SSAS决策树算法原理
Microsoft 决策树算法是由 Microsoft SQL Server Analysis Services 提供的分类和回归算法,用于对离散和连续属性进行预测性建模。
对于离散属性,该算法根据数据集中输入列之间的关系进行预测。对于连续属性,该算法使用线性回归确定决策树的拆分位置。
如果将多个列设置为可预测列,或输入数据中包含设置为可预测的嵌套表,则该算法将为每个可预测列生成一个单独的决策树。
Microsoft 决策树算法不允许使用连续数据类型作为输入;因此,如果任何列具有连续数值数据类型,将对该值进行离散化处理。该算法在拆分点针对所有连续属性执行其自己的离散化处理。Analysis Services 自动选择对连续属性进行装桶的方法;但是,通过将挖掘结构列的内容类型设置为 Discretized,并设置 DiscretizationBucketCount 或 DiscretizationMethod 属性,您可以控制如何离散化输入中的连续值。
Microsoft 决策树算法是一种混合算法,它可以创建功能相差很大的多种模型:决策树可以表示关联和规则,甚至线性回归。树的结构实质上都是相同的,但如何解释信息则取决于您创建模型的目的。
算法的原理
Microsoft 决策树算法通过在树中创建一系列拆分来生成数据挖掘模型。这些拆分以“节点”来表示。每当发现输入列与可预测列密切相关时,该算法便会向该模型中添加一个节点。该算法确定拆分的方式不同,主要取决于它预测的是连续列还是离散列。
Microsoft 决策树算法使用“功能选择”来指导如何选择最有用的属性。所有 Analysis Services 数据挖掘算法均使用功能选择来改善分析的性能和质量。功能选择对防止不重要的属性占用处理器时间意义重大。如果在设计数据挖掘模型时使用过多的输入或可预测属性,则可能需要很长的时间来处理该模型,甚至导致内存不足。用于确定是否拆分树的方法包括对“平均信息量”和 Bayesian 网络的行业标准度量。
数据挖掘模型中的常见问题是该模型对定型数据中的细微差异过于敏感,这种情况称为“过度拟合”或“过度定型”。过度拟合模型无法推广到其他数据集。为避免模型对任何特定的数据集过度拟合,Microsoft 决策树算法使用一些技术来控制树的生长。
预测离散列
通过柱状图可以演示 Microsoft 决策树算法为可预测的离散列生成树的方式。下面的关系图显示了一个根据输入列 Age 绘出可预测列 Bike Buyers 的柱状图。该柱状图显示了客户的年龄可帮助判断该客户是否将会购买自行车。
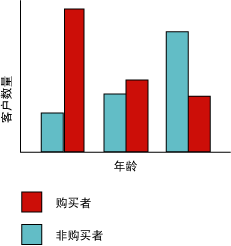
该关系图中显示的关联将会使 Microsoft 决策树算法在模型中创建一个新节点。
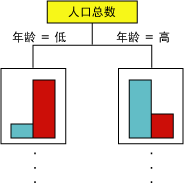
随着算法不断向模型中添加新节点,便形成了树结构。该树的顶端节点描述了客户总体可预测列的分解。随着模型的不断增大,该算法将考虑所有列。
预测连续列
当 Microsoft 决策树算法根据可预测的连续列生成树时,每个节点都包含一个回归公式。拆分出现在回归公式的每个非线性点处。例如,请看下面的关系图。
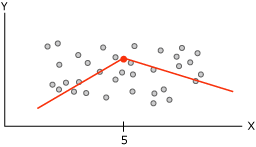
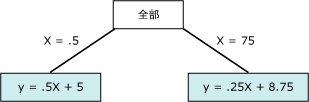
该关系图包含可通过使用一条或两条连线建模的数据。不过,一条连线将使得模型表示数据的效果较差。相反,如果使用两条连线,则模型可以更精确地逼近数据。两条连线的相交点是非线性点,并且是决策树模型中的节点将拆分的点。例如,与上图中的非线性点相对应的节点可以由以下关系图表示。两个等式表示两条连线的回归等式。
决策树模型所需的数据
在准备用于决策树模型的数据时,应了解特定算法的要求,其中包括所需的数据量以及数据的使用方式。
决策树模型的要求如下:
- 单个key 列 每个模型都必须包含一个数值或文本列,用于唯一标识每条记录。不允许复合键。
- 可预测列 至少需要一个可预测列。可以在模型中包括多个可预测属性,并且这些可预测属性的类型可以不同,可以是数值型或离散型。不过,增加可预测属性的数目可导致处理时间增加。
- 输入列 需要输入列,可为离散型或连续型。增加输入属性的数目会影响处理时间。
注释
- 支持使用预测模型标记语言 (PMML) 创建挖掘模型。
- 支持钻取。
- 支持使用 OLAP 挖掘模型和创建数据挖掘维度。