YOLOv5、YOLOv8改进:HorNet完全替换backone
1.简介
论文地址:https://arxiv.org/abs/2207.14284
代码地址:https://github.com/raoyongming/HorNet
视觉Transformer的最新进展表明,在基于点积自注意力的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,作者证明了视觉Transformer背后的关键成分,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。作者提出了递归门卷积(g n Conv),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。g nConv可以作为一个即插即用模块来改进各种视觉Transformer和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为HorNet。在ImageNet分类、COCO对象检测和ADE20K语义分割方面的大量实验表明,HorNet在总体架构和训练配置相似的情况下,优于Swin Transformers和ConvNeXt。HorNet还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明g n Conv可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,g n Conv可以作为一个新的视觉建模基本模块,有效地结合了视觉Transformer和CNN的优点。
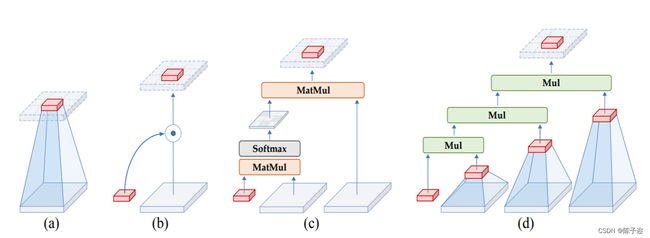
标准卷积运算没有明确考虑空间交互。
●
(b) 动态卷积 [27, 4] 和 SE [25] 引入了动态权重,以通过额外的空间交互来提高卷积的建模能力。
(c) 自注意力操作 通过两个连续的矩阵乘法执行二阶空间交互。
(d) gnConv 使用具有门控卷积和递归设计的高效实现来实现任意阶空间交互。
在本文中,作者总结了视觉Transformers成功背后的关键因素是通过自注意力操作实现输入自适应、远程和高阶空间交互的空间建模新方法。虽然之前的工作已经成功地将元架构、输入自适应权重生成策略和视觉Transformers的大范围建模能力迁移到CNN模型,但尚未研究高阶空间交互机制。作者表明,使用基于卷积的框架可以有效地实现所有三个关键要素。作者提出了递归门卷积(g nConv),它与门卷积和递归设计进行高阶空间交互。与简单地模仿自注意力中的成功设计不同,g n Conv有几个额外的优点:1)**效率。**基于卷积的实现避免了自注意力的二次复杂度。在执行空间交互期间逐步增加通道宽度的设计也使能够实现具有有限复杂性的高阶交互;2) 可扩展。将自注意力中的二阶交互扩展到任意阶,以进一步提高建模能力。由于没有对空间卷积的类型进行假设,g n Conv与各种核大小和空间混合策略兼容;3) 平移等变性。g n Conv完全继承了标准卷积的平移等变性,这为主要视觉引入了有益的归纳偏置。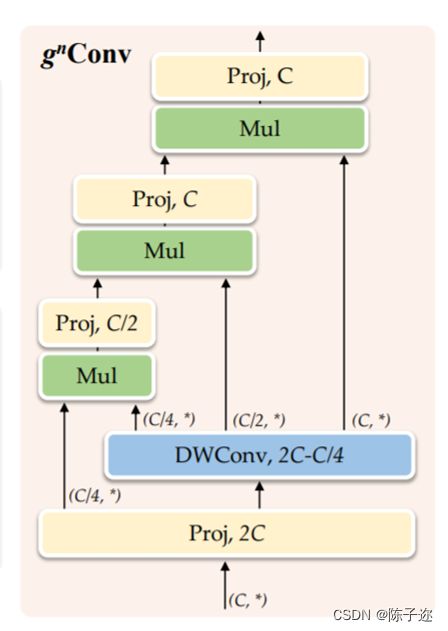
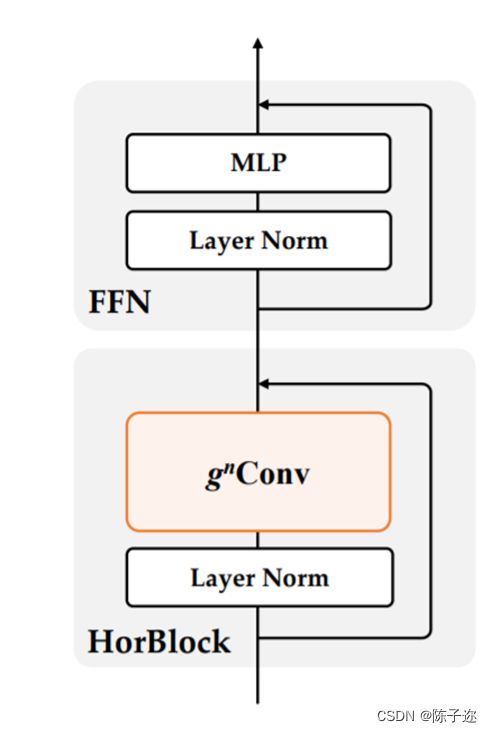
基于g n Conv,作者构建了一个新的通用视觉主干族,名为HorNet。作者在ImageNet分类、COCO对象检测和ADE20K语义分割上进行了大量实验,以验证本文模型的有效性。凭借相同的7×7卷积核/窗口和类似的整体架构和训练配置,HorNet优于Swin和ConvNeXt在不同复杂度的所有任务上都有很大的优势。通过使用全局卷积核大小,可以进一步扩大差距。HorNet还显示出良好的可扩展性,可以扩展到更多的训练数据和更大的模型尺寸,在ImageNet上达到87.7%的top-1精度,在ADE20K val上达到54.6%的mIoU,在COCO val上通过ImageNet-22K预训练达到55.8%的边界框AP。除了在视觉编码器中应用g n Conv外,作者还进一步测试了在任务特定解码器上设计的通用性。通过将g n Conv添加到广泛使用的特征融合模型FPN,作者开发了HorFPN来建模不同层次特征的高阶空间关系。作者观察到,HorFPN还可以以较低的计算成本持续改进各种密集预测模型。结果表明,g n Conv是一种很有前景的视觉建模方法,可以有效地结合视觉Transofrmer和CNN的优点。
2.YOLOv5代码修改
2.1 修改yaml文件 neck部分修改
# YOLOAir by , GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLO backbone
backbone:
[[-1, 1, HorNet, [128, 0, 3, [2, 3, 18, 2], 128]],
[-1, 1, HorNet, [256, 1, 3, [2, 3, 18, 2], 128]],
[-1, 1, HorNet, [512, 2, 3, [2, 3, 18, 2], 128]],
[-1, 1, HorNet, [1024, 3, 3, [2, 3, 18, 2], 128]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [1024, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]],
[-1, 3, C3, [1024, False]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 1], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 8], 1, Concat, [1]],
[-1, 3, C3, [1024, False]],
[-1, 1, Conv, [1024, 3, 2]],
[[-1, 4], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[11, 14, 17], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]2.2 common添加代码
class HorLayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).# https://ar5iv.labs.arxiv.org/html/2207.14284
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError # by iscyy/air
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GlobalLocalFilter(nn.Module):
def __init__(self, dim, h=14, w=8):
super().__init__()
self.dw = nn.Conv2d(dim // 2, dim // 2, kernel_size=3, padding=1, bias=False, groups=dim // 2)
self.complex_weight = nn.Parameter(torch.randn(dim // 2, h, w, 2, dtype=torch.float32) * 0.02)
trunc_normal_(self.complex_weight, std=.02)
self.pre_norm = HorLayerNorm(dim, eps=1e-6, data_format='channels_first')
self.post_norm = HorLayerNorm(dim, eps=1e-6, data_format='channels_first')
def forward(self, x):
x = self.pre_norm(x)
x1, x2 = torch.chunk(x, 2, dim=1)
x1 = self.dw(x1)
x2 = x2.to(torch.float32)
B, C, a, b = x2.shape
x2 = torch.fft.rfft2(x2, dim=(2, 3), norm='ortho')
weight = self.complex_weight
if not weight.shape[1:3] == x2.shape[2:4]:
weight = F.interpolate(weight.permute(3,0,1,2), size=x2.shape[2:4], mode='bilinear', align_corners=True).permute(1,2,3,0)
weight = torch.view_as_complex(weight.contiguous())
x2 = x2 * weight
x2 = torch.fft.irfft2(x2, s=(a, b), dim=(2, 3), norm='ortho')
x = torch.cat([x1.unsqueeze(2), x2.unsqueeze(2)], dim=2).reshape(B, 2 * C, a, b)
x = self.post_norm(x)
return x
class gnconv(nn.Module):
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
def forward(self, x, mask=None, dummy=False):
# B, C, H, W = x.shape gnconv [512]by iscyy/air
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
class HorBlock(nn.Module):
r""" HorNet block
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, gnconv=gnconv):
super().__init__()
self.norm1 = HorLayerNorm(dim, eps=1e-6, data_format='channels_first')
self.gnconv = gnconv(dim)
self.norm2 = HorLayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape # [512]
if self.gamma1 is not None:
gamma1 = self.gamma1.view(C, 1, 1)
else:
gamma1 = 1
x = x + self.drop_path(gamma1 * self.gnconv(self.norm1(x)))
input = x
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm2(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma2 is not None:
x = self.gamma2 * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class HorNet(nn.Module):
def __init__(self, index, in_chans, depths, dim_base, drop_path_rate=0.,layer_scale_init_value=1e-6,
gnconv=[
partial(gnconv, order=2, s=1.0/3.0),
partial(gnconv, order=3, s=1.0/3.0),
partial(gnconv, order=4, s=1.0/3.0),
partial(gnconv, order=5, s=1.0/3.0), # GlobalLocalFilter
],
):
super().__init__()
dims = [dim_base, dim_base * 2, dim_base * 4, dim_base * 8]
self.index = index
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers by iscyy/air
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
HorLayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
HorLayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks by iscyy/air
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
if not isinstance(gnconv, list):
gnconv = [gnconv, gnconv, gnconv, gnconv]
else:
gnconv = gnconv
assert len(gnconv) == 4
cur = 0
for i in range(4):
stage = nn.Sequential(
*[HorBlock(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value, gnconv=gnconv[i]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i] # by iscyy/air
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.downsample_layers[self.index](x)
x = self.stages[self.index](x)
return x2.3 YOLO注册
找到 parse_model并注册
def parse_model(d, ch): # model_dict, input_channels(3)
elif m in [CARAFE, SPPCSPC, SPPFCSPC, RepConv, BoT3, CA, CBAM, NAMAttention, GAMAttention, Involution, Stem, ResCSPC, ResCSPB, \
ResXCSPB, ResXCSPC, BottleneckCSPB, BottleneckCSPC,
ASPP, BasicRFB, SPPCSPC_group, HorNet, CNeB,C3GC ,C3C2, nn.ConvTranspose2d]: