scrapy-redis crontab
1. 爬虫常用redis中的命令
/etc/init.d/redis-server start启动服务端redis-serverredis-cli -h客户端启动-p <端口号> redis-cli
select 1切换dbkeys *查看所有的键tyep 键查看键的类型,再决定给其何种方式操作flushdb清空dbflushall清空所有数据库
列表list:
LPUSH mylist "world"向mylist从左边添加一个值LRANGE mylist 0 -1返回mylist中的所有值LLEN mylist返回mylist的长度
set:
SADD myset "hello"往set中添加数据SMEMBERS myset获取myset中的所有元素SCARD myset获取myset中的数量
zset:
ZADD myset 1 "one"添加一条数据,成功会有返回(interger)ZADD myset 2 "two" 3 "three"添加两条数据ZRANGE myset 0 -1 WITHSCORES遍历myset的所有值ZCARD myset返回zset中元素的数量
2. scrapy_redis domz爬虫 分析
###1.scrapy流程
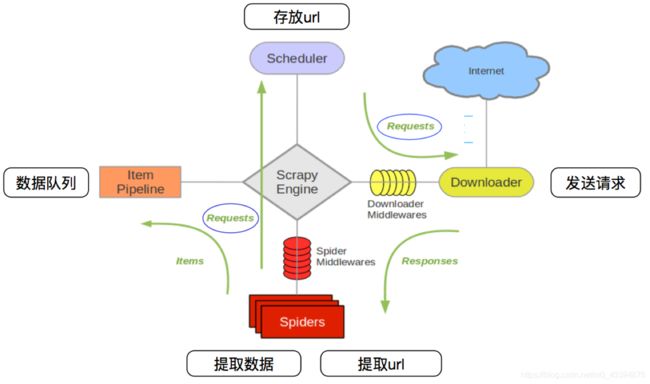
###2.scrapy-redis流程
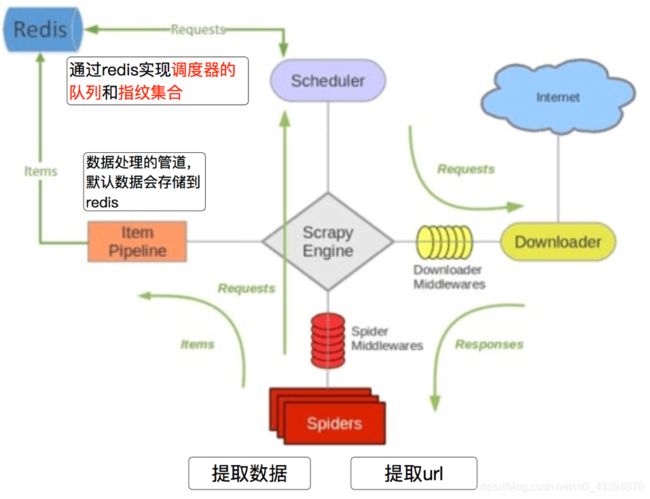
源码中的demo文件
1、clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git 2、研究项目自带的三个demo mv scrapy-redis/example-project ~/scrapyredis-project
在domz爬虫文件中,实现方式就是之前的crawlspider类型的爬虫
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/']
# 定义数据提取规则,使用了css选择器
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
但是在settings.py中多了一下几行,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
首先我们需要添加redis的地址,程序才能够使用redis
REDIS_URL = "redis://127.0.0.1:6379"
#或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379
我们执行domz的爬虫,会发现redis中多了一下三个键:
deoz:requests scheduler队列,存放的是待请求的requests对象,获取的过程是pop, 即获取一个删除一个
dmoz:dupefilter 指纹集合,存放的是已经放入到scheduler队列的requests对象,指纹默认由:请求方法,url,请求体组成
dmoz:items 存放获取到的item信息,在pipline中开启RedisPipline才会存入
3. scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析 分别是:
- RedisPipeline
- RFPDupeFilter
- Scheduler
RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密

Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

由此可以总结出request对象入队的条件
- request之前没有见过
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
4. RedisSpider实现分布式爬虫
分析demo中代码
通过观察代码:
- 继承自父类为RedisSpider
- 增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
- 多了
__init__方法,该方法不是必须的,可以手动指定allow_domains

5. RedisCrawlSpider
分析demo中的代码
和scrapy中的crawlspider的区别在于,继承自的父类,redis_key需要添加

6. crontab爬虫定时启动
crontab的安装和介绍

使用流程
- 把爬虫启动命令写入
.sh文件 - 给
.sh脚本添加可执行权限 - 把
.sh添加到crontab脚本正
myspier.sh例子
-
执行命令写入脚本
其中
>>表示重定向,把print等信息导入log中2>&1表示把标准错误作为标准输出,输入用0表示,标准输出用1表示,标准错误用2标识,通过该命令能够把错误一起输出到log中cd `dirname $0` || exit 1 python ./main.py >> run.log 2>&1 -
添加可执行权限
sudo chmod +x myspder.sh -
写入crontab中
sh脚本文件也可能会报错,对应的可以把其输出和错误重定向到run2.log中
0 6 * * * /home/ubuntu/..../myspider.sh >> /home/ubuntu/.../run2.log 2>&1
7. pycharm的tool工具:
- tools – > deployment —> SFTP 链接 —> 输入ip , 用户名, 密码—> 测试连接 —> Mappings—>选择py文件的保存到远端的目录 (完成设置
- 在需要上传的文件夹上右击,选择upload to xx 既可以传送到指定的目录,如果需要同步代码,在修改之后右击选择synchronize’xxx’
代码练习:
京东图书scrapy和scrapy-redis
- scrapy爬虫的思想和流程
- scrapy-redis比scrapy多出来的四行代码
- 插入数据到mongodb的示例
- 重点: 获取价格请求的方法: 先在调试工具搜索价格–找到json的url地址–复制进行url解码–删减url–找到skuid替换–得到的就是包含价格的字典,然后请求改地址再取值就是价格 // 在获取价格的时候,要
allowed_domains = ['jd.com','p.3.cn'], 因为是访问了p3.cn才返回的价格 - 选中兄弟节点:
em_list = dt.xpath("./following-sibling::*[1]/em")
import scrapy
from copy import deepcopy
import json
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com','p.3.cn']
start_urls = ['https://book.jd.com/booksort.html']
def parse(self, response): #提取所有的大分类和对应的小分类
#获取大分类的分组
dt_list = response.xpath("//div[@class='mc']/dl/dt")
for dt in dt_list:
item = {}
#大分类的名字
item["b_cate"] = dt.xpath("./a/text()").extract_first()
#获取小分类的分组
em_list = dt.xpath("./following-sibling::*[1]/em")
for em in em_list:
#小分类的地址
item["s_href"] = "https:"+em.xpath("./a/@href").extract_first()
#小分类的名字
item["s_cate"] = em.xpath("./a/text()").extract_first()
#构造小分类url地址的请求,能够进入列表页
yield scrapy.Request(
item["s_href"],
callback=self.parse_book_list,
meta= {"item":deepcopy(item)}
)
def parse_book_list(self,response):#提取列表页的数据
item = response.meta["item"]
#图书列表页书的分组
li_list = response.xpath("//div[@id='plist']/ul/li")
for li in li_list:
item["book_name"] = li.xpath(".//div[@class='p-name']/a/em/text()").extract_first().strip()
item["book_author"] = li.xpath(".//span[@class='p-bi-name']/span/a/text()").extract()
item["book_press"] = li.xpath(".//span[@class='p-bi-store']/a/text()").extract_first()
item["book_publisth_date"] = li.xpath(".//span[@class='p-bi-date']/text()").extract_first().strip()
item["book_sku"] = li.xpath("./div/@data-sku").extract_first()
#发送价格的请求,获取价格
price_url_temp = "https://p.3.cn/prices/mgets?ext=11000000&pin=&type=1&area=1_72_4137_0&skuIds=J_{}"
price_url = price_url_temp.format(item["book_sku"])
yield scrapy.Request(
price_url,
callback=self.parse_book_price,
meta = {"item":deepcopy(item)}
)
#实现翻页
next_url = response.xpath("//a[@class='pn-next']/@href").extract_first()
if next_url is not None:
yield response.follow(
next_url,
callback=self.parse_book_list,
meta = {"item":item}
)
def parse_book_price(self,resposne): #提取价格
item = resposne.meta["item"]
item["book_price"] = json.loads(resposne.body.decode())[0]["op"]
print(item)
#如果要实现scrapy-redis爬虫, 只需要在上面的基础之上, 在settings.py文件中补充下面四行代码:
#指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#制定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#调度器的内容是否持久化
SCHEDULER_PERSIST = True
#redis的url地址
REDIS_URL = "redis://127.0.0.1:6379"
#如果要插入到mongo:
from pymongo import MongoClient
client = MongoClient()
collection = client["book"]["jdbook"]
...........
collection.insert_many(item)
当当图书RedisSpider
发送小链接请求: yield scrapy.Request , 构造翻页请求: yield response.follow- 在爬虫文件中,导入
from scrapy_redis.spiders import RedisSpider,继承class DangdangSpider(RedisSpider): - 在pipline中处理字段中的空白字符
- 在setting中开启管道和redis设置
- 运行命令: 第一步 :
scrapy crawl dangdang第二步:在redis中插入: lpush dangdang http://book.dangdang.com/
import scrapy
from scrapy_redis.spiders import RedisSpider
from copy import deepcopy
class DangdangSpider(RedisSpider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
# start_urls = ['http://book.dangdang.com/']
redis_key = "dangdang"
def parse(self, response):
#获取大分类分组
div_list = response.xpath("//div[@class='con flq_body']/div")[1:-1]
for div in div_list:
item = {}
#大分类的名字
item["b_cate"] = div.xpath(".//dl[contains(@class,'primary_dl')]/dt//text()").extract()
#获取中间分类的分组
dl_list = div.xpath(".//dl[@class='inner_dl']")
for dl in dl_list:
#中间分类的名字
item["m_cate"] = dl.xpath("./dt//text()").extract()
#获取小分类的分组
a_list = dl.xpath("./dd/a")
for a in a_list:
#小分类的名字
item["s_cate"] = a.xpath("./text()").extract_first()
item["s_href"] = a.xpath("./@href").extract_first()
#发送小分类URL地址的请求,达到列表页
yield scrapy.Request(
item["s_href"],
callback=self.parse_book_list,
meta = {"item":deepcopy(item)}
)
def parse_book_list(self,response): #提取列表页的数据
item = response.meta["item"]
#获取列表页图书的分组
li_list = response.xpath("//ul[@class='bigimg']/li")
for li in li_list:
item["book_name"] = li.xpath("./a/@title").extract_first()
item["book_href"] = li.xpath("./a/@href").extract_first()
item["book_author"] = li.xpath(".//p[@class='search_book_author']/span[1]/a/text()").extract()
item["book_press"] = li.xpath(".//p[@class='search_book_author']/span[3]/a/text()").extract_first()
item["book_desc"] = li.xpath(".//p[@class='detail']/text()").extract_first()
item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first()
item["book_store_name"] = li.xpath(".//p[@class='search_shangjia']/a/text()").extract_first()
item["book_store_name"] = "当当自营" if item["book_store_name"] is None else item["book_store_name"]
yield item
#实现列表页翻页
next_url = response.xpath("//li[@class='next']/a/@href").extract_first()
if next_url is not None:
#构造翻页请求
yield response.follow(
next_url,
callback = self.parse_book_list,
meta = {"item":item}
)
# pipline
class DangDangPipeline(object):
def process_item(self, item, spider):
if spider.name == "dangdang":
item["b_cate"] = "".join([i.strip() for i in item["b_cate"]])
item["m_cate"] = "".join([i.strip() for i in item["m_cate"]])
print(item)
return item
# settings
#指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#制定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#调度器的内容是否持久化
SCHEDULER_PERSIST = True
#redis的url地址
REDIS_URL = "redis://192.168.95.22:6379"
# 开启管道
ITEM_PIPELINES = {'book.pipelines.DangDangPipeline': 300,}
amazon图书RedisCrawlSpider爬虫
- 导入
from scrapy_redis.spiders import RedisCrawlSpider添加redis_key = "amazon"注释掉start_urls - Rule中用一个规则匹配两个条件: 大分类和小分类的方法 , 实现翻页也是在Rule里
response.xpath("//b[text()='出版社:']/../text()")这种方式选择标签值得学习- restrict_xpaths()可以自动寻找标签下的所有的链接
- 因为该书的价格分为电子书与普通书,所以根据标题里是否含有特定值来判断,写入不同字段
- 字符串的切割方法``
- 使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符,在整体中进行匹配。
- 图书简介取到的时编码格式,怎么转换成字符串
-response.xpath("//ul/li[not(@class)]//a/text()")不包含节点选择
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
import re
class AmazonSpider(RedisCrawlSpider):
name = 'amazon'
allowed_domains = ['amazon.cn']
# start_urls = ['https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051']
redis_key = "amazon"
rules = (
#实现提取大分类的URL地址,同时提取小分类的url地址 , 定位到li标签,redis_xpath会自动提取li之内的所有url地址
# Rule(LinkExtractor(restrict_xpaths=("//ul[contains(@class,'a-unordered-list a-nostyle a-vertical s-ref-indent-')]/div/li",)), follow=True),
# Rule(LinkExtractor(restrict_xpaths=("//ul[@class='a-unordered-list a-nostyle a-vertical s-ref-indent-two']/div/li",)), follow=True),
# 实现提取图书详情页的url地址
Rule(LinkExtractor(restrict_xpaths=("//div[@id='mainResults']/ul/li//h2/..",)), callback="parse_item"),
#实现列表页的翻页
Rule(LinkExtractor(restrict_xpaths=("//div[@id='pagn']//a",)),follow=True),
)
def parse_item(self, response):
item = {}
item["book_name"] = response.xpath("//span[contains(@id,'roductTitle')]/text()").extract_first()
item["book_author"] = response.xpath("//div[@id='bylineInfo']/span[@class='author notFaded']/a/text()").extract()
item["book_press"] = response.xpath("//b[text()='出版社:']/../text()").extract_first()
item["book_cate"] = response.xpath("//div[@id='wayfinding-breadcrumbs_feature_div']/ul/li[not(@class)]//a/text()").extract()
item["book_url"] = response.url
item["book_desc"] = re.findall(r"\s+\n ,response.body.decode(),re.S)[0]
# item["book_img"] = response.xpath("//div[contains(@id,'img-canvas')]/img/@src").extract_first()
item["is_ebook"] = "Kindle电子书" in response.xpath("//title/text()").extract_first()
if item["is_ebook"]:
item["ebook_price"] = response.xpath("//td[@class='a-color-price a-size-medium a-align-bottom']/text()").extract_first()
else:
item["book_price"]= response.xpath("//span[contains(@class,'price3P')]/text()").extract_first()
yield item
# pipline
import re
class DangDangPipeline(object):
def process_item(self, item, spider):
if spider.name == "dangdang":
item["b_cate"] = "".join([i.strip() for i in item["b_cate"]])
item["m_cate"] = "".join([i.strip() for i in item["m_cate"]])
print(item)
return item
class AmazonPipline:
def process_item(self,item,spider):
if spider.name == "amazon":
item["book_cate"] = [i.strip() for i in item["book_cate"]]
item["book_desc"] = item["book_desc"].split("
")[0].split("
")
item["book_desc"] = [re.sub("||||\s+|\xa0||
","",i) for i in item["book_desc"]]
print(item)
return item
# setting
#指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#制定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#调度器的内容是否持久化
SCHEDULER_PERSIST = True
#redis的url地址
REDIS_URL = "redis://192.168.95.22:6379"
ITEM_PIPELINES = {'book.pipelines.DangDangPipeline': 300,'book.pipelines.AmazonPipline': 400,}