TB级Elasticsearch全文检索优化研究
Elasticsearch全文检索优化研究
背景
今年工作的一个重点是“新技术新模式”的导入和研究。Elasticsearch技术比较火,各项目和产品用的都也比较多。其中某团队遇到一个问题:“在TB级的数据量下进行全文检索时,ES集群检索响应速度比较慢”。虽然由于各种原因没有接触到系统,没有看到代码,甚至都没见到具体现象,但是任务分配下来了,就要有结果就要出方案。“没吃过猪肉,也得先见见猪跑”,先在一个30GB级别的ES集群下做一下优化研究。
全文检索的原理
- 全文检索的定义
全文检索和普通查询最大的区别是,全文检索判断的是“相关度”,普通查询判断是“是与非”。比如在全文检索里搜索“我爱你”,除了返回包含“我爱你”的文档,可能还会返回“我不爱你”、“我喜欢你”、“我中意你”、“我爱她” 等文档。相关度越高,也就是得分越高的文档越在前面。 - 检索流程
全文检索的基本流程可以分为两部分,“存”和“取”。“存”部分就是将输入的“字符串”,经过分析器,切分成多个“词”,将这些“词”存储到倒排索引中。“取”部分就是将用户搜索的"字符串",使用相同的分析器,切分成多个“词”,在倒排索引中检索是否包含这些“词”,包含就将这些词对应的文档返回。
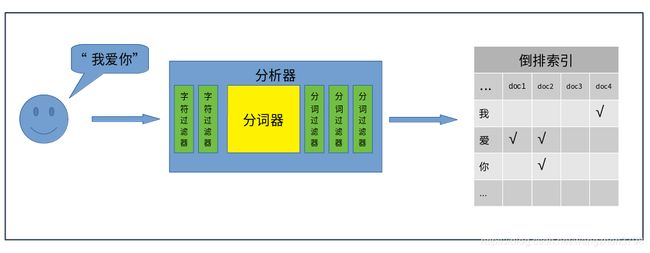
- 分析器
在整个全文检索过程中,分析器扮演着非常重要的角色,ES提供的有内置的分析器,社区也提供各种分析器插件(如中文的ik分析器)。分析器由以下几个组件构成:-
字符过滤器(char filters)
主要职责是在分词器前过滤字符流,在源字符流中添加、删除、替换字符。一个分析器中可以有0个或多个字符过滤器。主要包括:html char filter、mapping char filter等。 -
分词器
主要职责是将接收到的字符流,按照某些规则切分成若干个“词”,并记录这些“词”在源字符串中的位置。比如将“我爱你”切分成"我"、“爱”、“你”、“我爱”,“爱你”,“我爱你”等等。分析器中有且只能有一个分词器。 -
分词过滤器
主要职责是将分好的“词”进行某种规则的过滤,可以添加、移除、替换“词”,但是不能修改“词”在源字符串中的相对位置。一个分析器中可以有0个或多个分词过滤器。常用的分词过滤器包括:大小写转换过滤器、停用词过滤器、同义词过滤器、拼音过滤器 等等
-
一个分析器可以有字符过滤器、分词器、分词过滤器自由组合,形成新的自定义的分析器。
- 推理总结
根据全文检索的原理和流程可以推理出以下几点:- 全文检索本质上是精确匹配。如果某分析器将“我爱你”切分成了“我爱”和“爱你”两个词。那么直接搜索“爱”,是查不到任何文档的。
- 全文检索本质上是预处理的检索。分析器将所有可能被检索的“词”都预先建立了索引。理论上不能搜索没有被切分的词。
- 高频词会影响检索的性能。比如1000万文档,900万都包含“爱”字。那么检索“爱”字时就会把900万文档都查出来,然后计算出“爱”在每份文档的得分,返回得分最高的文档。
- 分析器会增加索引空间大小。比如某分词器将“我爱你”切分成"我"、“爱”、“你”、“我爱”,“爱你”,“我爱你”,要比切分成"我爱你"一个词的空间大N倍。
- 好的的分析器应该在分词的精确度和碎片度之间平衡,即能保证查的到、查的准,又能保证不大量增加索引空间。
分析器对比
分析器有很多种,有ES内置的和社区提供的。其中主流的分析器包括:standard 、ansj、ik、smartcn、icu、mmseg、pinyin,且均能支持中文分词。
- 基本用法
#查看集群安装的分析器插件
GET /_nodes/plugins
#结果:
...
"plugins": [
{
"name": "analysis-icu",
"version": "5.5.1",
"description": "The ICU Analysis plugin integrates Lucene ICU module into elasticsearch, adding ICU relates analysis components.",
"classname": "org.elasticsearch.plugin.analysis.icu.AnalysisICUPlugin",
"has_native_controller": false
},
{
"name": "analysis-ik",
"version": "5.5.1",
"description": "IK Analyzer for Elasticsearch",
"classname": "org.elasticsearch.plugin.analysis.ik.AnalysisIkPlugin",
"has_native_controller": false
},
{
"name": "analysis-mmseg",
"version": "5.5.1",
"description": "Mmseg Analyzer for Elasticsearch",
"classname": "org.elasticsearch.plugin.analysis.mmseg.AnalysisMMsegPlugin",
"has_native_controller": false
},
{
"name": "analysis-pinyin",
"version": "5.5.1",
"description": "Pinyin Analysis for Elasticsearch",
"classname": "org.elasticsearch.plugin.analysis.pinyin.AnalysisPinyinPlugin",
"has_native_controller": false
},
{
"name": "analysis-smartcn",
"version": "5.5.1",
"description": "Smart Chinese Analysis plugin integrates Lucene Smart Chinese analysis module into elasticsearch.",
"classname": "org.elasticsearch.plugin.analysis.smartcn.AnalysisSmartChinesePlugin",
"has_native_controller": false
},
{
"name": "elasticsearch-analysis-ansj",
"version": "5.5.1.0",
"description": "elasticsearch analysis by ansj",
"classname": "org.ansj.elasticsearch.plugin.AnalysisAnsjPlugin",
"has_native_controller": false
}
]
...
查看比较火的ik分词器效果:
GET /medcl/_analyze
{
"text": "武汉市长江大桥",
"analyzer": "ik_max_word"
}
#结果:
{
"tokens": [
{
"token": "武汉市",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "武汉",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "市长",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "长江大桥",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 3
},
{
"token": "长江",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "大桥",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 5
}
]
}
- 分词准确度比较
比较几种分析器对武汉市长江大桥这句话分词的准确度。
| 分析器 | 分词效果 |
|---|---|
| standard | “武”、“汉”、“市”、“长”、“江”、“大”、“桥” |
| ik | “武汉市”、“武汉”、“市长”、“长江大桥”、“长江”、“大桥” |
| smartcn | “武汉市”、“长江”、“大桥” |
| ansj | “武汉市”、“长江”、“大桥” |
| mmseg | “武汉”、“市”、“长江”、“大桥” |
| icu | “武汉”、“市”、“长江”、“大"、"桥” |
结论:smartcn和ansj是比较准确和智能的分析器
- 分词后索引空间比较
- 分词速度比较
优化方案
-
部署架构优化
在部署方式上应该采用分布式思想。- 8台16核64G内存RAID0磁盘阵列的中配计算集集群 性能好于1台128核512G内存RAID10磁盘阵列的高配计算机。
-
ES实例参数优化
- OS层调优参见官文和本人博客《Linux参数调优积累》
- JVM的最大最小堆内存应为RAM的40%,且最大不超过30G。
- index的分片数量应该设置成8片,并根据实际情况扩充至16片或更多。
- 分析器建议选择smartcn或者ansj。
-
ES查询语句优化
- 尽量少使用父子文档模型,减少父子联查。
- 禁用_all等索引和映射的元数据。
- 禁用script_field和function_score。
- 禁用 wildcard、prefiexd、fruzzd等模糊查询。
- 优先使用filter过滤掉不需要的数据,减小计算评分的数据量。