kotlin协程知识点梳理
前言
coroutines一词1958年提出来的,协程发明并用于构建汇编程序,说明协程是一种编程思想,并不局限于特定的语言。笔者就着文档简单的过了一下,记录了一点东西,有一些不常用的就没研究了,以后再补充,文章有点长,可能看字有点干,先上我最爱的熊猫图。

补充1:为啥我8核16线程的处理器,任务管理器里有那么多进程?
以AMD3700x 8核心16线程的处理器为例。严格意义上来说,他只有8核,同一时间点,应该只能有8个进程16个线程在运行。但是实际上,不管是进程也好,线程也好,远远不止这么点。为什么呢?因为现在硬件性能非常好,进程切换的非常快,宏观上给人感觉有多个程序在同时运行,所以任务管理器里才会有那么多的进程和进程树。
补充2:并行和并发
并发:在操作系统中,某一时间段,几个程序在同一个CPU上运行,但在任意一个时间点上,只有一个程序在CPU上运行。
并行:当操作系统有多个CPU时,线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式成为并行。
并发告诉我们,有处理多个任务的能力,但不要求同时。并行告诉我们,同一时间点有处理多个任务的能力。所以重点是同时。
补充3:进程和线程
进程是资源分配的最小单位。线程是程序执行过程中的最小单元。
其实操作系统有他自己的一套进程管理方法,因为要给人用啊,所有搞了个内核态和用户态。有没有发现一个事,任务管理器里有些进程关不掉或者关掉直接黑屏,没错,用户就好好关注你的用户线程,别有事没事去动系统的。
补充4:线程的效率已经这么高了,为啥还要协程
用协程的好处:内存开销小、上下文切换开销小、由于是用户态所以执行过程不会被系统强行中断、适合高并发场景。
线程的切换是由内核控制的,时间片用尽,当调用阻塞方法时,内核为了CPU 充分工作,也会切换到其他线程执行。当线程繁忙且数量众多时,这些切换会消耗绝大部分的CPU运算能力,经过实践得到一次切换耗时为3.5us。而协程可以在不陷入内核的情况进行上下文切换。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快,切换耗时只有区区100ns多一些。协程是用户态的轻量级线程。
在Linux系统中,系统默认分配8M给一个线程(可以通过 ulimit 之类的命令修改);java中,如jdk1.8,系统默认分配1M给一个线程;kotlin的协程需要分配的内存非常小(几十KB的级别)。
讲一讲协程并发模型和多线程同步模型。举个例子,用分治算法. 进程太多要靠线程分摊. 线程太多要用协程分摊. 100万个任务, 分解成100个进程, 每个进程100个线程, 每个线程100个协程, 列表的时间复杂度就能大幅度降低.
思考:空间还是时间性能都这么牛逼,操作系统干嘛不用协程
无论是空间还是时间性能都比进程(线程)好这么多,那么Linux为啥不把它在操作系统里实现了多好?操作系统为了实现实时性更好的目的,对一些优先级比较高的进程是会抢占其它进程的CPU的。而协程无法实现这一点,还得依赖于当前使用CPU的协程主动释放,于操作系统的实现目的不相吻合。所以协程的高效是以牺牲可抢占性为代价的。
协程中重要的概念
CoroutineScope
协程作用域,内部有作用域的CoroutineContext。协程的使用离不开其作用域,所有的协程构建器都声明为在它之上的扩展。
构造函数
ContextScope(context: CoroutineContext)
示例
//MainScope是工厂函数
private val mainScope = MainScope()
CoroutineContext
CoroutineContext作为协程上下文。协程上下文是各种不同元素的集合,其主元素是协程中的Job。有时我们需要在协程上下文中定义多个元素。我们可以使用 + 操作符来实现(表面上是个操作符,其实是个操作符函数)。
示例:
//指定调度器和名字
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
//创建了作业对象,指定了调度器
ContextScope(SupervisorJob() + Dispatchers.Main)
//空的协程上下文
EmptyCoroutineContext
CoroutineDispatcher
协程调度器。所有的协程构建器诸如 launch 和 async 接收一个可选的 CoroutineContext 参数,它可以被用来显式的为一个新协程或其它上下文元素指定一个调度器。如果不指定,从启动了它的 CoroutineScope 中承袭了上下文(以及调度器)。
在作用域内使用协程时,经常要用到下面这些调度器
- Dispatchers.Default
- Dispatchers.Main
- Dispatchers.Unconfined
- Dispatchers.IO
示例
//用的ExecutorCoroutineDispatcher
launch(newSingleThreadContext("MyOwnThread")) { // 将使它获得一个新的线程
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}
withContext(Dispatchers.IO){
}
闭包
闭包从java8就开始支持了,在kotlin中有个语法糖:函数的最后一个参数是 lambda 表达式时,可以将 lambda 写在括号外。
示例
//创建一个 Thread 一般这么写
Thread(object : Runnable{
override fun run() {
}
})
//满足条件,转化成lambda
Thread({ })
//再简化为
Thread { }
形如Thread {…},这样的结构中{}就是一个闭包。
Java中线程
Java中线程
- 想知道线程执行结束了,要用FutureTask;
- 想一个线程让出资源进入阻塞状态等待另一个线程执行结束再执行,要用join方法;
- 多个线程管理,要用线程池Executor。
- Android中封装了Handler进行线程间通信。此外还有已经过时了的AsyTask。
关于Java中线程和锁,了解更多请查看Java基础知识梳理中线程和锁部分。
协程是个啥?
首先,协程是个对象,被suspend关键字修饰的一个函数。具体查看withContext等函数源码。
被suspend关键字修饰的函数块,只能在协程作用域或者其他被suspend关键字修饰的函数块中调用。协程很牛逼的一个地方就是「非阻塞式」挂起,包括线程的自动调度,这个我们下面再讲。先要明白,这个对象是一个函数。
啥叫挂起?
在一个launch,async或者withContext函数中闭包的代码块,在执行到某一个suspend函数的时候,这个协程会被「suspend」,也就是被挂起。换句话说,就是从正在执行他的线程上脱离。他不会阻塞当前线程。
//doSomeThing和doOtherThing都是suspend修饰的函数,内部进行了耗时的操作
coroutineScope.launch() {//当前线程名为main
launch { doSomeThing() } // 执行doSomeThing不会阻塞main线程
launch { doOtherThing() } // 执行doOtherThing不会阻塞main线程
doXXThing() //正常执行
}
- 挂起不能脱离多线程的背景来谈。
- 挂起的对象是协程。
- 挂起的来源是从当前线程挂起。
- 挂起后会恢复。并且挂起并不会阻塞当前线程。
啥叫挂起:一个稍后会被自动切回来的线程调度操作。
非阻塞式挂起
「非阻塞式挂起」是协程非常厉害的一个地方。阻塞是针对单线程讲的,因为挂起就涉及到多线程,一旦切了线程,那肯定是非阻塞的,切了线程原来的线程自由了,没有了障碍,可以继续干其他的。
代码本质上都是阻塞式的,而只有比较耗时的代码才会导致人类可感知的等待,比如一次网络请求更多是反映在「等」这件事情上,你切多少个线程都无法减少要花费的时间。这跟协程半毛钱关系没有,协程只是帮我们切线程而已,所以看上去就像用同步的方式写异步的代码。
准备工作
工程目录build.gradle下添加信息
buildscript {
ext.kotlin_version = "1.4.31"
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
}
}
项目moudle下build.gradle添加信息
dependencies {
// 协程基础库
api "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.4.3"
api "org.jetbrains.kotlinx:kotlinx-coroutines-android:1.4.3"
}
开启一个协程
要用协程,必须有作用域,作用域又必须有上下文。
在任何类里的顶层函数使用
顶层函数,类比java中全局静态函数。
/**
* 用于单元测试的场景,业务开发中不适用,因为他是线程阻塞的
**/
runBlocking {
//todo
}
使用全局GlobalScope
/**
* 不会阻塞线程,但是不建议使用,此作用域生命周期和应用一致,无法主动取消
**/
GlobalScope.launch { // 在后台启动一个新的协程并继续
//delay是一个特殊的挂起函数,它不会造成线程阻塞,但是会 挂起 协程,并且只能在协程中使用
delay(1000L) // 非阻塞的等待 1 秒钟(默认时间单位是毫秒)
print("World!") // 在延迟后打印输出
}
print("Hello,") // 协程已在等待时主线程还在继续
Thread.sleep(2000L) // 阻塞主线程 2 秒钟来保证 JVM 存活
println("My Name is Tom!")
此例打印结果为:Hello,World!My Name is Tom!
部分官方架构封装了对协程的支持
这里简单提一下,比如ViewModel中viewModelScope还有活动页和碎片页中的lifecycle.coroutineScope。
自己创建一个CoroutineScope
val coroutineScope = CoroutineScope(SupervisorJob()+Dispatchers.Main)
coroutineScope.launch {
//做一些主线程做的事
withContext(Dispatchers.IO) {
//切到IO线程做事
}
//会自动切回来
}
常用的开启协程函数
在作用域内,常用的方法有:async、launch、withcontext、actor。
Job
一个接口,是协程的重点。
- Job中一些值:isActive、isCompleted、isCancelled、children。
- Job中一些方法:start、cancel、join、invokeOnCompletion、plus。
Deferred
继承自Job。
- Deferred中值:onAwait
- Deferred中一些方法:await、getCompleted、getCompletionExceptionOrNull
async基本用法
普通并发
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
惰性启动的 async
//惰性模式下,只有通过await获取或调用start的时候协程才会启动
//DEFAULT模式
val one=async (start = CoroutineStart.LAZY){
}
one.start()
val one = async { doSomethingUsefulOne() }
one.invokeOnCompletion{
//如果指定启动方式为惰性,这里不会回调,证明根本没启动
}
特点
- async是传播异常的。async{…}中未处理的异常会导致所有在作用域中启动的协程都会被取消,是以作用域为单位,不管是等待中的父协程还是另一个子协程,只要在一个作用域,就会受影响。
- async返回的Coroutine比launch返回的多实现了Deferred接口中的方法(Deferred继承自Job),Deferred有延迟的意思。
- 处理异常可以在初始化时候传入自定义的CoroutineExceptionHandler,然后可能出现异常的代码用try catch或者runCatching包裹。
来个异步的示例
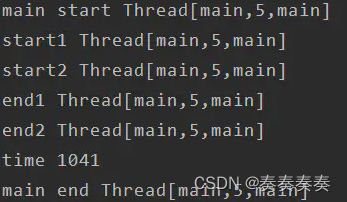
fun main()= runBlocking{
println("main start ${Thread.currentThread()}")
val time = measureTimeMillis {
val job1 =async {
loadTask1()
}
val job2= async {
loadTask2()
}
job1.await()
job2.await()
}
println("time $time")
println("main end ${Thread.currentThread()}")
}
结果如下
launch基本用法
很多用法可以参考async
有点不太好的是需要频繁切换线程时,不太整洁
//为了消除这种并发代码在协作时的嵌套,可以使用withContext
coroutineScope.launch(Dispachers.IO) {
...
launch(Dispachers.Main){
...
launch(Dispachers.IO) {
...
launch(Dispacher.Main) {
...
}
}
}
}
特点
- 不指定启动选项是默认执行的,所以并不需要手动调用Job#start()或者join()方法。
- 默认情况下,此协程中未捕获的异常会取消上下文中的父作业(除非明确指定了CoroutineExceptionHandler),这意味着当将launch与另一个协程的上下文一起使用时,任何未捕获的异常都会导致父协程的取消。
launch不会阻塞主线程的执行,示例如下
fun main()= runBlocking{
println("main start ${Thread.currentThread()}")
launch {
loadTask1()
}
launch {
loadTask2()
}
println("main end ${Thread.currentThread()}")
}
suspend fun loadTask1(){
println("start1 ${Thread.currentThread()}")
delay(1000)
println("end1 ${Thread.currentThread()}")
}
suspend fun loadTask2(){
println("start2 ${Thread.currentThread()}")
delay(1000)
println("end2 ${Thread.currentThread()}")
}
结果如下
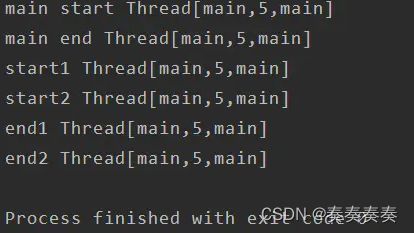
说明:执行loadTask1的时候,遇到delay,所以挂起loadTask1,执行loadTask2,然后loadTask11结束,loadTask12结束
关于join方法,是挂起一个协程直到他结束
fun main()= runBlocking{
println("main start ${Thread.currentThread()}")
val time = measureTimeMillis {
val job1 =launch {
loadTask1()
}
job1.join()
val job2= launch {
loadTask2()
}
job2.join()
}
println("time $time")
println("main end ${Thread.currentThread()}")
}
结果如下
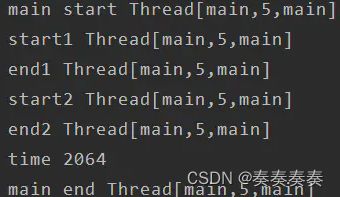
说明:耗时2064说明了一切。比2s多一点,因为调度是要花时间的。
补充1:协程的启动选项CoroutineStart
- DEFAULT 立即根据协程安排执行协程;
- LAZY 仅在需要时才懒惰地启动协程;
- ATOMIC 原子地(以不可取消的方式)根据协程的上下文来调度协程以执行该协程;
- UNDISPATCHED 立即执行协程,直到其在当前线程中的第一个挂起点。
补充2:使用生命周期作用域开启一个协程
lifecycle.coroutineScope.launchWhenStarted { Log.d("status:", "launchWhenStarted") }
lifecycle.coroutineScope.launchWhenResumed { Log.d("status:", "launchWhenResumed") }
withContext基本用法
消除使用launch并发代码在协作时的嵌套。
coroutineScope.launch(Dispachers.Main) {
...
withContext(Dispachers.IO) {
...
}
...
withContext(Dispachers.IO) {
...
}
...
}
特点
- 默认使用新上下文中的调度程序Dispatchers,如果指定了新的调度程序,则将块的执行转移到不同的线程中,并在完成时将其转移回原始调度程序。
示例分析1
//doSomeThing和doOtherThing都是suspend修饰的函数,且执行耗时操作
coroutineScope.launch(Dispatchers.Main) {
Log.e("launch","I'm working in thread ${Thread.currentThread().name}")
doSomeThing()
doOtherThing()
Log.e("finally","come here")
}
coroutineScope.launch(Dispatchers.Main) {
Log.e("launch","I'm working in thread ${Thread.currentThread().name}")
withContext(Dispatchers.IO) {
doSomeThing()
}
withContext(Dispatchers.IO) {
doOtherThing()
}
Log.e("finally","come here")
}
coroutineScope.launch(Dispatchers.Main) {
Log.e("launch","I'm working in thread ${Thread.currentThread().name}")
withContext(Dispatchers.IO) {
doSomeThing()
}
doOtherThing()
Log.e("finally","come here")
}
打印结果为
launch: I'm working in thread main
doSomeThing: I'm working in thread DefaultDispatcher-worker-1
doOtherThing: I'm working in thread main
finally: come here
结果分析:doSomeThing返回结果才继续执行doOtherThing,doOtherThing返回结果后才打印“finally: come here”。
launch开启一个协程s,此时这个协程运行在主线程mian中,然后不管是直接调用函数还是使用withcontext包裹,结果都是一样。看上去就像用同步的方式写异步的代码。
示例分析2
稍微改一下
coroutineScope.launch(Dispatchers.Main) {
Log.e("launch","I'm working in thread ${Thread.currentThread().name}")
launch { doSomeThing() }
launch { doOtherThing() }
Log.e("finally","come here")
}
打印结果为
launch: I'm working in thread main
finally: come here
doSomeThing: I'm working in thread main
doOtherThing: I'm working in thread main
结果可知,doSomeThing和doOtherThing是异步执行的。和示例分析1中同步的情况完全不同。
官方架构对协程的支持
Android 在所有具有生命周期的实体中都对协程作用域提供了一等的支持,比如ViewModel, Lifecycle, LiveData , Room 等。
我们知道作用域和生命周期是有关系了,下面举几个示例说明在不同场景使用协程
-
ViewModel中
使用的是一个打了标签的作用域,上下文使用:
//+是CoroutineContext接口内的运算符函数plus
SupervisorJob() + Dispatchers.Main.immediate
有了作用域,就可以使用协程了。
viewModelScope.launch {
}
分析:viewModelScope的实现非常简单,带有 Dispatchers.Main 的 SupervisorJob,当ViewModel.clear()时,在里面调用Job.cancel(),因为结构化并发的原因,所有在viewModelScope范围内启动的协程, 都会级联取消.
-
Activity和Fragment中
不推荐使用GlobalScope来开启协程,他生命周期与app一致,且无法取消。
建议使用viewLifecycleOwner.lifecycleScope或lifecycle.coroutineScope。
lifecycle.coroutineScope.launch {}
lifecycle.coroutineScope.launchWhenCreated { }
lifecycle.coroutineScope.launchWhenResumed { }
lifecycle.coroutineScope.launchWhenStarted { }
viewLifecycleOwner.lifecycleScope.launch {}
viewLifecycleOwner.lifecycleScope.launchWhenCreated { }
viewLifecycleOwner.lifecycleScope.launchWhenResumed { }
viewLifecycleOwner.lifecycleScope.launchWhenStarted { }
在 Activity 或者 Fragment 中, 我们有时需要等到某个生命周期方法时, 或者至少在某个生命周期方法之后才执行某一任务, 如页面状态至少要 STARTED 才可以执行 FragmentTransaction , 对这种需求,Lifecycle库提供对于协程的支持:launchWhenCreated、launchWhenResumed、launchWhenStarted。当页面状态不满足时,协程会挂起。
注意:生命周期方法重复调用,协程并不会重启。比如从活动页A跳转到活动页B再返回A,此时A的生命周期为onRestart->onStart->onResume。此时launchWhenStarted内部的函数并不会调用。
还有一点,上面我们提过ViewModel的onCleared方法内部可以做一些资源的释放。那在活动页和碎片里呢,虽然可以在onDestroy里,但是在知道页面销毁,协程会自动取消后,我们可以写一部分在协程里,示例如下
lifecycle.coroutineScope.launchWhenResumed {
try {
//do something
//maybe suspend function
delay(10000L)//模拟耗时
}finally {
//协程里的任务还没做完,页面就销毁了,会跑这来
//正常情况也会跑这来,但是当前状态一般不是State.DESTROYED
when(lifecycle.currentState==Lifecycle.State.DESTROYED){
//do something
}
}
}
-
LiveData中
val user: LiveData = liveData (timeoutInMs = 5000) {
val data = database.loadUser() // loadUser 是一个挂起函数.
emit(data)
}
这里liveData是一个 builder 函数, 在 builder 代码块中, 它调用挂起函数loadUser()然后通过emit把加载的数据发射出去.
需要注意的是, 当LiveData的状态变为活动时(即有人订阅观察它), 加载动作才会真正执行, 而当它变为不活动时, 并且空闲了timeoutInMs毫秒, 它将会自动取消. 如果在完成之前将其取消,则如果LiveData再次变为活动状态,它将重新启动。如果它在先前的运行中成功完成,则不会重新启动。请注意,只有自动取消后,它才会重新启动。如果由于任何其他原因取消了该块(例如,引发CancelationException),则它不会重新启动。
任何时候如果你想发射新值, 你也可以使用 emitSource(source: LiveData) 来发射多个值, 这里它产生值的源改变了. 调用 emit() 或者 emitSource() 会移除之前添加的源.
class UserDao: Dao {
@Query("SELECT * FROM User WHERE id = :id")
fun getUser(id: String): LiveData
}
class MyRepository {
fun getUser(id: String) = liveData {
val disposable = emitSource( // 这里使用数据库作为源
userDao.getUser(id).map {
Result.loading(it)
}
)
try {
val user = webservice.fetchUser(id)
// Stop the previous emission to avoid dispatching the updated user
// as `loading`.
disposable.dispose()
// Update the database.
userDao.insert(user)
// Re-establish the emission with success type.
emitSource( // 重新用数据库作为源, 因为之前 dispose 了.
userDao.getUser(id).map {
Result.success(it)
}
)
} catch(exception: IOException) {
// Any call to `emit` disposes the previous one automatically so we don't
// need to dispose it here as we didn't get an updated value.
emitSource(
userDao.getUser(id).map {
Result.error(exception, it)
}
)
}
}
}
-
Room中
Room版本2.1开始就支持协程了
@Dao
interface UsersDao {
@Query("SELECT * FROM users")
suspend fun getUsers(): List
@Query("UPDATE users SET age = age + 1 WHERE userId = :userId")
suspend fun incrementUserAge(userId: String)
@Insert
suspend fun insertUser(user: User)
@Update
suspend fun updateUser(user: User)
@Delete
suspend fun deleteUser(user: User)
}
Flow的使用记录
回顾一下,某一个协程作用域都有launch和async方法,前者返回一个Job对象,后者返回一个Deferred对象。然后lauch他是不传播异常的,也就是异常不会影响代码运行,而async是传播异常的,如果作用域内某个协程抛异常没有处理,那会导致整个作用域协程都取消。所以常用runCatching函数处理,或者try catch的方式。
Flow接口的概念
异步数据流,它顺序地发出值并正常或有例外地完成。
流中的中间运算符(例如map,filter,take,zip等)是应用于一个或多个上游流并返回下游流的函数,可以在其中应用其他运算符。
中间操作不会在流中执行任何代码,并且本身不会挂起函数。 他们只建立了一系列操作链,以便将来执行并快速返回。 这被称为冷流特性。
流上的终端运算符要么是暂停功能,如collect,single,reduce,toList等,要么是launchIn运算符,它开始在给定范围内收集流。 它们将应用于上游流程并触发所有操作的执行。流的执行也称为收集流,并且始终以挂起方式执行而没有实际阻塞。终端操作员根据上游中所有流操作的成功或失败执行正常或例外地完成操作。
最基本的终端操作员是collect ,例如:
try {
flow.collect { value ->
println("Received $value")
}
} catch (e: Exception) {
println("The flow has thrown an exception: $e")
}
默认情况下,流是顺序的,并且所有流操作都在同一协程中按顺序执行,但一些专门用于将并发引入流执行的操作(例如buffer和flatMapMerge)除外。
使用场景
看到操作符,我第一时间想到rxjava。那flow的使用场景呢?感觉也差不多。
- 数据源会持续发送数值的话,使用flow会很方便。
- 需要对数据源做处理,之后返回我们需要的结果,也可以使用flow。
//每隔 2 秒发送一个新的天气值
suspend fun fetchWeatherFlow(): Flow = flow {
var counter = 0
while(true) {
counter++
delay(2000)
emit(weatherConditions[counter % weatherConditions.size])
}
}
//在某个协程作用域内调用方法
fetchWeatherFlow().collect{
// 最终回到collect,顺带一提,示例代码是不需要捕获异常,但一般情况下需要
// runCatching{//需要捕获异常的代码}.onSuccess {//处理}.onFailure {//处理}
}
协程间同步
协程同步需使用Mutex
val mutex = Mutex()
suspend fun doSomething(i: Int) {
mutex.withLock {
println("#$i enter critical section.")
// do something
delay(1000) // <- The 'delay' suspension point is inside a critical section
println("#$i exit critical section.")
}
}
fun main() = runBlocking {
repeat(2) { i ->
launch(Dispatchers.Default) {
println("#$i thread name: ${Thread.currentThread().name}")
doSomething(i)
}
}
}
提示:不要想当然在挂起函数上添加@Synchronized关键字,你以为有用?根本同步不了。不信你实践下。
感谢
方卓的Kotlin Coroutine系列文章
kotlin语言中文站
hencoder老师的码上开学
Android KTX官方文档