美团接口自动化测试实践
一、概述
1.1 接口自动化概述
众所周知,接口自动化测试有着如下特点:
- 低投入,高产出。
- 比较容易实现自动化。
- 和UI自动化测试相比更加稳定。
如何做好一个接口自动化测试项目呢?
我认为,一个“好的”自动化测试项目,需要从**“时间”、“人力”、“收益”**这三个方面出发,做好“取舍”。
不能由于被测系统发生一些变更,就导致花费了几个小时的自动化脚本无法执行。同时,我们需要看到“收益”,不能为了总想看到100%的成功,而少做或者不做校验,但是校验多了维护成本一定会增多,可能每天都需要进行大量的维护。
所以做好这三个方面的平衡并不容易,经常能看到做自动化的同学,做到最后就本末倒置了。
1.2 提高ROI
想要提高ROI(Return On Investment,投资回报率),我们必须从两方面入手:
- 减少投入成本。
- 增加使用率。
针对“减少投入成本”
我们需要做到:
- **减少工具开发的成本。**尽可能的减少开发工具的时间、工具维护的时间,尽可能使用公司已有的,或是业界成熟的工具或组件。
- **减少用例录入成本。**简化测试用例录入的成本,尽可能多的提示,如果可以,开发一些批量生成测试用例的工具。
- **减少用例维护成本。**减少用例维护成本,尽量只用在页面上做简单的输入即可完成维护动作,而不是进行大量的代码操作。
- **减少用例优化成本。**当团队做用例优化时,可以通过一些统计数据,进行有针对性、有目的性的用例优化。
针对“增加使用率”
我们需要做到:
- **手工也能用。**不只是进行接口自动化测试,也可以完全用在手工测试上。
- **人人能用。**每一个需要使用测试的人,包括一些非技术人员都可以使用。
- **当工具用。**将一些接口用例当成工具使用,比如“生成订单”工具,“查找表单数据”工具。
- **每天测试。**进行每日构建测试。
- **开发的在构建之后也能触发测试。**开发将被测系统构建后,能自动触发接口自动化测试脚本,进行测试。
所以,我这边开发了Lego接口测试平台,来实现我对自动测试想法的一些实践。先简单浏览一下网站,了解一下大概是个什么样的工具。
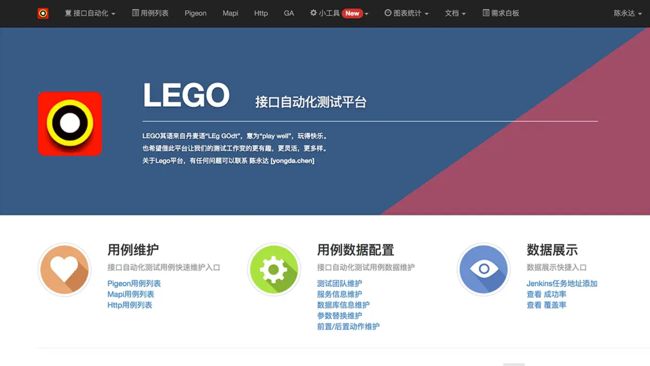
首页
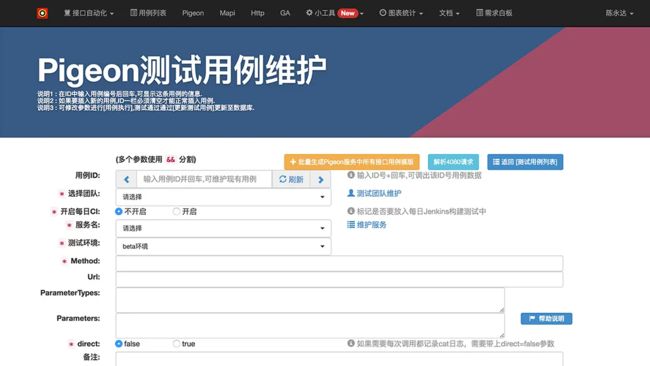
用例维护页面
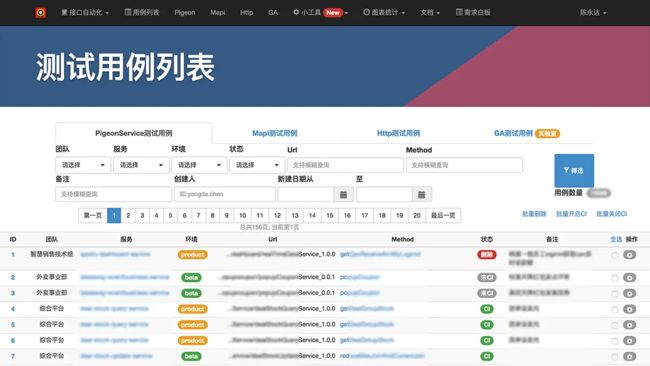
自动化用例列表
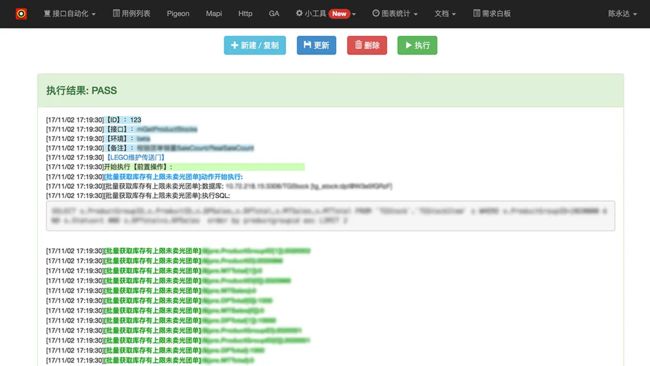
在线执行结果
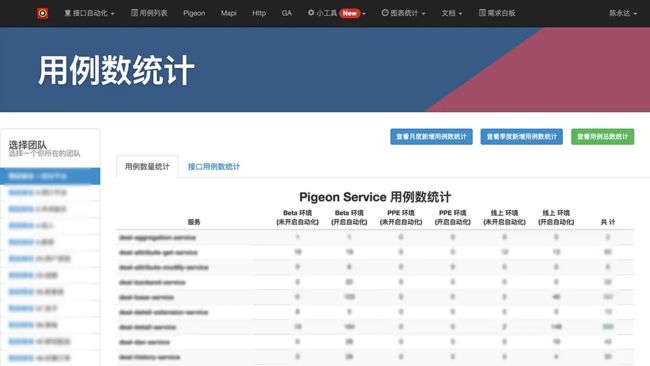
用例数量统计
1.3 Lego的组成
Lego接口测试解决方案是由两部分组成的,一个就是刚刚看到的“网站”,另一个部分就是“脚本”。
下面就开始进行“脚本设计”部分的介绍。
二、脚本设计
2.1 Lego的做法
Lego接口自动化测试脚本部分,使用很常见的Jenkins+TestNG的结构。
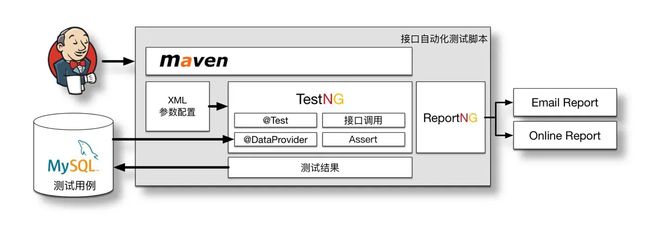
Jenkins+TestNG的结构
相信看到这样的模型并不陌生,因为很多的测试都是这样的组成方式。
将自动化测试用例存储至MySQL数据库中,做成比较常见的**“数据驱动”**做法。
很多团队也是使用这样的结构来进行接口自动化,沿用的话,那在以后的“推广”中,学习和迁移成本低都会比较低。
2.2 测试脚本
首先来简单看一下目前的脚本代码:
public class TestPigeon {
String sql;
int team_id = -1;
@Parameters({"sql", "team_id"})
@BeforeClass()
public void beforeClass(String sql, int team_id) {
this.sql = sql;
this.team_id = team_id;
ResultRecorder.cleanInfo();
}
/**
* XML中的SQL决定了执行什么用例, 执行多少条用例, SQL的搜索结果为需要测试的测试用例
*/
@DataProvider(name = "testData")
private Iterator getData() throws SQLException, ClassNotFoundException {
return new DataProvider_forDB(TestConfig.DB_IP, TestConfig.DB_PORT,
TestConfig.DB_BASE_NAME,TestConfig.DB_USERNAME, TestConfig.DB_PASSWORD, sql);
}
@Test(dataProvider = "testData")
public void test(Map data) {
new ExecPigeonTest().execTestCase(data, false);
}
@AfterMethod
public void afterMethod(ITestResult result, Object[] objs) {...}
@AfterClass
public void consoleLog() {...}
}
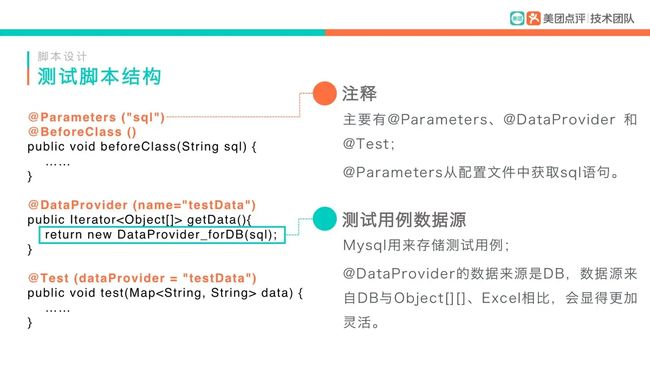
测试脚本结构
有一种做法我一直不提倡,就是把测试用例直接写在Java文件中。这样做会带来很多问题:修改测试用例需要改动大量的代码;代码也不便于交接给其他同学,因为每个人都有自己的编码风格和用例设计风格,这样交接,最后都会变成由下一个同学全部推翻重写一遍;如果测试平台更换,无法做用例数据的迁移,只能手动的一条条重新输入。
所以“测试数据”与“脚本”分离是非常有必要的。
网上很多的范例是使用的Excel进行的数据驱动,我这里为什么改用MySQL而不使用Excel了呢?
在公司,我们的脚本和代码都是提交至公司的Git代码仓库,如果使用Excel……很显然不方便日常经常修改测试用例的情况。使用MySQL数据库就没有这样的烦恼了,由于数据与脚本的分离,只需对数据进行修改即可,脚本每次会在数据库中读取最新的用例数据进行测试。同时,还可以防止一些操作代码时的误操作。
这里再附上一段我自己写的DataProvider_forDB方法,方便其他同学使用在自己的脚本上:
import java.sql.*;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
/**
* 数据源 数据库
*
* @author yongda.chen
*/
public class DataProvider_forDB implements Iterator {
ResultSet rs;
ResultSetMetaData rd;
public DataProvider_forDB(String ip, String port, String baseName,
String userName, String password, String sql) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
String url = String.format("jdbc:mysql://%s:%s/%s", ip, port, baseName);
Connection conn = DriverManager.getConnection(url, userName, password);
Statement createStatement = conn.createStatement();
rs = createStatement.executeQuery(sql);
rd = rs.getMetaData();
}
@Override
public boolean hasNext() {
boolean flag = false;
try {
flag = rs.next();
} catch (SQLException e) {
e.printStackTrace();
}
return flag;
}
@Override
public Object[] next() {
Map data = new HashMap();
try {
for (int i = 1; i <= rd.getColumnCount(); i++) {
data.put(rd.getColumnName(i), rs.getString(i));
}
} catch (SQLException e) {
e.printStackTrace();
}
Object r[] = new Object[1];
r[0] = data;
return r;
}
@Override
public void remove() {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
2.3 配置文件
上面图中提到了“配置文件”,下面就来简单看一下这个XML配置文件的脚本:

对照上图来解释一下配置文件:
- SQL的话,这里的SQL主要决定了选取哪些测试用例进行测试。
- 一个标签,就代表一组测试,可以写多个标签。
- “listener”是为了最后能够生成一个ReportNG的报告。
- Jenkins来实现每日构建,可以使用Maven插件,通过命令来选择需要执行的XML配置。
这样做有什么好处呢?
使用SQL最大的好处就是灵活
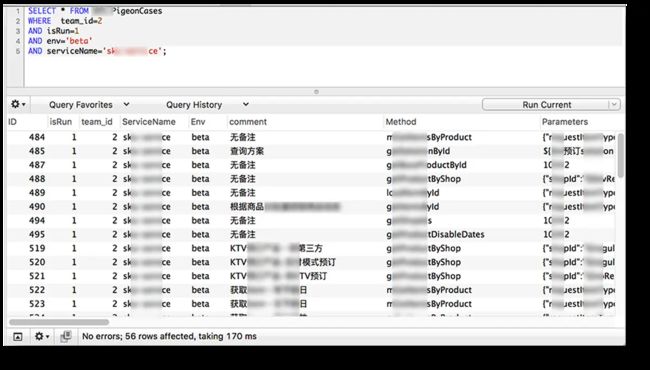
如上面的这个例子,在数据库中会查询出下面这56条测试用例,那么这个标签就会对这56条用例进行逐一测试。
多
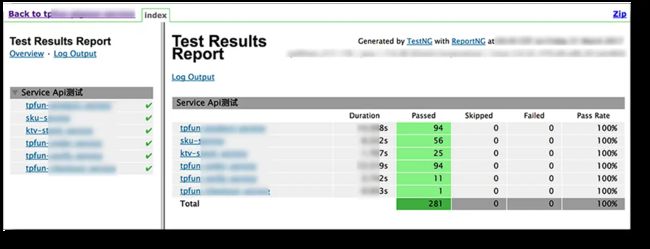
使用多个
报告更美观丰富
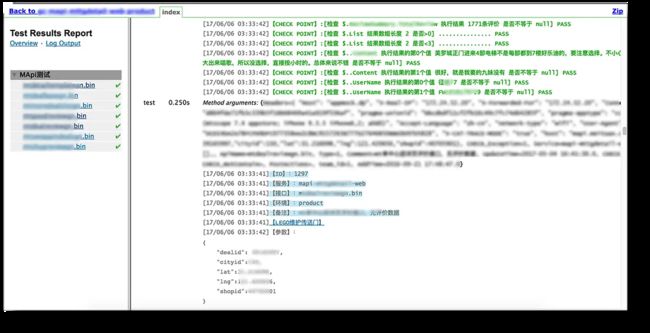
由于使用了ReportNG进行报告的打印,所以报告的展示要比TestNG自带的报告要更加美观、并且能自定义展示样式,点开能看到详细的执行过程。
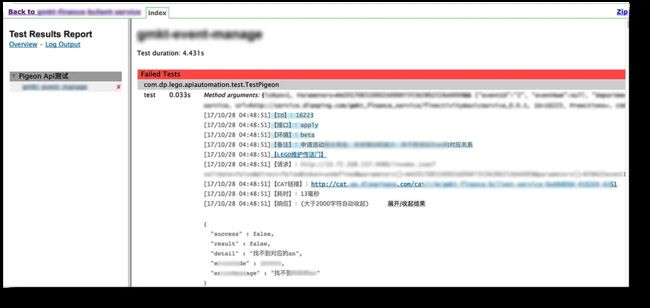
如果有执行失败的用例,通常报错的用例会在最上方优先展示。
支持多团队
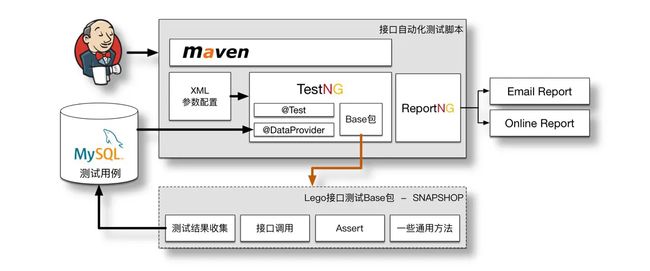
当两个团队开始使用时,为了方便维护,将基础部分抽出,各个团队的脚本都依赖这个Base包,并且将Base包版本置为“SNAPSHOT版本”。使用“SNAPSHOT版本”的好处是,之后我对Lego更新,各个业务组并不需要对脚本做任何改动就能及时更新。
当更多的团队开始使用后,比较直观的看的话是这个样子的:
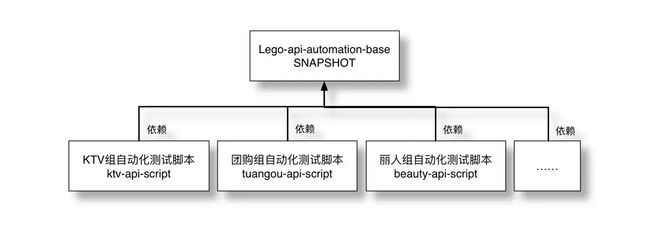
每个团队的脚本都依赖于我的这个Base包,所以最后,各个业务团队的脚本就变成了下面的这个样子:
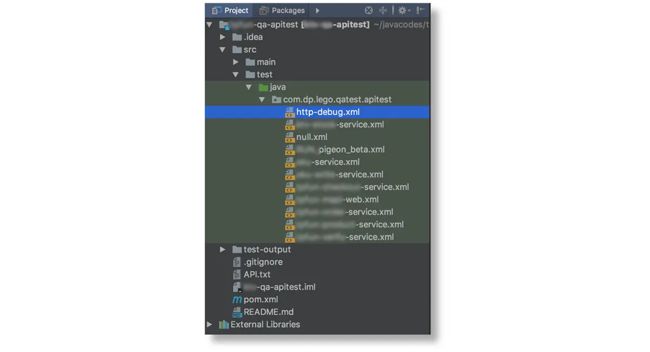
可以看到,使用了Lego之后:
- 没有了Java文件,只有XML文件
- xml中只需要配置SQL。
- 执行和调试也很方便。
- 可以右键直接执行想要执行的测试配置。
- 可以使用maven命令执行测试:
mvn clean test -U -Dxml=xmlFileName。- 通过参数来选择需要执行的xml文件。
- 也可以使用Jenkins来实现定时构建测试。
由于,所有测试用例都在数据库所以这段脚本基本不需要改动了,减少了大量的脚本代码量。
有些同学要问,有时候编写一条接口测试用例不只是请求一下接口就行,可能还需要写一些数据库操作啊,一些参数可能还得自己写一些方法才能获取到啊之类的,那不code怎么处理呢?
下面就进入“用例设计”,我将介绍我如何通过统一的用例模板来解决这些问题。
三、用例设计
3.1 一些思考
我在做接口自动化设计的时候,会思考通用、校验、健壮、易用这几点。
通用
- 简单、方便
- 用例数据与脚本分离,简单、方便。
- 免去上传脚本的动作,能避免很多不必要的错误和维护时间。
- 便于维护。
- 模板化
- 抽象出通用的模板,可快速拓展。
- 数据结构一致,便于批量操作。
- 专人维护、减少多团队间的重复开发工作。
- 由于使用了统一的模板,那各组之间便可交流、学习、做有效的对比分析。
- 如果以后这个平台不再使用,或者有更好的平台,可快速迁移。
- 可统计、可拓展
- 可统计、可开发工具;如:用例数统计,某服务下有多少条用例等。
- 可开发用例维护工具。
- 可开发批量生成工具。
校验
在写自动化脚本的时候,都会想“细致”,然后“写很多”的检查点;但当“校验点”多的时候,又会因为很多原因造成执行失败。所以我们的设计,需要在保证充足的检查点的情况下,还要尽可能减少误报。
- 充足的检查点
- 可以检查出被测服务更多的缺陷。
- 尽量少的误报
- 可以减少很多的人工检查和维护的时间人力成本。
- 还要
- 简单、易读。
- 最好使用一些公式就能实现自己想要的验证。
- 通用、灵活、多样。
- 甚至可以用在其他项目的检查上,减少学习成本。
健壮
执行测试的过程中,难免会报失败,执行失败可能的原因有很多,简单分为4类:
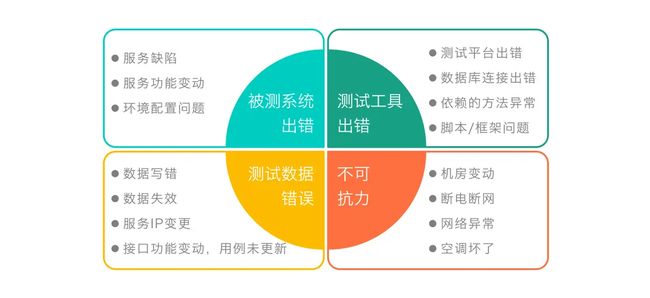
- 被测系统出错,这部分其实是我们希望看到的,因为这说明我们的自动化测试真正地发现了一个Bug,用例发挥了它的价值,所以,这是我们希望看到的。
- 测试工具出错,这部分其实是我们不希望看到的,因为很大可能我们今天的自动化相当于白跑了。
- 测试数据错误,这是我们要避免的,既然数据容易失效,那我在设计测试平台的时候,就需要考虑如果将所有的数据跑“活”,而不是只写“死”。
- 不可抗力,这部分是我们也很无奈的,但是这样的情况很少发生。
那针对上面的情况:
- 参数数据失效
- 支持实时去数据库查询。
- 支持批量查。
- IP进场发生变更
- 自动更新IP。
- 灵活、可复用
- 支持批量维护。
- 接口测试执行前生成一些数据。
- 接口执行完成后销毁一些数据。
- 支持参数使用另一条测试用例的返回结果。
- 支持一些请求参数实时生成,如token等数据,从而减少数据失效的问题。
通过这些手段,提高测试用例的健壮性,让每一条自动化测试用例都能很好的完成测试任务,真正发挥出一条测试用例的价值。
易用
- 简单
- 功能强大,但要人人会用。
- 非技术人员也要会用。
- 减少代码操作
- 让自动化开发人员注意力能更多的放在用例本身,而不是浪费在无关紧要的开发工作上面。
- 还要
- 配置能复用。
- 通用、易学。
- 一些数据能自动生成。
3.2 Lego接口自动化测试用例
说了这么多,那我们来看一下一条Lego接口测试用例的样子。
一条Lego自动用例执行顺序大概是如下图这样:
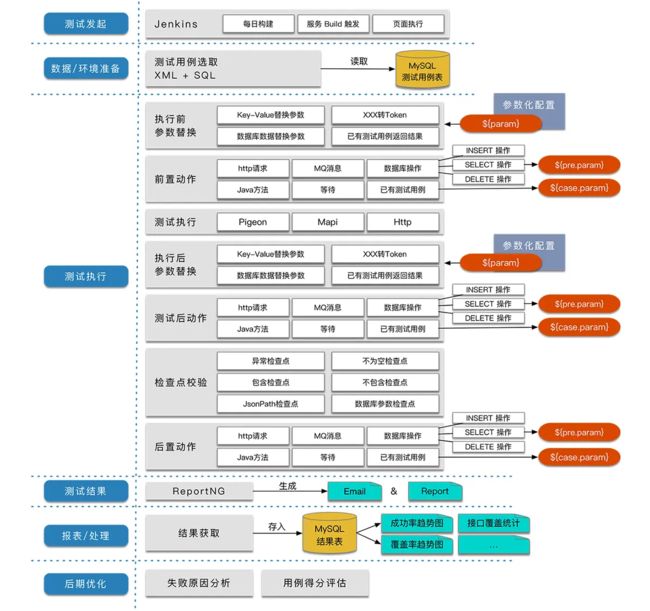
简单区分一下各个部分,可以看到:
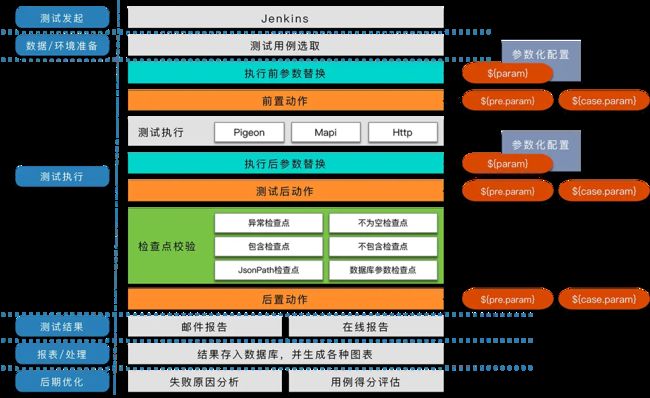
那上面图中提到了两个名词:
- “参数化”
- “前后置动作”
下面会先对这两个名词做一个简单的介绍。
3.3 参数化
比如一个请求需要用到的参数。
{
"sync": false,
"cityId": 1,
"source": 0,
"userId": 1234,
"productId": 00004321
}
这个例子中有个参数"productId": 00004321,而由于测试的环境中,表单00004321很可能一些状态已经发生了改变,甚至表单已经删除,导致接口请求的失败,那么这时候,就很适合对"productId": 00004321进行参数化,比如写成这样:
{
"sync": false,
"cityId": 1,
"source": 0,
"userId": 1234,
"productId": ${myProductId}
}
所以对**“参数化”**简单的理解就是:
通过一些操作,将一个“值”替换掉测试用例里的一个“替代字符”
${myProductId} 的值可以通过配置获取到:
- Key-Value
- 配置 Value=00004321。
- SQL获取
- 执行一个select语句来实时查询得到可用ID。
- 已有测试用例
- 某个接口接口测试用例的返回结果。
“参数化”实例
下面我们来看一个“参数化”的实例:
(1) 首先我们在参数化维护页面中新建一个参数化,shopdealid。

通过配置我们可以看到这个参数的值,是执行了一条SQL后,取用执行结果中DealID字段的值。
(2) 在用例中,将需要这个表单号的地方用${shopdealid}替代。
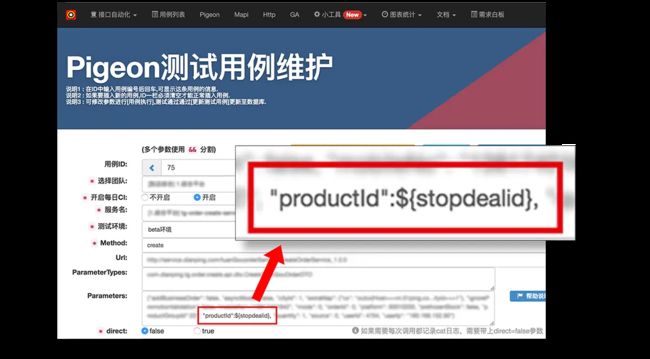
那在编写测试用例的时候,大家可以看一下这个放大的图片,在这里的ProductID的值并不是硬代码一个固定的表单号,而是选择了刚才配置的参数化数据。
(3) 执行结果中,${shopdealid} 变为实时查询数据库的来的一个真实的表单号。
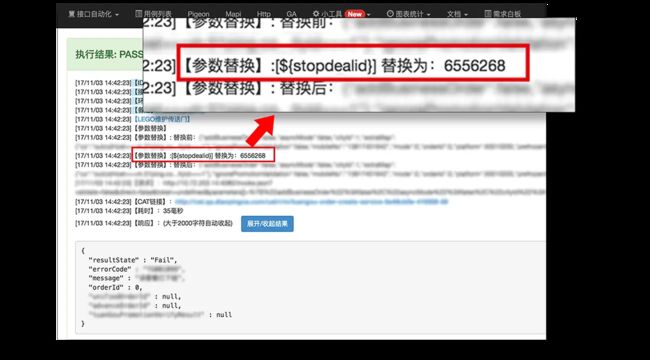
从结果中可以看到,我们的这个参数被替换成了一个有效的值,而这个值就是我们刚刚配置的那个SQL实时查询而来的。
“参数化”的场景
多个测试用例使用同一个参数进行测试
如50条测试用例都使用同一个id作为参数进行测试,这时候我们需要变更这个id。
无参数化时:
- 需要修改50次,即每条测试用例中的id都得进行修改。
- 可能会有遗漏。 有参数化时:
- ID部分用 ${myID} 替代。
- 需要修改的话,在“参数化维护”页面中维护 m y I D 这条数据就可以。修改一次,所有使用 {myID}这条数据就可以。修改一次,所有使用 myID这条数据就可以。修改一次,所有使用{myID}的用例都配置完成。
测试数据过期导致测试用例执行失败
如一条用例参数需要传入Token,但是Token会因为时间问题而导致过期,这时候用例就失败了。
无参数化时:
- 经常修改Token,或是写一段ID转Token的代码。
- 方法可能会重复编写。
- 多个团队之间可能实现方式也不同。
有参数化时:
- 使用参数化工具,Lego统一管理。
- 维护一个参数化 如:
${测试用Token} = id:123。
数据库获取有效测试数据
参数中需要传入DealId作为参数,写死参数的话,如果这个DealId被修改引起失效,那这条测试用例就会执行失败。
不使用Lego时:
- 测试环境中,一个订单时常会因为测试需要被修改数据,导致单号失效,最后导致自动化失败。
- 编写相关代码来做好数据准备工作。
- 在代码中编写读取数据库的方法获取某些内容。
在Lego上的方案: - 使用参数化,实时获取sql结果,查询出一条符合条件的dealId来实现。 - 使用参数化,调用写好的“生成订单”接口用例实现,拿单号来实现。 - 前后置动作,插入一条满足条件的数据。
3.4 前后置动作
“前后置动作”的概念就比较好理解了:
在接口请求之前(或之后),执行一些操作
目前前后置动作支持6种类型:
- 数据库SQL执行
- 有时候在执行接口请求前,为了保证数据可用,可能需要在数据库中插入或删除一条信息,这时候就可以使用前后置动作里的“执行SQL语句”类型,来编写在接口请求前(后)的 Insert 和 Delete 语句。
- 已有测试用例执行
- 比如当前测试用例的请求参数,需要使用另一条测试用例的返回结果,这时候就可以使用“执行测试用例”类型,写上Lego上某条测试用例的ID编号,就可以在当前用例接口请求前(后)执行这条测试用例。
- 前后置动作中测试用例的返回结果可以用于当前用例的参数,对测试用例返回结果内容的获取上,也支持JsonPath和正则表达式两种方式。
- MQ消息发送
- 在接口请求前(后)发送MQ消息。
- HTTP请求
- 等待时间
- 自定义的Java方法
- 如果上面的方法还满足不了需求,还可以根据自己的需要,编写自己的Java方法。
- 可以在Lego-Kit项目中,编写自己需要的Java方法,选择“执行Java方法”,通过反射实现自定义Java方法的执行。
这里的SQL同时支持Select操作,这里其实也是做了一些小的设计,会将查询出来的全部的结果,放入到这个全局Map中。
比如查询一条SQL得到下表中的结果:
| id | name | age | number |
|---|---|---|---|
| 0 | 张三 | 18 | 1122 |
| 1 | 李四 | 30 | 3344 |
那我们可以使用下面左边的表达式,得到对应的结果:
${pre.name}—- 得到 “张三”å${pre.age}—- 得到 18${pre.number}—- 得到 1122
也可以用:
${pre.name[0]}—- 得到 “张三”${pre.age[0]}—- 得到 18${pre.number[0]}—- 得到 1122${pre.name[1]}—- 得到 “李四”${pre.age[1]}—- 得到 30${pre.number[1]}—- 得到 3344
这样的设计,更加帮助在用例设计时,提供数据准备的操作。
“前后置动作”实例
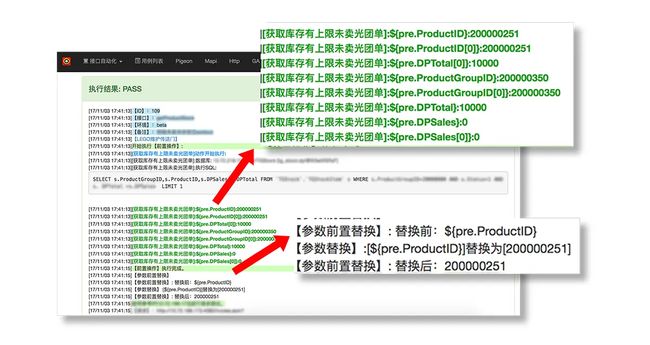
(1) 首先我们在前后置维护页面中新建一个动作,获取库存上限未卖光团单 。

这个配置也是可以支持在线调试的,在调试中,可以看到可以使用的参数化:
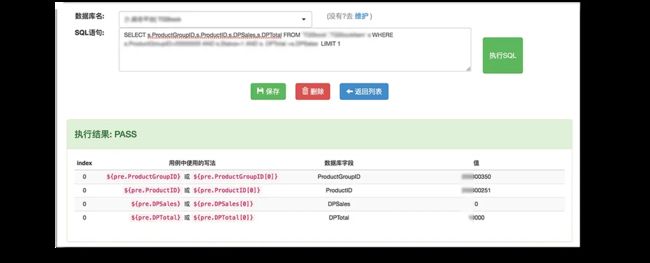
(2) 在测试用例中的前置动作,添加获取库存上限未卖光团单 。

这样就可以在整个测试用例中,使用${pre.ProductID},来替换掉原有的数据信息。
(3) 最后请求接口,返回了执行成功 。
Q & A
Q:那如果同样是获取三个参数,使用3个“参数化的Select操作”和使用1个“前置动作的Select操作”又有什么不同呢?
A: 不同在于执行时间上。 比如,我们查询最新的有效团单的“单号”“下单人”和“手机号”三个字段。 使用3个“参数化的Select操作”:可能当执行 单号的时候得到的订单号是“ 10001 ”,但是当执行到 {单号}的时候得到的订单号是“10001”,但是当执行到 单号的时候得到的订单号是“10001”,但是当执行到{下单人}的时候,可能有谁又下了一单,可能取到的下单人变成了“10002”的“李四”而不是“10001”的“张三”了,最后可能“单号”“下单人”和“手机号”三个字段去的数据并非同一行的数据。 而使用“前置动作的Select操作”:就可以避免上面的问题,因为所有字段的数据是一次性查询出来的,就不会出现错位的情况。
Q : 那“参数化的Select操作”和“前置动作的Select操作”这样不同的取值时机又有什么好用之处呢?
A : 由于“前置动作”一定是接口请求前执行,“参数化”一定是用到的时候才执行这样的特性。 所以在检查点中,如果要验证一个数据库字段在经过接口调用后发生了变更,那使用“前置动作”和“参数化”同时去查询这个字段,然后进行比较,不一致就说明发生了变化。 所以根据使用场景,选择合适的参数化方式,很重要,选择对了,能大大提升测试用例的测试数据健壮性。
3.5 执行各部分
回到一开始的流程图,可以按照一类一类来看执行过程。
测试发起

测试发起基本还是使用的Jenkins,稳定、成熟、简单、公司工具组支持,也支持从Lego的Web页面进行执行操作。
数据 / 环境准备

使用 @DataProvider 的方式,从DB数据库中读取测试用例,逐一执行进行测试。
测试执行
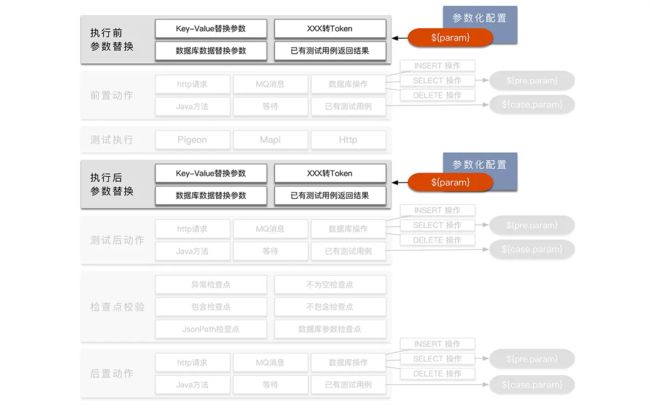
在正式执行测试用例之前,会先进行一波参数替换的动作,在调用接口之后,还会执行一次参数替换动作。
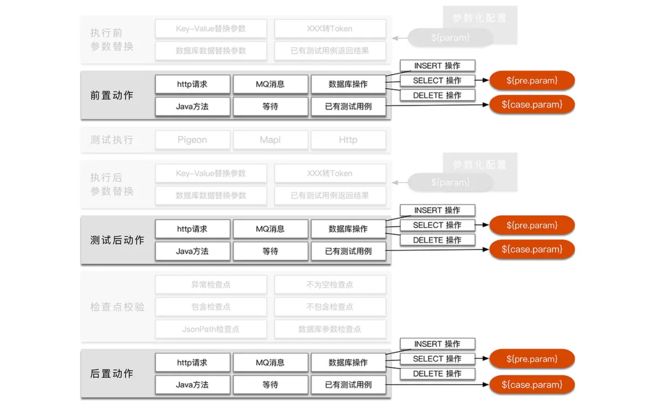
参数替换后会进行前置动作的执行,然后在调用接口之后还会执行测试后动作,最后执行后置动作。
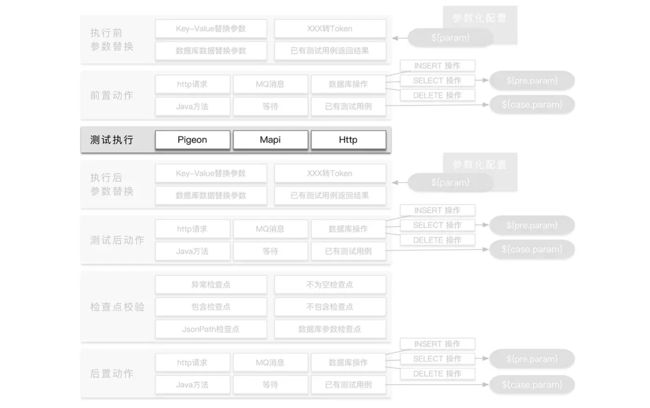
接口请求这部分就没什么好说的了,就是通过接口请求的参数,请求对应的接口,拿到返回结果。
这里的话是为了方便通用,所以要求返回的结果都是使用的String类型。这样做最大的好处就是。比如说我现在有一种新的接口类型需要接入。那只需要写一个方法能够请求到这个接口,并且拿到String类型的返回结果,就可以很快将新的接口类型接入Lego测试平台进行接口测试。
检查点校验
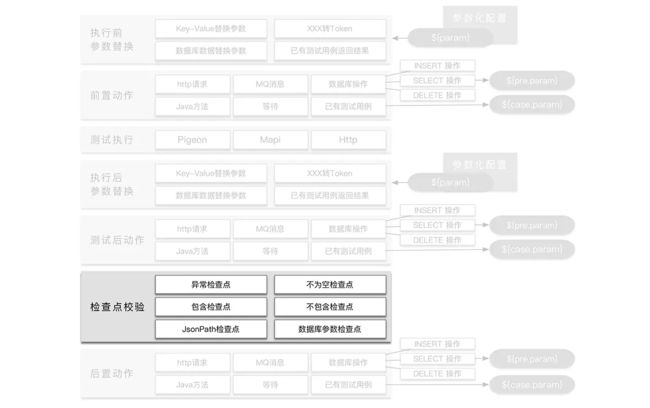
检查点部分是一条自动化测试用例的精髓,一条自动化测试用例是否能真正的发挥它的测试功能,就是看QA对这条测试用例的检查点编写是否做了良好设计。在Lego平台上,目前我拥有的检查点有6种不同的类型。
- 异常检查点
- 当返回结果为异常时,则会报错。
- 但是有时候为了做异常测试,可以将这个检查点关掉。
- 不为空检查点
- 顾名思义,当出现”“、”[]“、”{}“、null 这样的的结果,都会报错。也可以根据自己用例的实际情况关闭。
- 包含检查点
- 不包含检查点
- “包含”和“不包含”检查点是将接口的返回结果作为一个String类型来看,检查所有返回内容中是否“包含”或“不包含”指定的内容。
- 数据库参数检查点
- 顾名思义,不做过多的解释了。
- JsonPath检查点
- 这是我在Lego上设计的最具有特色的一种检查点类型。
JsonPath的基本写法是:{JsonPath语法}==value
JsonPath的语法和XPath的语法差不多,都是根据路径的方法找值。这里也是主要是针对返回结果为JSON数据的结果,进行检查。
说完了**“JsonPath的语法”,现在说一下“JsonPath检查点的语法”,“JsonPath检查点的语法”**是我自己想的,主要针对以下几种数据类型进行校验:
(1) 字符串类型结果检验
- 等于:
== - 不等于:
!== - 包含:
= - 不包含:
!=
例如:
{$.[1].name}==aa:检查返回的JSON中第2个JSON的name字段是否等于aa。{$..type}=='14':检查返回的JSON中每一个JSON的name字段是否等于aa。{$.[1].type}==14 && {$.[1].orderId}==106712:一条用例中多个检查用&&连接。{$..orderId}!==12:检查返回的JSON中每个JSON的orderId字段是否不等于12。{$..type}=1:检查返回的JSON中每个JSON的type字段是否包含1。{$.[1].type}!=chenyongda:检查返回的JSON中第2个JSON的type字段是否不包含chenyongda。
(2) 数值校验
- 等于:
= - 大于:
> - 大于等于:
>= - 小于:
< - 小于等于:
<=
例如:
- {$.[0].value}<5:检查返回的JSON中第1个JSON的value字段的列表是否小于3。
- {$.[1].value}>4:检查返回的JSON中第2个JSON的value字段的列表是否大于4。
(3) List结果检验
- list长度:
.length - list包含:
.contains(param) - list成员:
.get(index)
例如:
{$..value}.length=3:检查返回的JSON中每个JSON的value字段的列表是否等于3。{$.[0].value}.length<5:检查返回的JSON中第1个JSON的value字段的列表是否小于3。{$.[1].value}.length>4:检查返回的JSON中第2个JSON的value字段的列表是否大于4。{$..value}.contains('222'):检查返回的JSON中每个JSON的value字段的列表是否包含222字符串。{$.[0].value}.contains(1426867200000):检查返回的JSON中第1个JSON的value字段的列表是否包含1426867200000。{$.[0].value}.get(0)=='222':检查返回的JSON中第1个JSON的value字段的列表中第1个内容是否等于222。{$..value}.get(2)='22':检查返回的JSON中每个JSON的value字段的列表中第3个内容是否包含22。
(4) 时间类型处理
时间戳转日期时间字符串:.todate
例如:
{$..beginDate}.todate==2015-12-31 23:59:59:检查返回的JSON中beginDate这个时间戳转换成日期后是否等于2015-12-31 23:59:59。
当JsonPath返回的结果是列表的形式时
| 检查点 | 检查点等号左边 | 期望值 | 验证效果 |
|---|---|---|---|
| {$.value}==“good” | [‘good’, ‘good’, ‘bad’, ‘good’] | “good” | 作为4个检查点,会拿列表里的每个对象逐一和“期望值”进行检验,每一次对比都是一个独立的检查点。 |
| {$.value}==[“good”] | [‘good’, ‘good’, ‘bad’, ‘good’] | [“good”] | 作为1个检查点,作为一个整体做全量比对。 |
| {$.value}==[‘a’, ‘b’] | [[‘a’, ‘b’],[‘a’, ‘b’],[‘a’, ‘b’, ‘c’]] | [‘a’, ‘b’] | 作为3个检查点,道理和1一样,列表中的数据分别和期望值做比较。 |
除此之外,还有非常多的花样玩法
JsonPath中的检查支持“参数化”和“前后置动作”,所以会看到很多如:
{KaTeX parse error: Expected 'EOF', got '}' at position 7: .param}̲=‘{param}’ && {KaTeX parse error: Expected 'EOF', got '}' at position 7: .param}̲=={pre.param}
这样的检查点:
“参数化”和“前后置动作”也支持递归配置,这些都是为了能够让接口自动化测试用例写的更加灵活好用。
测试结果
![]()
使用ReportNG可以打印出很漂亮的报告。
报告会自定义一些高亮等展示方式,只需要在ReportNG使用前加上下面的语句,就可以支持“输出逃逸”,可使用HTML标签自定义输出样式。
System.setProperty("org.uncommons.reportng.escape-output", "false");
后期优化

当使用Jenkins执行后,通过Jenkins API 、和Base包中的一些方法,定时获取测试结果,落数据库,提供生成统计图表用。
四、网站功能
4.1 站点开发
既然打算做工具平台了,就得设计方方面面,可惜人手和时间上的不足,只能我一人利用下班时间进行开发。也算是担任了Lego平台的产品、后端开发、前端开发、运维和测试等各种角色。
Jenkins+TestNG+ReportNG+我自己开发的基本接口自动化测试Base jar包,基本上没什么太大难度。但是站点这块,在来美团之前,还真没开发过这样的工具平台,这个算是我的第一个带Web界面的工具。边Google边做,没想到不久还真的架起来了一个简易版本。
使用 Servlet + Jsp 进行开发,前端框架使用Bootstrap,前端数据使用jstl,数据库使用MySQL,服务器使用的公司的一台Beta环境Docker虚拟机,域名是申请的公司内网域名,并开通北京上海两侧内网访问权限。
功能上基本都是要满足的,界面上,虽然做不到惊艳吧,但是绝对不能丑,功能满足,但是长得一副80年代的界面,我自己都会嫌弃去使用它,所以界面上我还是花了一些时间去调整和设计。熟练以后就快多了。
4.2 整体组成
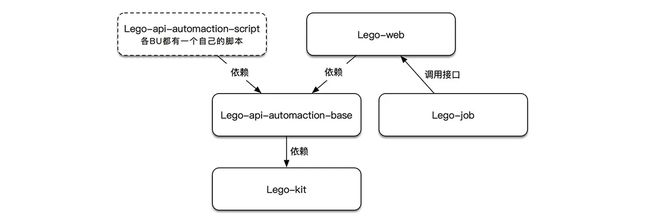
目前Lego由五个不同的项目组成,分别是“测试脚本”、“Lego-web页面项目”、“用于执行接口测试的base包”、“小工具集合Lego-kit”和“lego-job”,通过上图可以看出各项目间的依赖关系。
细化各个项目的功能,就是下图:
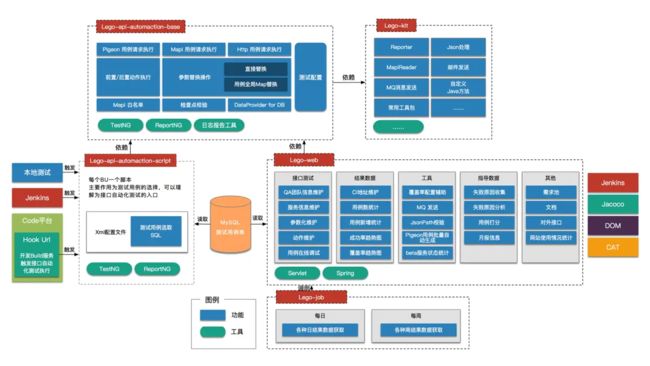
简单来说,网站部分和脚本是分离的,中间的纽带是数据库。所以,没有网站,脚本执行一点问题也没有;同样的,网站的操作,和脚本也没有关系。
4.3 使用-日常维护
Step 1
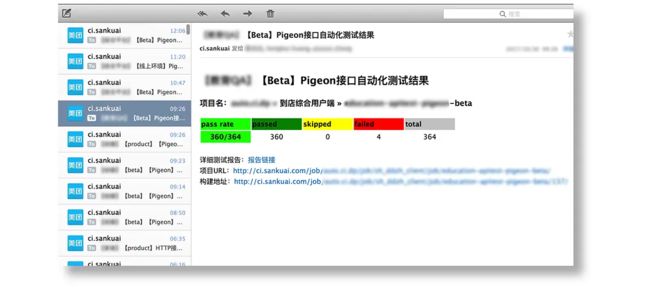
每天上班来会收到这样的测试邮件,通过邮件能知道昨晚执行的情况。如果有报错,可以点击“详细报告链接”,跳转到在线报告。
Step 2
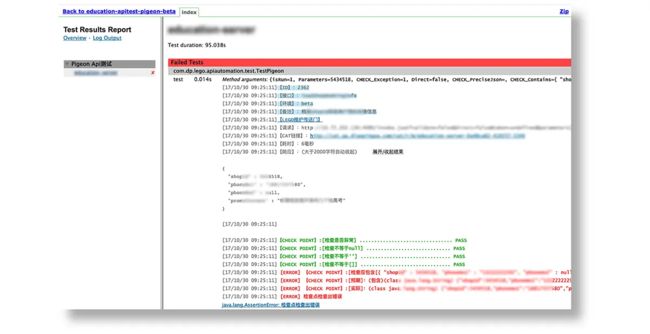
在现报告可以直接看到执行报错的信息,然后点击“LEGO维护传送门”,可以跳转到Lego站点上,进行用例维护。
Step 3
跳转到站点上以后,可以直接展示出该条测试用例的所有信息。定位,维护、保存,维护用例,可以点击“执行”查看维护后的执行结果,维护好后“保存”即可。
仅仅3步,1~2分钟即可完成对一条执行失败的用例进行定位、调试和维护动作。
4.4 用例编辑

通过页面,我们就可以对一条测试用例进行:
- 新建
- 复制
- 编辑
- 删除
- 是否放入每日构建中进行测试
4.5 在线调试
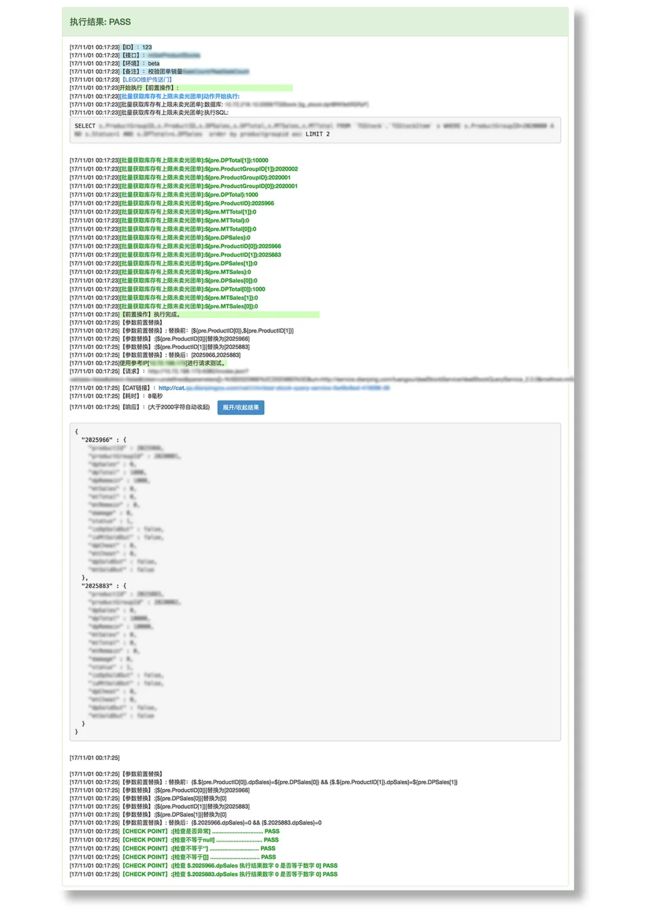
lego-web项目同样的使用base进行的用例执行,所以执行结果和打印都与脚本执行的一致的。
4.6 用例生成工具
为了更方便的写用例,针对部分接口开发了一键批量生成用例的小工具。
4.7 执行结果分析
通过Jenkins接口、Base包中基础Test方法,将结果收集到数据库,便于各组对测试结果进行分析。
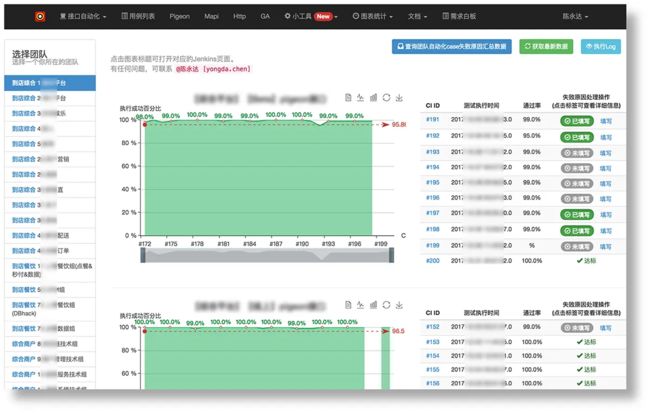
这是每天执行后成功率走势图:

也可以按月进行统计,生成统计的图表,帮助各个团队进行月报数据收集和统计。
4.8 失败原因跟踪
有了能直观看到测试结果的图表,就会想要跟踪失败原因。
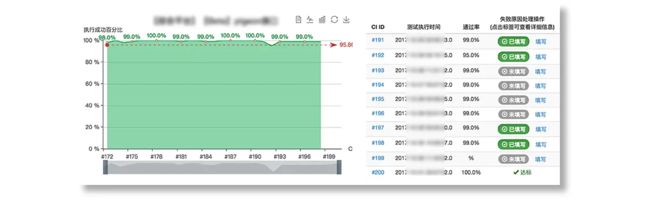
所以在成功率数据的右边,会有这样的跟踪失败原因的入口,也可以很直观地看到哪一些失败的原因还没有被跟踪。点开后可以对失败原因进行记录。
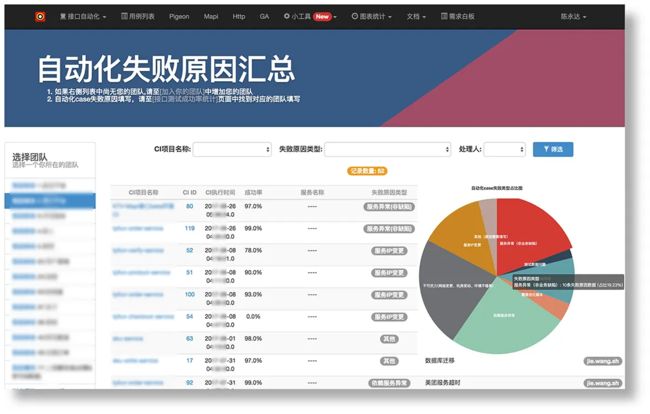
最后会有生成图表,可以很清晰地看到失败原因以及失败类型的占比。
4.9 代码覆盖率分析
结合Jacoco,我们可以对接口自动化的代码覆盖率进行分析。
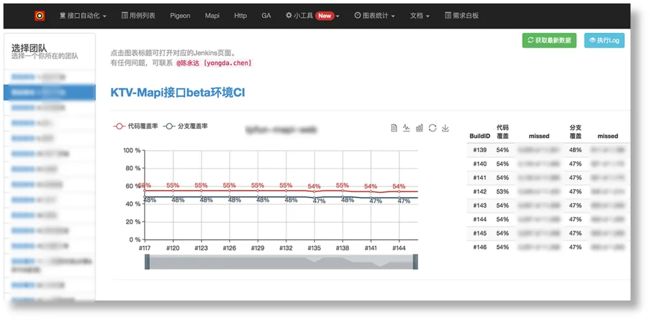
在多台Slave机器上配置Jacoco还是比较复杂的,所以可以开发覆盖率配置辅助工具来帮助测试同学,提高效率。

4.10 用例优化方向
除了上面的图表,还会给用例优化提供方向。
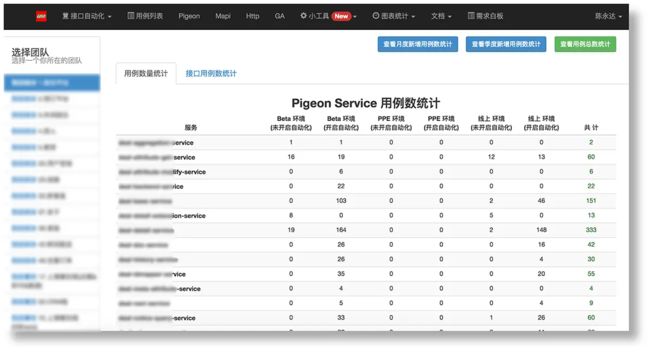
通过用例数量统计的图表,我们可以知道哪些服务用例还比较少,哪些环境的用例还比较少,可以比较有针对性的进行测试用例的补充。
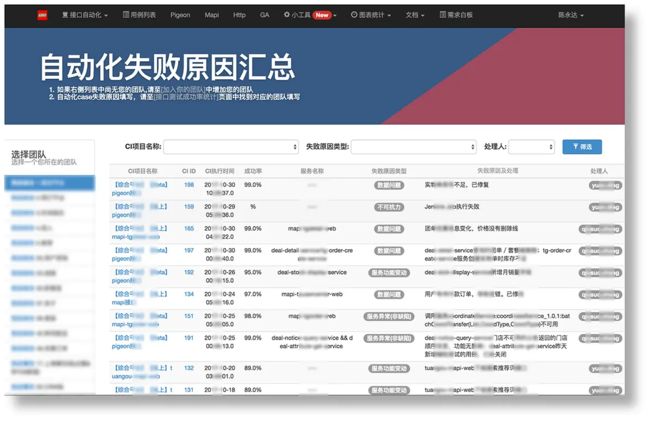
通过失败原因的图表,我们可以改善自己用例中的“参数化”和“前后置动作”的使用,增加测试用例的健壮性。
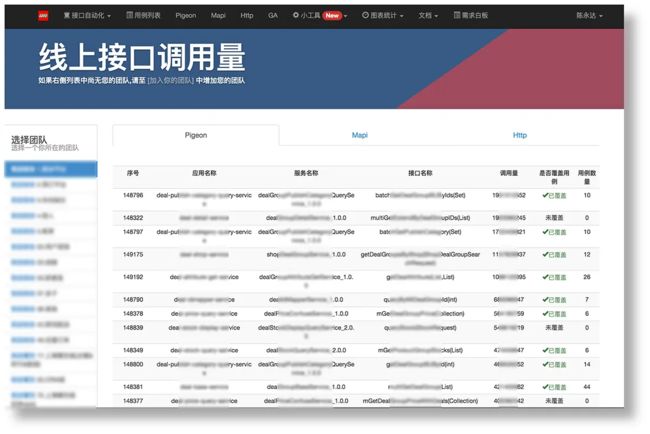
通过线上接口调用量排序的图表。我们可以有效的知道优先维护哪些服务的测试用例,通过表格中,我们可以看到,哪些服务已经覆盖了测试用例,哪些没有被覆盖, 给各组的QA制定用例开发计划,提供参考。

同时在维护接口自动化测试的时候,都会看到用例评分的情况,来协助QA提高用例编写的质量。
4.11 收集反馈/学习
还做了“需求白板”,用来收集使用者的需求和Bug。除此之外,Lego平台已经不只是一个接口测试的平台,还可以让想学习开发的QA领任务,学习一些开发技巧,提高自己的代码能力。
五、总结
- 为了减少开发成本,使用比较常见的Jenkins+TestNG的脚本形式。
- 为了简化code操作,使用DB进行测试用例存储,并抽象出用例摸版。
- 为了减低新建用例成本,开发“用例维护页面”和“一键生成”等工具。
- 为了减低维护成本,加跳转链接,维护一条用例成本在几分钟内。
- 为了增加用例健壮性,设计了“参数化”、“前后置动作”等灵活的参数替换。
- 为了易用和兼容,统一“返回结果”类型,统一“检查点”的使用。
- 为了接口自动化用例设计提供方向,结合Jacoco做代码覆盖率统计,并开发相关配置工具
- 为了便于分析数据,从DOM、CAT、Jenkins上爬各种数据,在页面上用图表展示。
- 为了优化用例,提供“用例打分”、“线上调用量排行”等数据进行辅助。
推荐
年薪百万的测开也得懂的接口测试!你有什么理由可以不学习?:https://www.bilibili.com/video/BV1jp4y1P7KL