MySQL进阶_2(应用优化、缓存优化、内存优化、锁)
文章目录
-
- 一点前言
- 应用优化
-
- 连接池
- 减少数据库的访问
- 负载均衡
- 缓存优化
-
- 概述
- 操作流程
- 查询缓存参数设置
- 查询缓存的使用
- 缓存失效的情况
- 内存优化
-
- 优化原则
- 内存优化说明
- MySQL并发度调整
- 锁(浅了解一下)
一点前言
- Mysql可以通过调整参数进行调优,所以本篇大致整理一下参数调优的东西,大多偏理论,没有实际的应用场景去实践,大家且随便看看
- 这些参数都可以在Mysql的配置文件my.ini(Linux中叫做my.conf)中进行配置
应用优化
连接池
对于数据库来说,建立数据库连接的开销比较大,而每一次数据库的访问都要去创建一个连接对象。
那么我们可以通过数据库连接池来进行优化,提高数据库的访问性能
减少数据库的访问
- 避免对数据进行重复检索
- 增加缓存,像mybatis这类的框架都会给我们提供一级/二级缓存,也可以使用redis进行缓存
- ps:简述一下mybatis的一级/二级缓存
一级缓存: 指的是SqlSession级别的,作用域是SqlSession,Mybatis默认开启一级缓存,在同一个SqlSession中,相同的Sql查询的时候,第一次查询就会从缓存中取,如果发现没有数据,那么就从数据库查询出来,并且缓存到HashMap中,如果下次还是相同的查询,就会直接从缓存中查询,即不再去重复执行Sql
当查询到的数据,进行增删改操作的时候,缓存就会失效,在Spring容器管理中每次查询都是在创建一个新的SqlSession,所以在分布式环境中不会出现数据不一致的问题
二级缓存: 二级缓存是mapper级别的,多个SqlSession去操作同一个mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
第一次调用mapper下的sql的时候去数据库查询信息,查询到后会放到该mapper对应的二级缓存区域,第二次调用namespace下的mapper映射文件中相同的Sql去查询时,会去对应的二级缓存中取结果,使用时需要开启cache标签,在select上添加useCache属性值为true,在更新和删除的时候需要手动开启flushCache刷新缓存
负载均衡
- 读写分离,只对master进行写操作,而提供多台服务器对master进行同步用于读操作
- 分布式数据库架构
缓存优化
概述
开启mysql缓存后,在数据没有更新的情况下,相同的查询sql会使用缓存数据来返回结果
在数据更新较少,相似查询较多的情况下,使用mysql缓存可以显著提升查询效率
操作流程
一张老图来解释
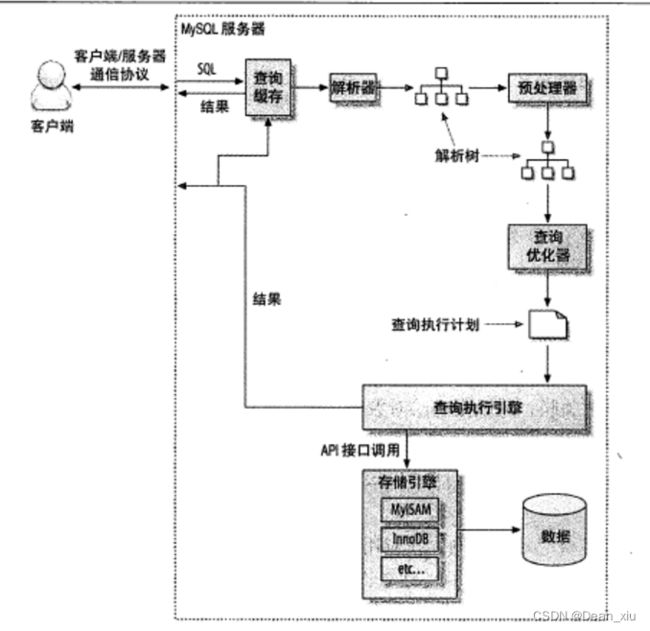
- 客户端发送一条查询语句给服务器
- 服务器先检查查询缓存中是否已存在结果,如果命中缓存,则立刻返回结果,否则进行下一步
- 服务器端对SQL进行解析、预处理、再由优化器生成对应的执行计划
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询
- 返回结果
查询缓存参数设置
常用命令:
# 查看是否支持缓存
show variables like 'have_query_cache';
#查看是否开启缓存
show variables like 'query_cache_type';
#查看缓存占用大小
show variables like 'query_cache_size';
#查看缓存参数设置
show variables like '%query_cache%';
#查看缓存状态变量
show status like 'Qcache%';

- Qcache_free_blocks:已分配内存块中空闲块数量
- Qcache_total_blocks:当前查询缓存占用的内存块数量
- Qcache_free_memory:缓存空闲空间的大小
- Qcache_hits:缓存命中次数
- Qcache_inserts:缓存未命中时,数据写入缓存的次数
- Qcache_queries_in_cache:缓存查询语句的数量
- Qcache_lowmem_prunes:缓存的修剪次数,缓存满时,会使用LRU算法移除最久未被使用的缓存,此值较大时,说明缓存空间太小
- Qcache_not_cached:未被缓存的查询Sql的数量
查询缓存的使用
可以在my.ini中修改缓存配置
query_cache_size=1048576
query_cache_type=1
query_cache_type
- 查询缓存类型,有0,1,2三个取值。0代表不使用查询缓存。1表示始终使用查询缓存。2表示按需使用查询缓存
- 如果query_cache_type为1而又不想利用查询缓存中的数据,可以使用下面的SQL
SELECT SQL_NO_CACHE * FROM my_table WHERE condition; - 如果值为2,要使用缓存的话,需要使用SQL_CACHE开关参数:
SELECT SQL_CACHE * FROM my_table WHERE condition;
缓存碎片整理
重置缓存 reset query cache;
缓存失效的情况
- SQL语句不一致,要想缓存命中,必须保持SQL语句一致
- 当SQL语句中有些不确定条件时,不会缓存,如使用now()函数等
- 不使用任何表的语句
- information_schema,performance_schema,mysql库中的表不缓存
- 在函数、触发器或事件的主体中执行的查询,不缓存
- 数据表的数据有变化(增删改)或数据表的结构(字段的增减)有变化,则会清空全部的缓存数据,即缓存失效
内存优化
优化原则
- 将尽量多的内存分给mysql做缓存,但也要给操作系统和其他程序预留足够的内存
- MyISAM的数据文件的读取依赖于操作系统的IO,因此如果有MyISAM表,就要预留更多的内存给操作系统做IO缓存
- 合理设置排序区,链接区等缓存大小
内存优化说明
查询最大使用内存
select (@@key_buffer_size+
@@innodb_buffer_pool_size+
@@tmp_table_size+
@@query_cache_size+
@@innodb_log_buffer_size+
@@max_connections*(
@@read_buffer_size+
@@read_rnd_buffer_size+
@@sort_buffer_size+
@@join_buffer_size+
@@binlog_cache_size+
@@thread_stack)
)/1024/1024 as “MYSQL_Service_Max_Mem”;
查询单个会话使用内存
select (@@read_buffer_size +
@@read_rnd_buffer_size +
@@sort_buffer_size +
@@join_buffer_size +
@@binlog_cache_size +
@@thread_stack
)/1024/1024 as “MYSQL_Session_Max_Mem”;
有一个内存测算网站,这个网站

浅说一下这些参数:
- key_buffer_size = 32M:指定索引缓冲区的大小,决定了索引处理的速度,尤其是索引读的速度,仅对MyISAM表起作用,即使不使用MyISAM表,但内部的临时磁盘表是MyISAM表,也要用该值。由于大部分数据库的引擎是InnoDB,大部分表均是innodb,此处推荐取默认值一半32M
- query_cache_size = 64M:查询缓存大小,当打开的时候,执行查询语句会进行缓存,读写都会带来额外的内存消耗,下次再查询若命中该缓存会立刻返回结果
默认该选项是关闭,打开需要调整参数query_cache_type=ON - tmp_table_size = 64M: 范围设置为64-256M最佳,当需要做类似group by操作生成临时表大小,提高连接查询的速度,调整该值直到 created_tmp_disk_tables / created_tmp_tables * 100% <= 25%(可以通过
show global status like 'created_tmp%'查看计算),处于这样一个状态下,效果较好,如果网站大部分为静态内容,可以设置为64M,如果动态页面,则设置为100M以上,不宜过大,会导致内存不足IO堵塞 - innodb_buffer_pool_size = 8196M:缓存innodb表的索引,数据,插入数据时的缓冲。专用mysql服务器设置的大小:操作系统内存的70%~80%最佳。
此外这个参数是非动态的,要修改这个值,需要重启mysqld服务。设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而降低了sql的查询效率 - innodb_additional_mem_pool_size = 16M:用于存放innodb的内部目录,这个值不用分配的过大,系统可以自适应调节。通常16M就够用了,如果表很多,可以适当的增大,如果这个值自动增加,会在error log中有所显示
- innodb_log_buffer_size = 8M:innodb的写操作,将数据写入到内存中的日志缓存中,由于InnoDB在事务提交前,并不将已改变的日志写入到磁盘中,因此在大事务中,可以减轻磁盘IO的压力,通常情况下,如果不是写入大量的超大二进制数据,4~8M已经足够
- max_connections = 200:最大连接数,根据同时在线人数设置一个比较综合的数字,最大不超过16384,需要进行系统评估
- sort_buffer_size = 2M:一个connection级的参数,在每个connection第一次需要这个buffer的时候,一次性分配设置的内存。并不是越大越好,由于是connection级别的参数,过大的设置+高并发可能会耗尽系统内存资源,官方文档给的建议是256KB~2MB
- read_buffer_size = 2M:Mysql读入缓存区的大小,对表进行顺序扫描的请求将分配一个读入缓冲区,Mysql会为它分配一段内存缓冲区,read_buffer_size变量控制这一缓冲区的大小,如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描太慢,可以通过增加该变量的值以及内存缓冲区提高性能,256KB适用于512内存,1GB内存可以设置为1M,以此类推
- read_rnd_buffer_size = 250K:Mysql的随机读缓冲区大小,当按任意顺序读取行时(列如按照排序顺序)将分配一个随机读取缓冲区,进行排序查询时,Mysql会先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度
如果需要大量数据可适当的调整该值,但Mysql会为每个客户连接分配该缓冲区,所以尽量适当设置该值,以避免内存开销过大。表的随机的顺序缓冲,提高读取效率 - join_buffer_size = 250K:多表参与join操作时的分配缓存,适当分配,降低内存消耗
- thread_stack = 256K:每个连接线程被创建时,MySQL给它分配的内存大小,当MySQL创建一个新的连接线程时,需要给它分配一定大小的内存堆栈空间,以便存放客户端的请求Query及自身的各种状态和处理信息
Thread Cache 命中率:Thread_Cache_Hit = (Connections - Threads_created) / Connections * 100%;命中率处于90%才算正常配置,当出现“mysql-debug: Thread stack overrun”的错误提示的时候需要增加该值。此处我们配置为256K。 - binlog_cache_size = 250K:类似于Innodb_log_buffer_size缓存事务日志,binlog_cache_size缓存Binlog,不同的是这个是每个线程独一个,主要对大事务有较大的性能提升
但如果设置过大,也会消耗内存资源,更需要注意的是:binlog_cache不是全局的,是按session为单位独享分配的,也就是说当一个线程开始一个事务的时候,mysql就会为这个session分配一个binlog_cache
而设置过小的话,如果用户提交一个长事务,如批量导入数据的话,那么该事务必然会产生很多binlog,这样cache可能不够用,不够用的时候mysql会把uncommited的部分写入临时文件(临时文件cache的效率必然没有内存cache高),等到commited的时候才会写入正式的持久化日志文件,可以通过以下方式来查询是否合理
show status like '%binlog%';

Binlog_cache_disk_use:查看调整写入磁盘的次数,写入磁盘为0最好
MySQL并发度调整
- 从实现上来说,MySQL Server是多线程结构,包括后台线程和客户服务线程,多线程可以有效利用服务器资源,提高数据库的并发性能。
- 在MySQL中,控制并发连接和线程的主要参数包括 max_connections、back_log、thread_cache_size、table_open_cahce、innodb_lock_wait_timeout
- max_connections
控制允许连接到MySQL数据库的最大数量,默认值是151,如果状态变量connection_errors_max_connections不为0,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这时可以考虑增大max_connections的值
Mysql最大可支持的连接数,取决于很多因素,包括给定操作系统平台的线程库的质量、内存大小、每个连接的负荷、CPU处理速度、期望的响应时间等。
在Linux平台下,性能好的服务器,支持500-1000个连接不是难事
具体值需要根据服务器性能进行评估 - back_log
该参数控制的是mysql监听TCP端口时设置的积压请求栈大小,如果MySQL的连接数达到max_connections时,新来的请求会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。
5.6.6版本之前默认值为50,之后的版本默认为50+(max_connections/5),但最大不超过900
如果需要数据库在较短时间内处理大量连接请求,可以考虑适当增大back_log的值 - thread_cache_size
为了加快连接数据库的速度,MySQL会缓存一定数量的客户服务线程以备重用,通过本参数可以控制MySQL缓存客户服务线程的数量 - table_open_cahce
该参数用来控制所有SQL语句执行线程可打开表缓存的数量,而在执行SQL语句时,每一个SQL执行线程至少要打开一个表缓存
该参数的值应根据最大连接数以及每个连接执行关联查询中涉及的表的最大数量来设定:max_connections x N - innodb_lock_wait_timeout
该参数用于设置InnoDB事务等待行锁的时间,默认是50ms,可以根据需要动态设置
对于需要快速反馈的业务系统来说,可以将行锁的等待时间调小,以避免事务长时间挂起,对于后台运行的批量处理程序来说,可以将行锁的等待时间调大,以避免发生大的回滚操作
锁(浅了解一下)
mysql有八种锁:行锁、间隙锁、临建锁、共享锁/排他锁、意向共享锁/意向排他锁、插入意向锁、自增锁
实际上,MySQL官网中还提到了一种预测锁,这种锁主要用于存储了空间数据的空间索引
- 行锁
行锁一定作用在索引上 - 间隙锁
间隙锁的本质上是用于阻止其他事务在该间隙插入新记录,而自身事务是允许在该间隙内插入数据的
间隙锁的应用场景包括并发读取、并发更新、并发插入和并发删除 - 临键锁
临键锁是行锁+间隙锁,即临键锁是一个左开右闭的区间,当隔离级别是RR时,InnoDB会使用临键锁,因而可以防止幻读 - 共享锁/排他锁
共享锁/排他锁都只是行锁,与间隙锁无关,并且共享锁是一个事务并发读取某一行记录所需要持有的锁
尽管共享锁/排他锁是行锁,与间隙锁无关,但一个事务在请求共享锁/排他锁时,获取到的结果却可能是行锁,也可能是间隙锁,也可能是临键锁,这取决于数据库的隔离级别以及查询的数据是否存在 - 意向共享锁/意向排他锁
意向共享锁/意向排他锁属于表锁,且取得意向共享锁/意向排他锁是取得共享锁/排他锁的前置条件 - 插入意向锁
插入意向锁是一种特殊的间隙锁,但不同于间隙锁的是,该锁只用于并发插入操作
如果说间隙锁锁住的是一个区间,那么插入意向锁锁住的就是一个点 - 自增锁
自增锁是一种特殊的表级锁,主要用于事务中插入自增字段,也就是我们最常用的自增主键id
通过innodb_autoinc_lock_mode参数可以设置自增主键的生成策略