yolov5 windows 下训练+ c++ TensorRT 部署在qt (vs+qtcreator) 只要一篇文章即可
目录
1.yolov5训练自己的数据集
(1).github上下载好yolov5的代码
编辑
(2).yolov5的环境部署(这里是anaconda的方式 也可以pycharm 打开后直接pip install -r requirements.txt )
【1】下载下来之后进行解压:
【2】打开pycharm ,打开文件打开项目文件
【3】在anaconda 中生成好相应的环境:
【4】在pycharm 中部署anaconda中配置好的环境:
(3).yolov5的数据集的制作
(4).开始训练数据(cpu和GPU训练),并导出onnx保存结果
【1】cpu训练
【2】GPU训练--重点是cuda 和cudnn 的下载安装,把device改成0,其余和cpu的一样
2.yolov5 c++ tensoRT的部署
(1)下载配置tensorRT
(2)下载配置yolov5-tensorrrt
[1].下载源码(方法一):
[2]:当然这里我这边提供一个封装好的下载地址,下载的路径如下,后面的步骤和我的一样(方法2-推荐)
(2)pycharm 下将.pt导出成.wts文件 并在yolov5-tensorrrt生成.engine文件
【1】将gen_wts.py文件夹复制到和train.py 同级目录下面
【2】将要导出的.pt文件夹也复制到和train.py 同级目录下面
(3)yolov5-tensorrrt生成.engine文件
[1]将生成的exp8best.wts 文件复制到build/release 下面 并把picture复制到在build/release下面,下面可以验证
(4)yolov5-tensorrrt 的dll封装 可以直接外部调用
3.yolov5-tensorrrt 的dll在vs qt中调用
(1)这里关于qt 在vs 的配置 以及qt 在vs中常见的问题可以参考如下:我使用的qt 版本是5.12.10
(2)将下面这些文件复制进qt项目文件夹中,这些都是我们上面已经生成了的
1.yolov5训练自己的数据集
(1).github上下载好yolov5的代码
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
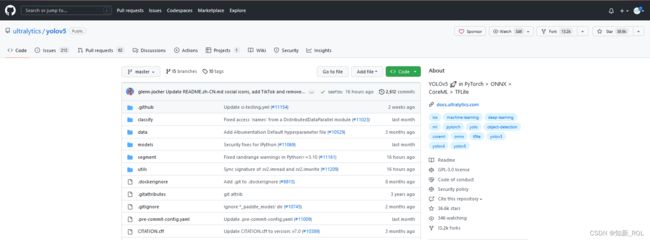
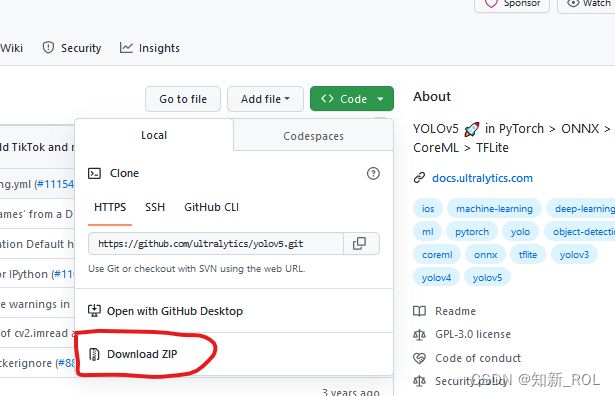
这里需要注意下载的版本。我这里直接是master 版本
(2).yolov5的环境部署(这里是anaconda的方式 也可以pycharm 打开后直接pip install -r requirements.txt )
【1】下载下来之后进行解压:

我解压在下面这个文件夹:
【2】打开pycharm ,打开文件打开项目文件




在这之前我们需要把环境配置一下啊
【3】在anaconda 中生成好相应的环境:

先产生一个环境:python 的版本选择的是3.8.16

然后点击下面的:进入命令行中

进入下面:
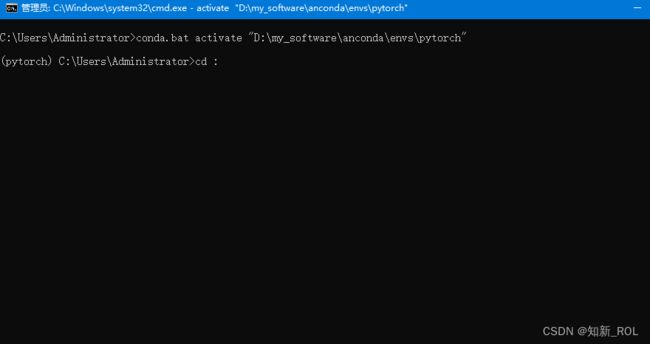
输入之前保存的文件路径
cd E:\yolov5_new_book\yolov5-master然后再输入当前所在的文件夹E: 就能进入到下解压好的yolov5-master的路径,
如果是D盘就输入D:
E:
(我们成功进入到pytorch虚拟环境中)
输入pip install -r requirements.txt指令进行安装,安装完成我们可以在 XXX\Anconda\envs\pytorch\Lib\site-packages路径下看到我们安装的各种依赖库。
pip install -r requirements.txt这里还需要在pycharm 中部署anaconda的环境
【4】在pycharm 中部署anaconda中配置好的环境:
选择settings


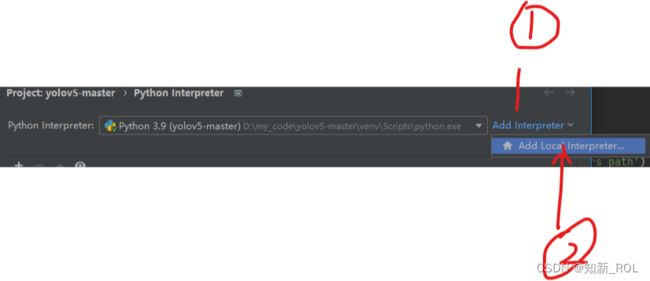
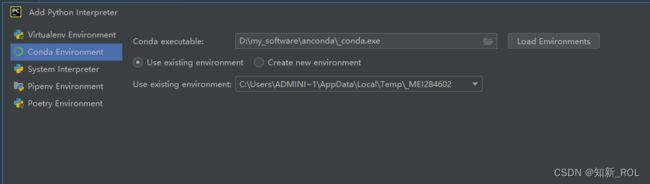
选择我们刚刚之前配置好的环境


然后点击apply 和ok 即可,

点击下面的加号,
![]()
目录按照如下选择即可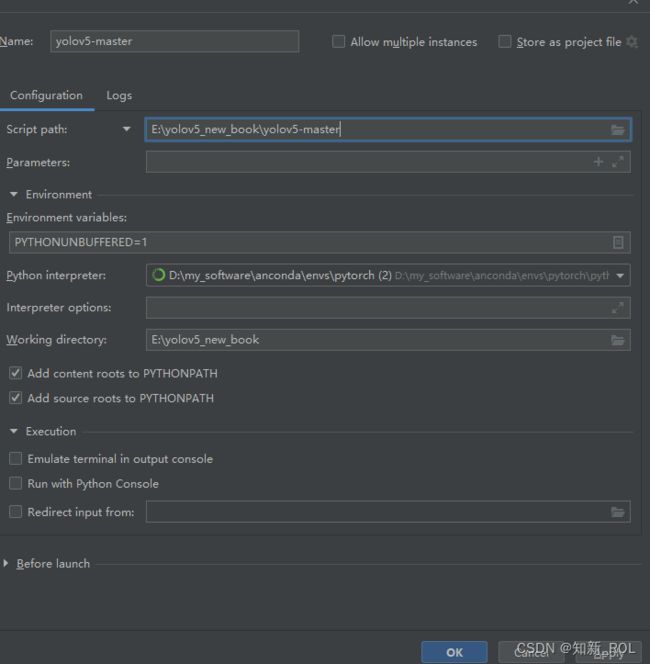
整体的环境配置完成;下面就可以开始制作自己的数据集了。
这部分有什么问题可以参考下面的 文章:
【零基础上手yolov5】yolov5的安装与相关环境的搭建_罅隙`的博客-CSDN博客
(3).yolov5的数据集的制作
在数据集的制作过程中有两种方式:1):labelme 2):labelImg 下面主要讲labelImg
这两者的主要区别在于,labelme的数据生成之后不能直接使用,还需要代码进行转换成.txt的文件。一开始我制作数据集的时候使用的是labelme 后来
首先在pycharm 的终端中输入:
pip install labelImg下载好后,继续在终端输入:labelImg 进入到打标签的页面,这些就可以自己去摸索了 我不啰嗦了 ,主要就是 openDir(打开你准备标记的数据集) change save Dir (保存你要标记的数据集文件夹)

制作数据集过程中可能遇到的:
1,数据集制作的过程中可能由于协调不到位会遇到标签 01 打错,看我主页,有代码可以直接替换0,1 标签集,
修改txt标签_知新_ROL的博客-CSDN博客yolo改txt标签https://blog.csdn.net/weixin_43608857/article/details/127400974?spm=1001.2014.3001.5502
2.数据集需要批量修改图片的(名称),你们可以选择我主页,也可以下载Adobe Bridge(比较方便)软件 进行
只要三步,批量改图片名称的方法_知新_ROL的博客-CSDN博客批量修改图片名称https://blog.csdn.net/weixin_43608857/article/details/127401714?spm=1001.2014.3001.55023.最后对数据集进行分类:可以参考我下面的代码,修改相应的文件目录即可:
yolov5 数据集分类,xml转txt,_yolov5 xml转txt_知新_ROL的博客-CSDN博客yolov5数据集分类https://blog.csdn.net/weixin_43608857/article/details/127414568?spm=1001.2014.3001.5502我们将我们制作好的数据集放到我们的目录下面:
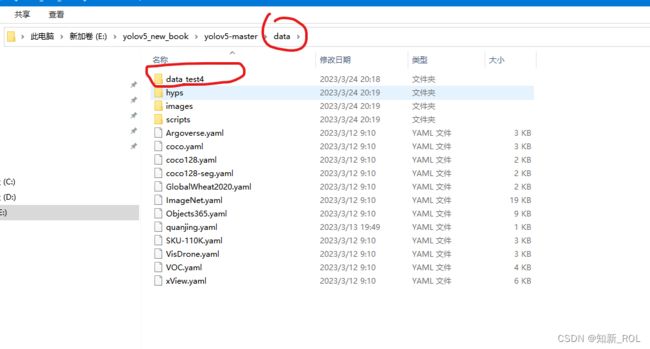
数据集的结构如下:data-分为images 和labels 然后每个里面继续分为训练集和测试集



这部分有什么问题可以参考下面的 文章:
yolov5制作数据集(实测)_yolov5数据集制作_Reminiscing 的博客-CSDN博客yolov5制作数据集https://blog.csdn.net/weixin_51732791/article/details/127699523
(4).开始训练数据(cpu和GPU训练),并导出onnx保存结果
【1】cpu训练
现在data 目录下新建一个yamal文件
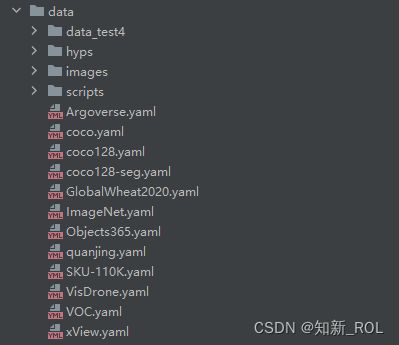

将coco 数据集的yaml复制过来改成我们自己的数据集,包括种类和路径

打开train.py

修改data

设置epochs 为300轮, batch-size 8 ,device 改成cpu,

其他的没啥改动,右键 run “train”
会跑出来一组实验结果,weights 里面的 best.pt权重文件是我们后面要导出的

打开export.py文件

要修改的有,data, imgsize 和前面的一样 ,weights 改成我们刚刚跑出来的数据
./runs/train/exp6/weights/best.pt![]()
最后这里改成如下
右键run export.py
会在相应的weight 中生成一个![]()
这样表示导出成功。
【2】GPU训练--重点是cuda 和cudnn 的下载安装,把device改成0,其余和cpu的一样
![]()
注意:如果刚打开时,软件崩了的话,可能是显卡内存不够,减小img-size 或者batch-size
下面讲一下cuda的配置
1.确定好自己的显卡型号,如何确定看后面的那个;两个链接
需要注意的是:cuda 和cudnn的型号要匹配
cuda的下载地址:
https://developer.nvidia.com/
cudnn的下载地址:
https://developer.nvidia.com/rdp/cudnn-download
在终端输入nvidia-smi,返回GPU型号则安装成功有啥问题可以参考别人的配置:基本上都能解决
windows安装cuda简易教程_浅梦语11的博客-CSDN博客在windows环境中选择适合cuda版本进行下载安装,以进行后续的深度学习等工作。https://blog.csdn.net/weixin_43907136/article/details/127014181
Windows10系统CUDA和CUDNN安装教程_cudnn安装教程win10_流泪&枯萎的博客-CSDN博客Windows10系统下安装CUDA和CUDNN保姆级教程https://blog.csdn.net/yang4123/article/details/127188279
win10 使用TensorRT部署 yolov5-v4.0(C++)_yolo v5 4.0 c++_SongpingWang的博客-CSDN博客
2.yolov5 c++ tensoRT的部署
(1)下载配置tensorRT
官网地址:
https://developer.nvidia.com/nvidia-tensorrt-8x-download=
我这边下的是tensorRT8.x,勾选 I agree 出现

选择window 下的

下载后解压到文件夹:
![]()

将 TensorRT-7.2.3.4\include 中头文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include;
将 TensorRT-7.2.3.4\lib 中所有lib文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64;
将 TensorRT-7.2.3.4\lib 中所有dll文件copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin;
【windows版】TensorRT安装教程_tensorrt windows_花花少年的博客-CSDN博客模型推理的时候,每一次的操作都是由GPU启动不同的的CUDA核心来完成的,大量的时间花在CUDA核心启动和读写操作上,造成了内存带宽的瓶颈和GPU资源浪费。TensorRT通过层间融合,横向融合把卷积偏置激活合并成一个结构,并且只占用一个CUDA核心,纵向融合把结构相同、权值不同的层合并成一个更宽的层,也是占用一个CUDA核心,因此整个模型结构更小更快。https://blog.csdn.net/m0_37605642/article/details/127583310
(2)下载配置yolov5-tensorrrt
下面是整个项目的环境
WIN 10
CUDA 11.7
CuDnn 8.7.0
TensorRT 8.5.3.1
OpenCV 4.5.3
VS 2017[1].下载源码(方法一):
https://github.com/wang-xinyu/tensorrtx/tags
下面这个地址是tensorrrt-yolov5的
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5 https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
这里还需要单独下载一个文件dirent.h:
dirent/dirent.h at master · tronkko/dirent · GitHub
新建一个文件夹
![]()
我是在里面又建了一个include 的文件夹放下载下来的dirent.h

[2]:当然这里我这边提供一个封装好的下载地址,下载的路径如下,后面的步骤和我的一样(方法2-推荐)
GitHub - Monday-Leo/Yolov5_Tensorrt_Win10: A simple implementation of tensorrt yolov5 python/c++
然后修改cmakelists 中的路径改成自己路径:
cmake_minimum_required(VERSION 2.6)
project(yolov5)
#change to your own path
##################################################
set(OpenCV_DIR "D:\\my_software\\opencv\\opencv\\build")
set(OpenCV_INCLUDE_DIRS "D:\\my_software\\opencv\\opencv\\build\\include")
set(TRT_DIR "D:\\my_software\\TensorRT-8.5.3.1")
set(Dirent_INCLUDE_DIRS "D:\\my_code\\my_yolov5_tensorrt_build\\Yolov5_Tensorrt_Win10-master\\include")
##################################################
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads)
# setup CUDA
find_package(CUDA REQUIRED)
message(STATUS " libraries: ${CUDA_LIBRARIES}")
message(STATUS " include path: ${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
include_directories(${Dirent_INCLUDE_DIRS})
#change to your GPU own compute_XX
###########################################################################################
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS};-std=c++11;-g;-G;-gencode;arch=compute_75;code=sm_75)
###########################################################################################
####
enable_language(CUDA) # add this line, then no need to setup cuda path in vs
####
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${TRT_DIR}\\include)
# -D_MWAITXINTRIN_H_INCLUDED for solving error: identifier "__builtin_ia32_mwaitx" is undefined
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")
# setup opencv
find_package(OpenCV QUIET
NO_MODULE
NO_DEFAULT_PATH
NO_CMAKE_PATH
NO_CMAKE_ENVIRONMENT_PATH
NO_SYSTEM_ENVIRONMENT_PATH
NO_CMAKE_PACKAGE_REGISTRY
NO_CMAKE_BUILDS_PATH
NO_CMAKE_SYSTEM_PATH
NO_CMAKE_SYSTEM_PACKAGE_REGISTRY
)
message(STATUS "OpenCV library status:")
message(STATUS " version: ${OpenCV_VERSION}")
message(STATUS " libraries: ${OpenCV_LIBS}")
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${TRT_DIR}\\lib)
add_executable(yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h ${PROJECT_SOURCE_DIR}/preprocess.cu)
target_link_libraries(yolov5 "nvinfer" "nvinfer_plugin")
target_link_libraries(yolov5 ${OpenCV_LIBS})
target_link_libraries(yolov5 ${CUDA_LIBRARIES})
target_link_libraries(yolov5 Threads::Threads)
然后这里需要cmake一下:

路径的配置如上,先configure一下,

然后再generate

cmake后的结果:
然后可以openProject

这里需要修改一些参数:
【1】在yololayer.h中 输入自定义训练图像的尺寸大小,和检测类别数量

【2】选择release或者debug,点击生成项目,
会在 build 下面的 Debug 文件夹下生成如下,

注意我们这里没有点击本地window调试器,因为这是一个封装好的导出dill和.exe文件的,不能打开本地调试器,不然会报错(报错没有关系),但不影响它在本地生成debug下面的文件

以上对yolov5-tensorrrt的配置已经完成了。
如果cmake 有啥不懂的可以参考下面
windows中CMake的安装与配置_cmake安装windows_秋雨梧桐落满阶的博客-CSDN博客
(2)pycharm 下将.pt导出成.wts文件 并在yolov5-tensorrrt生成.engine文件
【1】将gen_wts.py文件夹复制到和train.py 同级目录下面

【2】将要导出的.pt文件夹也复制到和train.py 同级目录下面
【1】修改device 把默认的GPU改成0,然后把我们需要导出的终端下面输入如下命令行:
python gen_wts.py -w exp8best.pt -o exp8best.wts 
即可生成
(3)yolov5-tensorrrt生成.engine文件
[1]将生成的exp8best.wts 文件复制到build/release 下面 并把picture复制到在build/release下面,下面可以验证

[2]在文件夹下面, 输入cmd 进入命令行

【3】在命令行中输入如下代码:
yolov5 -s exp8best.wts yolov5sexp8best.engine s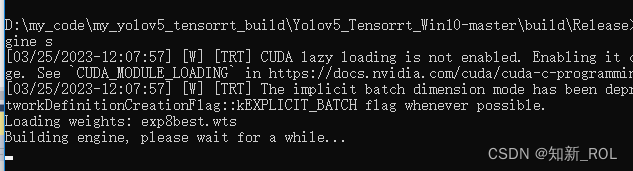
如果一切正常的话,这里导出engine需要一点时间,不会马上弄好。

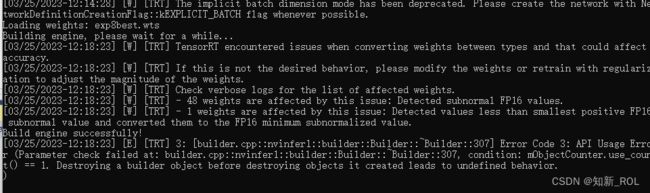
成功了则会出现build engine successfully
下面这个错误是由于yololayer.h中 检测的类别数目没改,看前面把它改过来
到现在.engine文件 的导出结束。
下面进行测试,我在release/picture 下放了一组照片

还是在原来的在命令行中输入:
yolov5 -d yolov5sexp8best.engine ./pictures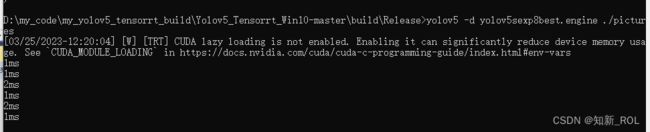
说明导出的yolov5sexp8best.engine测试成功
(4)yolov5-tensorrrt 的dll封装 可以直接外部调用
【1】还在原来的文件夹路径下 新建一个build_dill (这里我建议,大家可以重新把前面链接里下载好的文档再重新解压到一个新的文件夹,因为这里要重新cmake过,所以可能会导致我们之前生成engine 的项目出错,所以建议还是新建一个文件夹,解压下面文件,在新的文件夹下操作,)

【2】生成dll项目的cmake文件如下写入:
cmake_minimum_required(VERSION 2.6)
project(yolov5)
#change to your own path
##################################################
set(OpenCV_DIR "D:\\my_software\\opencv\\opencv\\build")
set(OpenCV_INCLUDE_DIRS "D:\\my_software\\opencv\\opencv\\build\\include")
set(TRT_DIR "D:\\my_software\\TensorRT-8.5.3.1")
set(Dirent_INCLUDE_DIRS "D:\\my_code\\Yolov5_Tensorrt_Win10-master\\include")
##################################################
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads)
# setup CUDA
find_package(CUDA REQUIRED)
message(STATUS " libraries: ${CUDA_LIBRARIES}")
message(STATUS " include path: ${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
include_directories(${Dirent_INCLUDE_DIRS})
#change to your GPU own compute_XX
###########################################################################################
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS};-std=c++11;-g;-G;-gencode;arch=compute_75;code=sm_75)
###########################################################################################
####
enable_language(CUDA) # add this line, then no need to setup cuda path in vs
####
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${TRT_DIR}\\include)
# -D_MWAITXINTRIN_H_INCLUDED for solving error: identifier "__builtin_ia32_mwaitx" is undefined
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")
# setup opencv
find_package(OpenCV QUIET
NO_MODULE
NO_DEFAULT_PATH
NO_CMAKE_PATH
NO_CMAKE_ENVIRONMENT_PATH
NO_SYSTEM_ENVIRONMENT_PATH
NO_CMAKE_PACKAGE_REGISTRY
NO_CMAKE_BUILDS_PATH
NO_CMAKE_SYSTEM_PATH
NO_CMAKE_SYSTEM_PACKAGE_REGISTRY
)
message(STATUS "OpenCV library status:")
message(STATUS " version: ${OpenCV_VERSION}")
message(STATUS " libraries: ${OpenCV_LIBS}")
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${TRT_DIR}\\lib)
#add_executable(yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h ${PROJECT_SOURCE_DIR}/preprocess.cu)
add_library(yolov5 SHARED ${PROJECT_SOURCE_DIR}/common.hpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h "Detection.h" "Detection.cpp" "framework.h" "dllmain.cpp""pch.h" )
target_link_libraries(yolov5 "nvinfer" "nvinfer_plugin")
target_link_libraries(yolov5 ${OpenCV_LIBS})
target_link_libraries(yolov5 ${CUDA_LIBRARIES})
target_link_libraries(yolov5 Threads::Threads)
这里和上面那段的主要的区别是下面这段代码:
#add_executable(yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h ${PROJECT_SOURCE_DIR}/preprocess.cu)
add_library(yolov5 SHARED ${PROJECT_SOURCE_DIR}/common.hpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h "Detection.h" "Detection.cpp" "framework.h" "dllmain.cpp""pch.h" )

这里在cmake之前要写几个文件,

1.导出dll的vs的模板文件,你可以自己新建一个项目,生成一个能调用的dill 测试一遍,再进行下面的过程。
导出库必要文件:dllmain.cpp,framework.h,就在当前工程下面建立这两个文件这里就直接给出文件。
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#pragma once
#include "pch.h"
BOOL APIENTRY DllMain(HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}// framework.h
#pragma once
#define WIN32_LEAN_AND_MEAN // 从 Windows 头文件中排除极少使用的内容
// Windows 头文件
#include 新建导出类文件:pch.h,Detection.h,Detection.cpp
// pch.h: 这是预编译标头文件。
// 下方列出的文件仅编译一次,提高了将来生成的生成性能。
// 这还将影响 IntelliSense 性能,包括代码完成和许多代码浏览功能。
// 但是,如果此处列出的文件中的任何一个在生成之间有更新,它们全部都将被重新编译。
// 请勿在此处添加要频繁更新的文件,这将使得性能优势无效。
#pragma once
#ifndef PCH_H
#define PCH_H
// 添加要在此处预编译的标头
#include "framework.h"
#include
#include
#include
#include
#include
#include
#include
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
#define CLASS_DECLSPEC __declspec(dllexport)//表示这里要把类导出//
struct Net_config
{
float gd; // engine threshold
float gw; // engine threshold
const char* netname;
};
class CLASS_DECLSPEC YOLOV5
{
public:
YOLOV5() {};
virtual ~YOLOV5() {};
public:
virtual void Initialize(const char* model_path, int num) = 0;
virtual int Detecting(cv::Mat& frame, std::vector& Boxes, std::vector& ClassLables) = 0;
};
#endif //PCH_H
// pch.cpp: 与预编译标头对应的源文件
#include "pch.h"
// 当使用预编译的头时,需要使用此源文件,编译才能成功。
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
这里面类别数量可以自己改成自己的
const char* classes[3] = { "ship", "car","person" };
//Detection.h
#pragma once
#include "pch.h"
#include "yololayer.h"
#include
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
class CLASS_DECLSPEC Connect
{
public:
Connect();
~Connect();
public:
YOLOV5* Create_YOLOV5_Object();
void Delete_YOLOV5_Object(YOLOV5* _bp);
};
class Detection :public YOLOV5
{
public:
Detection();
~Detection();
void Initialize(const char* model_path, int num);
void setClassNum(int num);
int Detecting(cv::Mat& frame, std::vector& Boxes, std::vector& ClassLables);
private:
char netname[20] = { 0 };
float gd = 0.0f, gw = 0.0f;
const char* classes[3] = { "ship", "car","person" };
Net_config yolo_nets[4] = {
{0.33, 0.50, "yolov5s"},
{0.67, 0.75, "yolov5m"},
{1.00, 1.00, "yolov5l"},
{1.33, 1.25, "yolov5x"}
};
int CLASS_NUM = 2;
float data[1 * 3 * 640 * 640];
float prob[1 * 6001];
size_t size = 0;
int inputIndex = 0;
int outputIndex = 0;
char* trtModelStream = nullptr;
void* buffers[2] = { 0 };
nvinfer1::IExecutionContext* context;
cudaStream_t stream;
nvinfer1::IRuntime* runtime;
nvinfer1::ICudaEngine* engine;
};
// Detection.cpp : 定义 DLL 的导出函数。
//
#include "pch.h"
#pragma once
#include "Detection.h"
using namespace std;
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;
static int get_width(int x, float gw, int divisor = 8) {
//return math.ceil(x / divisor) * divisor
if (int(x * gw) % divisor == 0) {
return int(x * gw);
}
return (int(x * gw / divisor) + 1) * divisor;
}
static int get_depth(int x, float gd) {
if (x == 1) {
return 1;
}
else {
return round(x * gd) > 1 ? round(x * gd) : 1;
}
}
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto bottleneck_CSP2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto bottleneck_csp4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto bottleneck_csp6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7");
auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, 9, 13, "model.8");
/* ------ yolov5 head ------ */
auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9");
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10");
auto upsample11 = network->addResize(*conv10->getOutput(0));
assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };
auto cat12 = network->addConcatenation(inputTensors12, 2);
auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");
auto upsample15 = network->addResize(*conv14->getOutput(0));
assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");
// yolo layer 0
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
auto cat19 = network->addConcatenation(inputTensors19, 2);
auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");
//yolo layer 1
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors22, 2);
auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
//下面三行是修改
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);
std::vector dets = { det0, det1, det2 };
std::string lname = "yolov5sexp8best";
auto yolo = addYoLoLayer(network, weightMap, lname, dets );
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {
// Create builder
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);
assert(engine != nullptr);
// Serialize the engine
(*modelStream) = engine->serialize();
// Close everything down
engine->destroy();
builder->destroy();
config->destroy();
}
inline void doInference(IExecutionContext& context, cudaStream_t& stream, void** buffers, float* input, float* output, int batchSize) {
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
void Detection::Initialize(const char* model_path, int num)
{
if (num < 0 || num>3) {
cout << "=================="
"0, yolov5s"
"1, yolov5m"
"2, yolov5l"
"3, yolov5x" << endl;
return;
}
cout << "Net use :" << yolo_nets[num].netname << endl;
this->gd = yolo_nets[num].gd;
this->gw = yolo_nets[num].gw;
//初始化GPU引擎
cudaSetDevice(DEVICE);
std::ifstream file(model_path, std::ios::binary);
if (!file.good()) {
std::cerr << "read " << model_path << " error!" << std::endl;
return;
}
file.seekg(0, file.end);
size = file.tellg(); //统计模型字节流大小
file.seekg(0, file.beg);
trtModelStream = new char[size]; // 申请模型字节流大小的空间
assert(trtModelStream);
file.read(trtModelStream, size); // 读取字节流到trtModelStream
file.close();
// prepare input data ------NCHW---------------------
runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
CUDA_CHECK(cudaStreamCreate(&stream));
std::cout << "Engine Initialize successfully!" << endl;
}
void Detection::setClassNum(int num)
{
CLASS_NUM = num;
}
int Detection::Detecting(cv::Mat& img, std::vector& Boxes, std::vector& ClassLables)
{
if (img.empty()) {
std::cout << "read image failed!" << std::endl;
return -1;
}
if (img.rows < 640 || img.cols < 640) {
std::cout << "img.rows: " << img.rows << "\timg.cols: " << img.cols << std::endl;
std::cout << "image height<640||width<640!" << std::endl;
return -1;
}
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[i] = (float)uc_pixel[2] / 255.0;
data[i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast(end - start).count() << "ms" << std::endl;
std::vector batch_res;
nms(batch_res, &prob[0], CONF_THRESH, NMS_THRESH);
for (size_t j = 0; j < batch_res.size(); j++) {
cv::Rect r = get_rect(img, batch_res[j].bbox);
Boxes.push_back(r);
ClassLables.push_back(classes[(int)batch_res[j].class_id]);
cv::rectangle(img, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(
img,
classes[(int)batch_res[j].class_id],
cv::Point(r.x, r.y - 2),
cv::FONT_HERSHEY_COMPLEX,
1.8,
cv::Scalar(0xFF, 0xFF, 0xFF),
2
);
}
return 0;
}
Detection::Detection() {}
Detection::~Detection()
{
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
}
Connect::Connect()
{}
Connect::~Connect()
{}
YOLOV5* Connect::Create_YOLOV5_Object()
{
return new Detection; //注意此处
}
void Connect::Delete_YOLOV5_Object(YOLOV5* _bp)
{
if (_bp)
delete _bp;
}
这部分有什么问题可以参考下面的文章
yolov5动态链接库DLL导出(TensorRT)_yolov5 dll_成都_小吴的博客-CSDN博客延续上一篇tTensorRT部署yolov5,大家可以使用生成的yolov5.exe进行终端命令或者VS里面使用命令代码进行检测,但是这样看起来很繁琐很臃肿,有些同学想调用他做一个QT界面啥的,直接调用这个dll就可以进行推理又方便还很快,大家也可以去原博主下面查看,首选i保证你看了我的第一篇tensort推理yolov5,我们打开cmake编译程序的工程目录:一.文件创建:导出库必要文件:dllmain.cpp,framework.h,就在当前工程下面建立这两个文件// dl....https://blog.csdn.net/qq_52859223/article/details/124362671
win10 导出yolov5为动态链接库DLL(TensorRT推理)_SongpingWang的博客-CSDN博客win10 导出yolov5为动态链接库DLL(TensorRT)一、前期准备1. 新增windows导出动态库文件2. 新增导出类(以接口类的方式导出)二、编译动态链接库三、测试导出的DLL本文的前置文章:win10 使用TensorRT部署 yolov5-v4.0(C++) 调试好确定代码正常运行。https://blog.csdn.net/wsp_1138886114/article/details/122321920?spm=1001.2014.3001.5501
同样的cmake 操作:

打开项目文件,重新生成即可


到这里说明一切生成成功,因为很多东西我进行了修改,所以这次配置没有出错,我会在评论区留下资源,把后面这些文件进行分享,你们复制进去即可。
3.yolov5-tensorrrt 的dll在vs qt中调用
(1)这里关于qt 在vs 的配置 以及qt 在vs中常见的问题可以参考如下:我使用的qt 版本是5.12.10

Qt5.11.1安装与VS2017配置_qt5.11下载_GJXAIOU的博客-CSDN博客
https://blog.51cto.com/u_15127693/3317104
Visual Studio 2019配置qt开发环境_LYH2277的博客-CSDN博客



(2)将下面这些文件复制进qt项目文件夹中,这些都是我们上面已经生成了的
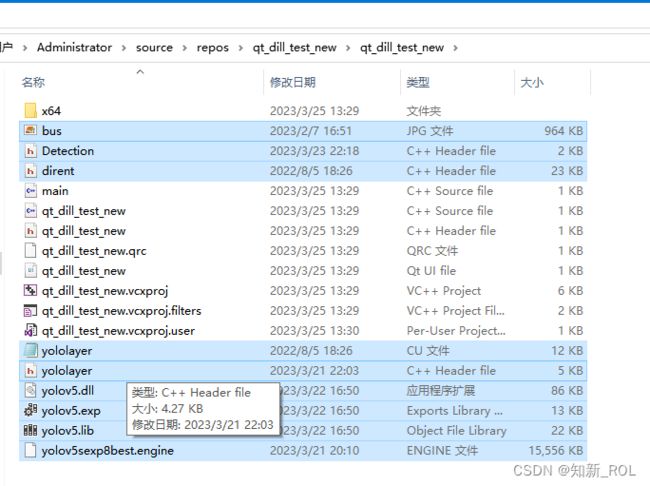
并将这些文件导入进去

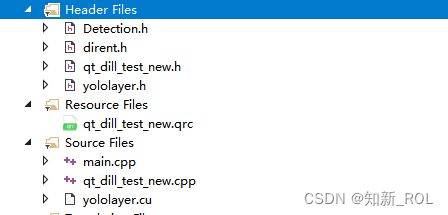
导进来之后对.cu开始配置cuda 选中项目 点击生成依赖项,生成自定义


选中后,点击确定。
然后在项目的属性列表中配置。
需要生成三个地方 头文件,库文件,以及哪些.lib
如果不是qt项目测试的话,以上操作差不多

附加包含目录改成
D:\my_code\my_yolov5_tensorrt;D:\my_code\my_yolov5_tensorrt\include;D:\my_software\opencv\opencv\build\include;D:\my_software\opencv\opencv\build\include\opencv2;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include;D:\my_software\TensorRT-8.5.3.1\include;%(AdditionalIncludeDirectories)
链接器中的常规的附加库目录改成
D:\my_software\opencv\opencv\build\x64\vc15\lib;D:\my_software\TensorRT-8.5.3.1\lib;D:\my_code\my_yolov5_tensorrt\build_dill\Release;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\Win32;%(AdditionalLibraryDirectories) 
链接器中输入的 附加依赖项改成
opencv_world453.lib;opencv_world453d.lib;cudart.lib;cudart_static.lib;yolov5.lib;nvinfer.lib;nvinfer_plugin.lib;nvonnxparser.lib;nvparsers.lib;cuda.lib;cudadevrt.lib;OpenCL.lib;cublas.lib;cudnn.lib;cudnn64_8.lib;%(AdditionalDependencies)配置上这些后加入测试代码
导入头文件
#include"yololayer.h"
#include
#include
#include
#include "Detection.h"
#include "yololayer.h"
#include
#include
#include
#include
#include 然后
在你要调试的那一块
Connect connect;
YOLOV5* yolo_dll = connect.Create_YOLOV5_Object();
cv::Mat img, frame;
std::vector Boxes;
std::vectorClassLables;
const char* image_path = "E:/1.mp4";
cv::VideoCapture capture(image_path);//打开摄像头
yolo_dll->Initialize("D:/my_code/dill_test_yolo_new/dill_yolo/yolov5sexp8best.engine", 0);
int len = strlen(image_path);
while (true)
{
/*************摄像头测试
capture >> frame; //取一帧图片
img = frame;
*************/
capture >> frame; //取一帧图片
img = frame;
yolo_dll->Detecting(img, Boxes, ClassLables);
cv::namedWindow("output", cv::WINDOW_NORMAL);
cv::imshow("output", img);
cv::waitKey(1);
}
cv::waitKey();
connect.Delete_YOLOV5_Object(yolo_dll); 

所以这就是检测结果,项目要求,不展示全部画面
关于如何在qtcreator 中如何调用,感兴趣的可以联系我邮箱[email protected]
提供我的.pro文件供大家参考
QT += core gui
greaterThan(QT_MAJOR_VERSION, 4): QT += widgets
CONFIG += c++11
# You can make your code fail to compile if it uses deprecated APIs.
# In order to do so, uncomment the following line.
#DEFINES += QT_DISABLE_DEPRECATED_BEFORE=0x060000 # disables all the APIs deprecated before Qt 6.0.0
SOURCES += \
main.cpp \
mainwindow.cpp
HEADERS += \
Detection.h \
mainwindow.h \
yololayer.h
FORMS += \
mainwindow.ui
# Default rules for deployment.
qnx: target.path = /tmp/$${TARGET}/bin
else: unix:!android: target.path = /opt/$${TARGET}/bin
!isEmpty(target.path): INSTALLS += target
# CUDA settings <-- may change depending on your system
#__________________________________________________________________________________________________
DISTFILES += \
yololayer.cu\
# opencv 设置
win32:CONFIG(release, debug|release): LIBS += -LD:/my_software/opencv/opencv/build/x64/vc15/lib/ -lopencv_world453
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_software/opencv/opencv/build/x64/vc15/lib/ -lopencv_world453d
INCLUDEPATH += D:/my_software/opencv/opencv/build/include
DEPENDPATH += D:/my_software/opencv/opencv/build/include/opencv2
# 自己导出的dll 设置
INCLUDEPATH += "D:/my_code/my_yolov5_tensorrt"
DEPENDPATH += "D:/my_code/my_yolov5_tensorrt"
win32:CONFIG(release, debug|release): LIBS += -LD:/my_code/my_yolov5_tensorrt/build_dill/Release/ -lyolov5
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_code/my_yolov5_tensorrt/build_dill/Release/ -lyolov5d
### TensorRT-8.5.3.1设置
INCLUDEPATH +="D:/my_software/TensorRT-8.5.3.1/include"
DEPENDPATH +="D:/my_software/TensorRT-8.5.3.1/include"
win32:CONFIG(release, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvinfer
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvinferd
win32:CONFIG(release, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvinfer_plugin
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvinfer_plugind
win32:CONFIG(release, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvonnxparser
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvonnxparserd
win32:CONFIG(release, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvparsers
else:win32:CONFIG(debug, debug|release): LIBS += -LD:/my_software/TensorRT-8.5.3.1/lib/ -lnvparsersd
## CUDA 设置
CUDA_SOURCES += yololayer.cu
CUDA_DIR = "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.7"
SYSTEM_NAME = Win64
SYSTEM_TYPE = 64
CUDA_ARCH = sm_86
NVCC_OPTIONS = --use_fast_math
## 头文件路径
INCLUDEPATH += "$$CUDA_DIR/include"
# 导入库文件路径
QMAKE_LIBDIR += "$$CUDA_DIR/lib/x64"
CUDA_INC = $$join(INCLUDEPATH,'" -I"','-I"','"')