序列化和反序列化 (知识点补充)
为什么要序列化?
Redis是一个开源的、内存中的数据结构存储系统,可以用作数据库、缓存和消息代理。它支持多种数据类型,包括字符串、哈希、列表、集合和有序集合。
一、Redis数据类型的使用
1. 字符串(String)
字符串是Redis最基本的数据类型,你可以理解它为与Memcached类似的功能,它是二进制安全的。也就是说,Redis的字符串可以包含任何数据,比如jpg图片或者序列化的对象。一个Redis字符串类型的值最大能存储512MB。由于其简单且灵活,字符串类型在Redis中有很多用途,如:
-
缓存:你可以将数据库查询的结果、用户会话、网页内容等存储为字符串,从而实现缓存功能。
-
计数器:Redis的字符串可以存储64位的整数和双精度浮点数,并支持自增或自减操作,所以你可以用字符串实现计数器。
-
分布式锁:你可以用
SET key value [EX seconds] [PX milliseconds] [NX|XX]命令实现分布式锁。
以下是一些基本的字符串操作和示例:
- SET key value:设置键的字符串值。
SET mykey "Hello"
- GET key:获取键的值。
GET mykey
- DEL key:删除键。
DEL mykey
- INCR key:将键的整数值增一。
INCR mycounter
- DECR key:将键的整数值减一。
DECR mycounter
- APPEND key value:如果键已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到原值的末尾。
APPEND mykey " World"
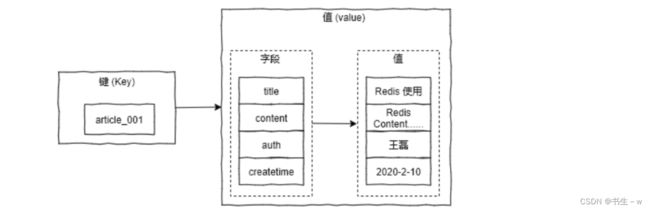
2. 字典类型(哈希 Hashes)
Redis的哈希(Hash)类型是字符串字段和字符串值之间的映射,因此它们是适合存储对象的理想数据类型。每个哈希可以存储2^32-1个键值对(超过40亿个)
哈希在Redis中常见的应用场景包括:
-
存储对象:哈希类型非常适合存储对象,因为它们可以存储与对象相关的多个字段和值。
-
缓存:哈希可以作为缓存的一种数据结构,例如存储一些数据库查询的结果。
-
计数器:哈希字段的值可以增加或减少,可以用来实现多个计数器。
以下是一些基本的哈希操作和示例:
- HSET key field value:为哈希表 key 中的指定字段设置值。
- HSET key field value:为哈希表 key 中的指定字段设置值。
HSET myhash field1 "Hello"
HGET myhash field1
将一个对象存入Redis哈希中的方法是将对象的每个字段作为键值对存储到哈希中。例如,如果你有一个表示人的对象,它有 name, age, 和 city 三个字段,你可以这样存储它:
HSET person name "Bob" age "30" city "New York"
- 在这个例子中,
person是哈希的名字,name,age,city是字段名,而Bob,30,New York则是它们对应的值。 - 需要注意的是,Redis 4.0.0 版本之后,
HSET命令支持同时设置多个字段。如果你的Redis版本较旧,可能需要分别执行多次HSET命令来存储每个字段。
获取存储的对象也同样简单,你可以使用 HGETALL 命令:
HGETALL person
这将返回哈希中所有的字段和值:
1) "name"
2) "Bob"
3) "age"
4) "30"
5) "city"
6) "New York"
3. 列表(Lists)
Redis的列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素至列表的头部(左边)或者尾部(右边)。一个列表最多可以包含 232 - 1 元素 (4294967295,每个列表超过40亿个元素)。列表中的元素可以重复,并且列表是双向的,这意味着元素可以从列表的两端推入或弹出。这种数据类型适合用于各种不同的场景,如:
-
消息队列:Redis列表的push、pop操作使得它非常适合作为消息队列使用。例如,应用程序可以将要处理的任务推入列表中,然后工作线程可以从列表中取出并处理任务。
-
时间线或者新闻feed:如果你想追踪最新的几件事情或者记录日志,Redis的列表类型很适合。可以将新的元素推入列表,然后仅保留最新的N个元素。
-
堆栈:通过将元素推入列表的头部,然后再从头部弹出元素,Redis列表可以作为LIFO(后入先出)堆栈使用。
以下是一些基本的列表操作和示例:
- LPUSH key value:将一个或多个值插入到列表头部。
LPUSH mylist "world"
LPUSH mylist "Hello"
- RPUSH key value:将一个或多个值插入到列表尾部。
RPUSH mylist "there"
- LPOP key:移除并获取列表最左边的元素。
LPOP mylist
- RPOP key:移除并获取列表最右边的元素。
RPOP mylist
- LRANGE key start stop:获取列表在指定区间内的元素。
start和stop都是0-based的索引,其中0是列表的第一个元素(头部),-1是最后一个元素(尾部)。
LRANGE mylist 0 -1
4. 集合(Sets)
Redis的Set是字符串的无序集合。集合是通过哈希表实现的,所以添加、删除、查找的复杂度都是O(1)。集合中最大的成员数为 232 - 1 (4294967295,每个集合可存储40多亿条记录)。集合在Redis中有很多应用场景,如:
-
社交网络:你可以用集合来存储用户的朋友列表或者粉丝列表,然后通过求交集、并集、差集等操作来获取共同的朋友、特定群体的用户等。
-
标签系统:你可以为每个标签创建一个集合,然后将带有该标签的项(如文章的ID)添加到集合中。然后你可以很容易地获取带有某个或某些特定标签的所有项。
-
数据过滤:由于集合的元素是唯一的,所以你可以通过向集合添加元素的方式来过滤重复的数据。
以下是一些基本的集合操作和示例:
- SADD key member:将一个或多个成员元素加入到集合中
SADD myset "Hello"
SADD myset "World"
- SREM key member:移除集合中一个或多个成员。
SREM myset "World"
- SMEMBERS key:返回集合中的所有成员。
SMEMBERS myset
- SISMEMBER key member:判断 member 元素是否是集合 key 的成员。
SISMEMBER myset "World"
- SUNION key1 key2:返回一个集合的并集。
SUNION myset otherset
- SINTER key1 key2:返回一个集合的交集。
SINTER myset otherset
- SDIFF key1 key2:返回一个集合的差集。
SDIFF myset otherset
5. 有序集合(Sorted sets)
和Sets相比,Sorted Sets类型也是set类型,但是每个元素都会关联一个score,redis正是通过score来为集合中的成员进行从小到大的排序的。有序集合的成员是唯一的,但score可以重复。有序集合中最大的成员数为 232 - 1 (4294967295,可以存储40多亿条记录)。
由于元素是按照分值排序的,有序集合非常适合以下几种用途:
-
排行榜:可以使用有序集合创建实时的排行榜,如游戏得分排行、用户活跃度排行等。
-
时间序列:如果把时间戳作为分值,那么有序集合就可以存储时间序列数据,如用户登录记录、文章发布记录等。
-
按距离排序的地理位置数据:如果把地理位置的距离作为分值,有序集合可以用来实现本地化的功能,如查找附近的餐厅或朋友。
以下是一些基本的有序集合操作和示例:
-
ZADD key score member:将一个或多个成员元素及其分数值加入到有序集当中。
ZADD myzset 1 "one"
ZADD myzset 2 "two"
- ZREM key member:移除有序集合中的一个或多个成员。
ZREM myzset "one"
- ZRANGE key start stop [WITHSCORES]:返回有序集中指定区间内的成员,成员位置按分数值递增来排序。
ZRANGE myzset 0 -1 WITHSCORES
- ZREVRANGE key start stop [WITHSCORES]:返回有序集中指定区间内的成员,成员位置按分数值递减来排序。
ZREVRANGE myzset 0 -1 WITHSCORES
- ZSCORE key member:返回有序集中,成员的分数值。
ZSCORE myzset "two"
- ZRANK key member:返回有序集合中指定成员的索引(排名)。
ZRANK myzset "two"
二、SpringBoot连接Redis操作
1. 添加依赖:首先,在你的Maven或Gradle项目中添加Spring Boot Data Redis依赖。如果你使用的是Maven,可以在pom.xml中添加如下依赖:
org.springframework.boot
spring-boot-starter-data-redis
2. 配置Redis连接:在你的application.properties或者application.yml文件中,可以配置如下Redis连接参数:(application.properties示例如下)
#配置连接reds
spring.redis.host= 127.0.0.1
#配置连接的端口号
spring.redis.port=8891
# 如果Redis服务器设置了密码,需要配置这一项
spring.redis.password=1111
#配置使用哪个Redis数据库
spring.redis.database=13. 在Spring应用中使用Redis:Spring Boot会自动配置一个RedisTemplate和StringRedisTemplate实例,你可以直接在你的应用中注入这些实例,然后就可以使用它们进行Redis操作了。例如:
// 使用 @RestController 注解,这样类中的方法都会以Json格式返回
@RestController
public class RedisController {
// 通过 @Autowired 注解,Spring Boot 会自动为我们注入一个 RedisTemplate 对象,我们可以使用它来操作 Redis
@Autowired
private RedisTemplate redisTemplate;
// 定义一个 HTTP 的 endpoint,当你访问 "/save" 这个路径时,会执行这个方法
// 使用 @RequestMapping 注解,可以将 HTTP 请求映射到特定的处理方法上
@RequestMapping("/save")
public String save() {
// 使用 RedisTemplate 的 opsForValue() 方法获取到一个 ValueOperations 对象,
// 然后调用 set 方法将 "userinfo" 的值设置为 "zhangsan"
redisTemplate.opsForValue().set("userinfo","zhangsan");
// 返回 "ok" 字符串作为 HTTP 响应
return "ok";
}
// 定义一个 HTTP 的 endpoint,当你访问 "/get" 这个路径时,会执行这个方法
@RequestMapping("/get")
public Object get() {
// 使用 RedisTemplate 的 opsForValue() 方法获取到一个 ValueOperations 对象,
// 然后调用 get 方法获取 "userinfo" 的值
return redisTemplate.opsForValue().get("userinfo");
}
// 定义一个 HTTP 的 endpoint,当你访问 "/save2" 这个路径时,会执行这个方法
@RequestMapping("/save2")
public String save2() {
// 使用 RedisTemplate 的 opsForHash() 方法获取到一个 HashOperations 对象,
// 然后调用 put 方法在 "myhash" 这个 hash 中添加一个键值对,键是 "username",值是 "lisi"
//myhash是哈希表的名字,然后username是该哈希表内的一个字段,它的值是lisi。
redisTemplate.opsForHash().put("myhash","username","lisi");
// 返回 "ok" 字符串作为 HTTP 响应
return "ok";
}
// 定义一个 HTTP 的 endpoint,当你访问 "/get2" 这个路径时,会执行这个方法
@RequestMapping("/get2")
public Object get2() {
// 使用 RedisTemplate 的 opsForHash() 方法获取到一个 HashOperations 对象,
// 然后调用 get 方法从 "myhash" 这个 hash 中获取 "username" 的值
return redisTemplate.opsForHash().get("myhash","username");
}
}
三、Spring Session持久化
1. 引进sping session的依赖 , 配置相应的session存储方式(redis) 实现持久化
- 在上面配置好redis的基础上,继续在
pom.xml文件中添加以下依赖:
org.springframework.session
spring-session-data-redis
- 然后在application.properties文件里修改上面redis的配置
# 表示我们使用Redis存储,这意味着Session数据将被存储在Redis数据库中。
spring.session.store-type=redis
#配置使用哪个Redis数据库
spring.redis.database=3
# 会话在30分钟(1800秒)无交互后将过期。
server.servlet.session.timeout=1800
# Redis Session的刷新模式。
#如果设置为"on_save",那么每次在Session中保存数据时,都会立即将数据写入Redis。
spring.session.redis.flush-mode=on_save
# Spring Session在Redis中使用的命名空间。所有的键都会被前缀化,以防止键之间的冲突。
spring.session.redis.namespace=spring:session
# Redis服务器的主机地址。这是Spring Boot应用将要连接的Redis服务器的IP地址或者主机名。
spring.redis.host=
# 连接Redis服务器的密码。如果Redis服务器没有设置密码,这个属性可以为空。
spring.redis.password=1111
# Redis服务器的端口号。默认情况下,Redis服务器运行在6379端口上。
spring.redis.port=8891- 最后就可以使用HttpSession的接口进行操作,将用户信息存储到session中即可(此时session会被存储到redis中)

// 使用@RestController注解,告诉Spring这是一个REST控制器,用于处理HTTP请求。
@RestController
// @RequestMapping("/user")注解为此控制器指定一个公共路径前缀,所以在此控制器中的所有路由都将在其前添加/user路径。
@RequestMapping("/user")
public class UserController {
// 这是一个字符串常量,代表了在HttpSession中保存用户信息的键名。将这个键名定义为一个常量可以帮助避免键名的打字错误。
private static final String SESSION_KEY_USERINFO = "SESSION_KEY_USERINFO";
// 这是一个路由处理方法,用于处理/save的HTTP请求。在请求中,客户端可以通过这个方法向HttpSession中保存用户信息。
@RequestMapping("/save")
public String save(HttpSession session) {
// 创建一个新的UserInfo对象,设置其属性,然后将其保存到HttpSession中。
UserInfo userInfo = new UserInfo();
userInfo.setId(1);
userInfo.setUsername("lisi");
userInfo.setAge(18);
// 将UserInfo对象保存到HttpSession中,键名为SESSION_KEY_USERINFO。
session.setAttribute(SESSION_KEY_USERINFO, userInfo);
// 如果保存成功,则返回"ok"。
return "ok";
}
// 这是一个路由处理方法,用于处理/get的HTTP请求。在请求中,客户端可以通过这个方法从HttpSession中获取用户信息。
@RequestMapping("/get")
public Object get(HttpServletRequest request) {
// 从HttpServletRequest中获取HttpSession。如果请求中没有对应的HttpSession,则返回null。
HttpSession session = request.getSession(false);
// 检查session是否存在,并且session中是否有对应的用户信息。如果都满足,则返回存储在SESSION_KEY_USERINFO键名下的用户信息。
if(session != null && session.getAttribute(SESSION_KEY_USERINFO) != null) {
return session.getAttribute(SESSION_KEY_USERINFO);
}
// 如果session不存在,或者session中没有用户信息,则返回"null"。
return "null";
}
}
在完成以上步骤之后,你的Spring Boot应用就会自动将Session数据存储在Redis中,而不是在内存中。这样,即使你的应用重启,用户的Session数据也不会丢失。此外,这也使得在多实例环境下共享Session数据成为可能。
2. Spring Session的工作原理
- Spring Session提供了一个透明的方式来替换HttpSession。当你在应用中加入了Spring Session的依赖并配置了相应的Session存储方式(如这里的Redis)后,Spring Session会在后台替换原生的HttpSession实现。
- 在我上面的代码中,我并没有直接使用Redis的API,仍然是使用HttpSession的接口进行操作。然而,因为Spring Session的存在,这些操作实际上已经被映射到了Redis上。这就是为什么你只需要配置Redis和引入Spring Session的依赖,就可以将Session存储在Redis中的原因。
- 也就是说,Spring Session提供了一种透明的方式来更改Session的存储位置,而开发者无需更改自己的代码。这也使得在不同环境中切换Session存储的方式变得非常方便。例如,你可能在开发环境中使用内存存储Session,而在生产环境中则使用Redis存储Session。只需要更改配置文件,而无需更改代码。
四、序列化和反序列化 (知识点补充)
在 Java 中,对象的序列化是将对象的状态(包括它的数据或属性)转换为字节流的过程,反序列化则是将字节流恢复为原来的对象。这个过程主要涉及两个接口:Serializable 和 Externalizable。
为什么要序列化?
序列化的主要目的是为了保存对象的状态,以便可以在未来的某个时间点再将其恢复。以下是使用序列化的几个常见场景:
-
在网络中发送对象:序列化可以将对象转换为字节流,然后可以将这个字节流在网络中传输。在接收端,我们可以再将这个字节流反序列化为对象。
-
持久化:如果你想将对象的状态保存到磁盘上,那么你可以将对象序列化为字节流,然后将这个字节流写入到磁盘。在需要的时候,你可以再从磁盘读取这个字节流,并将其反序列化为对象。
-
跨JVM内存共享:例如在分布式计算或者微服务架构中,一个服务的JVM可能需要将对象发送给另一个服务的JVM。
如果你觉得这篇文章有价值,或者你喜欢它,那么请点赞并分享给你的朋友。你的支持是我创作更多有用内容的动力,感谢你的阅读和支持。祝你有个美好的一天!
