论文浅尝 | 基于预训练语言模型的简单问题知识图谱问答

笔记整理:刘赫,天津大学硕士
链接:https://doi.org/10.1007/s11280-023-01166-y
动机
大规模预训练语言模型(PLM)如BERT近取得了巨大的成功,成为自然语言处理(NLP)的一个里程碑。现在NLP社区的共识是采用PLM下游任务的骨干。在最近关于知识图谱问答(KGQA)的研究中,BERT或其变体在他们的KGQA模型中已经成为必要。然而,对于不同PLMs在KGQA中的性能,目前还缺乏全面的研究和比较。为此,本研究总结了两个基于PLM额外的神经网络模块的基本KGQA框架,以比较9种PLM性和效率方面的性能。此外,本研究在流行的SimpleQuestions基准测试的基础上提出了三个大规模kg的基准测试,以研究PLM展性。本研究仔细分析了所有基于PLMs的KGQA基本框架在这些基准和另外两个流行的数据集(WebQuestionSP和FreebaseQA)上的结果,发现PLMs中的知识蒸馏技术和知识增强方法对KGQA很有前景。最后,本研究测试了ChatGPT,它在NLP社区中引起了很大的关注,展示了它在零样本KGQA中的令人印象深刻的功能和局限性。
亮点
本文的亮点主要包括:
(1)第一次尝试全面研究各种PLM在KGQA任务中的整体性能。总结提出了两种基本的知识图谱问答框架:基于分类的知识图谱问答框架和基于检索排序的知识图谱问答框架。
(2)评估了所有KGQA框架在所有数据集基准上的整体结果,并从不同PLM和KGQA框架的角度对整体准确性、效率和可扩展性进行了详细分析。
(3)本文研究发现知识蒸馏的轻量级PLM和知识增强型PLM在KGQA中具有很大的潜力,促使未来深入探究这个方向,探索实用的KGQA系统。
概念及模型
本文总结提出了两种基本的知识图谱问答框架:基于分类的知识图谱问答框架和基于检索排序的知识图谱问答框架。前者通过编码问题并将其映射到知识图谱关系字典来回答问题,后者则先检索相邻关系,然后通过网络架构或上下文信息对关系进行排名。这两种框架都由四个模块组成,包括提及检测、实体消歧、关系检测和答案查询。其中,将实体链接和关系检测视为不同的模块,而将它们作为一个流水线处理,关系检测在实体链接之后。
基于分类的知识图谱问答框架
基于分类的知识图谱问答框架如图1所示。它由四个模块组成,分别是提及检测、实体消歧、关系检测和答案查询模块。
提及检测:给定一个问题,提及检测的目标是确定主题是否提及。本文将这个任务视为基于预训练语言模型的命名实体识别任务。问题的序列由预训练语言模型编码,然后将其输入一个线性分类层中。它将为问题序列中的每个单词分配一个标签,B表示提及的开始,I表示提及的中间,O表示未提及。
实体消歧:该框架预先生成了一个反向索引字典,建立了一个提及到实体的映射。我们使用在反向索引字典中查找对应的实体,这些实体被视为候选实体。此外,对于每个候选实体,其相邻关系也将用于消歧。基于PLM的实体消歧模型的损失函数如下,其中,ek表示黄金实体,N表示负样本数量,ej表示负实体,P(y = ek)为ek发生的概率。

关系检测:关系检测是该框架中基于PLMs的分类任务。由于简单的KGQA只考虑一跳关系,因此问题Q只对应于KG中的一个关系。该模型旨在将Q映射到一个KG关系,具体来说利用PLM对问题序列进行编码,得到向量h,然后将h送入线性分类层,得到关系的概率分布。
答案查询:该模块不涉及任何神经网络,旨在使用实体-关系对在KG中查询答案。给定由实体消歧和关系检测模块得到的候选实体集Ec和候选关系集Rc,我们将它们组合成(E, r)对在KB中查询,。我们对每个(e, r)对进行排序,其得分是其组成部分得分的加权和,即实体消歧得分和关系检测得分如下,其中λ∈(0,1),根据验证集的结果进行调优。Se和Sr分别为归一化实体得分和关系得分。
![]()

图 1 基于分类的知识图谱问答框架
基于检索排序的知识图谱问答框架
基于检索排序的知识图谱问答框架如图2所示。它是一个流水线结构,由四个模块组成,其中提及检测、实体消歧和答案查询与基于分类的知识图谱问答框架相同,只有关系检测模块不同。
与基于分类的知识图谱问答框架不同,该框架的关系检测的目的是从候选关系中选择与问题模式具有最高语义相似度得分的关系。Rc由候选实体Ec在KG中搜索到的所有邻接关系组成。问题模式p是通过使用一个特殊token

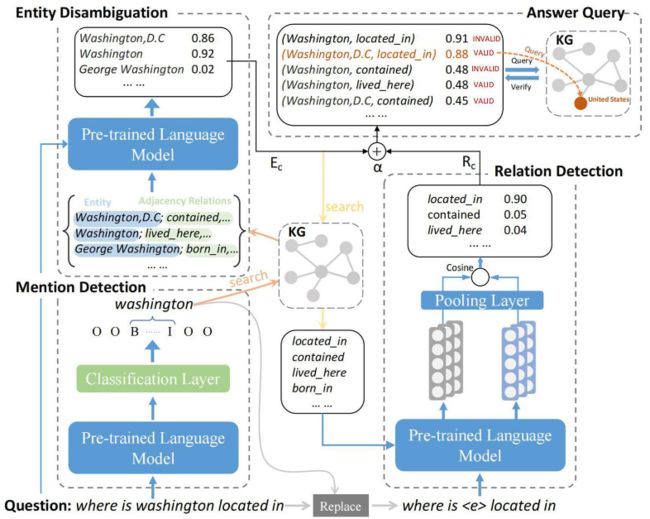
图 2 基于检索排序的知识图谱问答框架
实验
本研究中实现了18个KGQA系统(9个预训练语言模型 * 2个基本KGQA框架)进行评估。采用了9个预训练语言模型,分为3个类别,包括大规模预训练语言模型Bert、RoBERTa、XLNet和GPT2,轻量级预训练语言模型Albert、DistilBERT和DistilRoBERTa,以及知识增强预训练语言模型Luke和KEPLER。由于常用的模型是轻量级预训练语言模型和知识增强预训练语言模型的骨架,本文根据预训练任务类别进一步对常用预训练语言模型进行分类,即Masked Language Modeling(MLM,Bert和Roberta)、Language Modeling(LM,即GPT2)和Permuted Language Modeling(PeLM,XLnet)。
KGQA的准确性实验及结果讨论:下表总结了所有研究的基于plms的KGQA框架和基准的准确性性能。

KGQA系统效率实验:下表总结了所有研究过的基于PLM的KGQA框架和基准的效率表现。我们为所有KGQA系统设置了相同的patience,以便每个模型都被训练得收敛。由于不同PLM的收敛速度不同,PLM的训练时间的变化与测试时间的变化不一致。

ChatGPT在零样本KGQA任务实验:我们对SimpleQuestions、WebQuestionSP和FreebaseQA上的300个抽样问题进行了实验,比较了ChatGPT和其他PLMs的性能。请注意,ChatGPT是在零样本KGQA设置下,而其他PLM是使用性能更好的框架框架与其他PLM中的训练集进行微调的。ChatGPT的输入包括指令(“请根据上下文回答给定的问题。答案应该是事实性的答案和问题。在读取整个输入后,模型以一段文本的形式生成答案。对于每个问题,ChatGPT生成的答案都由两位专业人士根据答案进行评估和交叉验证。实验结果如下。
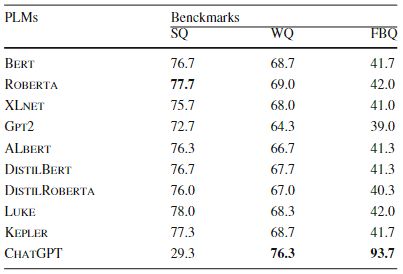
图 3 ChatGPT对比实验结果
总结
由于PLMs在大多数NLP任务上性能的提高,使用PLMs作为解决NLP任务的框架已经成为共识。在本文中,我们研究了PLMs在解决知识密集型任务,即知识图问答中的应用。我们进行了全面的实验,以探索PLMs在KGQA上的准确性和效率性能,以及随着KG大小的增加,PLMs的可扩展性。此外,我们比较了ChatGPT和其他PLMs在三个KGQA数据集上的性能。我们对这些实验结果进行了详细的分析,并得出了关于在KGQA中使用PLMs的一些重要结论。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。