Kafka核心原理
一、kafka安装步骤
(1)配置profile文件
vim /etc/profile
// KAFKA
export KAFKA_HOME=/opt/soft/kafka212
export PATH=$KAFKA_HOME/bin:$PATH
source /etc/profile(2)创建kfkdata目录
cd /opt/soft/kafka212/
mkdir kfkdata
(3)进入config目录配置server.properties文件
// Kafka服务器id号
21 broker.id=0
// 设置主机IP地址和端口号
36 advertised.listeners=PLAINTEXT://192.168.91.11:9092
// 存储日志文件的目录
60 log.dirs=/opt/soft/kafka212/kfkdata
123 zookeeper.connect=192.168.91.11:2181
// 设置连接zk的超时时间(毫秒)
126 zookeeper.connection.timeout.ms=18000
// 主题启用
137 delete.topic.enable=true (4)进入config目录启动Kafka
先启动zookeeper后启动Kafka
// 先启动zookeeper
zhServer.sh start
// 后启动kafka
nohup kafka-server-start.sh /opt/soft/kafka212/config/server.properties &二、kafka常用命令
// partitions 分区 replication-factor 副本数
// 创建主题
kafka-topics.sh --create --zookeeper 192.168.91.128:2181 --topic kb23 --partitions 1 --replication-factor 1
// 查看主题内容
kafka-topics.sh --zookeeper 192.168.91.11:2181 --list
// 生产者,生产消息
kafka-console-producer.sh --topic kb23 --broker-list 192.168.78.131:9092
// 消费者
kafka-console-consumer.sh --bootstrap-server 192.168.78.131:9092 --topic bigdate --from-beginning
// 查看队列详情
kafka-topics.sh --zookeeper 192.168.91.128:2181 --describe --topic kb23
// 查看队列消息数量
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.91.11:9092 --topic bigdate2
// 删除topic
kafka-topics.sh --zookeeper 192.168.91.11:2181 --delete --topic bigdate三、Kafka架构
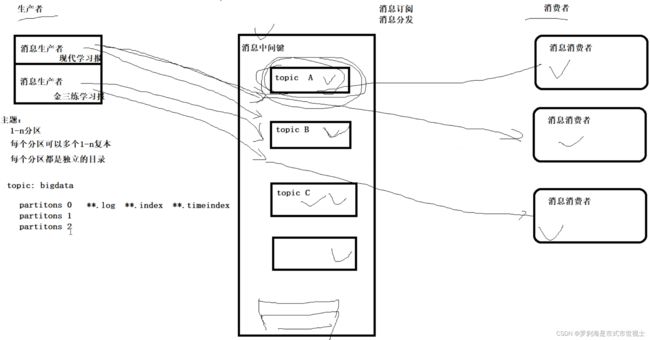
Topic:维护一个主题中的消息,可视为消息分类
Producer:向Kafka主题发布(生产)消息
Consumer:订阅(消费)主题并处理消息
Broker:Kafka集群中的服务器
四、Kafka
(1)topic
主题是已发布消息的类别名称
发布和订阅数据必须指定主题
主题副本数量不大于Brokers个数
(2)partition
一个主题包含多个分区,默认按Key Hash分区
每个Partition对应一个文件夹
每个Partition被视为一个有序的日志文件(LogSegment)
Replication策略是基于Partition,而不是Topic
每个Partition都有一个Leader,0或多个Followers
(3)Kafka Message header(消息头,固定长度)
offset:唯一确定每条消息在分区内的位置
CRC32:用crc32校验消息
"magic":表示本次发布Kafka服务程序协议版本号
"attributes":表示为独立版本、或标识压缩类型、或编码类型
(4)Kafka Message body(消息体)
key:表示消息键,可选
value bytes payload:表示实际消息数据
(5)Kafka Producer
生产者将消息写入到Broker
Producer直接发送消息到Broker上的Leader Partition
Producer客户端自己控制着消息被推送到哪些Partition
随机分配、自定义分区算法等
Batch推送提高效率
(6)Kafka Consumer
①消费者通过订阅消费消息
offset的管理是基于消费组(group.id)的级别
每个Partition只能由同一消费组内的一个Consumer来消费
每个Consumer可以消费多个分区
消费过的数据仍会保留在Kafka中
消费者不能超过分区数量
②消费模式
队列:所有消费者在一个消费组内
发布/订阅:所有消费者被分配到不同的消费组
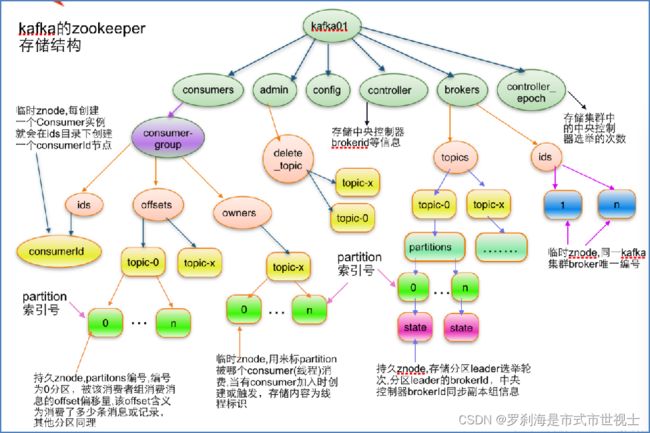
(7)ZooKeeper在Kafka中的作用
①Broker注册并监控状态
/brokers/ids
②Topic注册
/brokers/topics
③生产者负载均衡
每个Broker启动时,都会完成Broker注册过程,生产者会通过该节点的变化来动态地感知到Broker服务器列表的变更
④offset维护
Kafka早期版本使用ZooKeeper为每个消费者存储offset,由于ZooKeeper写入性能较差,从0.10版本后,Kafka使用自己的内部主题维护offset
(8)Kafka数据流
①副本同步 ISR(In-Sync Replica)
②容灾 Leader Partition
③高并发 读写性能 Consumer Group
④负载均衡

(9)Kafka API
①Producer API②Consumer API③Streams API④Connector API |
 |
五、kafka生产消费者模式
package nj.zb.kb23.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.Scanner;
/*
生产者消费模式
*/
public class MyProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.11:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
/*
应答机制
0:不需要等待broker任何响应,无法确保数据正确送到broke中
1:只需要得到分区副本中leader的确认就OK,可能会丢失数据(极端情况下)
-1:等到所有副本确认收到信息,响应时间最长,数据最安全,不会丢失数据,(极端情况下,可能会重复)
*/
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
KafkaProducer producer = new KafkaProducer<>(properties);
Scanner scanner = new Scanner(System.in);
while (true){
System.out.println("请输入内容:");
String msg=scanner.nextLine();
if (msg.equals("tt")) {
break;
}
ProducerRecord record = new ProducerRecord<>("bigdate",msg);
producer.send(record);
}
}
} 
// 创建表bigdate
kafka-topics.sh --create --zookeeper 192.168.91.11:2181 --topic bigdate --partitions 1 --replication-factor 1
// 查看列队信息
kafka-console-consumer.sh --bootstrap-server 192.168.91.11:9092 --topic bigdate --from-beginning六、kafka生产者生产消息
package nj.zb.kb23.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/*
生产者生产消息
*/
public class MyProducer2 {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.11:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
/*
* 开启重试,如果发送消息失败,默认是0,只发送一次,可以设置重置3次(共4次)
* 每次重试的间隔是100ms,可以手动设置10000
*/
properties.put(ProducerConfig.RETRIES_CONFIG,3);//properties.put(ProducerConfig."retries",3);
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,10000);//每个分区10000条信息
/*
BUFFER_MEMORY_CONFIG 缓存内存 默认值 32M
BATCH_SIZE_CONFIG 批大小配置 默认值 16KB
SEND_BUFFER_CONFIG 每次批量发送的值
*/
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,102400); //1024 byte kb
properties.put(ProducerConfig.SEND_BUFFER_CONFIG,102400);
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,67108864); //64M
//应答机制:-1 all
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
//多线程
ExecutorService executorService = Executors.newCachedThreadPool();
//模拟10个线程,同时向Kafka传递数据
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
//一个线程代表一个人
KafkaProducer producer = new KafkaProducer<>(properties);
String threadName = Thread.currentThread().getName();
System.out.println(threadName);
//每个线程传递1000条数据
for (int j = 0; j < 10000; j++) {
ProducerRecord record = new ProducerRecord<>("bigdate1", threadName + " " + j);
try {
//让主机休息10毫微秒
Thread.currentThread().sleep(10);
} catch (Exception e) {
e.printStackTrace();
}
producer.send(record);
}
}
});
executorService.execute(thread);
}
executorService.shutdown();
while (true){
//让主线程多休息10秒,主线程关闭,子线程没有跟上,所有数据缺失
Thread.sleep(10000);
if (executorService.isTerminated()){
System.out.println("game over!");
break;
}
}
}
} 
// 查看进度
[root@kb23 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.91.11:9092 --topic bigdate1 --from-beginning
pool-1-thread-4 9997
pool-1-thread-9 9997
pool-1-thread-1 9997
pool-1-thread-8 9998
pool-1-thread-4 9999
pool-1-thread-7 9999
pool-1-thread-3 9999
pool-1-thread-5 9999
pool-1-thread-2 9999
^CProcessed a total of 100000 messages