Pytorch并行计算(二): DistributedDataParallel介绍
PyTorch并行计算: DistributedDataParallel
- 一、为什么要并行计算?
- 二、基本概念
- 三、DistributedDataParallel的使用
-
- 1. torch.distributed
- 2. torch.multiprocessing
- 四、一些BUG和问题
这部分是nn.DataParallel的后续,想看DataParallel的点击这里
为什么要用DistributedDataParallel呢,首先我们看PyTorch官网对nn.DataParallel的一段话
WARNING
It is recommended to use DistributedDataParallel, instead of this class, to do multi-GPU training, even if there is only a single node. See: Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel and Distributed Data Parallel.
这段话的意思是说即使在单机多卡中也建议使用DistributedDataParallel,这就不得不说二者的区别
- nn.DataParallel:只能用于单机多卡的情况,且不能使用apex加速
- nn.parallel.DistributedDataParallel:既可以用于单机多卡也可以用于多机多卡的情况,可以使用apex加速(apex是由Nvidia维护的一个支持混合精度分布式训练的PyTorch扩展,不仅能加速收敛,还能节省显存,但由于本文是介绍并行计算,所以这里不作过多的apex介绍)
一、为什么要并行计算?
在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进行训练,最后汇总计算。而右图中是将数据放在不同GPU上进行训练,最后汇总计算,不仅能增大BatchSize,还能加快计算速度,提高计算精度

二、基本概念
在使用DistributedDataParallel时有一些概率必须掌握
| 多机多卡 | 含义 |
|---|---|
| world_size | 代表有几台机器,可以理解为几台服务器 |
| rank | 第几台机器,即第几个服务器 |
| local_rank | 某台机器中的第几块GPU |
| 单机多卡 | 含义 |
|---|---|
| world_size | 代表机器一共有几块GPU |
| rank | 第几块GPU |
| local_rank | 第几块GPU,与rank相同 |
三、DistributedDataParallel的使用
分布式训练的启动有两种方法,一种是torch.multiprocessing,还有一种是torch.distributed
这两种的区别是第一种在启动程序时不需要在命令行输入额外的参数,写起来也比较容易,但是调试较麻烦,kaiming大佬的代码一般用这个,比如MAE;第二种必须要用命令行启动,写起来略微复杂,但是调试较方便,一般来说我都用第二种,所以这里详细介绍第二种,第一种在最后我会提到
1. torch.distributed
分布式的训练并不复杂,这里仅展示与单卡训练不同的地方
第一步,导入必要的模块,其中distributed中必须导入的是以下模块
import torch.distributed as dist
第二步,需要用argparse写自己的一些参数。注意这里如果使用了argparse方法的话,必须传入local_rank参数,系统会自动给他进行赋值,如果不传入会报错!
parser = argparse.ArgumentParser()
''' ...your params '''
''' ...distributed params'''
# 开启的进程数,不用设置该参数,会根据nproc_per_node自动设置
parser.add_argument('--world-size', default=4, type=int, help='number of distributed processes')
parser.add_argument('--local_rank', type=int, help='rank of distributed processes')
opt = parser.parse_args()
第三步,初始化distributed,下面代码是具体的初始化过程,其中有一个dist.barrier()函数,这个函数在文末有详细说明,这里简单理解为:假设我们的world_size=8,那么我们有8张GPU初始化,初始化有快有慢,快的GPU初始化会在dist.barrier()处停下来等待,当所有的GPU都到达这个函数时,才会继续运行之后的代码
# 初始化各进程环境
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
else:
print('Not using distributed mode')
return
# 设置当前程序使用的GPU。根据python的机制,在单卡训练时本质上程序只使用一个CPU核心,而DataParallel
# 不管用了几张GPU,依然只用一个CPU核心,在分布式训练中,每一张卡分别对应一个CPU核心,即几个GPU几个CPU核心
torch.cuda.set_device(args.gpu)
# 分布式初始化
args.dist_url = 'env://' # 设置url
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
print('| distributed init (rank {}): {}'.format(args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url, world_size=args.world_size, rank=args.rank)
dist.barrier() # 等待所有进程都初始化完毕,即所有GPU都要运行到这一步以后在继续
'''
| distributed init (rank 1): env://
| distributed init (rank 2): env://
| distributed init (rank 0): env://
| distributed init (rank 3): env://
'''
真正意义上来讲,分布式的初始化就只有dist.init_process_group这一句。从上面我们print的输出可以得到不同GPUs初始化的速度是不同的,这也正是因为每个GPU都分配了一个CPU核心,他们的速度有快有慢,比如本次实验初始化顺序为1,2,0,3
关于环境变量,有一下几点需要注意
- local_rank是被自动赋值的,在单机多卡中他和rank的值相同
- os.environ[“RANK”]是没有值的,运行时在命令行上输入python -m torch.distributed.launch --nproc_per_node=4 --use_env train.py他才被赋予了值
- –nproc_per_node=4这条指令可以将os.environ[“WORLD_SIZE”]赋值为4
- 之前我们说过,如果用argparse这个库,就必须加上local_rank变量,如果忘记加了,在命令行启动时就需要加上–use_env参数,–use_env 表示 Local Rank 用 LOCAL_RANK 这个环境变量传参
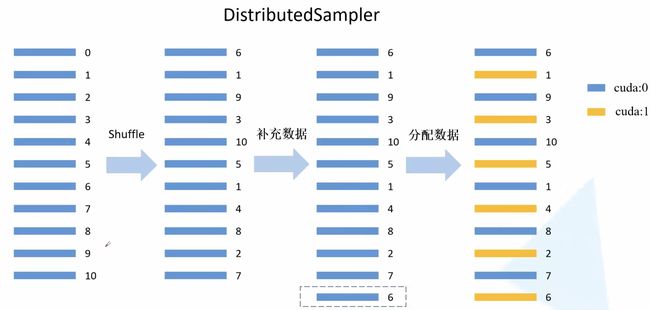
第四步,设置数据集分布式的数据集加载不同于之前的单卡,这里需要将数据集分为N部分,N为卡的数量。单卡时只需要设置Datasets→DataLoader即可,但是分布式中需要对每一块GPU分配不重复的数据,分配方式也不难,分配方式变为:Datasets→DistributedSampler→BatchSampler→DataLoader(BatchSampler可以省略)
DistributedSampler将数据集N等分,BatchSamper将每一等分后的数据内部进行batch的划分。BatchSampler的作用就是分配batchsize,这一步可以再DataLoader中分配,因此也可以将BatchSampler省略。下图展示了数据集的分配过程
 |
 |
# 1. datasets
train_datasets = MyDataSet(xxx)
val_datasets = MyDataSet(xxx)
# 2. DistributedSampler
# 给每个rank对应的进程分配训练的样本索引,比如一共800样本8张卡,那么每张卡对应分配100个样本
train_sampler = torch.utils.data.distributed.DistributedSampler(train_datasets)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_datasets)
# 3. BatchSampler
# 刚才每张卡分了100个样本,假设BatchSize=16,那么能分成100/16=6...4,即多出4个样本
# 下面的drop_last=True表示舍弃这四个样本,False将剩余4个样本为一组(注意最后就不是6个一组了)
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size, drop_last=True)
# 4. DataLoader
# 验证集没有采用batchsampler,因此在dataloader中使用batch_size参数即可
train_dataloader = torch.utils.data.DataLoader(train_datasets,
batch_sampler=train_batch_sampler, pin_memory=True, num_workers=nw)
val_dataloader = torch.utils.data.DataLoader(val_datasets,
batch_size=batch_size, sampler=val_sampler, pin_memory=True, num_workers=nw)
第五步,加载模型到所有GPUs上,在训练时,因为我们用到了DistributedSampler,所以需要每一个epoch都将原数据打乱一下,其他剩下的过程和单卡相同
model = UNet().cuda()
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank])
...
for epoch in range(start_epoch, n_epochs):
if is_distributed:
train_sampler.set_epoch(epoch)
...
第六步,启动
python -m torch.distributed.launch --nproc_per_node=4 --master_port=2424 --use_env main.py (your_argparse_params)
在pytorch新版中将python -m torch.distributed.launch替换为了torchrun,在训练时我们需要指定通讯端口master_port,也可以让程序自动寻找,即将--master_port=xxxx替换为--rdzv_backend c10d --master_port=0
2. torch.multiprocessing
官方的一个示例,方法的核心是spawn函数,这个函数是调用GPU并行的,看一下函数的参数
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')
- fn:这个就是我们要分布式运行的函数,一般来说是main函数,main(rank, *args),其中rank为必须,单机多卡中可以理解为第几个GPU,args为函数传入的参数,类型tuple,在spawn(…args)的args参数中定义
- args:传入fn的参数,tuple
- nprocs:进程数,即几张卡
- join: 默认为True即可
- daemon: 默认为False即可
# 调用
mp.spawn(main, args=(opt, ), nprocs=opt.world_size, join=True)
其实与distributed大同小异,但是我用的较少,就直接给一个完整的训练代码供调试~
# 单机多卡并行计算示例
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6, 7"
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", init_method='tcp://127.0.0.1:6666', rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
print("finished rank: {}".format(rank))
def main():
world_size = torch.cuda.device_count()
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
四、一些BUG和问题
1. runtimeerror: address already in use
这种情况是端口被占用了,可能是由于你上次调试之后端口依旧占用的缘故,假设88889端口被占用了,用以下命令查询其PID,然后杀掉即可。第二种方法是将当前终端关闭,重新开一个他会自动解除占用
lsof -i:88889 # 或者 netstat -tunlp|grep 88889
kill -9 PID
2. 调试时可能会出现以下问题
- 显存未释放:nvidia-smi看一下显存是否释放,如果没有释放使用kill -9 PID命令进行释放。如果kill也无法释放显存,直接将terminal关闭重新开一个即可
- 端口被占用:如果第一次调试后进行第二次调试时提示xx端口被占用了,这里最快的解决方法时将当前terminal关闭,然后重新开一个即可,或者参考第一个问题,kill掉相应的PID
2. 如何理解dist.barrier()函数?
详细参考StackOverflow
单机多卡环境下使用分布式训练具有更快的速度。PyTorch在分布式训练过程中,对于数据的读取是采用主进程预读取并缓存,然后其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现
举个例子(来自StackOverflow)
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
... (loads the model and the vocabulary)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
假设我们有4张卡[0, 1, 2, 3],其中[0]卡是first process或者base process,有些操作不需要所有的卡同时进行,比如在预处理的时候只用base process即可。在上述代码中,第一个if是说除了主卡之外的卡运行到此处会被barrier,也就是说运行到这里就停止了,而base process不会停止会继续运行,执行预加载模型等操作,当主卡运行到第二个if时,他也会进入到barrier,就是说他已经预加载完了,现在他也需要被barrier了。此时所有的卡都进入到了barrier,意味着所有的卡可以继续运行(主卡已经加载完了,这个数据所有的卡都可以使用),可以理解为小弟在等大哥发号施令(小弟都在barrier),当大哥准备好了以后(进入到barrier),就告诉小弟可以出发了(所有的卡从barrier撤出)
a process is blocked by a barrier until all processes have encountered a barrier, upon which the barrier is lifted for all processes