基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(七)
目录
- 前言
- 总体设计
-
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
-
- 1. 模型训练
-
- 1)数据集分析
- 2)数据预处理
- 3)模型创建
- 4)模型训练
- 5)获取特征矩阵
- 2. 后端Django
- 3. 前端微信小程序
-
- 1)小程序全局配置文件
- 2)推荐电影页面
- 3)个人信息界面以及用户登录记录页面
- 系统测试
-
- 1. 模型损失曲线
- 2. 测试效果
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目专注于MovieLens数据集,并采用TensorFlow中的2D文本卷积网络模型。它结合了协同过滤算法来计算电影之间的余弦相似度,并通过用户的交互方式,以单击电影的方式,提供两种不同的电影推荐方式。
首先,项目使用MovieLens数据集,这个数据集包含了大量用户对电影的评分和评论。这些数据用于训练协同过滤算法,以便推荐与用户喜好相似的电影。
其次,项目使用TensorFlow中的2D文本卷积网络模型,这个模型可以处理电影的文本描述信息。模型通过学习电影的文本特征,能够更好地理解电影的内容和风格。
当用户与小程序进行交互时,有两种不同的电影推荐方式:
-
协同过滤推荐:基于用户的历史评分和协同过滤算法,系统会推荐与用户喜好相似的电影。这是一种传统的推荐方式,通过分析用户和其他用户的行为来推荐电影。
-
文本卷积网络推荐:用户可以通过点击电影或输入文本描述,以启动文本卷积网络模型。模型会分析电影的文本信息,并推荐与输入的电影或描述相匹配的其他电影。这种方式更注重电影的内容和情节相似性。
综合来看,本项目融合了协同过滤和深度学习技术,为用户提供了两种不同但有效的电影推荐方式。这可以提高用户体验,使他们更容易找到符合他们口味的电影。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
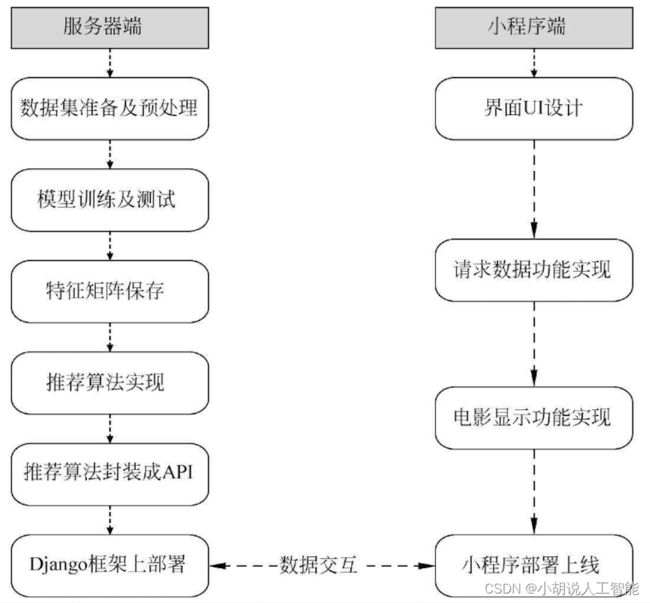
系统流程图
系统流程如图所示。

模型训练流程如图所示。

服务器运行流程如图所示。

运行环境
本部分包括Python环境、TensorFlow环境、 后端服务器、Django和微信小程序环境。
模块实现
本项目包括3个模块:模型训练、后端Django、 前端微信小程序模块,下面分别给出各模块的功能介绍及相关代码。
1. 模型训练
下载数据集,解压到项目目录下的./ml-1m文件夹下。数据集分用户数据users.dat、电影数据movies.dat和评分数据ratings.dat。
1)数据集分析
数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt对数据的描述。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#1_44
2)数据预处理
通过研究数据集中的字段类型,发现有一些是类别字段,将其转成独热编码,但是UserID、MovieID的字段会变稀疏,输入数据的维度急剧膨胀,所以在预处理数据时将这些字段转成数字。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#2_123
3)模型创建
相关博客:https://blog.csdn.net/qq_31136513/article/details/133125845#3_50
4)模型训练
相关博客:https://blog.csdn.net/qq_31136513/article/details/133130704#4_57
5)获取特征矩阵
本部分包括定义函数张量、生成电影特征矩阵、生成用户特征矩阵。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133130704#5_240
2. 后端Django
该模块实现了推荐算法的封装与前端数据交互功能。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133131103#2_Django_67
3. 前端微信小程序
该模块实现用户交互以及与后端数据的传输功能,通过微信开发者平台进行前端开发。
1)小程序全局配置文件
全局配置文件通常以APP开头,包括app.js、app.json、app.wxss等, 这些文件在新建小程序时,由微信开发者平台自动生成。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133146411#1_75
2)推荐电影页面
推荐电影页面movies,包含movies.js、movies.json、movies.wxml、movies.wxss。其中movies.js记录的是逻辑层; movies.wxml记录的是视图层; movies.wxss记录页面元素的样式表;movies.json 类似于app.json,记录这个页面的相关配置信息。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133146411#2_177
3)个人信息界面以及用户登录记录页面
这两个页面是新建小程序时系统自动生成的,不做改动。以下个人信息页面由index.js、index.html、 index.json、index.wxss等文件构成。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133146411#3_383
系统测试
本部分包括模型损失曲线及测试效果。
1. 模型损失曲线
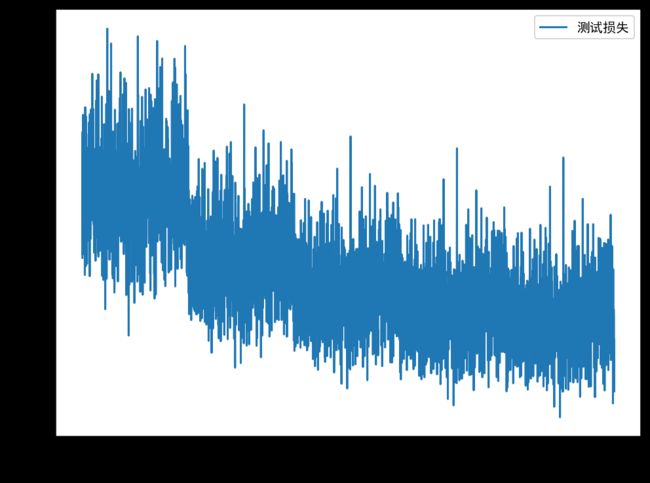
模型使用真实评分与预测评分的MSE作为损失函数,随着迭代次数的增多,在训练数据、测试数据上的损失逐渐降低,最终趋于稳定,经过5次迭代后,损失稳定为1。
训练损失如图所示。

测试损失如图所示。
2. 测试效果
前端小程序开发完成后,在微信开发者平台中进行预览,操作界面如图所示。

Movies页面中有两种推荐方式选择按钮,下面还有5部随机显示的电影信息。选择其中一种方式进行电影推荐,也就是“同类型电影”的推荐方式,再选择其中一部电影,例如,选择当前屏幕中的第一部电影Last Night,可以看到推荐了很多同类型的电影,如图所示。

选择另一种方式,即“看过这个的还喜欢看”的推荐方式,继续选择第一部电影,出现其他电影,如图所示。

相关其它博客
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(一)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(二)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(三)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(四)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(五)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(六)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。