多选项问题候选评估
一些研究维度
1 为问题生成具有干扰项的答案,作为多项选择题候选答案,生成问题
2 评估干扰项的好坏,评估问题
3 从多个选项答案中选出正确的答案。复杂结构的语义理解问题
一些数据集
1 RACE数据集
收集中学生英语考试题目。覆盖了各种学科和领域
2 sciq数据集
一些论文阅读
1 Distractor Generation for Chinese Fill-in-the-blank Items 2017
Proceedings of the 12th Workshop on Innovative Use of NLP
- 数据集构成:
教科书语料库:从三本汉语教材(刘,2004,2010;王,2007)中收集了299个填空项目,每个项目都有一个目标词和两到三个干扰词。对该语料库的分析证实了文献中提出的许多标准:在63%的条目中,所有干扰词都与目标词具有相同的词性;在45%的条目中,至少有一个干扰词与目标词具有相同的特征。
维基语料库: 我们从中文维基百科中提取了1400万个句子,用于计算候选生成步骤中的词频、相似度和共现统计。然后,我们使用斯坦福中文解析器(Levy and Manning,2003)对550万个句子的子集进行分词、词性标注和相关性分析,以用于候选筛选步骤。
- 生成方法:
第一步,候选生成,优化干扰源的合理性;
相似词性和难易度:提取维基语料库中所有词性相同的词,然后根据它们的词频和目标词的词频的接近程度对它们进行排序。
拼写相似性:候选词至少与目标词共享一个公共字符。
共同出现的单词:根据Wiki语料库上估计的目标词的点互信息(PMI)得分对候选分心词进行排序。
词语相似度:语义上接近目标词的词往往是似是而非的候选者。我们根据候选分心词与目标词的相似度对其进行排序。我们通过在Wiki语料库上训练word2vec模型获得了这些分数。
第二步,候选筛选,筛除可以接受的答案。
Trigarm :前一个单词和后一个单词在句子中不能出现在wiki语料库
依赖关系:提取出所有以候选词为head活着child的关系,并要求这些关系不能出现在wiki语料库
- 评估方法:
人工评估
对于项目中的每一个选择,评委决定其是否正确;他们可以确定零个、一个或多个正确答案。对于一个不正确的答案,他们进一步评估它的合理性,将其作为三点量表上的干扰因素:“合理”、“有点合理”或“明显错误”。
人类注释的kappa为0.529,被认为是“中等”水平的一致性(Landis和Koch,1977)。作为一种注释质量检查,我们发现,总的来说,在6.8%的情况下,法官会将目标词标记为干扰词。
2 Crowdsourcing Multiple Choice Science Questions
ACL
- 数据集构成方法:
1.选择该领域的教材作为原始资源
2.使用基于规则的方法,从教材中选择适合生成合理问题的片段
3.提供3个过滤出的片段供每个参与者选择/全不选择
4.定义期望的和不期望的问题示例供参考
5.一个参与者根据提供的片段问问题,并提供正确答案
6.训练模型从一个大集合中预测出的6个干扰选项
7.另一个参与者从6个干扰选项中最多选择2个使用
8.自己再想一个构成最终的3个干扰选项
3 Race:Large-scale reading comprehension dataset from examinations
EMNLP
- 数据集构成方法:
从中国中学生阅读理解中得到
- 问题的推理五个难度
单词匹配:问题与文章中的跨度完全匹配。答案不言而喻。
释义:问题是由文章中的一个句子引起或释义的。答案可以在句子中提取出来。
单句推理:通过识别不完整信息或概念重叠,可以从文章的单句中推断出答案。
多句子推理:答案必须通过综合分布在多个句子中的信息来推断。
不充分/模棱两可:问题没有答案,或者根据给定的段落,答案不是唯一的。
- 问题的推理类型
细节推理:要回答这个问题,应该清楚文章的细节。答案出现在文章中,但仅仅通过将问题与文章相匹配是找不到答案的。
全貌推理:需要理解故事的全貌才能得到正确的答案。
文章摘要:问题要求在四个候选摘要中选择文章的最佳摘要。这种类型的典型问题是“这篇文章的主要思想是”。
态度分析:这个问题询问作者或故事中的人物对某人或某事的看法/态度
世界知识:需要一定的外部知识。这类问题中最常见的是简单的算术题。
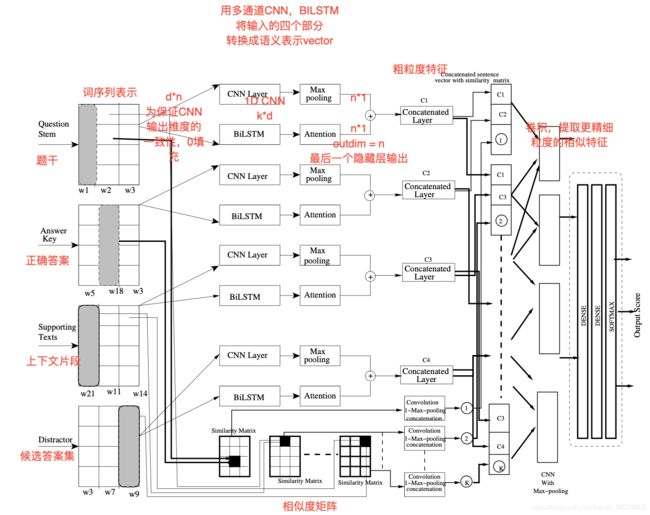
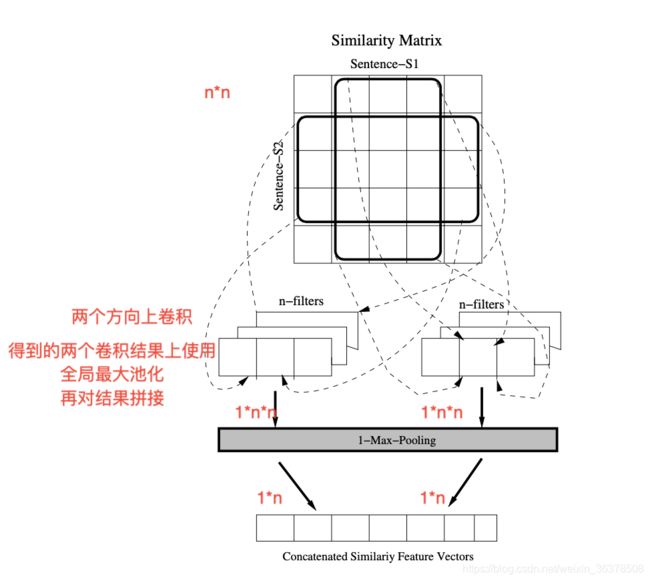
4 Ranking Distractors for Multiple Choice Questions Using Multichannel Semantically Informed CNN-LSTM Networks
AAAI
- 评估候选集的方法
提出了一种新的模型
数据集:SciQ,RACE
模型输入:题干,正确答案,上下文片段,候选答案i
模型输出:分数
模型使用:根据分数排序,正确答案和候选答案应该分数大于其他。
评估方法:准确率,平均准确率,NDCG,MRR
5 Automatic Generation Technology of Chinese Multiple-choice Items based on Ontology [in Chinese]基于本体的中文多项选择题自动生成技术
《Computer Engineering and Design》
- 提出了干扰度的概念
干扰度是通过模仿人类家族的血缘关系来表示。干扰项对正确选项的干扰程度,可表示为一个二元函数DL = f(D,C)式中:D——干扰项,C——正确答案,DL∈Z+。
干扰度用正整数表示。它的值越小,表示正确选项和干扰项的关系越亲,即干扰项对正确选项所产生的干扰越大。它的值越大,表示正确选项和干扰项的关系越疏远,即干扰项对正确选项所产生的干扰越小。
一个概念的父类和子类对这个概念的干扰度为 1,其兄弟概念对其干扰度为 2,一个和其没有任何关系的概念对其干扰度设置为最大值。
6 Discriminative Approach to Fill-in- the-Blank Quiz Generation for Language Learners. 语言学习者填空题的判别生成法
Meeting of the Association for Computational Linguistics会议
- 干扰项原则
首先,干扰项应该是可靠的;他们对答案是排他性的;
第二,应该是有效的;它们能充分区分学习者的熟练程度
- 数据集
英语的Lang-8语料库[1]作为一个大规模的ESL语料库,由1.2M个句子修正对组成
- 生成方法
从ESL语料库中提取目标词的方法,并通过一个考虑到特定句子的长距离上下文的判别模型来选择干扰词
把纠正作为目标,把误用词作为干扰候选词之一。
- 评估方法
人工评估
用此的方法(DiscSimESL)产生的干扰源有98.3%是可靠的。
研究结果还显示,被试的托业成绩与分心因子的相关系数为0.76,说明干扰项的有效性优于以往的方法
7 Distractor generation with generative adversarial nets for automatically creating fill-in-the-blank questions利用生成性对抗网自动生成填空题的干扰源
the Knowledge Capture Conference会议
- 数据集
Sciq
MSQL(自己制作的)
- 生成方法
对抗生成网络
G,输入q,a输出d
D, 输入q,a,d 判断d是来自于训练数据还是G产生的数据
- 评估方法
-------- 基于特征的模型--------------:
(i) Logistic Regression 逻辑回归
(ii) Random Forest 随机森林
(iii) LambdaMART:排序模型
参数输入
对每一组(q,a,d),输入为一个26维的一个vector ,输出,如果d是正确答案或者干扰项,输出在【0,1】之间的数值要尽量接近1,否则尽量接近0
这26维的vector为根据q,a,d提取的特征
2 基于NN的模型
打分函数f(theta)=(d, q, a), theta为打分函数所要拟合的参数
级联方法:
第一级:通过基于特征的模型,粗筛
将所有问题的候选项作为候选项集合。对每一个问题和答案,如果是属于qa的候选项,label为1,不是则为0
训练得到模型,当候选项排序都在前K时,计算recall@K
选择合适的K,作为第一级
第二级:基于特征的或者基于NN的
8 Automatic Generation of Challenging Distractors Using Context-Sensitive Inference Rules利用上下文相关推理规则自动生成具有挑战性的干扰源
Proceedings of the Ninth Workshop on Innovative Use of NLP
- 生成方法
使用Melamud等人提供的资源。(2013),其中包括2000多个频繁动词的上下文敏感和上下文不敏感规则。[2]我们使用这些规则生成具有挑战性的干扰
- 评估方法
人工评估
9 NewsQA: A Machine Comprehension Dataset
Proceedings of the 2nd Workshop on Representation Learning for NLP
https://github.com/Maluuba/newsqa/tree/master/maluuba/newsqa
阅读理解题,only have答案,无多选项
数据集构成方法:
1.12744个CNN 新闻文章
2.发问者只看到新闻文章的标题和摘要;
他们看不到完整的文章本身;
他们被要求从这个不完整的信息中提出一个问题;
每个文章最多提出三个问题
3.他们看到新闻文章的内容以及提出的问题来回答问题
每一个问题,他们都在文章点击选择对应的答案
每个问题,都会问多个人回答,至少在两个人身上答案需保持一致
4.第三组人看到了完整的文章、一个问题以及该问题的一组唯一答案。
我们要求这些员工从候选集中选择最佳答案或拒绝所有答案。
每一个文章问题对平均由2.48个人选择 。
10 Semantic similarity of distractors in multiple-choice tests: extrinsic evaluation
- 数据集
(自己制作的)20个问题
- 生成方法
i)搭配模式;
优先考虑出现在源文本中的干扰。如果没有足够的干扰源,则从列表中随机选择干扰源。根据每个干扰项与
正确答案之间的相似性得分对列表中的干扰项进行排序,并选择前4个
(ii)四种不同的基于WordNet的语义相似度方法
(扩展的gloss重叠度量、Leacock和Chodorow度量、Jiang和Conrath度量和Lin度量);
(iii)分布相似度相似性,
(iv)语音相似性。
(v)语音相似性。
(vi)混合模式。
- 评估方法
243个大学学生对产生的这些多选项问题做题
根据难度,辨别了,有效性三个方面评估生成的选项
结果,混合模式最好
11 Difficulty-aware Distractor Generation for Gap-Fill Items
Proceedings of the The 17th Annual Workshop of the Australasian Language Technology Association
- 研究内容
研究干扰项的的估计排名与人类对似然性的判断之间的相关性
- 数据集
1 Distractor Generation for Chinese Fill-in-the-blank Items 2017中提到的数据集中的37个句子。其中包含37个目标词,不同的名词或者动词
- 生成方法
语义相似度. 得到分数最高的集合
bert对这些集合进行一个排序。作为候选排序
- 评估方法
每一个问题取出直接根据语义相似度得到的前20,以及bert重新排序后得到的前50。
总的里面随机选择172个单词进行人为打分。计算人的打分高低与程序预测给出的相关性
结果,bert排序后与人的打分相关性更高
12 A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
ACL
- 数据集
CNN
Daily Mail
将文章和摘要配对。并抠出一个实体,回答这个实体是什么
- 阅读理解方法
将文章中的所有实体都用一个mark代替。看question中缺少的实体是文章中的哪一个
bilstm做embedding以及句子的表示。
attentionQ与文章,最后得到answer
- 评估方法
对预测出的答案entity, 得到一些feature。输入到LambdaMART,label为0或者1.最终查看这些feature对于结果的影响:frequency of e和ngram影响最大
预测模型与其他模型对比。结果最好,72.4%
分析预测错的的问题模糊不清或者没有答案的占到了20%左右。
说明CNN&& Daily mail问题产生数据的方式和共指错误,达到了性能上线
13 Co-Attention Hierarchical Network:
Generating Coherent Long Distractors for Reading Comprehension
AAAI
- 数据集
RACE
- 生成方法
生成更长的句子级别,而不是单词级别或者词组级别的干扰项
ENCODER-DECODER结构
ARTICLE层级的信息提取。再与Q做attention;再通过一个门,最终得出当前问题与文章的一个相关表示
根据encoder输出以及question输入,attention
之后得到一个content表示,最终输出
干扰项与文章之间的余弦相似性作为loss度量,最大化这个loss,使生成的干扰项更接近文章内容
- 评估方法
前一/二/三个生成的干扰项与提供的干扰项之间的BLEU ROUGE,本文提出的模型总体上笔其他模型都表现更好
笑容实验发现本文提出的loss 以及co-attention模型都对基线模型得到了大幅提升
人类评估流利度,连贯性,干扰性。我们的模型在流利度,干扰性方面都好于基线模型
其他研究结果
1 Three Options Are Optimal for Multiple‐Choice Items: A Meta‐Analysis of 80 Years of Research
三种选择是多项选择项目的最佳选择:对80年研究的荟萃分析
2 词汇评价问题生成
Automatic Question Generation for Vocabulary Assessment.
Automatic Generation of English Vocabulary Tests
3 不同领域内自动问题生成
A Preliminary Inquiry into Using Corpus Word Frequency Data in the Automatic Generation of English Language Cloze Tests在英语语言自动生成问题中使用预料词频
Generating Multiple-Choice Test Items from Medical Text在医学测试中生成多选项问题
WordGap: Automatic Generation of Gap-Filling Vocabulary Exercises for Mobile Learning.移动学习中填空词汇练习的自动生成
An Automatic MultipleChoice Question Generation Scheme for English Adjective Understanding英语形容词理解的自动多选项问题生成方案
Automatic gap-fill question generation from text books从教科书自动生成填空题
Automatic gap-fill question generation from educational texts
Generating questions and multiple-choice answers using semantic analysis of texts基于文本语义分析的多选项问答生成
Automatic generation of context-based fill-in-the-blank exercises using co-occurrence likelihoods and google n-grams. 使用共现可能性和谷歌n-grams自动生成基于上下文的填空练习。
5 Distractor Efficiency in Foreign Language Testing.
哪一类干扰因素最有可能吸引学生偏离正确答案?2-哪一类干扰因素最容易区分或区分学生的熟练程度
6 Relationship between Types of Distractor and Difficulty of Multiple-Choice Vocabulary Tests in Sentential Context句子语境中干扰项类型与多选词汇测试难度的关系
7 Multiple Choice Question Corpus Analysis for Distractor Characterization. 干扰表征的多选题语料库分析
8 Guidelines for the construction of multiple choice questions tests.多项选择题的结构指南
9 Questimator: Generating knowledge assessments for arbitrary topicsQuestimator:生成任意主题的知识评估
10 Semantic similarity of distractors in multiple-choice tests: extrinsic evaluation多项选择测验中干扰语的语义相似性:外部评价
11 Semiautomatic generation of cloze question distractors effect of students完形填空的候选集的半自动生成对于学生的影响
12 Good question! statistical ranking for question generation. In Human Language Technologies:生成问题,由一个陈述句转变为提问问题
13 Wikiqa: A challenge dataset for open-domain question answering. ACL Association for Compu- tational Linguistics. https://www.microsoft.com/en- us/research/publication/wikiqa-a-challenge-dataset- for-open-domain-question-answering/.