c语言-基础知识点复习
对C语言做一个整理,最基本的就不说了,列一些容易忘记和搞错的知识点。
一、指针
1、指针的定义
int a = 100;
int b = 200;
int *p_a = &a; //定义指针变量时必须带*,注意取地址符号,指针p_a指向a
printf("%d\n", *p_a); //除了定义外,*p_a代表指针所指向的数据。
p_a = &b; //除了定义外,p_a代表指针地址。
printf("%d\n", *p_a);
定义指针变量时必须带*,给指针变量赋值时不能带*。
2、指针指向数组
例子1:
#include 例子2:
#include 指针指向二维数组的示例:
#include 指针p=a;此时p应该理解为第0行首位元素的地址的地址,于是p+1为第一行首位元素的地址的地址。*(p+1)表示第一行首位元素的地址,*(p+1)+1表示第一行第一列元素的地址,*(*(p+1)+1)就表示第一行第一列实际的值5。
3、数组字符串和常量字符串的区别
char str[] = "http://c.biancheng.net"; //数组字符串
char *str = "http://c.biancheng.net"; //常量字符串
最根本的区别是在内存中的存储区域不一样,字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串有读取和写入的权限,而常量区的字符串只有读取权限,没有写入权限,所以常量字符串只能在初始化时赋值,不允许修改。
4、指针变量做函数的参数
#include 5、数组做函数参数
示例:
#include 像 int、float、char 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行内存拷贝有可能是一个漫长的过程,会严重拖慢程序的效率,C语言没有从语法上支持数据集合的直接赋值,在底层都使用类似指针的方式来实现。
6、指针函数
指针函数指返回值为指针的函数。
示例:
#include 指针函数返回的指针尽量不要指向局部变量,函数运行结束后会销毁在它内部定义的所有局部数据,造成返回值无法保证其正确性,例如:
#include 7、二级指针
二级指针的定义:
#include 这样理解:p1表示a的地址,*p1表示a的值,&p1表示a的地址的地址。
p2表示一级指针p1的地址,也就是a的地址的地址;*p2表示a的地址;**p2表示a的值。
也就是说:
&p1=p2; //a的地址的地址
p1=*p2 //a的地址
*p1=**p2 //a的值
8、void指针
void 用在函数定义中表示函数没有返回值或者表示指针指向的数据的类型是未知的。C语言动态内存分配函数 malloc() 的返回值就是void *类型,在使用时要进行强制类型转换:
void* malloc(int size);
char *str = (char *)malloc(sizeof(char) * 30);
9、数组和指针的区别
数组和指针不等价的一个案例是求数组的长度,这个时候只能使用数组名,不能使用数组指针:
#include 结果:len_a = 6, len_p = 1
解释:数组是一系列数据的集合,p 仅仅是一个指向 int 类型的指针,对p使用 sizeof 求得的是指针变量本身的长度。
10、指针数组(数组每个元素都是指针)
定义方法:
#include 参照前面的二级指针,这样理解:
arr[0]表示a的地址,arr[1]表示b的地址;
*arr[0]表示变量a,*arr[1]表示变量b;
&arr[0]表示a的地址的地址,&arr[1]表示b的地址的地址;
arr表示指针数组的起始地址。即a的地址的地址,即为&arr[0];
parr表示指针数组的起始地址。即a的地址的地址,即为&arr[0];parr+1表示b的地址的地址,即为&arr[1];
*(parr+0)表示a的地址,*(parr+1)表示b的地址
**(parr+0)表示a的值,**(parr+1)表示b的值
11、指针数组和字符串数组
指针数组可以和字符串数组结合使用:
#include 分析一道示例:
#include 输出:
str1 = Programming
str2 = is
c1 = f
c2 = 2
c3 = E
解释:
1、 lines[1]表示第二个字符串的地址。打印str1得到第二个字符串
2、 lines表示第一个字符串的地址的地址,lines + 3表示第四个字符串的地址的地址,*(lines + 3) 表示第四个字符串的地址。打印str2得到第四个字符串
3、 lines + 4表示第五个字符串的地址的地址,*(lines + 4)+6表示第五个字符串的地址再加6,也就是字符“f”的地址,所以*(*(lines + 4) + 6)表示字符f。
4、 *lines表示第一个字符串的地址,*lines + 5表示字符串中第一个字符“2”的地址,把这个*lines + 5地址当做一个新数组的起始地址,(*lines + 5)[5]就表示字符串中第一个字符“2”的地址往右边第5个字符的地址,即为第二个“2”的地址。
5、 lines[0]表示第一个字符串的地址(起始地址),*lines[0]表示字符串的第一个字符“C”,*lines[0] + 2表示字符“C”做ASCII码计算。
12、函数指针和指针函数
函数指针:是指定义一个指针,指向函数代码的首地址,可以通过函数指针对函数进行调用。
函数指针的定义:
#include 函数指针的作用及使用场景:
比如在嵌入式中,微控制器的一些功能函数(系统函数)是固化在rom中的(类似于PC机中的BIOS)。用户代码是不认识这些函数的,不能直接使用函数名调用。所以,当我们想在用户程序中调用这些系统函数时,就可以将系统函数的入口地址传给函数指针,来达到调用rom中程序的目的。
指针函数:是指定义一个函数,其返回值类型为指针,注意区别,前面有讲。
二、结构体
1、结构体和结构体数组的定义
//创建一个stu结构体模板
struct stu{
char *name;
int num;
int age;
char group;
float score;
};
//定义结构体stu1并初始化,也可以不初始化。
struct stu stu1 = { "Tom", 12, 18, 'A', 136.5 };
printf(“name is %s,num is %d …”, stu1.name,stu1.num);
//定义结构体数组class,数组的每一个元素都是stu结构体,可以不初始化。
struct stu class[] = {
{ "Li ping", 5, 18, 'C', 145.0 },
{ "Zhang ping", 4, 19, 'A', 130.5 },
{ "He fang", 1, 18, 'A', 148.5 },
{ "Cheng ling", 2, 17, 'F', 139.0 },
{ "Wang ming", 3, 17, 'B', 144.5 }
};
printf("first student name is %s, num is %d...", class[0].name, class[0].num);
2、结构体指针以及结构体数组指针
结构体指针:
struct stu{
char *name;
int num;
int age;
char group;
float score;
}stu1 = { "Tom", 12, 18, 'A', 136.5 }; //定义结构体stu1的另一种写法
struct stu *p = &stu1; //定义一个结构体指针p指向stu1结构体,注意取址符
printf("stu name is %s", p->name); //打印结构体的name变量
结构体数组指针:
struct stu{
……
} class[] = {
{ "Li ping", 5, 18, 'C', 145.0 },
{ "Zhang ping", 4, 19, 'A', 130.5 },
{ "He fang", 1, 18, 'A', 148.5 },
{ "Cheng ling", 2, 17, 'F', 139.0 },
{ "Wang ming", 3, 17, 'B', 144.5 }
};
struct stu *p = class; //定义一个结构体指针指向结构体数组,注意没有取地址符
printf("first stu name is %s", p->name); //打印第一个学生名
p++; //p表示第一个结构体地址,p++表示数组的第二个结构体地址
printf("second stu name is %s", p->name);
3、结构体以及结构体数组做函数参数
#include4、enum关键字,枚举类型
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };
enum week day = Mon; //day=0
将enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun }理解为宏定义:
#define Mon 0;
#define Tues 1;
…
就可以。
5、union关键字,联合体
union data{
int n;
char ch;
short m;
};
union data a;
a.n = 0x40;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。例如上面的data联合体占用字节数取决于int,为4个字节。
6、大小端及判别方法
大端模式:指将数据的低位(比如 1234 中的 34 就是低位)放在内存的高地址上,而数据的高位(比如 1234 中的 12 就是高位)放在内存的低地址上。
小端模式:指将数据的低位放在内存的低地址上,而数据的高位放在内存的高地址上。
例如32位系统中一个int数据0x12345678,小端模式:
内存地址 :0x4000 0x4001 0x4002 0x4003
存放内容 :0x78 0x56 0x34 0x12
大端模式:
内存地址 :0x4000 0x4001 0x4002 0x4003
存放内容 :0x12 0x34 0x56 0x78
如何判别cpu采用的大端还是小端模式?
可以利用联合体的概念:
#include 1为数据低位,如果data.ch==1表示数据低位在地址低位,为小端模式,否则为大端模式。
7、bs位域
它的成员用来存储一个或几个数据位。感觉这个不太常用,知道有这么个东西就行。
三、输入输出函数及缓冲区
1、输出函数:printf
a、位宽及对齐方式
#include -9d的意思:9表示占9个字符的宽度,-表示左对齐,不加-号默认右对齐。
b、输出精度
#include 输出:
f: 882.92 882.9237 882.9236720000
str: abcde abcdefghi
对于小数,%.2 %.4等表示精确到小数点后几位。
对于字符串,%.5 %.15等表示截取字符串的长度。
可以与前面的字符宽度和对齐方式连用,如:
printf("f: %-10.2lf\n",f);
表示左对齐,占10个字符宽度,精确到小数点后两位。
c、其余标志符(*)
前面对齐方式中的 “–” 称为标志符,标志符还可以是如下形式:
–: 表示左对齐。如果没有,就按照默认的对齐方式,默认一般为右对齐。
+: 用于整数或者小数,表示输出符号(正负号)。
空格: 用于整数或者小数,输出值为正时冠以空格,为负时冠以负号。
#: 对于八进制(%o)和十六进制(%x / %X)整数,# 表示在输出时添加前缀;对于小数(%f / %e / %g),# 表示强迫输出小数点。
示例:
#include 输出:
m= 192, m=192
m=+192, n=-943
m= 192, n=-943
f=84, f=84.
d、输出地址
%p用于打印表示以十六进制的形式(带小写的前缀)输出数据的地址,或%P大写形式:
#include 2、输入函数scanf
a、scanf指定读取的长度
#include b、匹配特定的字符
#include scanf从头开始检查缓冲区用户输入字符串的每一个字符,符合%[a-zA-Z]规则的,就存入str,一旦检测到字符不符合规则或遇到空格,就停止扫描。
或者%[0-9]只匹配数字,%[a-z-A-Z0-9]读取所有的英文字母和十进制数字等。
c、不匹配某些字符
在不匹配的字符前面加上^,例如%[^0-9]表示匹配除十进制数字以外的所有字符,%[^\n]表示匹配除换行符以外的所有字符:
#include scanf依然从头开始检查用户输入字符串的每一个字符,%[^0-9]只有遇到十进制数字,才停止匹配,遇到空格也不会停止。
%[^\n]只有遇到换行符才停止匹配,遇到空格也不会停止,所以scanf("%[^\n]", str2)相当于gets(str2)。
d、丢弃读取到的字符
把读取到的数据直接丢弃,不往变量中存放,具体方法就是在 % 后面加一个*:
#include scanf依然从头开始检查用户输入字符串的每一个字符,scanf("%*[a-z]")表示匹配到小写字母就丢弃掉(不停止),停止的条件是匹配到非小写字母的字符(包括空格)。
例如输入:abcd1234
程序输出:1234
3、输入输出缓冲
无论是用户输入的数据,还是printf想要输出的数据,数据都是暂时存放在缓冲区中的,缓冲区知识点可以参照linux系统编程-IO缓冲里面的原理图:
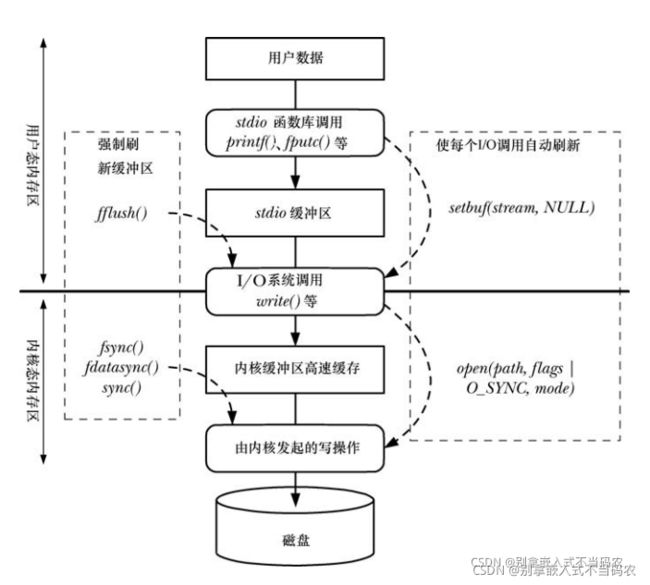
输入输出缓冲区采用的是行缓冲,也就是说遇到换行符,就会与内核缓冲区交换数据,看这样一个例子:
#include "mytest:"不会马上输出,而是睡眠3秒后和print right now一起输出。原因是printf(“mytest:”)这一句只是将"mytest:"放进了缓冲区,没有和内核缓冲区数据交换,printf(“print right now\n”)这一句键入了一个换行符,用户缓冲区与内核缓冲区交换数据,内核才发起write系统调用将内容写到STDOUT_FILENO流文件中,这个时候才真正的输出到屏幕上。
如果使用fflush清空缓冲区,就可以让“mytest:”一开始就输出:
#include 执行程序,"mytest:"会马上输出,3秒睡眠后输出“print right now”。
在printf和scanf之间,会发生一次隐式的fflush调用:
#include abcdef为键盘输入,输出为:
mytest:abcdef
print right now
(null)
解释:在printf(“mytest:”)和scanf(“input:%s”,str)发生了一次隐式调用fflush(stdout),所以"mytest:“会马上输出到屏幕上。
scanf(“input:%s”,str)和printf(“print right now\n”)发生了一次隐式调用fflush(stdin),也就是说放弃了缓冲区str的数据,所以最后printf(”%s",str)打印出来是空指针。
清空缓冲区的方法:
清空输出缓冲区:fflush(stdout)
清空输入缓冲区:fflush(stdin)貌似不是在所有环境都有效的,更可靠的方法有下面两种:
a、getchar() 是带有缓冲区的,只要我们让 getchar() 不停地读取,直到读完缓冲区中的所有字符,就能达到清空缓冲区的效果:
char c;
while((c = getchar()) != '\n' && c != EOF);
该代码不停地使用 getchar() 获取缓冲区中的字符,直到遇见换行符\n或者到达文件结尾才停止。
b、第二种方法,利用scanf:
scanf("%*[^\n]"); scanf("%*c");
scanf("%*[^\n]")表示匹配缓冲区中除了换行符所有的字符,并把匹配到的这些字符丢弃;scanf("%*c")表示丢弃掉最后一个回车符。
四、其他
1、typedef关键字
typedef用于给数据类型定义别名:
//给int类型定义别名
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;
//给数组定义别名
typedef char ARRAY[20];
ARRAY a,b,c; // 相当于char a[20], b[20],c[20]
//结构体定义别名
typedef struct stu{
char name[20];
int age;
char sex;
} STU;
STU stu1,stu2;
//二维数组指针定义别名
typedef int (*PTR_TO_ARR)[4];
PTR_TO_ARR p1;
//函数指针定义别名
typedef int (*PTR_TO_FUNC)(int, int);
PTR_TO_FUNC pfunc;
二维数组指针定义别名的一个例子:
#include 函数指针定义别名的一个例子:
#include typedef 和 #define 的区别
1、#define可以类型名进行扩展,但对 typedef 所定义的类型名却不能。
#define INTERGE int
unsigned INTERGE n; //没问题
typedef int INTERGE;
unsigned INTERGE n; //错误,不能在 INTERGE 前面添加 unsigned
2、连续定义几个变量的时候,typedef 能够保证定义的所有变量均为同一类型,而 #define 则无法保证。
#define PTR_INT int *
PTR_INT p1, p2; //实际上等于:int *p1,p2,本来是想定义两个int指针,然而p2是int
typedef int * PTR_INT
PTR_INT p1, p2; //p1,p2两个都是int型指针
2、const关键字
const定义的变量的值不能被改变,在整个作用域中都保持固定:
const int a=100;
a=50; //错误,const定义过后的变量不能再修改
和指针一起使用时,可以让指针指向的数据不能被改变,也可以让指针的地址不能被改变,还可以两者兼而有之:
const int *p1; //指向的数据不能被修改
int const *p2; //指向的数据不能被修改
int * const p3; //p3地址不能被修改
const int * const p4; //地址和指向数据均不能修改
int const * const p5; //地址和指向数据均不能修改
const 用做函数形参修饰
const 通常用在函数形参中,如果形参是一个指针,可以防止在函数内部修改指针指向的数据:
例子:
#include 3、static和extern关键字
extern关键字
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。例如:
main.c中:
extern void func(); //函数和全局变量在其他文件中定义,提示在其他文件中寻找
extern int m;
注:exterb仅用于声明,所以不推荐这种写法:
extern datatype name = value; //相当于datatype name = value,extern没起作用
static关键字
static修饰全局变量或函数时,会修改其作用域,static修饰的全局变量或函数仅对本文件有效。
static修饰局部变量,会改变变量的存储区域,被 static 修饰的局部变量会存储在全局数据区(与全局变量存储的区域一样),而未被static修饰的局部变量应该是在栈空间里的。所以不会因为函数调用结束而销毁,同时注意全局数据区的变量只能被初始化(定义)一次。
下面这个例子:
#include 运行结果:
Function is called 1 times.
Function is called 2 times.
Function is called 3 times.
Function is called 4 times.
Function is called 5 times.
n = 0
注意static int n 只初始化一次,且static int n 和main里的n互不影响(main的n在栈空间里)
4、volatile关键字
由于访问寄存器要比访问内存单元快的多,编译器在存取变量时,为提高存取速度,编译器优化有时会先把变量读取到一个寄存器中;以后再取变量值时就直接从寄存器中取值。但在很多情况下会读取到脏数据,严重影响程序的运行效果。
volatile就是告诉编译器对该变量不做优化,每次都会直接从变量内存地址中存储或读取数据。
使用场景:
例如当变量在触发某中断程序中修改,而编译器判断主函数里面没有修改该变量,因此可能只执行一次从内存到某寄存器的读操作,而后每次只会从该寄存器中读取变量副本,使得中断程序对变量的修改在读取的值看来没有起到作用。
五、虚拟地址和内存相关
1、虚拟地址:
程序员在设计程序时,关心和使用的是虚拟地址。虚拟地址大小由cpu的地址总线长度和外置内存大小决定,例如在一个32位的系统中,理论虚拟地址空间为4GB。但程序实际运行是需要加载到物理内存中去的,一个固定的虚拟地址映射到物理地址,物理地址可能是不固定的,但程序员不需要关心这些,哪些部分需要在哪个时刻被加载进物理内存,加载到哪个位置,交给内存管理系统就好了。
为什么要使用虚拟地址?面试可能会问
直接使用物理地址存在的问题:
(1)安全风险:
有些物理地址的内容不允许修改,如果直接操作物理地址,可能导致设备变砖。
进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。
(2)地址不确定:
众所周知,编译完成后的程序是存放在硬盘上的,当运行的时候,需要将程序搬到内存当中去运行,如果直接使用物理地址的话,我们无法确定内存现在使用到哪里了,也就是说拷贝的实际内存地址每一次运行都是不确定的。但是使用物理地址的话就需要程序员自己去确定现在物理内存中哪一块是空闲的,可以用来运行程序。
(3)效率低下
使用虚拟空间的办法是将不常用的进程拷贝到磁盘的交换分区中,好腾出内存,但是如果是物理地址的话,就需要将整个进程一起拷走,这样,在内存和磁盘之间拷贝时间太长,效率较低。
虚拟地址如何转换为物理地址:使用多级页表将虚拟地址转换为物理地址,通过页表完成虚拟地址和物理地址的映射时,要经过多次转换,还要进行计算,如果由操作系统来完成这项工作,那将会成倍降低程序的性能,所以使用MMU来负责将虚拟地址映射为物理地址:

CPU 发出的是虚拟地址,这个地址会先交给 MMU,经过 MMU 转换以后才能变成了物理地址。即便是这样,MMU也要访问好几次内存,性能依然堪忧,所以在MMU内部又增加了一个缓存,专门用来存储页目录和页表。
2、内存对齐
内存对齐:CPU 通过地址总线来访问内存,例如32 位的 CPU 一次可以处理4个字节的数据,那么每次就从内存读取4个字节的数据,4字节便称为读取的步长,将一个数据尽量放在一个步长之内,避免跨步长存储,这称为内存对齐。
例如在这样的一个结构体:
struct{
int a;
char b;
int c;
}t={ 10, 'C', 20 };
sizeof求它占用的字节数为12,而不是9。
3、栈帧
栈帧:当发生函数调用时,会将函数运行需要的信息全部压入栈中,这常常被称为栈帧或活动记录。活动记录的内容包括:
1、 函数的返回地址。
2、 参数和局部变量。
3、 返回值,当函数返回值的长度较大时,会先将返回值压入栈中,然后再交给函数调用者。
4、 一些需要保存的寄存器,例如 ebp、ebx、esi、edi 等。之所以要保存寄存器的值,是为了在函数退出时能够恢复到函数调用之前的场景,继续执行上层函数。
4、malloc和free的原理
malloc原理:malloc首先通过系统调用申请一块较大的内存,然后由 malloc() 自己管理这块空间(因为系统调用的开销比较大,所以采用这种方式),这块空间称为空闲列表。malloc时会扫描空闲内存块列表,如果有一内存块的尺寸正好与要求相当,就把它直接返回给调用者;如果是一块较大的内存,那么将对其进行分割,在将一块大小相当的内存返回给调用者的同时,把较小的那块空闲内存块保留在空闲列表中;如果在空闲列表中根本找不到足够大的空闲内存块,那么 malloc()会调用 sbrk()以分配更多的内存。
free原理:free的作用就是把malloc分配的内存块归还给空闲列表。实际上malloc的时候,会额外分配几个字节来存放记录这块内存大小的整数值。实际返回给调用者的内存地址位于这一长度记录字节之后。

free()归还内存块时,会使用内存块本身的空间来存放链表指针,将自身添加到列表中,以为知道内存块的长度了,那么指向前一空闲内存块和后一空闲内存块的指针地址也就知道了。

5、野指针与内存泄漏
野指针:如果一个指针指向的内存没有访问权限,或者指向一块已经释放掉的内存,那么就无法对该指针进行操作,这样的指针称为野指针。如何规避野指针?1) 指针变量如果暂时不需要赋值,一定要初始化为NULL,因为任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的。2) 当指针指向的内存被释放掉时,要将指针的值设置为 NULL,因为 free() 只是释放掉了内存,并为改变指针的值。
内存泄露:使用 malloc()、calloc()、realloc() 动态分配的内存,如果没有指针指向它,就无法进行任何操作,也无法被释放,只有等到程序运行结束由操作系统回收,可理解为程序和内存失去了联系。例如下面一段程序:
int *pOld = (int*) malloc( sizeof(int) );
int *pNew = (int*) malloc( sizeof(int) );
pOld=pNew;
free(pOld);
pOld改变了指向的地址,变成和pNew指向同一个地址,那么free(pOld)释放掉的就是后面申请的那块内存,前面申请的内存没有指针指向他,所以再也没办法释放掉了,就造成了内存泄露。
六、字符串处理函数
1、 strcpy字符串拷贝
原型:strcpy(str1,str2);
功能:将字符串str2复制到字符串str1中,并覆盖str1原始字符串。
返回:str1
int main(int argc, char const *argv[])
{
char *str1 = "hello world";
char *str2;
// 功能:把str1的内容拷贝到str2,参数为字符数组指针
strcpy(str2, str1);
printf("str2 = %s\n", str2);
return 0;
}
2、strncpy函数
原型:strncpy(str1,str2,n);
功能:将字符串str2中的前n个字符复制到字符串str1的前n个字符中
返回:str1
int main(int argc, char const *argv[])
{
char str1[] = "day day up";
char str2[] = "you are";
strncpy(str1, str2, strlen(str2));
printf("%s\n", str1); // you are up
return 0;
}
3、strcat函数
原型:strcat(str1,str2);
功能:将字符串str2添加到字符串str1的尾部,也就是拼接两个字符串
返回:str1
int main(int argc, char const *argv[])
{
char str1[] = "hello ";
char str2[] = "world";
strcat(str1, str2); // hello world
printf("%s\n", str1);
return 0;
}
4、strncat函数
原型:strncat(str1,str2,n);
功能:将字符串str2的前n个字符添加到字符串str1的尾部
返回:str1
int main(int argc, char const *argv[])
{
char str1[] = "hello ";
char str2[] = "world";
strncat(str1, str2, 2); // hello wo
printf("%s\n", str1);
return 0;
}
5、 strlen函数与sizeof函数
重要知识点:strlen与sizeof的区别?
a、 sizeof是运算符,在编译时计算,而strlen是函数,在运行时计算。
b、 sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以’’\0’'结尾的。
例如:
sizeof(int); //正确
strlen(int); //错误
c、先看几段代码:
# include 由上可以总结C:1、对于数组str[20]和str[]而言,sizeof求得的是实际编译器为其分配的数组空间大小,不关心里面存了多少数据;strlen只关心存储的数据内容,不关心空间的大小和类型。2、当定义一个指针指向字符串数组,sizeof求得的是指针本身类型所占的内存字节数,而strlen不改变原意,还是表示实际字符串长度。
6、 strchr、strrchr、strstr,查找字符或字符串的位置
strchr(str,c);
功能:在str字符串中查找首次出现字符c的位置(从字符串的首地址开始查找)
例子:
# include strrchr(str,c);
在字符串str中从后向前开始查找字符c首次出现的位置
strstr(str1,str2);
在字符串str1中查找字符串str2的位置,若找到,则返回str2第一个字符在str1中的位置的指针,若没找到,返回NULL。
例子:
# include 7、 strtok分割字符串
该函数返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针
例子:
#include 8、sscanf字符串提取特定的数据
sscanf用于从指定字符串中提取特定的数据。该函数返回成功匹配和赋值的个数
如下为提取字符串dtm的指定类型数据:
#include 9、sprintf和snprintf函数
sprintf与printf一样,只不过printf是输出内容到终端进行显示,sprintf是将内容输出到字符串str中,如果成功,则返回写入的字符总数,不包括字符串追加在字符串末尾的空字符。如果失败,则返回一个负数。代码如下:
#include snprintf用于将字符串格式化后,截取字符串的前n个字符。
例如:
#include