YOLOv5,YOLOv8添加ASFF(自适应空间特征融合)
ASFF:Adaptively Spatial Feature Fusion (自适应空间特征融合)
论文来源:Learning Spatial Fusion for Single-Shot Object Detection
代码地址:ASFF
1.背景
不同特征尺度之间的不一致性是基于特征金字塔的单阶段检测器的主要缺陷。
本文提出了一种新的基于数据驱动的金字塔特征融合策略,称为自适应空间特征融合(ASFF)。它学习了空间过滤冲突信息的方法来抑制不一致性,从而提高了特征的尺度不变性,并且开销小。
所提出的方法使网络能直接学习如何在空间上过滤其他层次的特征,以便只保留有用的信息进行组合。在每个空间位置,不同层次的特征被自适应地融合,也就是说,一些特征在这个位置携带矛盾的信息时可能被过滤掉,而一些特征可能以更具争议性的线索支配。
- 提出一种自适应特征融合方法,ASFF
- ASFF可以提高FPN形式网络的性能
- 借助ASFF策略和可靠的YOLOv3基线,在MS COCO数据集上实现了最佳的速度精度折衷
解决单发检测器特征金字塔的不一致性。
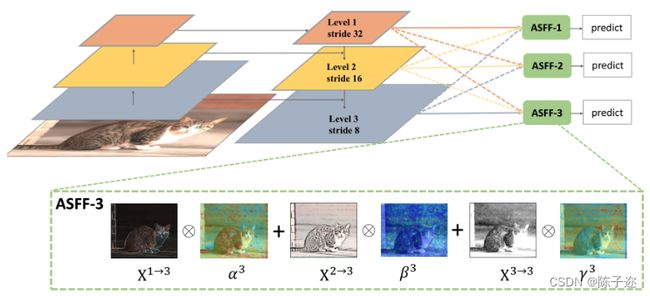
特征金字塔的一大缺点是不同尺度特征的不一致性,特别是对于一阶段检测器。确切地说,在FPN形式的网络中启发式地选择特征,高层语义信息中检测大目标、低层语义信息中检测小目标。当某个目标在某一层被当做正类时,相应地该目标区域在其它层被当做负类。如果一幅图像中既有大目标也有小目标,那么不同层间的特征的不一致性将会影响最后检测结果(大目标的检测在某一层,小目标的检测在另一层,但是网络的多尺寸检测不会仅仅检测一个特定的区域,而是综合整幅图进行检测。在特征融合时,其它层很多无用的信息也会融合进来)。
为了充分利用高层特征的语义信息和底层特征的细粒度特征,很多网络结构都会采用FPN的方式输出多层特征,但是无论是类似于YOLOv3还是RetinaNet他们多用concatenation或者element-wise这种直接衔接或者相加的方式,作者认为这样并不能充分利用不同尺度的特征。
示意图如下
2.YOLOv5代码修改
这里的代码我结合yolov5的网络结构进行过修改,所以会与原代码不同
2.1第一步,在models/common.py文件最下面添加下面的代码
def add_conv(in_ch, out_ch, ksize, stride, leaky=True):
"""
Add a conv2d / batchnorm / leaky ReLU block.
Args:
in_ch (int): number of input channels of the convolution layer.
out_ch (int): number of output channels of the convolution layer.
ksize (int): kernel size of the convolution layer.
stride (int): stride of the convolution layer.
Returns:
stage (Sequential) : Sequential layers composing a convolution block.
"""
stage = nn.Sequential()
pad = (ksize - 1) // 2
stage.add_module('conv', nn.Conv2d(in_channels=in_ch,
out_channels=out_ch, kernel_size=ksize, stride=stride,
padding=pad, bias=False))
stage.add_module('batch_norm', nn.BatchNorm2d(out_ch))
if leaky:
stage.add_module('leaky', nn.LeakyReLU(0.1))
else:
stage.add_module('relu6', nn.ReLU6(inplace=True))
return stage
class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
# 特征金字塔从上到下三层的channel数
# 对应特征图大小(以640*640输入为例)分别为20*20, 40*40, 80*80
self.dim = [512, 256, 128]
self.inter_dim = self.dim[self.level]
if level==0: # 特征图最小的一层,channel数512
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==1: # 特征图大小适中的一层,channel数256
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
elif level==2: # 特征图最大的一层,channel数128
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.compress_level_1 = add_conv(256, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 128, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized =F.interpolate(level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
2.2 第二步,在models/yolo.py文件的Detect类下面添加下面的类(我的是在92行加的)
class ASFF_Detect(Detect):
# ASFF model for improvement
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__(nc, anchors, ch, inplace)
self.nl = len(anchors)
self.asffs = nn.ModuleList(ASFF(i) for i in range(self.nl))
self.detect = Detect.forward
def forward(self, x): # x中的特征图从大到小,与ASFF中顺序相反,因此输入前先反向
x = x[::-1]
for i in range(self.nl):
x[i] = self.asffs[i](*x)
return self.detect(self, x[::-1])
2.3 第三步,在有yolo.py这个文件中,出现 Detect, Segment这个代码片段的地方加入ASFF_Detect,例如我的177行中改动后变成:

一共会改三处类似的地方,我的分别是177,211,353行。
2.4 第四步,在models文件夹下新创建一个文件,命名为yolov5s-ASFF.yaml,然后把下面的内容粘贴上去:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, ASFF_Detect, [nc, anchors]], # Detect(P3, P4, P5)
]