Hugging Face第一本中文书出版啦!
Datawhale分享
学习生态伙伴:Hugging Face
你能想象吗?下面这些精美绝伦的图片竟然都是AI自动生成的!


图:书中插图
没想到,AI界已经有如此炫酷的技术!而在整个过程中,创作者只用做一件事,那就是:用一段文字描述想要的图片内容。
这种效果背后的技术被称作扩散模型(Diffusion Model)。
事实上,它在很多领域都占有一席之地,在游戏、生物、医疗等行业都能看到它的身影。其中,最知名的当属画作《太空歌剧院》。
可见,AI绘画已经彻底出圈。现如今,要进入AI领域,AIGC几乎已经是人手必备的生存技能了。
那么,在这一过程中,关乎其效果的背后的技术扩散模型是如何发挥魅力的呢?
今天,就让我们借由这本得到澜舟科技创始人兼 CEO,创新工场首席科学家,CCF副理事长周明、北京大学人工智能研究院研究员杨耀东等联袂推荐的《扩散模型从原理到实战》,一窥究竟。
▲
Datawhale专属
5折
购书,限50人
01
赶超AI风口,让模型“扩散”起来!
扩散模型是基于扩散思想的深度学习生成模型,其背后蕴含着复杂的数学原理。
小异发现,为了便于读者理解,作者特意避开了这些复杂内容。但是,读者依旧可以基于本书内容学会如何生成精美图像。
扩散模型是一类生成模型,它借鉴了物理热力学中的扩散思想:分子从高浓度区域扩散到低浓度区域。这与由于噪声干扰导致的信息丢失十分相似。
书中采用了一滴墨水在水中扩散的过程举例。
▮ 初始状态:扩散开始之前,这滴墨水会在水中的某个地方形成一个大的斑点。
▮ 扩散过程:这滴墨水随着时间的推移逐步扩散到水中,水的颜色也逐渐变成这滴墨水的颜色。
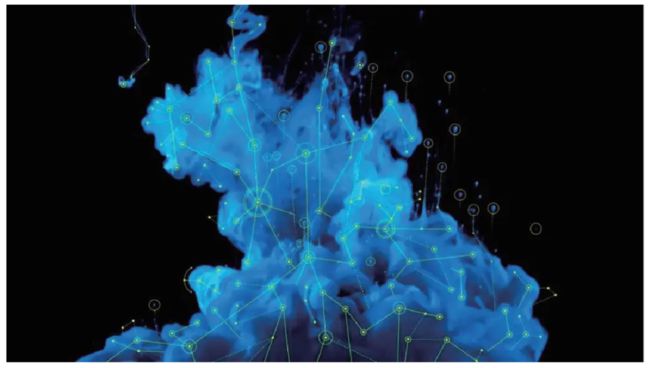
图:一滴墨水在水中扩散分布的示意图(选自书中)
就这个过程而言,描述该初始状态的概率分布很困难,因为该分布非常复杂。而扩散后的墨水分子的概率分布更加简单和均匀,可以很轻松地用数学公式来描述。
这时候非平衡热力学就派上用场了,它可以描述墨水随时间推移的扩散过程中每一个时间步状态的概率分布。如果把这个过程反过来,就可以从简单的分布中逐步推断出复杂的分布。
扩散模型和这个过程类似,只不过它分为前向扩散和反向扩散两个过程。
▮ 前向扩散:引入噪声,并学习由噪声引起的信息衰减,最终得到纯随机噪声分布的数据,即类似稳定墨水系统的状态。
▮ 反向扩散:前向扩散的反向过程,是“去噪”的过程,即从随机噪声中迭代恢复出清晰数据的过程。通俗地说,就是生成模型的采样过程。

图:DDPM 的扩散过程(选自书中)
公认最早的扩散模型 DDPM(Denoising Diffusion Probabilistic Mode)的扩散原理就由此而来。
作者在书中对扩散模型做了大量的诠释,也给出了对应的案例和代码,降低了理解门槛,提高了学习效率。

图:使用现有模型再学习到指定主体图像的功能
在第3章中,作者以实战方式演示了从0开始搭建扩散模型的过程,从一个简单的扩散模型讲起,展示其不同部分的工作原理。
▮ 退化:引入噪声并和内容混合。

▮ 训练模型:获取一批数据添加随机噪声,之后将数据输入模型,对模型预测与初始图像进行比较,计算损失更新模型的参数。

图:模型的预测结果(选自书中)
▮ 采样过程:从完全随机的噪声开始,先检查一下模型的预测结果,然后只朝着预测方向移动一小部分(比如,20%),如果新的预测结果比上一次的预测结果稍微好一点,就可以根据这个新的、更好的预测结果继续往前迈出一步。

图:采样过程(选自书中)
此外,作者还对调整时间步、优化采样步骤等提出了思考,以便更好地改善模型效果。同时,读者可以访问B站观看Hugging Face平台提供的课程,来以互动性更强的方式学习扩散模型知识。
图:B站扩散模型直播活动
正如一开始所说,扩散模型已经逐渐渗透到了生活、工作的方方面面,甚至有科学家已经开始尝试结合大型语言模型的信息与图像生成扩散模型,用文本指导扩散过程。
作者也希望各位读者可以将学到的知识与专业领域或技能相结合,解决生活或工作中的实际问题。
02
巧用工具,你的模型你做主!
工欲善其事,必先利其器。
想要更高效地打造扩散模型并解决日常问题,少不了给力的工具。作者也在书中介绍了很多实用工具——
首先是Hugging Face,它是专门服务机器学习从业者的协作和交流平台,致力于构建开放、负责的人工智能的未来。本书第3-8章的内容就是基于Hugging Face平台上的Diffusion课程设计的。
Hugging Face 的核心产品是 Hugging Face Hub——一个基于 Git 进行版本管理的存储库,由模型、数据集、应用程序三块组成。
截至 2023 年 3 月底,Hugging Face Hub 上已经托管了 16.2 万个模型、2.6 万个数据集以及 2.5 万个应用程序。
▮ 模型:每一个模型都有一个模型卡片页面,包括介绍、用途和限制、使用方法、训练方法、模型评估、使用的数据集,甚至还有供快速体验的示例应用,让读者快速体验。
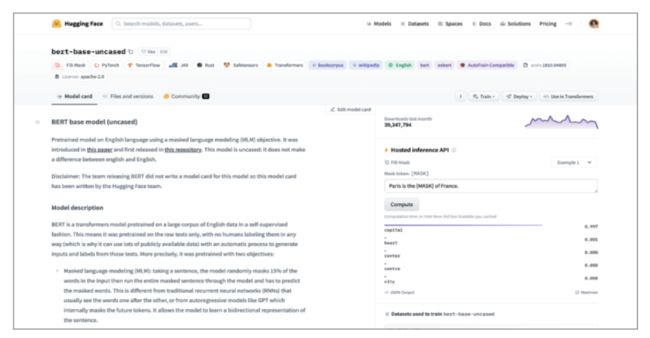
图:Hugging Face Hub 上的模型卡片(选自书中)
▮ 数据集:Hugging Face 归集了超过5000个数据集,涵盖100多种语言,可用于自然语言处理、计算机视觉和音频等广泛领域的任务。
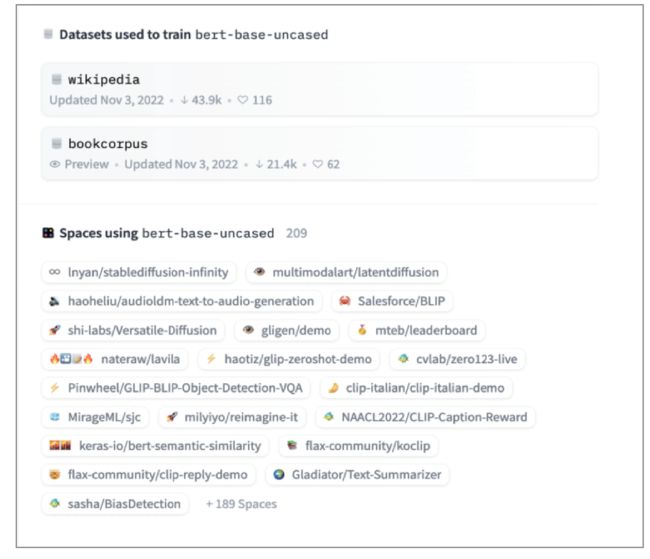
图:某个模型的训练数据集以及使用该模型建立的应用列表(选自书中)
▮ 应用程序:Hugging Face Hub 提供了Spaces 功能,它可以让你在几分钟内创建和部署一个应用程序。
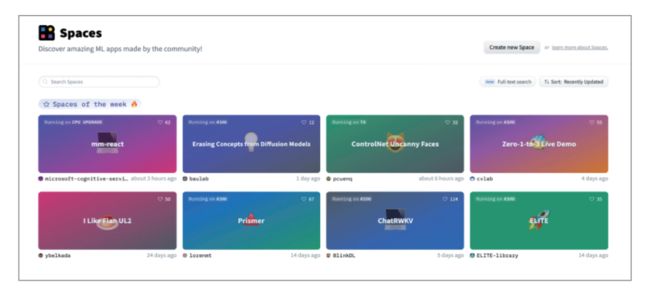
图:Hugging Face Hub 内展示的本周热门 Spaces 应用
除此之外,Hugging Face 还在 GitHub 上开源了一系列机器学习库和工具,比如Transformer、Datasets、diffusers等。
此外,作者还介绍了开源的 Python 库Gradio。它由 Hugging Face 推出,用于构建机器学习和数据科学演示以及 Web 等应用。
当需要向用户展示机器学习模型的时候,Gradio 可以有效地帮助你创建交互式应用。
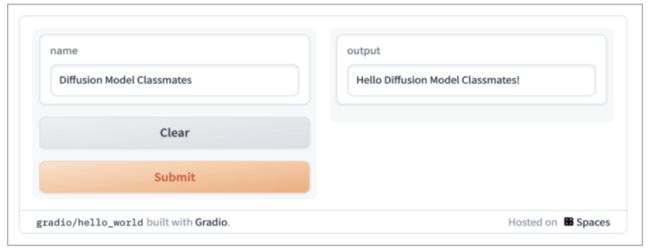
图:使用 Gradio 运行“Hello World !”
程序(选自书中)
03
关注未来技术趋势!
剑桥大学的2022年 AI 全景报告(《State of AI Report 》)指出:扩散模型席卷计算机视觉世界是AI五大趋势之一。
从国内外各机构、大厂近期的种种操作看来,这个预测已经照进现实:
▮ 清华朱军团队开源首个基于Transformer的多模态扩散大模型;
▮ 谷歌提出扩散模型推理加速新方法;
▮ 英特尔研究院宣布与Blockade Labs合作发布LDM3D扩散模型,使用生成式AI创建3D视觉内容……
扩散模型不再是论文里的畅想,而是握在手中的实际成果。如何用扩散模型创造更多可能?欢迎入手这本书寻找答案!
▲
Datawhale读者专属
5折
购书
最后,为了感谢各位读者的一直以来的支持,在Datawhale送出5本《扩散模型:从原理到实战》,依然是老规矩:评论区留言并点赞数前五的读者将直接送书。