【对比学习】从个体判别到多视角/模态判别
1. 前言
近期笔者重新阅读了对比学习(Contrastive learning)领域的4篇较为早期的文献(2019-2020),包括个体判别( instance discrimination)模型、instance Invariant and Spreading模型、CPC模型和CMC模型。

之所以去阅读对比学习的相关文献,是笔者通过学习多模态大模型时发现,现有多模态大模型(如CLIP模型)很多都是基于对比学习进行预训练,然后再在特定任务上进行微调的。
所以笔者就决定先简单阅读一些对比学习的文献,看看这个领域的发展,在脑子里留个大致印象后再较为深入探索多模态大模型这个领域,以及去探索多模态大模型在交通领域的潜在应用。

本文也是看过B站李沐老师视频后做的简单总结,这里也强烈建议感兴趣的小伙伴去B站看一下原视频:对比学习论文综述【论文精读】_哔哩哔哩_bilibili
2. instance discrimination
2.1 简介
-
论文名《Unsupervised Feature Learning via Non-Parametric Instance Discrimination 》-
-
发表年份:2018
-
代码:http://github.com/zhirongw/lemniscate.pytorch
-
摘要:本文提出了一种以“个体判别"(instance discrimination)为任务的无监督学习方法,也就是将数据集中的每个个体当做一个类别,目标是学习一种表征能把每一个图片都区分开来。基于这样学习好的表征,应用到各类下游任务中。
2.2 研究动机
如下图1所示,作者受到有监督学习的结果启发,发现如果将一张花豹的图片喂给一个通过有监督学习方式训练好的分类器(比如基于ImageNet训练好的ResNet),会发现他给出来的分类结果排名前几的全都是跟豹子相关的,有猎豹、美洲豹、雪豹之类。
这个现象表明,这种通过类别标签学习的判别式学习方法可以学到类别间的相似性,即使做的是判别任务(也就是将不同类别在特征空间的间隔增大)。作者认为,这种相似性学习并非来自给定的语义标签,而是来自于数据本身。
那么作者就在想,既然这种能力是来自于数据本身,那么能否仅利用数据本身而非语义标签,来自动学习一个好的图像特征表征呢?
到这,作者就在考虑能否将每个样本当做一个单独的类别,实现**“个体判别"**这个分类任务呢?
这里,作者思考了一下,如果把每个样本当做一个单独的类别,那么对于一个数据集来说,其类别数就等同于样本数了。对ImageNet数据集来说,类别说就从原来的1000到了120万。
作者认为这样会带来几个问题:
-
对于分类任务而言,一般使用softmax来输出类别的概率。如果softmax的输出维度过大(120万),那么会造成计算量大、且难以学习的问题;
-
经典的分类任务中,每一类是有很多样本的。而在“个体判别"任务中,每类就一个样本。那么在每个训练轮次中,每个类只会被访问一次,这会导致训练的时候存在大幅震荡的情况。
为了解决以上一些问题,作者提出了 利用噪声对比估计(noise-contrastive estimation,NCE)来近似完整的softmax分布;同时,引入了Proximal Regularization方法使得训练过程更稳定。
2.3 研究方法
(1)步骤
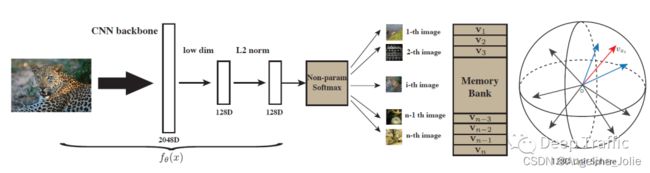
如图2所示,本文的研究方法在训练阶段的大致步骤可以归纳为:
-
(1)构建Memory bank。通过一个卷积神经网络和L2正则化把所有的图片都编码成维度为128的特征,保存成一个Memory bank(可见视为一个很大的字典表),这里降到128维度是考虑到内存开支;
-
(2)构建正样本和负样本。假如batch size是256,也就是说有256个图片进入到编码器中,获得256个128维度的特征。其中,正样本就是图片本身(可能经过一些数据增强),因此共有256个正样本。负样本则是从Memory bank中随机抽取的4,096个样本;
-
(3)设置NCE学习目标,更新网络参数。文章中用了较多的公式讲了如何利用NCE损失作为训练目标,其实简单理解就是利用NCE损失使得正负样本在特征空间的距离扩大,而正样本间(图像与其增强后的图像)的距离缩小;
-
(4)更新Memory bank。在训练过程中,每一个iteration更新完神经网络参数后,就可以把mini batch里的数据样本所对应的那些特征在 memory bank 里更换掉,这样 memory bank 就得到了更新;
-
(5)循环迭代。反复上述(1)-(4)的过程,最后学到这个特征尽可能的有区分性。
训练完毕后,模型的测试过程更加简单,具体为:
-
(1)计算测试图像的特征,不妨计算测试特征吧;
-
(2)计算测试特征与memory bank里面所有特征的余弦相似度;
-
(3)取相似度最大的个样本(k近邻)用来做加权投票;
-
(4)根据加权投票结果进行测试图像所属类别的预测。
(2)Proximal Regularization
作者发现在“个体判别"任务训练过程中存在大幅震荡的情况。为了使得训练更稳定,引入了Proximal Regularization方法。
具体地,作者在损失函数上引入了一个约束,使得 memory bank 里的那些特征进行动量式更新。
这个约束本质上就是一个二范数,迫使前后iteration的memory bank尽可能相等。这样, memory bank 里面的特征就不会变的太快了。
2.4 意义
Inst Disc 这篇论文是对比学习的一个里程碑式的工作:
-
它不仅提出了个体判别这个代理任务,而且用这个代理任务用** NCE loss**做对比学习,从而取得了不错的无监督表征学习的结果
-
同时它还提出了用memory bank的数据结构存储这种大量的负样本,以及如何对特征进行动量的更新,所以真的是对后来对比学习的工作起到了至关重要的推进作用
3. instance Invariant and Spreading
3.1 简介
-
论文名《Unsupervised Embedding Learning via Invariant and Spreading Instance Feature 》
-
发表年份:2019
-
摘要:本文也提出了一种以“个体判别"(instance discrimination)为代理任务的无监督学习方法。与前面的instance discrimination方法不同的是,该方法抛弃了memory bank去存储大量的负样本,它的正负样本就是来自于同一个minibatch。其中,正样本为图像与其自身增强后的图像形成的数据对,负样本则为某图像与除自身和其增强图像后的所有样本所形成的数据对。作者之所以在同一个 mini-batch 里去选正负样本,是因为这样就可以用一个编码器做端到端的训练了,这也就是MoCo(一个很有名的对比学习方法,后续会提到)里讲过的端到端的学习方式。
3.2 研究方法
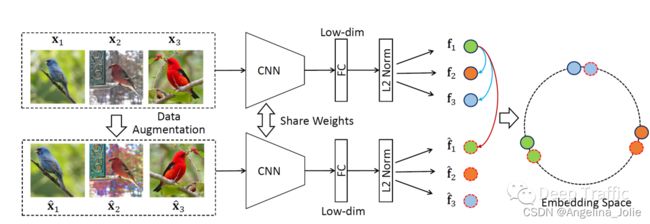
如图3所示,本文的研究方法前向阶段的大致步骤可以归纳为:
-
以 batch size 为256为例,也就是一共有256个图片,经过数据增强,又得到了增强后的256张图片,总计512张图像;
-
对于 这张图片,是其增强后的图像, 那么 就是一对正样本;而 的负样本是所有剩下的图片(除自身和其增强图像后的所有样本)。那么,正样本的数量总数为256,任意图像的负样本的数量为510(512-2)。需要注意的是在instance discrimination方法中,正样本虽然是256,它的负样本是从一个 memory bank 里抽出来的,它用的负样本是4096甚至还可以更大;
-
剩下的前向过程都是差不多的,就是过完编码器以后,再过一层全连接层就把这个特征的维度降的很低(128维),然后利用NCE loss使得正样本(比如说上图中绿色圆圈)在最后的特征空间上应该尽可能的接近,负样本的特征(颜色不一的圆圈)应该尽可能的拉远;
3.3 意义
其实本文方法最后取得的效果也比较一般,但本文提出的这种在一个minibach找正样本和负样本的想法,后续被很多知名的工作(比如MoCo, SimCLR )所借鉴。
至于为什么它没有取得好的结果呢?最主要的原因就是他的负样本数还是太少了,在对比学习中,默认认为负样本的数量是越多越好的。然而,本文的作者是没有 TPU 来提升batch size的大小的(财力有限),再加上缺少像 SimCLR 中采用的那么强大的数据增广以及最后提出的那个 mlp projector,所以说呢这篇论文的结果没有那么炸裂,自然也就没有吸引大量的关注,但事实上它是可以理解成 SimCLR 的前身。
4. Contrastive Predictive Coding
4.1 简介
-
论文名《Representation Learning with Contrastive Predictive Coding 》
-
发表年份:2019
-
代码:https://github.com/davidtellez/contrastive-predictive-coding
-
摘要:前面提到的两种方法都是判别式模型,而本文提出了一种生成式模型(执行预测任务)进行对比学习,即Contrastive Predictive Coding,以下我们统称

为CPC。而且,CPC这种生成式的方法使得模型能够处理各类信号,如文本、语音和图像等等。其大致原理是:通过最大化预测正确的上下文与给定的目标之间的互信息来学习有用的数据表示。
4.2 研究方法
如图4所示,本文的研究方法的大致步骤可以归纳为:


这里,我再给出GPT4对于CPC流程的描述(个人认为讲的很对),如下:

5 contrastive multiview coding
5.1 简介
-
论文名《Contrastive Multiview Coding》
-
发表年份:2020
-
代码:https://github.com/HobbitLong/CMC/
-
摘要:Contrastive Multiview Coding(CMC)实现了多视角的对比学习,一个物体的很多个视角/模态都可以被当做正样本,而不同物体间则可视为负样本。
5.2 研究动机
人观察这个世界是通过很多个传感器,比如说眼睛或者耳朵都充当着不同的传感器来给大脑提供不同的信号。每一个视角都是带有噪声的,而且有可能是不完整的,但是最重要的那些信息其实是在所有的这些视角中间共享,比如说基础的物理定律、几何形状或者说它们的语音信息都是共享的。
在这里举了个很好的例子:比如一个狗既可以被看见,也可以被听到或者被感受到。基于这个现象作者就提出:他想要学一个非常强大的特征,它具有视角的不变性(不管看哪个视角,到底是看到了一只狗,还是听到了狗叫声,都能判断出这是个狗)。
其中CMC的目的就是去增大所有的视角之间的互信息,进而学到一种特征能够抓住所有视角下的关键的因素。
5.3 研究方法

如图5所示,以 NYU RGBD 这个数据集为例,注:这个数据集有同时四个视角的数据:原始的图像、这个图像对应的深度信息(每个物体离观察者到底有多远)、SwAV ace normal、这个物体的分割图像。本文的研究方法可以归纳为:
如果不同输入对应同一张图像(描述同一个东西),尽管它们可能来自于不同的传感器或者说不同的模态,那它们就应该互为正样本。也就是说,当有一个特征空间的时候,比如图5中圆圈所示的特征空间,这四种模态(4个绿色的点)在这个特征空间里就应该非常的接近。这时候如果随机再去挑一张图片,不论是用图片还是用风格的图像(总之属于一个不配对的视角)的话,这个特征就应该跟这些绿色的特征远离。其大致步骤可归纳为:
-
(1)数据预处理: CMC要求对每个输入数据创建两种或多种不同的视图。这种视图可以是不同的数据增强策略、不同的模态,等等。例如,在图像处理中,可能会对原始图像进行裁剪、翻转、颜色扭曲等操作来生成不同的视图。
-
(2)特征提取: 使用深度神经网络(如CNN)分别对两种视图进行特征提取,得到两个嵌入向量。
-
(3)对比学习: 在对比学习阶段,网络被训练来使同一个样本的两种视图(正样本对)的特征向量更接近,而与其他样本的视图(负样本对)的特征向量更远离。这通常通过最大化正样本对的相似度和最小化负样本对的相似度来实现,这个相似度通常用余弦相似度或者点积等度量。
-
(4)优化: 通过反向传播和优化算法(如Stochastic Gradient Descent)来更新网络权重,以改善对比学习目标。
-
(5)重复迭代: 重复步骤2-4,直到达到预定的迭代次数或满足其他停止条件。
5.4 意义
CMC可是视为第一个或者说比较早的工作去做这种多视角的对比学习,它不仅证明了对比学习的灵活性,而且证明了这种多视角、多模态的这种可行性。这篇工作也为CLIP这篇工作奠定了基础。
所以说接下来open AI,很快就出了CLIP模型:也就是说如果有一个图片,还有一个描述这个图片的文本,那这个图像和文本就可以当成是一个正样本对,就可以拿来做多模态的对比学习。
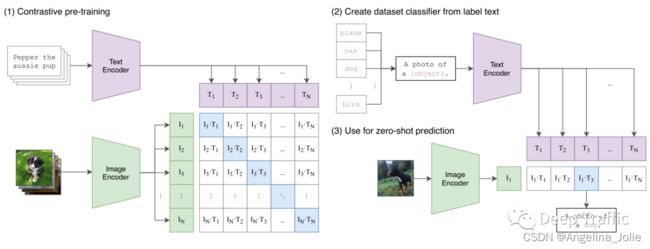
这里再说CMC模型的一个小小的局限性:当处理不同的视角或者说不同的模态时候,可能需要不同的编码器,因为不同的输入可能长得很不一样,这就有可能会导致使用几个视角,有可能就得配几个编码器,在训练的时候这个计算代价就有点高(比如说在CLIP这篇论文里,它的文本端就是用一个大型的语言模型,比如说 BERT,它的图像端就是用一个 VIT,就需要有两个编码器)。
不过这个局限性已经在现有研究中被很好地缓解了。一些研究已经发现Transformer有可能能同时处理不同模态的数据。也就是用一个Transformer网络同时处理图像和文本,这可能相比于使用不同的编码器,反而效果会更好了。这也展示了 Transformer 真正吸引人的地方:一个网络能处理很多类型的数据,而不用做针对每个数据特有的改进。
6 总结
本文主要对一些较为早期的对比学习方法进行了简单总结,虽然这些方法有的名气可能不是特别大,至少相较于后面的MoCo,SimCLR以及CLIP来说名气较小,但确实也是后续这些有名工作的基础,所以我特此写了这篇总结文。