正则表达式与文本处理器
- 正则表达式
-
-
- 1.元字符
- 2.表示次数
- 3.位置锚定
- 4.分组
-
- 文本处理器
-
-
- 1.grep
- 2.tr 基本功能转换
- 3.cut 切片
- 4.sort排序
- 5.uniq 去重
- 6.awk
-
- 6.1基础用法
- 6.2 awk常见的内置变量
-
正则表达式
1.元字符
. 匹配任意单个字符,可以是一个汉字
[] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] [:alpha:]
[^] 匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] [a.z]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围
广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意
Unicode 正则表达式会匹配全角空格符

2.表示次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* #任意长度的任意字符,不包括0次
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
#匹配手机号
[root@localhost ~]#echo 15232012345 |grep '1[0-9]\{10\}'
15232012345
#匹配qq号
[root@localhost ~]#echo 20141472225 |grep '[0-9]\{5,12\}'
20141472225
[root@localhost ~]#echo 12345 |grep '[0-9]\{5,12\}'
12345
#例子
[root@localhost ~]#echo google |grep 'go\{2\}gle'
#代表前面的o出现2次
google
[root@localhost ~]#echo goooogle|grep 'go\{2,\}gle'
#代表前面的o出现2次以上
goooogle
[root@localhost ~]#echo gooooogle|grep 'go\{2,5\}gle'
#带表前面的o出现2次以上5次以下
gooooogle
[root@localhost ~]#
[root@localhost ~]#echo gooooogle|grep 'go*gle'
gooooogle
[root@localhost ~]#echo ggle|grep 'go*gle'
#表示0次到任意次
ggle
[root@localhost ~]#echo gggle|grep 'go*gle'
#grep 包含最前面的g不匹配
gggle
[root@localhost ~]#echo gdadadadagle|grep 'g.*gle'
#.*代表任意匹配所有
gdadadadagle
[root@localhost ~]#echo ggle|grep 'go\?gle'
ggle
[root@localhost ~]#echo gogle|grep 'go\?gle'
# \?一次或者0次
gogle
[root@localhost ~]#echo google|grep 'go\+gle'
#一个以上
google
[root@localhost ~]#echo ggle|grep 'go\+gle'
[root@localhost ~]#echo google|grep 'go\?gle'
#过滤ip地址
[root@localhost ~]#ifconfig ens33|grep netmask
inet 192.168.210.101 netmask 255.255.255.0 broadcast 192.168.210.255
[root@localhost ~]#ifconfig ens33|grep netmask|grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+'|head -1
192.168.210.101
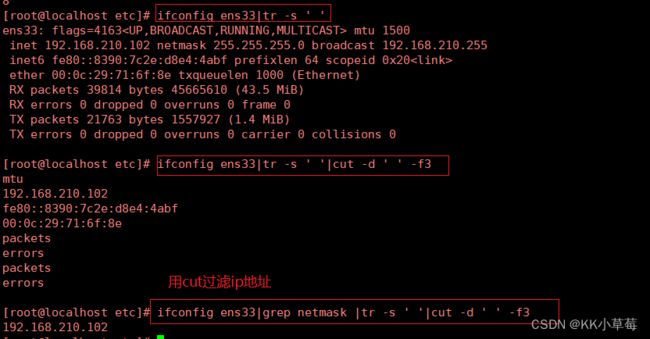
#用cut过滤ip地址
[root@localhost ~]#ifconfig ens33|tr -s ' '
[root@localhost ~]#ifconfig ens33|tr -s ' '|cut -d ' ' -f3
[root@localhost ~]#ifconfig ens33|grep netmask |tr -s ' '|cut -d ' ' -f3
3.位置锚定
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行 (单独一行 只有root)
^$ #空行
^[[:space:]]*$ # 空白行
\< 或 \b #词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\> 或 \b #词尾锚定,用于单词模式的右侧
\b以字母开头以字母结尾
\ #匹配整个单词
#例子
#过滤出fstab中的单词
[root@localhost ~]#cat /etc/fstab | grep -o '\b[[:alpha:]]\+\b'
[root@localhost ~]#cat /etc/fstab | grep -o '\b[[:alpha:]]\+\b'|wc -l
46
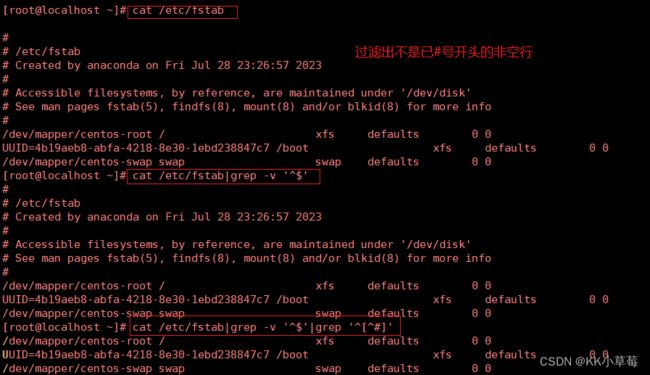
#思考过滤出不是已#号开头的非空行
[root@localhost ~]#cat /etc/fstab
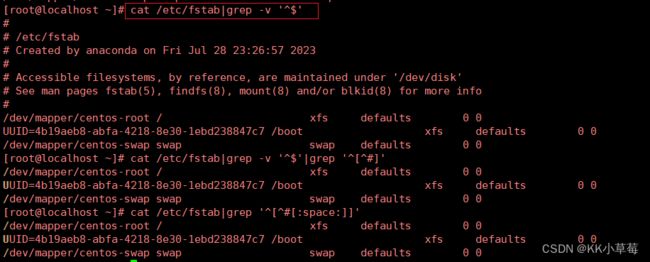
[root@localhost ~]#cat /etc/fstab|grep -v '^$'
[root@localhost ~]#cat /etc/fstab|grep -v '^$'|grep '^[^#]'
#更简洁的方法,不是以#号或空格开头的非空行
[root@localhost ~]#cat /etc/fstab|grep '^[^#[:space:]]'

4.分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
#例子
[root@localhost ~]#echo abcabcabc |grep "\(abc\)\{3\}"
#分组,匹配abc
abcabcabc
[root@localhost ~]#echo 1abc |grep "1\|2abc"
#只匹配了1abc
1abc
[root@localhost ~]#echo 1abc |grep "\(1\|2\)abc"
#匹配1abc或者2abc
1abc
[root@localhost ~]#ifconfig ens33 |grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}'
192.168.210.101
255.255.255.0
192.168.210.255
文本处理器
1.grep
#选项
-m # 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
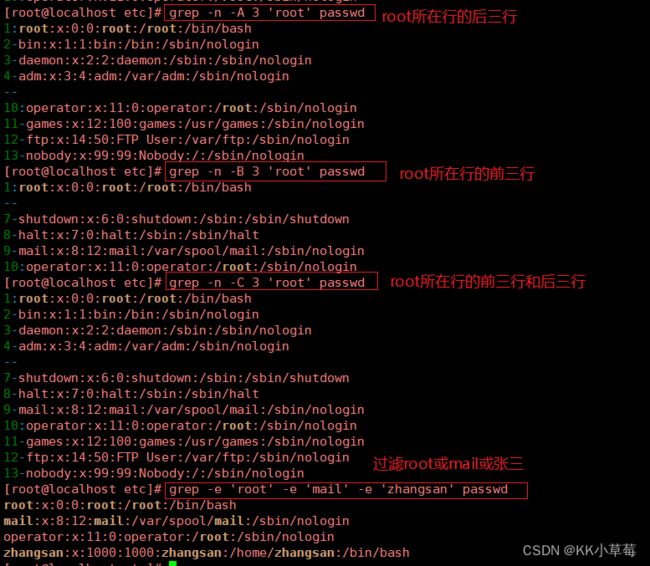
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
#例子
[root@localhost etc]#grep -in 'root' passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost etc]#grep -inc 'root' passwd
2
[root@localhost etc]#grep -n -A 3 'root' passwd
#root所在行的后三行
[root@localhost etc]#grep -n -B 3 'root' passwd
#root所在行的前三行
[root@localhost etc]#grep -n -C 3 'root' passwd
#root所在行的前三行和后三行
[root@localhost etc]#grep -e 'root' -e 'mail' -e 'zhangsan' passwd
#过滤root或mail或zhangsan
2.tr 基本功能转换
tr[选项]...SET1[SET2]
SET是一组字符串,一般都可按照字面含义理解
-d 删除
-s 压缩
-c 用字符串1中字符集的补集替换此字符,要求字符集为ASCll
#例子
[root@localhost ~]#tr 123 abc
#只要出现123 就转换成abc
234
bc4
123
abc
245
b45
[root@localhost ~]#tr 123456 abc
#最后一个一直用
123456789
abcccc789
[root@localhost ~]#tr -d abc
#删除abc
2a34bc
234
[root@localhost ~]#tr -s 1
#压缩
111111111
[root@localhost ~]#cat /dev/random |tr -dc [[:alnum:]] |head -c 12 删特殊字符的补集
#生成随机密码
ONbNjw]U3Ttx[root@localhost ~]#cat /dev/random |tr -dc [[:alnum:]] |head -c 12
YqNPsddvl[Ud
3.cut 切片
cut命令可以提取文本文件数据的指定列
cut[选项]...[文件]...
常用选项:
-d:指明分隔符,默认tab
-f:想要获取的字段 1列 2列
-c:取字符
#例子
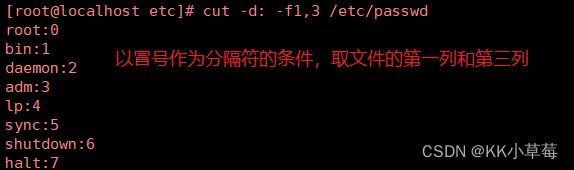
[root@localhost ~]#cut -d: -f1,3 /etc/passwd
#以冒号作为分隔符的条件,取文件的第一列和第三列
[root@localhost ~]#ll |tail -n +2|tr -s ' '|cut -d ' ' -f2,3
#从第二行开始,将空行压缩成一个后 再空格为分隔符取第2列和第3列

4.sort排序
把整理过的文本显示在屏幕上,不改变原始文件
sort [options] file(s)
选项:
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t 指定分隔符
-k 指定列
#例子
[root@localhost ~]#sort /etc/passwd -k3 -t: -n
#以:为分隔符 第3列按照数字大小排序
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
5.uniq 去重
只去连续的重
uniq [OPTION]... [FILE]...
选项:
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
#例子:
[root@localhost ~]#vim test1
1
2
3
3
4
5
5
5
6
7
6
7
[root@localhost ~]#uniq test1
#只会将连续的行去重
1
2
3
4
5
6
7
6
7
[root@localhost ~]#uniq -c test1
#显示出现次数
1 1
1 2
2 3
1 4
3 5
1 6
1 7
1 6
1 7
6.awk
- 功能强大的编辑工具
- 无交互的情况下实现复杂的文本操作
awk [options] 'program' var=value file…
awk -f 脚本文件 文件1 文件2
#说明:
program通常是被放在单引号中,并可以由三种部分组成
BEGIN语句块
模式匹配的通用语句块
END语句块
pattern{action statements;..}
pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等
action statements:对数据进行处理,放在{}内指明,常见:print, printf
#常见选项:
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v(小v) var=value 变量赋值
6.1基础用法
#例子
#print动作
[root@localhost ~]#df | awk '{print $5}'
[root@localhost ~]#df | awk '{print $5,$2}'
[root@localhost ~]#ifconfig ens33|awk '/netmask/{print $2}'
#提取ip地址
192.168.210.101
[root@localhost ~]#awk '{print "hello"}' < /etc/passwd
#passwd文件有多少行就打印多少个hello
[root@localhost ~]#cat /etc/passwd|awk -F: '{print $1":"$3}'
##指定冒号作为分隔符,打印第一列和第三列
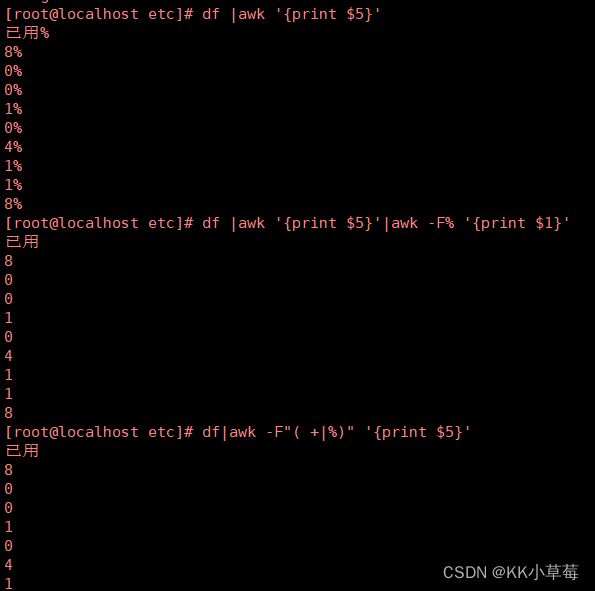
[root@localhost ~]#df |awk '{print $5}'
[root@localhost ~]#df |awk '{print $5}'|awk -F% '{print $1}'
[root@localhost ~]#df|awk -F"( +|%)" '{print $5}'



6.2 awk常见的内置变量
FS :指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
OFS:输出时的分隔符
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
#例子
################# FS ###################
[root@localhost ~]#awk -v FS=':' '{print $1FS$3}' /etc/passwd
#此处FS 相当于于变量 -v 变量赋值 相当于 指定: 为分隔符
[root@localhost ~]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd
#定义变量传给FS
######### 支持变量 ##################
[root@localhost ~]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#输出分隔符
-F -FS一起使用 -F 的优先级高
############ OFS ##########
[root@localhost ~]#awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
root==0
bin==1
daemon==2
adm==3
lp==4
sync==5
######## RS #######
默认是已 /n (换行符)为一条记录的分隔符
不动他
[root@localhost ~]#echo $PATH | awk -v RS=':' '{print $0}'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
################## NF ###################
代表字段的个数
[root@localhost ~]#awk -F: '{print NF}' /etc/passwd
[root@localhost ~]#awk -F: '{print $NF}' /etc/passwd
#$NF最后一个字段
[root@localhost ~]#df|awk -F: '{print $(NF-1)}'
#倒数第二行
################ NR ######################
行号
[root@localhost ~]#awk '{print $1,NR}' /etc/passwd
##行号
[root@localhost ~]#awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一个字段
[root@localhost ~]#awk 'NR%2==0' /etc/passwd
#偶数行
[root@wyx etc]#awk 'NR==1||NR==3{print}' passwd
#打印出1和3行
[root@wyx etc]#awk '(NR%2)==0{print NR}' passwd
#打印出函数取余数为0行
[root@wyx etc]#awk '(NR%2)==1{print NR}' passwd
#打印出函数取余数为1的行
[root@localhost ~]#awk '$3>1000{print}' /etc/passwd
#注意分隔符
#打印出普通用户 第三列 大于1000 的行
################ FNR ############
[root@localhost data]#cat /etc/issue |wc -l
3
[root@localhost data]#cat /etc/os-release |wc -l
16
[root@localhost data]#awk '{print FNR}' /etc/issue /etc/os-release
1
2
3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15