Java 使用 druid 进行sql 语句的词法、语法解析
参考链接:https://blog.csdn.net/yuanzhengme/article/details/121229360
1.druid环境安装
此文档安装环境:Ubuntu18.04/java-8(PS:java-8以上支持性没有java8好)
官方对于环境描述:
Java 8 (8u92+)
Linux, Mac OS X, or other Unix-like OS (Windows is not supported)
1.1java-8安装
sudo apt-get install openjdk-8-jdk
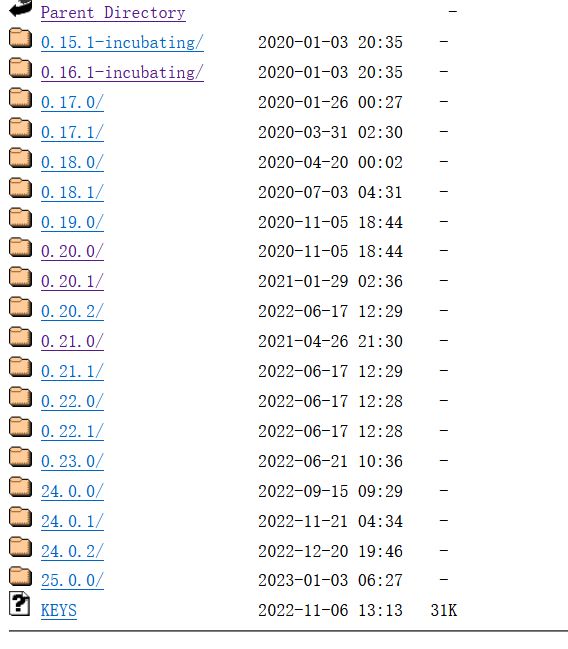
https://archive.apache.org/dist/druid/
1.2 安装mysql数据库
1.安装mysql-server
sudo apt install mysql-server
2.初始化配置
sudo mysql_secure_installation
#1
VALIDATE PASSWORD PLUGIN can be used to test passwords...
Press y|Y for Yes, any other key for No: N (我的选项)
#2
Please set the password for root here...
New password: (输入密码)
Re-enter new password: (重复输入)
#3
By default, a MySQL installation has an anonymous user,
allowing anyone to log into MySQL without having to have
a user account created for them...
Remove anonymous users? (Press y|Y for Yes, any other key for No) : N (我的选项)
#4
Normally, root should only be allowed to connect from
'localhost'. This ensures that someone cannot guess at
the root password from the network...
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : Y (我的选项)
#5
By default, MySQL comes with a database named 'test' that
anyone can access...
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : N (我的选项)
#6
Reloading the privilege tables will ensure that all changes
made so far will take effect immediately.
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : Y (我的选项)
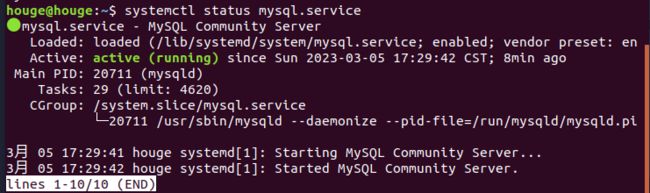
3.检查mysql服务状态
systemctl status mysql.service
显示如下结果说明mysql服务是正常的
4.使用默认的用户名和密码登录修改PLUGIN设置
查看系统默认的用户名和密码
sudo cat /etc/mysql/debian.cnf
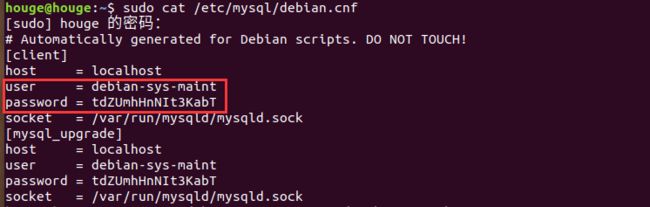
使用默认用户名密码登录
mysql -u('上图中的用户名') -p('上图中的密码')

修改PLUGIN设置
UPDATE mysql.user SET authentication_string=PASSWORD('root'), PLUGIN='mysql_native_password' WHERE USER='root';
设置完成之后重启服务
sudo service mysql stop
sudo service mysql start
5.使用mysql -uroot -p 输入密码之后密码进入数据库
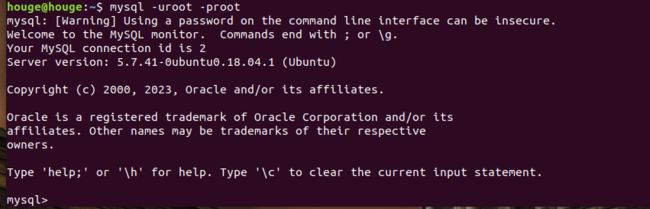
PS:如果出现这种错误按照如下步骤来
出现场景:这个问题一般出现在刚刚安装完mysql的时候
出现原因:由于使用命令sudo apt-get install mysql安装时,并没有提示输入密码,则密码没有初始化,使用root用户登录自然失败.
具体情况:

执行步骤四4.使用默认的用户名和密码登录即可。
再次使用mysql -uroot -proot的方式即可登录
ps:查看mysql状态和mysql卸载重装过程
#查看mysql状态
sudo service mysql status
#启动mysql服务
sudo service mysql start
#停止mysql服务
sudo service mysql stop
#重启mysql服务
sudo service msyql restart
#权限不够命令加 sudo
完全卸载
sudo rm /var/lib/mysql/ -R
sudo rm /etc/mysql/ -R
sudo apt-get autoremove mysql* --purge
sudo apt-get remove apparmor
安装
sudo apt-get update
sudo apt-get install mysql-server
1.3 Mysql配置数据库远程访问(远程访问情况下需要配置)
在Ubuntu下MySQL缺省是只允许本地访问的,在本机之外使用是连不上的;如果你要其他机器也能够访问的话,需要进行配置.
首先要把MySQL的默认连接端口3306打开,查其看是否开放:
netstat -an | grep 3306
查看的结果如下(这表示未开放)

在配置文件中说明端口号
cd /etc/mysql/mysql.conf.d/
sudo vim mysqld.cnf
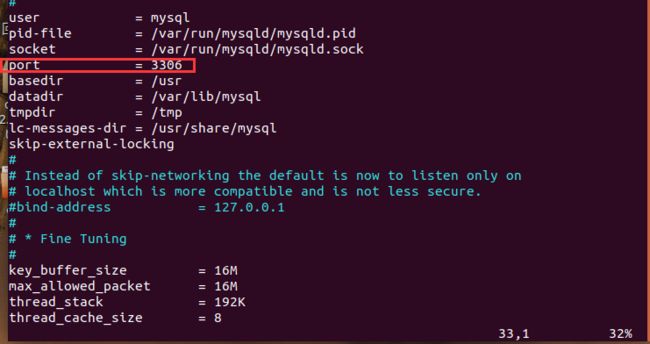
再次查看3306端口号

接着编辑mysqld.cnf 的配置文件
cd /etc/mysql/mysql.conf.d/
sudo vim mysqld.cnf
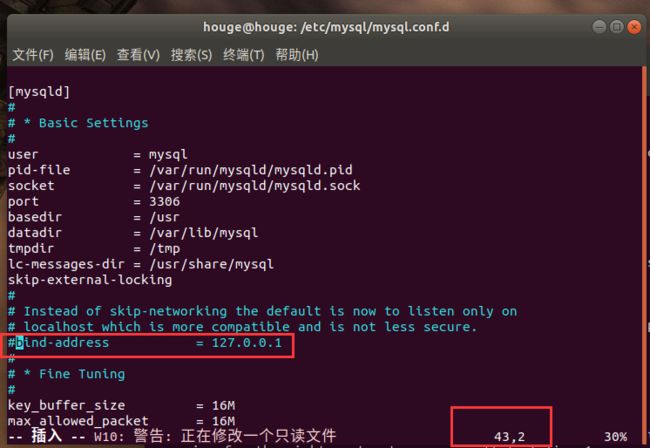
随后重启MySQL让其生效
service mysql restart
然后用根用户进入mysql
sudo mysql -uroot -p
GRANT ALL PRIVILEGES ON *.* to root@'%' IDENTIFIED BY 'root';
%代表所有主机,也可以是具体的ip;


上文中root的host已经是%,意思是所有不同主机都可以连接到此处的mysql来
1.4 druid安装过程
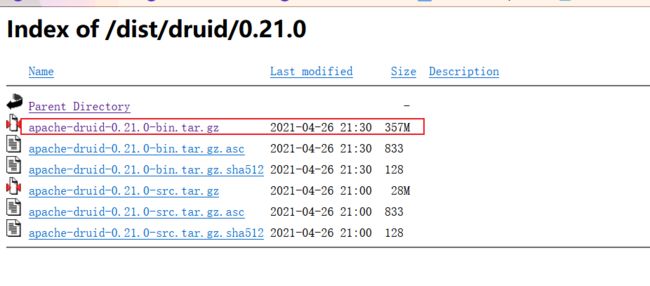
tar -zxvf apache-druid-0.21.0-bin.tar.gz
mv apache-druid-0.21.0 /usr/local/druid
进入apache-druid的安装目录后,我们可以看一下各子目录和文件的功能:
bin/:用于快速入门的脚本。
conf/:单机和集群设置的配置示例。
extensions/:核心Druid扩展。
hadoop-dependencies/:Druid的Hadoop依赖。
lib/:核心Druid的库和依赖。
quickstart/:快速入门的配置文件、样例数据和其他文件。
DISCLAIMER、LICENSE和NOTICE文件。
1.5 druid快速启动
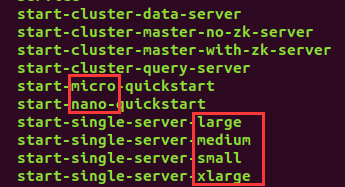
Nano-Quickstart: 1 CPU, 4GB RAM
Micro-Quickstart: 4 CPU, 16GB RAM
Small: 8 CPU, 64GB RAM (~i3.2xlarge)
Medium: 16 CPU, 128GB RAM (~i3.4xlarge)
Large: 32 CPU, 256GB RAM (~i3.8xlarge)
X-Large: 64 CPU, 512GB RAM (~i3.16xlarge)
根据自己运行环境选择相应的启动选项,本文档选用的是start-nano-quickstart。在apache-druid-0.21.0(Druid的安装目录)下,运行./bin/start-nano-quickstart命令。这个命令用于启动Druid。也可以在bin目录下直接运行./start-nano-quickstart,如果权限不够加上sudo即可。
 如果是安装在本机中的话,在浏览器中输入:localhost:8888即可访问Druid了
如果是安装在本机中的话,在浏览器中输入:localhost:8888即可访问Druid了

2.druid入门小试
下载mysql和durid的jar包
mysql的jar包https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.25/
druid的jar包https://repo1.maven.org/maven2/com/alibaba/druid/1.1.13/
2.1 通过Druid配置文件使用
1. 导入mysql和DRUID jar 包
2. 拷贝配置文件到src目录
3. 根据配置文件创建Druid连接池对象
4. 从Druid连接池对象获得Connection
配置文件:
# 数据库连接参数
url=jdbc:mysql://(数据库地址):3306/[这里输入数据库文件名路径]
username=[这里输入数据库用户名]
password=[这里输入数据库密码]
driverClassName=com.mysql.jdbc.Driver//驱动
# 连接池的参数
initialSize=10//初始化连接数
maxActive=10//最大最大活动连接数
maxWait=2000//最大等待时间
2.2 使用druid
druid底层是使用的工厂设计模式,去加载配置文件
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
//
public class TestDruid {
public void test01() throws Exception {
//配置文件的方式使用Druid连接池
//1. 创建Properties对象
Properties properties = new Properties();
//2. 将配置文件转换成字节输入流
InputStream is = TestDruid.class.getClassLoader().getResourceAsStream("druid.properties");
//3. 使用properties对象加载is
properties.load(is);
//druid底层是使用的工厂设计模式,去加载配置文件,创建DruidDataSource对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection conn1 = dataSource.getConnection();
Connection conn2 = dataSource.getConnection();
Connection conn3 = dataSource.getConnection();
Connection conn4 = dataSource.getConnection();
Connection conn5 = dataSource.getConnection();
Connection conn6 = dataSource.getConnection();
Connection conn7 = dataSource.getConnection();
Connection conn8 = dataSource.getConnection();
Connection conn9 = dataSource.getConnection();
Connection conn10 = dataSource.getConnection();
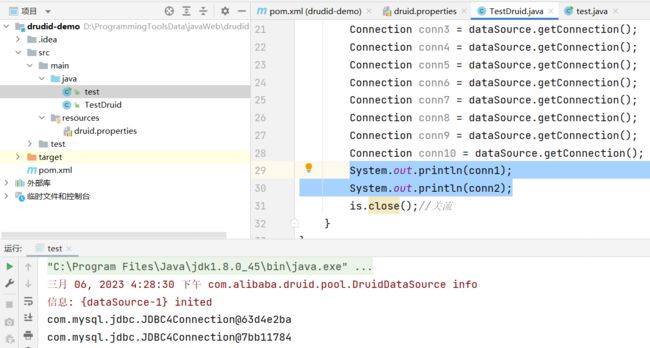
System.out.println(conn1);
System.out.println(conn2);
is.close();//关流
}
}
出现下图即为成功
3.sql语句中词法\语法分析
3.1Druid格式化SQL语句
String sql3 =
"select \n" +
" t1.*\n" +
" ,t2.*\n" +
"from\n" +
"(\n" +
" select \n" +
" shop_id 门店id\n" +
" ,shop_name 门店名称\n" +
" from tableA\n" +
" where pt=20201130\n" +
" and shop_level>=8 --注释\n" +
") t1\n" +
"left join\n" +
"(\n" +
" SELECT \n" +
" shop_id\n" +
" ,sum(create_orders) AS 创建订单数\n" +
" ,sum(payment_amount) AS 支付订单金额\n" +
" ,sum(pay_orders) AS 成功订单数\n" +
" ,sum(pay_amount) AS 成功订单金额\n" +
" ,sum(coalesce(ninety_orders,0) -coalesce(ninety_refund_orders,0)) AS XX元订单数\n" +
" ,sum(coalesce(ninety_order_amount,0) - coalesce(ninety_refund_amount,0)) AS XX元订单金额\n" +
" ,sum(zero_orders) AS 0元订单数\n" +
" ,sum(coalesce(pay_orders,0) - coalesce(zero_orders,0)) AS 付费订单数\n" +
" FROM tableB\n" +
" WHERE substr(pt,1,6) = '202011'\n" +
" GROUP BY \n" +
" shop_id\n" +
") t2 on t1.门店id = t2.shop_id\n" +
";";
List<SQLStatement> sqlStatementList = SQLUtils.parseStatements(sql3,JdbcConstants.MYSQL);
System.out.println(sqlStatementList);
System.out.println();

3.2 Druid 解析 insert语句
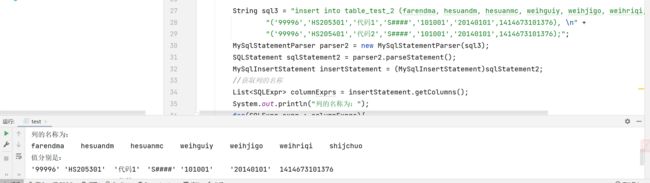
String sql = "insert into table_test_2 (farendma, hesuandm, hesuanmc, weihguiy, weihjigo, weihriqi, shijchuo) values\n" +
"('99996','HS205301','代码1','S####','101001','20140101',1414673101376), \n" +
"('99996','HS205401','代码2','S####','101001','20140101',1414673101376);";
MySqlStatementParser parser = new MySqlStatementParser(sql);
SQLStatement sqlStatement = parser.parseStatement();
MySqlInsertStatement insertStatement = (MySqlInsertStatement)sqlStatement;
//获取列的名称
List<SQLExpr> columnExprs = insertStatement.getColumns();
System.out.println("列的名称为:");
for(SQLExpr expr : columnExprs){
System.out.print(expr + "\t");
}
System.out.println();
//获取插入的值
List<SQLInsertStatement.ValuesClause> valuesClauseList = insertStatement.getValuesList();
System.out.println("值分别是:");
for(SQLInsertStatement.ValuesClause valuesClause : valuesClauseList){
List<SQLExpr> valueExprList = valuesClause.getValues();
for(SQLExpr expr : valueExprList){
System.out.print(expr + "\t");
}
System.out.println();
}
3.3 Druid 解析 update语句
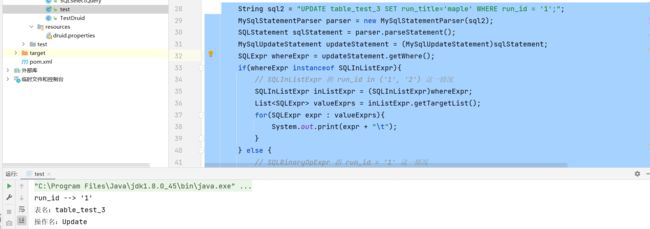
String sql2 = "UPDATE table_test_3 SET run_title='maple' WHERE run_id = '1';";
MySqlStatementParser parser = new MySqlStatementParser(sql2);
SQLStatement sqlStatement = parser.parseStatement();
MySqlUpdateStatement updateStatement = (MySqlUpdateStatement)sqlStatement;
SQLExpr whereExpr = updateStatement.getWhere();
if(whereExpr instanceof SQLInListExpr){
// SQLInListExpr 指 run_id in ('1', '2') 这一情况
SQLInListExpr inListExpr = (SQLInListExpr)whereExpr;
List<SQLExpr> valueExprs = inListExpr.getTargetList();
for(SQLExpr expr : valueExprs){
System.out.print(expr + "\t");
}
} else {
// SQLBinaryOpExpr 指 run_id = '1' 这一情况
SQLBinaryOpExpr binaryOpExpr = (SQLBinaryOpExpr) whereExpr;
System.out.println(binaryOpExpr.getLeft() + " --> " + binaryOpExpr.getRight());
}
String dbType = JdbcConstants.MYSQL;
List<SQLStatement> sqlStatementList = SQLUtils.parseStatements(sql2,dbType);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < sqlStatementList.size(); i++) {
builder.append(sqlStatementList.get(i));
}
String substring = builder.substring(0, builder.length() - 1);
MySqlStatementParser parser2 = new MySqlStatementParser(substring);
SQLStatement sqlStatement2 = parser2.parseStatement();
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
sqlStatement2.accept(visitor);
Map<TableStat.Name, TableStat> tableStatMap = visitor.getTables();
for(Map.Entry<TableStat.Name, TableStat> tableStatEntry: tableStatMap.entrySet()) {
System.out.println("表名:" + tableStatEntry.getKey().getName());
System.out.println("操作名:" + tableStatEntry.getValue());
}
3.4 Druid 解析 group by/order by语句
String sql = "select age a,name n from student s inner join (select id,name from score where sex='女') temp on sex='男' and temp.id in(select id from score where sex='男') where student.name='zhangsan' group by student.age order by student.id ASC;";
System.out.println("SQL语句为:" + sql);
//格式化输出
String result = SQLUtils.format(sql, JdbcConstants.MYSQL);
System.out.println("格式化后输出:\n" + result);
System.out.println("*********************");
// 使用工具类直接获取到AST
List<SQLStatement> sqlStatementList = SQLUtils.parseStatements(sql,JdbcConstants.MYSQL);
SQLStatement stmt = sqlStatementList.get(0);
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
stmt.accept(visitor);
System.out.println("数据库类型\t\t" + visitor.getDbType());
//获取字段名称
System.out.println("查询的字段\t\t" + visitor.getColumns());
//获取表名称
System.out.println("表名\t\t\t" + visitor.getTables().keySet());
System.out.println("条件\t\t\t" + visitor.getConditions());
System.out.println("order by\t\t" + visitor3.getOrderByColumns());
System.out.println("group by\t\t" + visitor.getGroupByColumns());

3.5 综合案例
String sql3 =
"select \n" +
" t1.*\n" +
" ,t2.*\n" +
"from\n" +
"(\n" +
" select \n" +
" shop_id 门店id\n" +
" ,shop_name 门店名称\n" +
" from tableA\n" +
" where pt=20201130\n" +
" and shop_level>=8 --注释\n" +
") t1\n" +
"left join\n" +
"(\n" +
" SELECT \n" +
" shop_id\n" +
" ,sum(create_orders) AS 创建订单数\n" +
" ,sum(payment_amount) AS 支付订单金额\n" +
" ,sum(pay_orders) AS 成功订单数\n" +
" ,sum(pay_amount) AS 成功订单金额\n" +
" ,sum(coalesce(ninety_orders,0) -coalesce(ninety_refund_orders,0)) AS XX元订单数\n" +
" ,sum(coalesce(ninety_order_amount,0) - coalesce(ninety_refund_amount,0)) AS XX元订单金额\n" +
" ,sum(zero_orders) AS 0元订单数\n" +
" ,sum(coalesce(pay_orders,0) - coalesce(zero_orders,0)) AS 付费订单数\n" +
" FROM tableB\n" +
" WHERE substr(pt,1,6) = '202011'\n" +
" GROUP BY \n" +
" shop_id\n" +
") t2 on t1.门店id = t2.shop_id\n" +
";";
List<SQLStatement> sqlStatementList = SQLUtils.parseStatements(sql3,JdbcConstants.MYSQL);
System.out.println(sqlStatementList);
System.out.println();
/*语句分析*/
MySqlStatementParser parser = new MySqlStatementParser(sql3);
SQLStatement sqlStatement = parser.parseStatement();
SQLSelectStatement selectStatement = (SQLSelectStatement) sqlStatement;
MySqlSchemaStatVisitor visitor1 = new MySqlSchemaStatVisitor();
selectStatement.accept(visitor1);
System.out.println("数据库类型\t\t" + visitor1.getDbType());
//获取字段名称
System.out.println("查询的字段\t\t" + visitor1.getColumns());
//获取表名称
System.out.println("表名\t\t\t" + visitor1.getTables().keySet());
System.out.println("条件\t\t\t" + visitor1.getConditions());
System.out.println("group by\t\t" + visitor1.getGroupByColumns());
//解析sql语句的表名和操作名
System.out.println("自定义输出sql语句的表名和操作名");
Map<TableStat.Name, TableStat> tableStatMap = visitor1.getTables();
for(Map.Entry<TableStat.Name, TableStat> tableStatEntry: tableStatMap.entrySet()){
System.out.print("表名:" + tableStatEntry.getKey().getName());
System.out.println(",操作名:" + tableStatEntry.getValue());
}
//输出where条件操作的条件及值
System.out.println("自定义输出操作条件和值:");
List<TableStat.Condition> conditions = visitor1.getConditions();
for(int i=0;i<conditions.size();i++) {
TableStat.Column column = conditions.get(i).getColumn();
System.out.print(column.getName());
List<Object> values = conditions.get(i).getValues();
for (int j=0;j<values.size();j++){
System.out.println(":"+values.get(j));
}
}
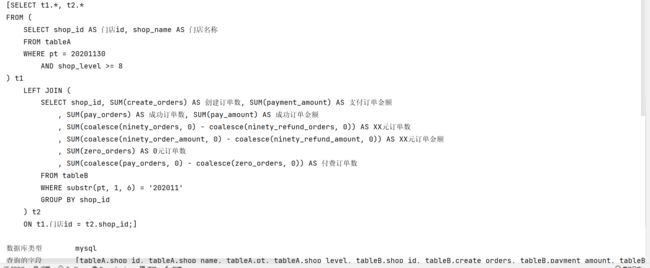
 3.6 手动描绘抽象语法树(Debug方式)
3.6 手动描绘抽象语法树(Debug方式)
String sql = "select * from t where id=1 or name='test' and age=14";
List<SQLStatement> sqlStatements = SQLUtils.parseStatements(sql, JdbcConstants.MYSQL);
System.out.println(sqlStatements);
 left
left
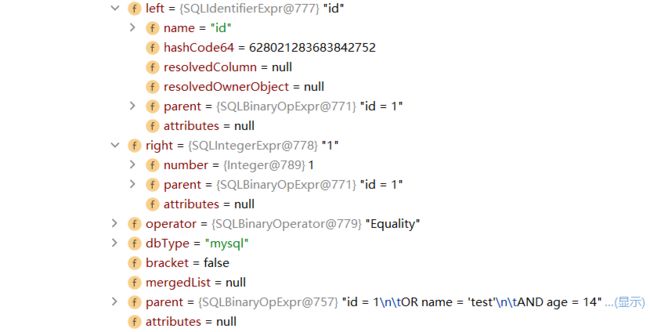
right
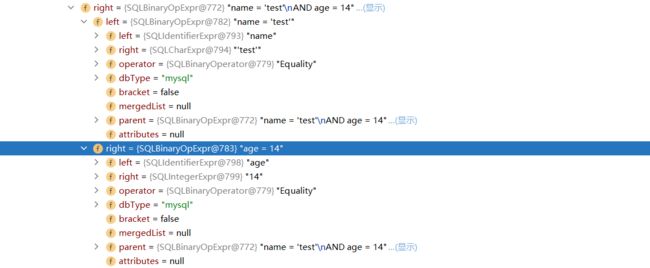
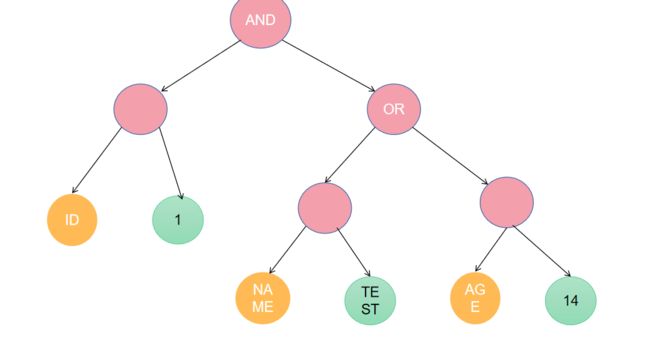
3.7 获取字段的数据类型
//1.获取连接
Connection conn = JDBCUtils.getConnection();
//2.定义sql
String sql="create table studenthtu2(id int,name varchar(255),PRIMARY KEY(id));";
//3.获取邮差对象
PreparedStatement ps = conn.prepareStatement(sql);
//4.执行sql
ps.executeUpdate();
List<SQLStatement> sqlStatementList = SQLUtils.parseStatements(sql, JdbcConstants.MYSQL);
//g格式化输出sql语句
System.out.println(sqlStatementList);
MySqlStatementParser parser = new MySqlStatementParser(sql2);
SQLStatement sqlStatement = parser.parseStatement();
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
sqlStatement.accept(visitor);
String dataType = visitor.getColumn("studenthtu2", "name").getDataType();
System.out.println(dataType);
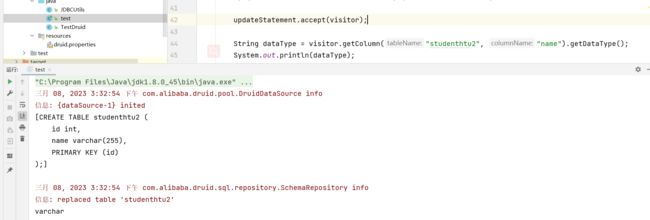 快速索引到sql语句中current这个字段是个datetime类型
快速索引到sql语句中current这个字段是个datetime类型
4.Druid的词法分析器Lexer
4.1 关键字
Druid是一个OLAP查询和分析引擎,它支持类SQL语言的查询。Druid的Lexer会将输入的SQL查询语句分解为词法单元(tokens)并进行解析。对于SQL关键字的解析,Druid的Lexer会将它们视为保留字(reserved words),并将它们作为特定类型的词法单元进行解析。下面是Druid支持的SQL关键字列表:
| SELECT | AS | WHERE |
|---|---|---|
| DELETE | CREATE | COMMENT |
| INSERT | ALTER | LIMIT |
| UPDATE | DROP | RIGHT JOIN |
| FROM | SET | IN |
| HAVING | DISTINCT | AND |
| ORDER | INDEX | IS NULL |
| PRIMARY | PRIMARY | ILIKE-REGEXP |
| GROUP | DESC | LIKE |
| INTO | ASC | SHOW |
对于输入的SQL查询语句中出现的关键字,Druid的Lexer会将它们解析成相应的词法单元类型,并将它们传递给解析器(Parser)进行下一步的语法分析。
SELECT("SELECT"),
DELETE("DELETE"),
INSERT("INSERT"),
UPDATE("UPDATE"),
FROM("FROM"),
HAVING("HAVING"),
WHERE("WHERE"),
ORDER("ORDER"),
BY("BY"),
GROUP("GROUP"),
INTO("INTO"),
AS("AS"),
CREATE("CREATE"),
ALTER("ALTER"),
DROP("DROP"),
SET("SET"),
NULL("NULL"),
NOT("NOT"),
DISTINCT("DISTINCT"),
TABLE("TABLE"),
TABLESPACE("TABLESPACE"),
VIEW("VIEW"),
SEQUENCE("SEQUENCE"),
TRIGGER("TRIGGER"),
USER("USER"),
INDEX("INDEX"),
SESSION("SESSION"),
PROCEDURE("PROCEDURE"),
FUNCTION("FUNCTION"),
PRIMARY("PRIMARY"),
KEY("KEY"),
DEFAULT("DEFAULT"),
CONSTRAINT("CONSTRAINT"),
CHECK("CHECK"),
UNIQUE("UNIQUE"),
FOREIGN("FOREIGN"),
REFERENCES("REFERENCES"),
EXPLAIN("EXPLAIN"),
FOR("FOR"),
IF("IF"),
GLOBAL("GLOBAL"),
ALL("ALL"),
UNION("UNION"),
EXCEPT("EXCEPT"),
INTERSECT("INTERSECT"),
MINUS("MINUS"),
INNER("INNER"),
LEFT("LEFT"),
RIGHT("RIGHT"),
FULL("FULL"),
OUTER("OUTER"),
JOIN("JOIN"),
STRAIGHT_JOIN("STRAIGHT_JOIN"),
ON("ON"),
SCHEMA("SCHEMA"),
CAST("CAST"),
COLUMN("COLUMN"),
USE("USE"),
DATABASE("DATABASE"),
TO("TO"),
AND("AND"),
OR("OR"),
XOR("XOR"),
CASE("CASE"),
WHEN("WHEN"),
THEN("THEN"),
ELSE("ELSE"),
ELSIF("ELSIF"),
END("END"),
EXISTS("EXISTS"),
IN("IN"),
NEW("NEW"),
ASC("ASC"),
DESC("DESC"),
IS("IS"),
LIKE("LIKE"),
ESCAPE("ESCAPE"),
BETWEEN("BETWEEN"),
VALUES("VALUES"),
INTERVAL("INTERVAL"),
LOCK("LOCK"),
SOME("SOME"),
ANY("ANY"),
TRUNCATE("TRUNCATE"),
RETURN("RETURN"),
TRUE("TRUE"),
FALSE("FALSE"),
LIMIT("LIMIT"),
KILL("KILL"),
IDENTIFIED("IDENTIFIED"),
PASSWORD("PASSWORD"),
DUAL("DUAL"),
BINARY("BINARY"),
SHOW("SHOW"),
REPLACE("REPLACE"),
PERIOD("PERIOD"),
BITS,
WHILE("WHILE"),
DO("DO"),
LEAVE("LEAVE"),
ITERATE("ITERATE"),
REPEAT("REPEAT"),
UNTIL("UNTIL"),
OPEN("OPEN"),
CLOSE("CLOSE"),
OUT("OUT"),
INOUT("INOUT"),
EXIT("EXIT"),
UNDO("UNDO"),
SQLSTATE("SQLSTATE"),
CONDITION("CONDITION"),
DIV("DIV"),
WINDOW("WINDOW"),
OFFSET("OFFSET"),
ROW("ROW"),
ROWS("ROWS"),
ONLY("ONLY"),
FIRST("FIRST"),
NEXT("NEXT"),
FETCH("FETCH"),
OF("OF"),
SHARE("SHARE"),
NOWAIT("NOWAIT"),
RECURSIVE("RECURSIVE"),
TEMPORARY("TEMPORARY"),
TEMP("TEMP"),
UNLOGGED("UNLOGGED"),
RESTART("RESTART"),
IDENTITY("IDENTITY"),
CONTINUE("CONTINUE"),
CASCADE("CASCADE"),
RESTRICT("RESTRICT"),
USING("USING"),
CURRENT("CURRENT"),
RETURNING("RETURNING"),
COMMENT("COMMENT"),
OVER("OVER"),
TYPE("TYPE"),
ILIKE("ILIKE"),
RLIKE("RLIKE"),
FULLTEXT("FULLTEXT"),
START("START"),
PRIOR("PRIOR"),
CONNECT("CONNECT"),
WITH("WITH"),
EXTRACT("EXTRACT"),
CURSOR("CURSOR"),
MERGE("MERGE"),
MATCHED("MATCHED"),
ERRORS("ERRORS"),
REJECT("REJECT"),
UNLIMITED("UNLIMITED"),
BEGIN("BEGIN"),
EXCLUSIVE("EXCLUSIVE"),
MODE("MODE"),
WAIT("WAIT"),
ADVISE("ADVISE"),
SYSDATE("SYSDATE"),
DECLARE("DECLARE"),
EXCEPTION("EXCEPTION"),
GRANT("GRANT"),
REVOKE("REVOKE"),
LOOP("LOOP"),
GOTO("GOTO"),
COMMIT("COMMIT"),
SAVEPOINT("SAVEPOINT"),
CROSS("CROSS"),
PCTFREE("PCTFREE"),
INITRANS("INITRANS"),
MAXTRANS("MAXTRANS"),
INITIALLY("INITIALLY"),
ENABLE("ENABLE"),
DISABLE("DISABLE"),
SEGMENT("SEGMENT"),
CREATION("CREATION"),
IMMEDIATE("IMMEDIATE"),
DEFERRED("DEFERRED"),
STORAGE("STORAGE"),
MINEXTENTS("MINEXTENTS"),
MAXEXTENTS("MAXEXTENTS"),
MAXSIZE("MAXSIZE"),
PCTINCREASE("PCTINCREASE"),
FLASH_CACHE("FLASH_CACHE"),
CELL_FLASH_CACHE("CELL_FLASH_CACHE"),
NONE("NONE"),
LOB("LOB"),
STORE("STORE"),
CHUNK("CHUNK"),
CACHE("CACHE"),
NOCACHE("NOCACHE"),
LOGGING("LOGGING"),
NOCOMPRESS("NOCOMPRESS"),
KEEP_DUPLICATES("KEEP_DUPLICATES"),
EXCEPTIONS("EXCEPTIONS"),
PURGE("PURGE"),
COMPUTE("COMPUTE"),
ANALYZE("ANALYZE"),
OPTIMIZE("OPTIMIZE"),
TOP("TOP"),
ARRAY("ARRAY"),
DISTRIBUTE("DISTRIBUTE"),
4.2 Java实现的Druid词法分析器Lexer对SQL关键字解析的例子
import com.alibaba.druid.sql.SQLUtils;
import com.alibaba.druid.sql.parser.Lexer;
import com.alibaba.druid.sql.parser.Token;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class test {
public static void main(String[] args) throws Exception{
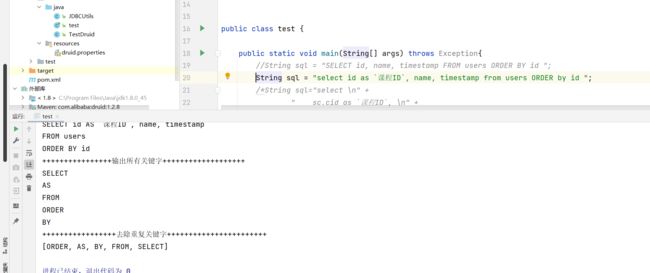
String sql = "select id as `课程ID`, name, timestamp from users ORDER by id ";
/*String sql="select \n" +
" sc.cid as `课程ID`, \n" +
" course.cname as `课程名称`,\n" +
" count(1) as `选学人数`,\n" +
" count(case when score < 60 then null else 1 end) as `合格人数`,\n" +
" count(case when score < 60 then 1 else null end) as `不合格人数`,\n" +
" round(avg(score)) as `平均成绩`,\n" +
" round(count(case when score < 60 then null else 1 end) / count(1), 2) as `通过率`,\n" +
" sum(case when score>= 85 then 1 else 0 end) as `100 - 85`,\n" +
" sum(case when score>= 70 and score< 85 then 1 else 0 end) as `85 - 70`,\n" +
" sum(case when score>= 60 and score<70 then 1 else 0 end) as `70 - 60`,\n" +
" sum(case when score< 60 then 1 else 0 end) as `60 - 0`\n" +
"from sc, course\n" +
"where sc.Cid = course.Cid\n" +
"group by sc.Cid;";*/
//格式化sql语句
String sqlStr = SQLUtils.formatMySql(sql);
System.out.println("+++++++++++++++++++++输出sql的格式化语句+++++++++++++++++++++++++");
System.out.println(sqlStr);
System.out.println("++++++++++++++++输出所有关键字+++++++++++++++++++");
// 实例化词法解析器
Lexer lexer = new Lexer(sqlStr);
List<String> keyList=new ArrayList<>();
while(true) {
// 解析下一个token
lexer.nextToken();
// 获得解析完的token,Token是一个枚举
Token tok = lexer.token();
if(tok != Token.IDENTIFIER){
if(testAllUpperCase(lexer.stringVal()) && isEnglish(lexer.stringVal()))
keyList.add(lexer.stringVal());
}
if (tok == Token.EOF) {
break;
}
}
for (int i = 0; i < keyList.size(); i++) {
//删除关键字中的NULL
if(keyList.get(i).equals("NULL")){
keyList.remove(i);
}
System.out.println(keyList.get(i));
}
System.out.println("+++++++++++++++++去除重复关键字+++++++++++++++++++++++");
// 使用HashSet去掉重复
Set<String> set = new HashSet<String>(keyList);
// 得到去重后的新集合
List<String> newList = new ArrayList<String>(set);
System.out.println(newList);
}
//判断字符串是否为大写字符
public static boolean testAllUpperCase(String str){
for(int i=0; i<str.length(); i++){
char c = str.charAt(i);
if(c >= 97 && c <= 122) {
return false;
}
}
return true;
}
//判断字符串是否为全英文
public static boolean isEnglish(String charaString) {
return charaString.matches("^[a-zA-Z]*");
}
}
 5.从mybatis的xml文件中提取sql语句
5.从mybatis的xml文件中提取sql语句
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 创建SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取所有的MappedStatement对象
Collection<MappedStatement> mappedStatements = sqlSession.getConfiguration().getMappedStatements();
// 遍历MappedStatement对象获取SQL语句
Iterator<MappedStatement> iterator = mappedStatements.iterator();
//存储 xml中的sql语句
Set<String> strXmlSql = new HashSet<String>();
//存储格式化之后的sql语句
Set<String> strFormatSql = new HashSet<String>();
//只要MappedStatement不为空就继续循环
while (iterator.hasNext()){
//当前的指针移向下一个
MappedStatement next = iterator.next();
//解析出当前的sql语句
String sql = next.getBoundSql("com.houge.Bean.User").getSql();
// 获取XML中的SQL语句,并存储在set集合中
strXmlSql.add(sql);
}
Iterator<String> itstrXmlSql = strXmlSql.iterator();
while(itstrXmlSql.hasNext())
{
//格式化sql语句
String sqlStr = SQLUtils.formatMySql(itstrXmlSql.next());
strFormatSql.add(sqlStr);
}
//输出格式化的sql语句
Iterator<String> itstrXmlFormatSql = strFormatSql.iterator();
while(itstrXmlFormatSql.hasNext())
{
String sqlStr = itstrXmlFormatSql.next();
System.out.println(sqlStr);
}

6.从mybatis的xml文件中提取sql语句并提取出关键字
package com.houge;
import java.io.InputStream;
import java.util.*;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import com.alibaba.druid.sql.SQLUtils;
import com.alibaba.druid.sql.parser.Lexer;
import com.alibaba.druid.sql.parser.Token;
import org.junit.Test;
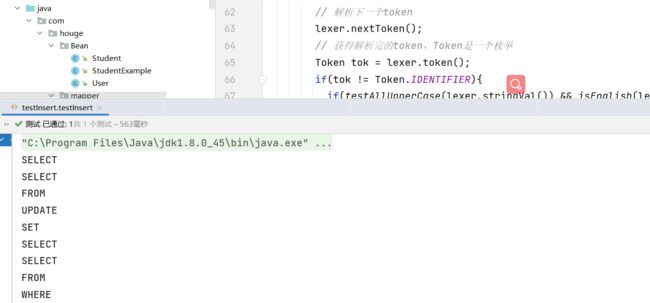
public class testInsert {
public void testInsert() throws Exception {
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 创建SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取所有的MappedStatement对象
Collection<MappedStatement> mappedStatements = sqlSession.getConfiguration().getMappedStatements();
// 遍历MappedStatement对象获取SQL语句
Iterator<MappedStatement> iterator = mappedStatements.iterator();
//存储 xml中的sql语句
Set<String> strXmlSql = new HashSet<String>();
//存储格式化之后的sql语句
Set<String> strFormatSql = new HashSet<String>();
//只要MappedStatement不为空就继续循环
while (iterator.hasNext()){
//当前的指针移向下一个
MappedStatement next = iterator.next();
//解析出当前的sql语句
String sql = next.getBoundSql("com.houge.Bean.User").getSql();
// 获取XML中的SQL语句,并存储在set集合中
strXmlSql.add(sql);
}
Iterator<String> itstrXmlSql = strXmlSql.iterator();
while(itstrXmlSql.hasNext())
{
//格式化sql语句
String sqlStr = SQLUtils.formatMySql(itstrXmlSql.next());
strFormatSql.add(sqlStr);
}
//从格式化的sql语句中提取sql关键字,并放到词法解析器中进行关键词解析
Iterator<String> itstrXmlFormatSql = strFormatSql.iterator();
//存储关键字的List集合
List<String> keyList=new ArrayList<>();
while(itstrXmlFormatSql.hasNext())
{
//取出格式化之后的待解析的sql语句
String sqlStr = itstrXmlFormatSql.next();
System.out.println(sqlStr);
System.out.println("**************************************");
Lexer lexer = new Lexer(sqlStr);
while(true) {
// 解析下一个token
lexer.nextToken();
// 获得解析完的token,Token是一个枚举
Token tok = lexer.token();
if(tok != Token.IDENTIFIER){
if(testAllUpperCase(lexer.stringVal()) && isEnglish(lexer.stringVal()))
keyList.add(lexer.stringVal());
}
if (tok == Token.EOF) {
break;
}
}
}
//输出所有的关键字
for (int i = 0; i < keyList.size(); i++) {
//删除关键字中的NULL
if(keyList.get(i).equals("NULL")){
keyList.remove(i);
}
System.out.println(keyList.get(i));
}
}
//判断字符串是否为大写字符
public static boolean testAllUpperCase(String str){
for(int i=0; i<str.length(); i++){
char c = str.charAt(i);
if(c >= 97 && c <= 122) {
return false;
}
}
return true;
}
//判断字符串是否为全英文
public static boolean isEnglish(String charaString) {
return charaString.matches("^[a-zA-Z]*");
}
}