c语言qsort函数的模拟实现
模拟实现qsort函数
- 关于qsort函数的预备知识
-
- 回调函数
-
- 函数指针类型解析
- qsort函数用法及相关参数
- 冒泡排序算法
- 模拟实现方法介绍
- 源代码
关于qsort函数的预备知识
回调函数
回调函数就是⼀个通过函数指针调用的函数。
如果你把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被用来调用其所指向的函数时,被调用的函数就是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
这样讲也许会有点抽象,等下面讲到实际案例时再具体介绍:>
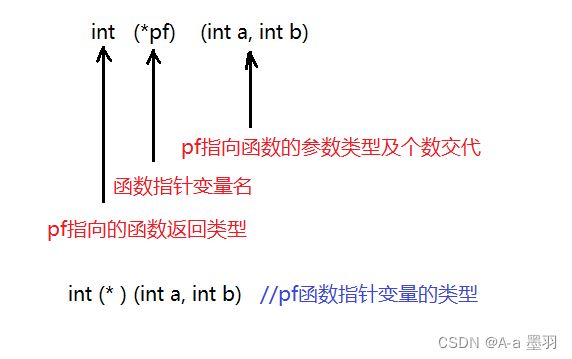
函数指针类型解析
听到函数指针这名字,我们肯定会想到这一定是个指针吧!其实不然,指针都是用来存放地址的,那么函数指针变量应该是用来存放函数地址的,未来通过地址能够调用函数的。
那么怎么得到一个函数的地址呢?我们来写一段代码:

通过调试我们不难看出函数是有地址的,函数名就是函数的地址,当然也可以通过&函数名的方式获得函数的地址。那么该如何接收函数的地址呢?这时就引入了函数指针,就以Add函数为例吧:
qsort函数用法及相关参数
我们看一下 cplusplus.com给出的解释吧!


(1) 第一个参数便是待排序的第一个元素的地址(此处base指向该地址),因为不知到该元素的类型,所以用void*来作变量名;
(2) 第二个参数是待排序的元素个数;
(3) 第三个参数便是待排序的每个元素的大小;
(4) 第三个参数是一个函数指针,指向的compar函数能比较两个元素,这个函数是要我们自己实现的;
我们可以观察到compar函数返回类型是int,参数类型是const void*。需要注意的是类型为void*的参数并不能直接比较大小,必须先进行类型转换才能比较!!!
冒泡排序算法
我们看一下最初的冒泡排序算法:
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
int flag = 1;
for (int j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0;
}
}
if (flag == 1)
break;
}
}
int main()
{
int arr[] = { 1,5,3,6,8,8,5,9,6,5 };
int len = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, len);
for (int i = 0; i < len; i++)
{
printf("%d ", arr[i]);
}
putchar('\n');
return 0;
}
图解:

通过上面的图解,我们只要知道要循环多少次,其实就没有什么难的了。我们可以用两层for循环来实现冒泡排序。切记外层len次,内层len-i次循环。
模拟实现方法介绍
那么既然明白了冒泡排序算法,那如何改进成类似qsort函数呢?
其实依旧是两层循环,外层len,内存len-i次。有所改变的是比较函数cmp((char*)base + j * width, (char*)base + (j + 1) * width);
因为不好将待排序元素直接交换,所以这里又用到一个交换函数Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);;
这两个函数中的base都被转为了char*,为什么呢?因为我们并不知道具体的元素类型,为了方便遍历,所以将void*转为char*类型。这时肯定有人会问,为什么不转变为int*,short*等等类型?
答案就在待排序的元素大小,如果待排序的每个元素是结构体,每个占9字节,那么占4字节的int,占2字节的short并不能被整除,从而导致交换不完全!也是为了能让Swap函数每次都能传待比较元素的首字节地址,并且通过j*width和(j+1)*width每次都能跳过一个元素。
void Swap(char* buf1, char* buf2, size_t width)
{
for (int i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++; buf2++;
}
}
所以这的Swap函数中每次交换一个字节,交换width次,便是交换了一个元素,用一个for循环便可实现。
源代码
struct Stu
{
char name[20];
int age;
};
//比较数组元素
int cmp_int(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
//比较结构体中的年龄
int cmp_str_by_age(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
//比较结构体中的字符串
int cmp_str_by_name(const void* e1, const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
//交换两个元素(因为不知道元素类型,所以以一字节为单位逐个交换,至width大小)
void Swap(char* buf1, char* buf2, size_t width)
{
for (int i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++; buf2++;
}
}
//其中调用函数指针,指向cmp函数
void bubble_sort(void* base, size_t sz, size_t width, int (*cmp)(const void* e1, const void* e2))
{
int i = 0;
for (i = 0; i < sz; i++)
{
int flag = 1;//测试是否已排序完成,提高效率
for (int j = 0; j < sz - 1 - i; j++)
{
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
flag = 0;
}
}
if (flag == 1)
break;
}
}
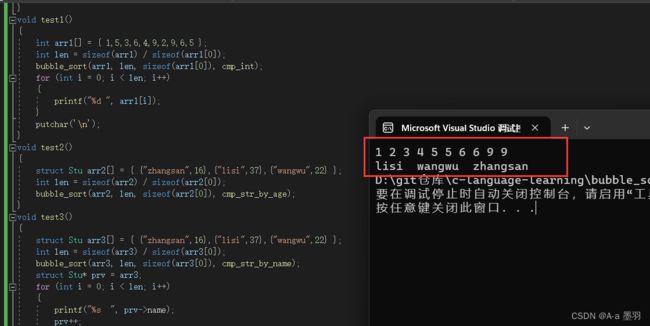
//整形数组
void test1()
{
int arr1[] = { 1,5,3,6,4,9,2,9,6,5 };
int len = sizeof(arr1) / sizeof(arr1[0]);
bubble_sort(arr1, len, sizeof(arr1[0]), cmp_int);
for (int i = 0; i < len; i++)
{
printf("%d ", arr1[i]);
}
putchar('\n');
}
//结构体数组--比较age,整形
void test2()
{
struct Stu arr2[] = { {"zhangsan",16},{"lisi",37},{"wangwu",22} };
int len = sizeof(arr2) / sizeof(arr2[0]);
bubble_sort(arr2, len, sizeof(arr2[0]), cmp_str_by_age);
}
//结构体数组--比较name,字符串
void test3()
{
struct Stu arr3[] = { {"zhangsan",16},{"lisi",37},{"wangwu",22} };
int len = sizeof(arr3) / sizeof(arr3[0]);
bubble_sort(arr3, len, sizeof(arr3[0]), cmp_str_by_name);
struct Stu* prv = arr3;
for (int i = 0; i < len; i++)
{
printf("%s ", prv->name);
prv++;
}
}
int main()
{
//三个测试函数
test1();
//test2();
test3();
return 0;
}