Word embedding
Word embedding
什么是词嵌入?为什么我们需要使用词嵌入?再深入探讨这些例子前,让我们看一下一些例子。
- 有很多网站,例如:Amazon、IMDB,要求我们使用他们的产品时给予反馈。
- 我们会使用一些词到谷歌去搜索,并且返回与搜索词相关的内容。
- 有一些博客上,在某些位置贴了一些关于这个博客的标签。
这些技术是如何实现的?实际上再写是文本处理的应用。我们使用文本去做一些情感分析,相关词聚类,文本分类和添加标签。
当我们阅读新闻报纸时,我们能够说新闻是什么?但是计算机是如何做到这个的呢?计算机能够匹配一些字符串和告诉我们这些字符串是否相同。但是,当我们搜索"Messi(梅西)“时,我们如何使计算机告诉你有关足球和"Ronaldo”(罗纳尔多)的事情呢?
对于对象或语音识别之类的任务,我们知道成功执行任务所需的所有信息都编码在数据中(因为人类可以从原始数据执行这些任务)。然而,传统的自然语言处理把词看作离散的原子符号(discrete atomic symbol:指不可再分),所以"cat"能够用Id537和"dog"用Id143来表示。这些编码使任意的,并且没有提供任何符号之间的相关信息给系统。
接下来介绍词嵌入(“word embedding”)。word embedding 仅仅只是文本的数字表示。
Word embedding有很多种不同的类型。
- 基于频率的嵌入(Frequency based embedding)
- 基于预测的嵌入(Prediction based embedding)
Frequency based embedding:
(计数向量)Count vector
count vector模型从所有文本种学习词汇(Vocabulary,不同单词的集合),然后对每个文本种出现的每个单词进行计数。例如,假设我们有D个文本,并且T是词汇中不同单词的数量,所以count vector的大小就是 D ∗ T D*T D∗T。让我们看接下来的例子:
Document 1: The cat sat on the hat。
Document 2: The dog ate the cat and the hat。
在这两个文本中,我们的词汇是{the, cat, sat, on, hat, dog, ate, and}。所以,D=2,T=8。现在,我们计算在每个文本中计算每个单词出现的次数。在Document 1中,"the"出现了两次,*“cat”, “sat”, “on”, “hat”*都只出现了一次。所以,文本的特征向量是词汇表(Vocabulary),而count vector matrix就是;
| the | cat | sat | on | hat | dog | ate | and | |
|---|---|---|---|---|---|---|---|---|
| Document 1 | 2 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| Document 2 | 3 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
[ 2 1 1 1 1 0 0 0 3 1 0 0 1 1 1 1 ] \left[ \begin{matrix} 2 & 1 & 1 & 1 & 1 & 0 & 0 & 0 \\ 3 & 1 & 0 & 0 & 1 & 1 & 1 & 1 \end{matrix} \right] [2311101011010101]
现在在矩阵中,每一列就能够理解为一个词所对应的词向量。例如,*“cat”*在矩阵中对应的向量就是 [ 1 , 1 ] [1,1] [1,1]。行向量对应的是在语料库中的文本,列向量对应的是字典(dictionary,vocabulary)中的token(这里表示词)。
在大型的语料库中,矩阵的维度是一个问题。所以我们可以去除一些common word(类似于:a, an, this, that等)和设置一个词频,大于这个词频的单词才会被使用。
TF-IDF vectorization
在大型的语料库中,一些单词非常的常见(类似于:a, an, this, that等),但是它携带着有关这个文本相关的信息却很少。所以,如果我们将直接计数的数据直接提供给分类器,那么这些common word将会影响那些虽然数量少但意义重要的单词。
为了将重新加权的计数特征并称分类器容易使用的浮点值,最常使用的是tf-idf transform。这种方法不仅仅考虑了在单一文本中词的共现,而且还考虑了整个语料库。考虑一下商业文献,这种文献比起其它类型的文献中包含了更多商业的专业术语,类似于——*“Stock-market, Price, Shares"等等。但是,像"a, an, the”*在每个文献中都是很高频率的。所以这个方法将会惩罚(penalize)这种高频率的单词。
TF是指term-frequency,而tf-idf意思是term-frequency times(乘于) inverse document-frequency。
TF=(Number of times term t appears in a document)/(Number of terms in the document)[term t会出现在一个文本中的数量/在这个文本中term的个数]。
IDF=log(N/n),N is the total number of document and n is the number of document a term t has appeared in(N是文所有文本的数量,n是term t在文本中出现的数量)。
*TF-IDF(t,document) = TF(t,document)IDF(t)
Co-Occurrence Matrix with a fixed context window
Word co-occurrence matrix描绘了单词是如何出现在一起的,并且利用这个矩阵去捕捉词之间的关系。Word co-occurrence matrix 是很容易计算的——在给定的语料库里,计算2个或者多个单词是如何同时出现的。举个例子,考虑一个语料库包含以下的文本:
penny wise and pound foolish。a penny saved is a penny earned。
让 c o u n t ( w ( n e x t ) ∣ w ( c u r r e n t ) ) count(w(next)|w(current)) count(w(next)∣w(current))表示词 w ( n e x t ) w(next) w(next)在词 w ( c u r r e n t ) w(current) w(current)出现了多少次,我们尝试统计a和penny的共现为:
| a | and | earned | foolish | is | penny | pound | saved | wise | |
|---|---|---|---|---|---|---|---|---|---|
| a | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| penny | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
*“a” 词的下一个词为"a"的个数为0;下一个词为"and"的个数为0;…;下一个词为"penny"的个数为2(a penny saved is a a penny)。"penny"的统计类似。
上面的这个表被称为bigram frequency。它仅仅从当前的单词中观察(look into)下一个单词。考虑有N个单词的语料库,对于所有可能的单词组合,我们需要N x N的表格来表示bigram frequency。但是这样的表格是非常稀疏的(sparse),因为大多数的值都为0。所以在实践中,这个co-occurrence count 会转换为概率。这样做的结果将会是在这个co-occurrence matrix中,每一行的和为1。
这种co-occurrence matrix来表征词并不是平常使用的。我们需要使用类似于——PCA、SVD等方法,去压缩这个矩阵的因子(factor),并且结合这些特征来形成词的表征。
举个例子,对上述 N ∗ N N*N N∗N的矩阵使用PCA,便会获得V个主要成分(principal components)。选择前K个成分,那么新的矩阵就是会是 N ∗ K N*K N∗K。之后,一个单词就不需要N维来表征它,只需要K维就足够了。k通常是几百的数量级。
PCA只是将co-occurrence matrix分解为三个矩阵U,S, V。在这里,U和V是正交的。重要的是U和S的点积词的向量表征,V表示上下文。
Co-occurrence matrix 的优势
- 它提供了单词间的语义联系。例如:man和woman比起man和apple是更加接近的。
- 使用SVD,将会得到比起其它方法更加精确的词向量表征。
- 使用分解的方法将会更加好定义问题和有效地得到解决。
- 计算一次后,能够在任何时候使用这次的计算。在这种情况下,比起其它方法来说是更加快速的。
Co-occurrence matrix 的劣势
- 需要更大的内存去存储 Co-occurrence matrix
这个问题可以在系统外分解得到解决并存储,例如使用Hadoop集群。
Applications of frequency based methods:
这种基于频率的方法是很容易理解并且也有很多应用——文本分类,情感分析等等。因为这种方法能够从文本中提取positive和negative词,以至于我们能够使用机器学习的方法去容易的分类它们。
Prediction based method
Continuous Bag of Words(CBOW)
CBOW模型是通过语境(context,上下文)去学习从而预测单词。语境可能是一个单词,也可能是多个单词。
看一个例子:* The cat jumped over the puddle*。把 {“the”, “cat”, “over”,“the”,“puddle”}看作是一个语境,然后去预测或者生成中心词"jumped"。
**在讨论CBOW的细节之前,我们先来看看词的one-hot(独热编码)表征。**把单词用向量来表征的方法之一就是one-hot。One-hot向量是只有一个元素为1,其余元素为0。通过对每个维度设置1或者0来表示是哪个单词。
例如,我们需要用一组向量来表示*{NLP, python, word, ruby, one-hot}*。那么"python"在这组单词的位置为2,所以向量表示就为:[0,1,0,0,0]。
尽管one-hot表征是非常简单的,但也有很多缺点:(1)不可能使用算术运算去获得向量间有意义的结果。假设我们用一个内积来计算单词之间的相似度。在One-hot中,由于单词的位置不同,那么值为1的下表在向量中也不同。因为,尽管意义相同的的两个单词,通过one-hot的点积也会变成0。(2)one-hot向量会变得维度相当的高。因为一个维度就分配了一个单词,那么随着词汇(vocabulary)的增加,向量的维度就会变得很高。
接下来,我们分步探讨CBOW模型的工作方法:假设:
Wi:属于输入层和隐层(hidden layer)之间的权重矩阵(weight matrix)[V * N]。
Wj:属于输出层和隐层之间的权重矩阵[N * V]。

- 从给定大小的语境单词中生one-hot向量(x(c-m),...,x(c-1),xc+1,...,x(c+m))。这里x(c)是中心词或者想要去预测的目标词。我们有C=2m个[1*V]的one-hot向量。所以我们的输入层的大小为[C*V]。
- 然后,我们将[1*V]的向量去乘以Wi,得到嵌入词(wmbedded words),大小为[1*N](总共有2m个嵌入词)。
- 将2m个[1 * N]向量取平均值。
- 将矩阵Wj乘以输入隐层(嵌入词向量)来去计算输出隐层。现在我们得到大小为[1 * V]的打分矩阵。命名为z。
- 将这个分数转换为概率,使用 y' = softmax(z)。
- 我们希望用生成的概率y'去匹配真实的概率y(实际存在的one-hot)。
- 计算预测词和真实词之间的概率,然后然过来去调整参数(weight)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-igOrno4r-1582183767137)(D:\markdown\自然语言处理\斯坦福笔记\lecture1_picture\CBOW Architure.jpg)]
这里使用的损失函数是: H ( y ^ , y ) = − ∑ j = 1 ∣ V ∣ y i log ( y ^ i ) H(\hat{y},y)=-\sum_{j=1}^{|V|}y_i\log{(\hat{y}_i)} H(y^,y)=−∑j=1∣V∣yilog(y^i)。然后我们使用梯度下降或者其它好的优化器去训练这个网络。在训练之后,隐层和输出层之间的权重用词向量来表征。这里每一列表征一个词向量[1 * N]。
Skip-gram model
另外一种方法对于中心词"jumped",去预测或者产生邻近词(surrounding words){The, cat, over, the, puddle}。这里,我们也称"jumped"为语境。这个模型称为Skip-gram model。
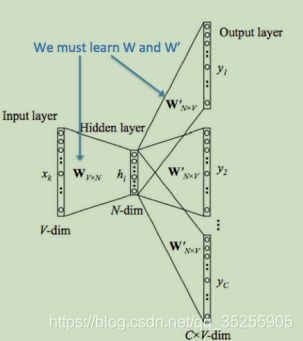
接下来我们分步探讨这个模型的工作方式。
同样的,我们假设:
Wi=输入层和隐层之间的权重矩阵,大小为(V * N)。
Wj=输出层和隐层之间的权重矩阵,大小为(N * V)
- 我们对输入的中心词x(c)去产生one-hot向量。这里(x(c-m),...,x(c-1),x(c+1),...,x(c+m))是需要预测的语境。所以我们的输入层的大小是[1 * V]。
- 现在,我们用输出层[1 * V]去乘以矩阵Wi[V * N]。得到嵌入词[1 * N]。
- 将输入隐层[1 * N]乘以矩阵[N * V]去计算输出隐层。我们会得到C(2m)个大小为[1 * V]的打分向量。命名为z(i)。
(注意,这里的2m个打分向量其实是相同的,但是他们的目标向量不同,所以之后求得的误差向量也会不同。)
- 使用y'(i) = softmax(z(i)),将打分向量变成频率。
- 将我们希望得到的概率y'(i)去匹配真实的概率y(i)(2m个打分向量对应的真实向量的概率不同)。
- 计算输y'(i)与y(i)之间的误差,然后重新调整Wi、Wj。
Advantages/Disadvantages of CBOW and Skip-gram:
- 由于这些计算的概率来自于自然语言,他们的性能应该是超过了确定性方法。
- 无需很大的内存,不需要巨大的RAM去存储像co-occurrence一样大的矩阵了。
- 尽管CBOW(从语境去预测中心词)和skip-gram(从中心词去预测语境)是相反的方法。但是他们有各自的优缺点。
对于CBOW来说
- 由于CBOW使用很多的语境词去预测一个单词,它可以使得分布平滑。这本质上类似于正则化,当我们的输入数据不是很大时,它提供了非常好的性能。
对于skip-gram
- skip-gram模型使更加细粒度的,以至于我们能够获取更多信息。
- 当拥有大的语料库时,能获得更加精确的嵌入词。
- skip-gram和negative-sampling结合的性能通常来说时超越其他方法的。
Application of word embedding(Word2Vec):
在深度学习中使用基于嵌入词方法的NLP任务已经超越了古老基于机器学习的方法了。例如:自动提取摘要(Automatic summarization),机器翻译(Machine translation),命名实体解析(Named entity resolution),情感分析(Sentiment analysis),聊天机器人(Chat-bot),信息提取(Information retrieval),语音识别(Speech recognition)和问答系统(Question answering)等。
[英文连接](https://medium.com/data-science-group-iitr/word-embedding-2d05d270b285)